机器学中的参数估计
机器学习中的参数估计方法
前几天上的机器学习课上,老师讲到了参数估计的三种方法:ML,MAP和Bayesian estimation。课后,又查了一些相关资料,以及老师推荐的LDA方面的论文《Parameter estimation for text analysis》。本文主要介绍文本分析的三类参数估计方法-最大似然估计MLE、最大后验概率估计MAP及贝叶斯估计,以及三者之间的区别。
1、最大似然估计MLE
首先回顾一下贝叶斯公式
 = \frac{p(X|\theta) \cdot p(\theta)}{p(X)}")
这个公式也称为逆概率公式,可以将后验概率转化为基于似然函数和先验概率的计算表达式,即

最大似然估计就是要用似然函数取到最大值时的参数值作为估计值,似然函数可以写做
 = p(X | \theta) = \prod_{x \in X}{p(X = x | \theta)}")
由于有连乘运算,通常对似然函数取对数计算简便,即对数似然函数。最大似然估计问题可以写成
 = argmax_\theta \sum_{x \in X}\log p(x|\theta)")
这是一个关于 的函数,求解这个优化问题通常对求导,得到导数为0的极值点。该函数取得最大值是对应的的取值就是我们估计的模型参数。
的函数,求解这个优化问题通常对求导,得到导数为0的极值点。该函数取得最大值是对应的的取值就是我们估计的模型参数。
以扔硬币的伯努利实验为例子,N次实验的结果服从二项分布,参数为P,即每次实验事件发生的概率,不妨设为是得到正面的概率。为了估计P,采用最大似然估计,似然函数可以写作
=\sum_{i=1}^N\log p(C=c_i|p) \\ &= n^{(1)}\log p(C = 1|p) + n^{(0)}\log p(C = 0|p)\\ &= n^{(1)}\log p + n^{(0)}\log (1-p) \end{aligned}")
其中 表示实验结果为i的次数。下面求似然函数的极值点,有
表示实验结果为i的次数。下面求似然函数的极值点,有
}}{p} - \frac{n^{(0)}}{1-p} = 0")
得到参数p的最大似然估计值为
}}{n^{(1)} + n^{(0)}} = \frac{n^{(1)}}{N}")
可以看出二项分布中每次事件发的概率p就等于做N次独立重复随机试验中事件发生的概率。
如果我们做20次实验,出现正面12次,反面8次
那么根据最大似然估计得到参数值p为12/20 = 0.6。
2、最大后验估计MAP
最大后验估计与最大似然估计相似,不同点在于估计的函数中允许加入一个先验") ,也就是说此时不是要求似然函数最大,而是要求由贝叶斯公式计算出的整个后验概率最大,即
,也就是说此时不是要求似然函数最大,而是要求由贝叶斯公式计算出的整个后验概率最大,即
注意这里P(X)与参数无关,因此等价于要使分子最大。与最大似然估计相比,现在需要多加上一个先验分布概率的对数。在实际应用中,这个先验可以用来描述人们已经知道或者接受的普遍规律。例如在扔硬币的试验中,每次抛出正面发生的概率应该服从一个概率分布,这个概率在0.5处取得最大值,这个分布就是先验分布。先验分布的参数我们称为超参数(hyperparameter)即
= p(\theta|\alpha)")
同样的道理,当上述后验概率取得最大值时,我们就得到根据MAP估计出的参数值。给定观测到的样本数据,一个新的值 发生的概率是
发生的概率是
![]()
下面我们仍然以扔硬币的例子来说明,我们期望先验概率分布在0.5处取得最大值,我们可以选用Beta分布即
 = \frac{1}{B(\alpha, \beta)}p^{\alpha - 1}(1-p)^{\beta - 1} \stackrel{\triangle}{=}Beta(p|\alpha, \beta)")
其中Beta函数展开是
 = \frac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha + \beta)}")
当x为正整数时
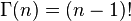
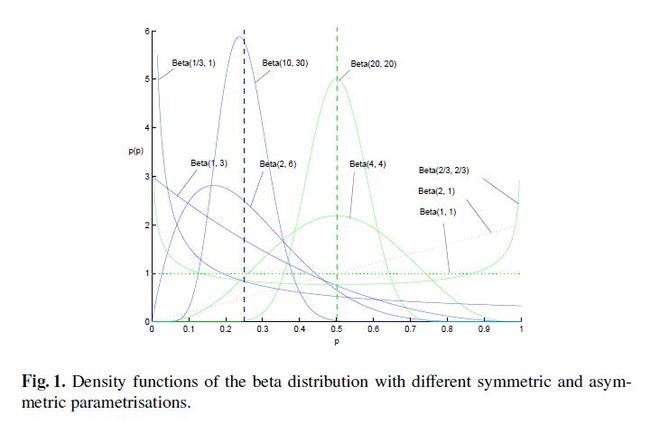
Beta分布的随机变量范围是[0,1],所以可以生成normalised probability values。下图给出了不同参数情况下的Beta分布的概率密度函数
我们取 ,这样先验分布在0.5处取得最大值,现在我们来求解MAP估计函数的极值点,同样对p求导数我们有
,这样先验分布在0.5处取得最大值,现在我们来求解MAP估计函数的极值点,同样对p求导数我们有
}}{p}-\frac{n^{(0)}}{1-p}+\frac{\alpha - 1}{p}-\frac{\beta - 1}{1 - p} = 0")
得到参数p的的最大后验估计值为
![]()
和最大似然估计的结果对比可以发现结果中多了 这样的pseudo-counts,这就是先验在起作用。并且超参数越大,为了改变先验分布传递的belief所需要的观察值就越多,此时对应的Beta函数越聚集,紧缩在其最大值两侧。
这样的pseudo-counts,这就是先验在起作用。并且超参数越大,为了改变先验分布传递的belief所需要的观察值就越多,此时对应的Beta函数越聚集,紧缩在其最大值两侧。
如果我们做20次实验,出现正面12次,反面8次,那么
那么根据MAP估计出来的参数p为16/28 = 0.571,小于最大似然估计得到的值0.6,这也显示了“硬币一般是两面均匀的”这一先验对参数估计的影响。
3 贝叶斯估计
贝叶斯估计是在MAP上做进一步拓展,此时不直接估计参数的值,而是允许参数服从一定概率分布。回顾一下贝叶斯公式
现在不是要求后验概率最大,这样就需要求") ,即观察到的evidence的概率,由全概率公式展开可得
,即观察到的evidence的概率,由全概率公式展开可得
 = \int_{\theta \in \Theta}p(X|\theta)p(\theta)d\theta")
当新的数据被观察到时,后验概率可以自动随之调整。但是通常这个全概率的求法是贝叶斯估计比较有技巧性的地方。
那么如何用贝叶斯估计来做预测呢?如果我们想求一个新值 的概率,可以由
的概率,可以由
 = \int_{\theta \in \Theta} p(\hat{x} | \theta)p(\theta|X)d\theta=\int_{\theta \in \Theta}p(\hat{x}|\theta)\frac{p(X|\theta)p(\theta)}{p(X)}d\theta")
来计算。注意此时第二项因子在 上的积分不再等于1,这就是和MLE及MAP很大的不同点。
上的积分不再等于1,这就是和MLE及MAP很大的不同点。
我们仍然以扔硬币的伯努利实验为例来说明。和MAP中一样,我们假设先验分布为Beta分布,但是构造贝叶斯估计时,不是要求用后验最大时的参数来近似作为参数值,而是求满足Beta分布的参数p的期望,有
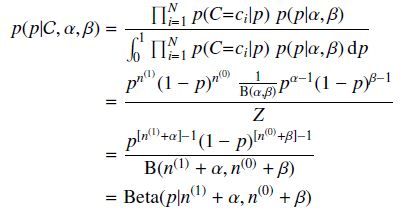
注意这里用到了公式
")
当T为二维的情形可以对Beta分布来应用;T为多维的情形可以对狄利克雷分布应用
根据结果可以知道,根据贝叶斯估计,参数p服从一个新的Beta分布。回忆一下,我们为p选取的先验分布是Beta分布,然后以p为参数的二项分布用贝叶斯估计得到的后验概率仍然服从Beta分布,由此我们说二项分布和Beta分布是共轭分布。在概率语言模型中,通常选取共轭分布作为先验,可以带来计算上的方便性。最典型的就是LDA中每个文档中词的Topic分布服从Multinomial分布,其先验选取共轭分布即Dirichlet分布;每个Topic下词的分布服从Multinomial分布,其先验也同样选取共轭分布即Dirichlet分布。
根据Beta分布的期望和方差计算公式,我们有
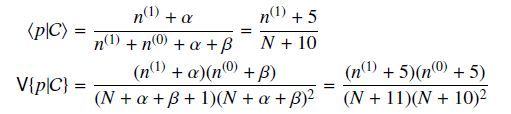
可以看出此时估计的p的期望和MLE ,MAP中得到的估计值都不同,此时如果仍然是做20次实验,12次正面,8次反面,那么我们根据贝叶斯估计得到的p满足参数为12+5和8+5的Beta分布,其均值和方差分别是17/30=0.567, 17*13/(31*30^2)=0.0079。可以看到此时求出的p的期望比MLE和MAP得到的估计值都小,更加接近0.5。
综上所述我们可以可视化MLE,MAP和贝叶斯估计对参数的估计结果如下
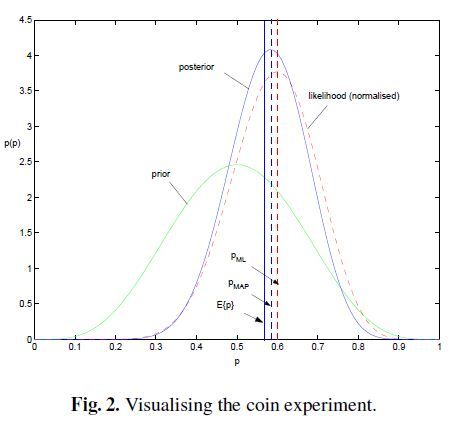
个人理解是,从MLE到MAP再到贝叶斯估计,对参数的表示越来越精确,得到的参数估计结果也越来越接近0.5这个先验概率,越来越能够反映基于样本的真实参数情况。
4.三者之间的区别
首先我们可以看到,最大似然估计和最大后验估计都是基于一个假设,即把待估计的参数π看做是一个固定的值,只是其取值未知。而最大似然是最简单的形式,其假定参数虽然未知,但是是确定值,就是找到使得样本对数似然分布最大的参数。而最大后验,只是优化函数为后验概率形式,多了一个先验概率项。 而贝叶斯估计和二者最大的不同在于,它假定参数是一个随机的变量,不是确定值。在样本分布P(π|χ)上,π是有可能取从0到1的任意一个值的,只是取到的概率不同。而MAP和MLE只取了整个概率分布P(π|χ)上的一个点,丢失了一些观察到的数据χ给予的信息(这也就是经典统计学派和贝叶斯学派最大的分歧所在。)
参考文献:
1.Gregor Heinrich, Parameter estimation for test analysis, technical report
2.文本语言模型的参数估计-最大似然估计、MAP及贝叶斯估计 http://blog.csdn.net/yangliuy/article/details/8296481
3.《Gibbs Sampling for the UniniTiated》阅读笔记(上)---参数估计方法及Gibbs Sampling简介 http://crescentmoon.info/2013/06/29/Gibbs%20Sampling%20for%20the%20UniniTiated-1/
- 本文已收录于以下专栏:

相关文章推荐
-
参数估计的方法,MLE,MAP,Bayesian estimator
Density estimation是learning中常见的一个task,即估计该分布的参数θ。在有限的样本下,如何判定哪个估计最优,概率论中有两种常用的principle:MLE(Maximum ...
- xyqzki
- 2013年08月29日 20:43
- 3755
-
机器学习中三类参数估计的方法
本文主要介绍三类参数估计方法-最大似然估计MLE、最大后验概率估计MAP及贝叶斯估计。1、最大似然估计MLE首先回顾一下贝叶斯公式...
- wtq1993
- 2016年04月21日 21:30
- 1275
-
贝叶斯参数估计的理解
极大似然估计贝叶斯估计是参数估计中的一种方法,以贝叶斯思想为基础,而贝叶斯思想在机器学习中经常用到。机器学习中常涉及贝叶斯网络,最终的问题都是转化为参数求解。贝叶斯参数估计是这些问题的基础版本。前方高...
- jinping_shi
- 2016年12月03日 13:51
- 1072
-
机器学习 - GMM参数估计的EM算法
看理论之前先来【举个例子】: 对于一个未知参数的模型,我们观测他的输出,得到下图这样的直方图:我们先假设它是由两个高斯分布混合叠加而成的,那么我们该怎么去得到这两个高斯分布的参数呢? EM算法!!...
- Robin__Chou
- 2016年11月09日 14:16
- 1346
-
EM算法---基于隐变量的参数估计
注:本文中所有公式和思路来自于李航博士的《统计学习方法》一书,我只是为了加深记忆和理解写的本文。】EM算法算是机器学习中有些难度的算法之一,也是非常重要的算法,曾经被誉为10大数据挖掘算法之一,...
- u012771351
- 2016年11月03日 10:31
- 1155
-
机器学习中常用的矩阵求导公式
主要copy自新浪微博MachineLearner的博客希望作为自己学习机器学习的工具。矩阵求导好像从来没有学过,讲矩阵的课不讲求导,讲求导的课不讲矩阵。像维基百科什么的查找起来又费劲。其实在实际机器...
- xtydtc
- 2016年04月12日 15:31
- 8014
-
机器学习中的损失函数
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验...
- rosenor1
- 2016年08月24日 17:07
- 5207
-
机器学习中的参数与超参数之间的区别
机器学习中的模型参数和模型超参数在作用、来源等方面都有所不同,而模型超参数常被称为模型参数,这样,很容易对初学者造成混淆。本文给出了模型参数和模型超参数的定义,并进行了对比,指出了二者本质上的区别:模...
- shenxiaoming77
- 2017年08月07日 15:38
- 1536
-
核密度估计与自适应带宽的核密度估计
最近看论文,发现一个很不错的概率密度估计方法。在此小记一下。 先来看看准备知识。 密度估计经常在统计学中作为一种使用有限的样本来估计其概率密度函数的方法。 我们在研究随机变量的过程中,随机变量的...
- ChiXueZhiHun
- 2017年06月29日 22:26
- 1683
-
机器学习之深度学习(Deep Learning)
Deep Learning是机器学习中一个非常接近AI的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,最近研究了机器学习中一些深度学习的相关知识,本文给出一些很有用的资料和心得。...
- u014365862
- 2015年09月04日 20:40
- 906
-
贝叶斯 - 《贝叶斯统计》笔记
《贝叶斯统计 - 茆诗松》茆诗松《贝叶斯统计》目前看过的讲贝叶斯方法最通俗易懂的书了 下载了在这里第一章 先验分布和后验分布1.1 三种信息 统计学的两个主要学派:频率学派,贝叶斯学...
- jackxu8
- 2017年04月21日 17:13
- 1767
-
常见的预测算法
常见的预测算法有1.简易平均法,包括几何平均法、算术平均法及加权平均法;2.移动平均法,包括简单移动平均法和加权移动平均法;3,指数平滑法,包括 一次指数平滑法和二次指数平滑法,三次指数平滑法;...
- konglongaa
- 2016年05月19日 14:13
- 20583
-
参数估计:文本分析的参数估计方法
http://blog.csdn.net/pipisorry/article/details/51482120文本分析的三类参数估计方法-最大似然估计MLE、最大后验概率估计MAP及贝叶斯估计。参数估...
- pipisorry
- 2016年05月23日 17:36
- 11905
-
三种参数估计方法(MLE,MAP,贝叶斯估计)
三种参数估计方法(MLE,MAP,贝叶斯估计)
- Leo_Xu06
- 2016年04月22日 18:02
- 769
-
参数估计-最大似然估计和贝叶斯参数估计
为什么要进行参数估计 参数估计是统计学中的经典问题,常用的方法是最大似然估计和贝叶斯估计。为什么机器学习中,也会用到参数估计呢?我们利用训练样本来估计先验概率和条件概率密度,并以此设计分类器。当假...
- yujianmin1990
- 2015年08月18日 23:11
- 3068
-
2.数理统计与参数估计
内容简介:A.重要统计量B.重要定理与不等式C.参数估计A.重要统计量一、概率与统计概率:已知总体的分布情况,计算事件的概率统计:总体分布未知,通过样本值估计总体的分布二、概率统...
- aidway
- 2016年05月05日 22:57
- 1631
-
系统学习机器学习之参数方法(一)
最大似然估计法的基本思想 最大似然估计法的思想很简单:在已经得到试验结果的情况下,我们应该寻找使这个结果出现 的可能性最大的那个作为真 的估计。 我们分两种情进行分析: 1.离散型总...
- App_12062011
- 2015年12月15日 09:32
- 1988
-
机器学习之极大似然估计
极大似然估计基本思想极大似然估计是在总体类型已知的条件下使用的一种参数估计方法。 首先是德国数学家高斯在1821年提出的,然而这个方法常归功于英国统计学家费歇。 极大似然法的基本思想通过一...
- weiyudang11
- 2016年05月28日 10:47
- 1298
-
系统学习机器学习之参数方法(三)
原文:http://www.cnblogs.com/jerrylead1判别模型与生成模型上篇报告中提到的回归模型是判别模型,也就是根据特征值来求结果的概率。形式化表示为,在参数确定的情况下,求解...-
- App_12062011
- 2016年01月19日 09:36
- 1414
-
七月算法机器学习笔记1--机器学习中的数学之数理统计和参数估计
数理统计和参数估计首先,看一下概率与统计的关注点概率论问问题的方式:已知总体的可能性,求某种事件发生的概率,如图所示:...
- thystar
- 2016年04月25日 18:06
- 1442
-
yt71656
+关注

-
原创
- 7
-
粉丝
- 4
-
喜欢
- 0
-
码云
- 未开通
他的最新文章
更多文章- 0-1背包问题
- 动态规划之合唱队形问题(最长递增子序列变形)
- java环境变量详解---找不到或无法加载主类
相关推荐
- 参数估计的方法,MLE,MAP,Bayesian estimator
- 机器学习中三类参数估计的方法
- 贝叶斯参数估计的理解
- 机器学习 - GMM参数估计的EM算法
他的热门文章
- 关于LDA学习的一些有用的博客以及大牛写的代码实现
5330
- 如何确定LDA的topic个数
3575
- 机器学习中的参数估计方法
2749
- 一文读懂机器学习,大数据/自然语言处理/算法全有了……
645
- 从最大似然到EM算法浅解
632