爬虫过程和反爬
文章目录
- 爬虫过程
-
- 一、获取网络数据(requests、selenium)
-
- 1.`requests`
- 2.`selenium`
- 3.常见反爬
- 4.找数据接口
- 二、解析数据(从获取到的网络数据中提取有效数据)
-
- 1.正则表达式
- 2.基于`css`选择器的解析器(`bs4`)
- 3.基于`xpath`的解析器(`lxml`)
- 三、保存数据:`csv`、Excel
爬虫过程
爬虫:获取网络数据(公开的网络)
网络数据来源:网站对应的网页、手机APP
一、获取网络数据(requests、selenium)
1.requests
-
定义
Python获取网络数据的第三方库(基于http或https协议的网络请求) -
应用场景
1)直接请求网页地址 2)对提供网页数据的数据接口发送请求 -
基本用法
1)对目标网页直接发送请求: requests.get(网页地址):获取指定页面的数据返回一个响应对象 2)获取响应的状态码:response.status_code 3)获取响应头:response.headers 4)请求内容(返回的有效数据): a.response.content: 二进制类型的数据(图片、视频、音频等,例如:图片下载) b.response.text: 字符串类型的数据(网页) c.response.json(): 对请求内容做完json解析后的数据(json数据接口)response = requests.get('https://cd.zu.ke.com/zufang') print(response) # 200表示请求成功 -
设置cookie
-
代理IP
2.selenium
-
下载驱动器
1)查看浏览器版本:chrome://version/
2)chromedriver国内镜像:https://registry.npmmirror.com/binary.html?path=chromedriver/0
3)到与浏览器最接近的文件夹进去下载,最新的是104.0.5112.81
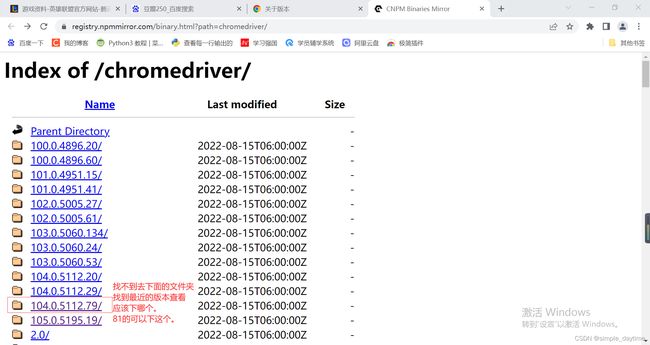

4)将下载好压缩包解压移动到python环境安装目录里。
在pycharm里面的settings里面查找环境目录,将解压好的chromedriver.exe放在python.exe同一目录。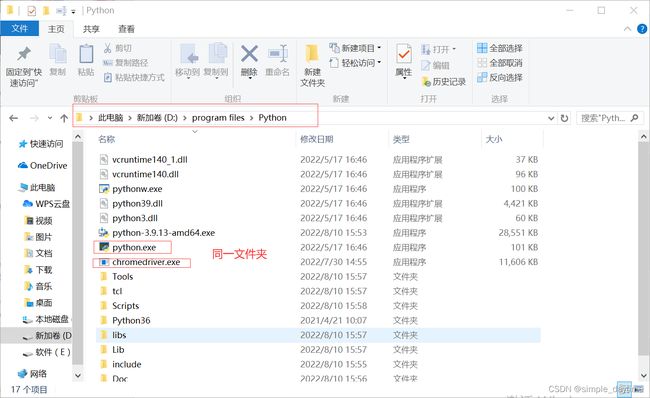
-
获取网页数据
1.创建浏览器对象(浏览器对象如果是全局变量,浏览器不会自动关闭) 2.打开网页 3.获取网页源代码 4.关闭浏览器# 导入模块 from selenium.webdriver import Chrome # 1.创建浏览器对象 b = Chrome() # 2.打开网页 b.get('https://movie.douban.com/top250') # 3.获取网页源代码: b.page_source print(b.page_source) # 4.关闭浏览器 b.close() -
控制浏览器基础操作
1.输入框输入内容 第一步:找到输入框 第二步:输入框输入内容-传值(标签.send_keys) 2.点击按钮 第一步:找到需要点击的标签 第二步:点击(标签.click()) 3.切换选项卡 1)获取当前浏览器上所有的窗口(选项卡):b.window_handles 2)切换选项卡:b.switch_to.window(切换到的窗口) 注意:selenium中,浏览器对象默认指向一开始打开的选项卡。除非用代码切换,否则浏览器对象指向的选项卡不会切换# 1.输入框输入内容 # 1)找到输入框 input_tag = b.find_element_by_id('key') # 2)输入框输入内容 input_tag.send_keys('电脑\n')# 2.点击按钮 # 1)找到需要点击的标签 btn = b.find_element_by_css_selector('#navitems-group2 .b') # 2)点击标签 btn.click()# 3.切换选项卡 # 进入中国知网输入‘数据分析’之后利用切换选项卡获取每篇论文的摘要 from selenium.webdriver import Chrome from time import sleep from bs4 import BeautifulSoup # 1.基本操作 b = Chrome() # 创建浏览器对象 b.get('https://www.cnki.net/') # 打开中国知网 # 获取输入框并输入内容 search_tag = b.find_element_by_id('txt_SearchText') search_tag.send_keys('数据分析\n') sleep(4) # 切换界面等待一会 # 获取需要点击的所有标签:如果拿到标签后需要点击或者输入,必须通过浏览器对象获取标签 results = b.find_elements_by_css_selector('.result-table-list .name>a') for i in range(len(results)): # 点击第一个结果(这会打开新的选项卡) results[i].click() b.switch_to.window(b.window_handles[-1]) # 切换选项卡到点开的论文窗口 # 解析内容 soup = BeautifulSoup(b.page_source, 'lxml') result = soup.select_one('#ChDivSummary') # 获取摘要 # 没有摘要输出无 if not result: print('无') else: print(result.text) b.close() # 关闭当前指向的窗口(最后一个窗口),窗口关闭后,浏览器对象的指向不会改变。 sleep(2) # 回到第一个窗口点击下一个搜索结果 b.switch_to.window(b.window_handles[0]) # 切换到第一个页面 b.close() # 关闭浏览器 -
前进后退
-
设置cookie
-
代理IP
3.常见反爬
-
浏览器伪装
import requests headers = { 'user-agent': 自己电脑浏览器信息 } response = requests.get('https://movie.douban.com/top250', headers=headers) -
登录反爬
解决办法: 设置cookie requests和selenium里分别写了 -
代理
IPrequests和selenium里分别写了
4.找数据接口
-
第一步:打开控制台
-
第二步:
-
第三步:
二、解析数据(从获取到的网络数据中提取有效数据)
1.正则表达式
# 例子
# 名字里面有换行,用单行匹配(?s)
names = findall(r'(?s)(.+?)', result)
2.基于css选择器的解析器(bs4)
-
bs4的作用
专门用来解析网页数据的第三方库。(基于css选择器解析网页数据) 这个库下载时用'beautifulsoup4', 使用的时候用'bs4' 注:使用bs4做数据解析时需要依赖'lxml'这个第三方库 -
导入模块
from bs4 import BeautifulSoup -
bs4的用法
1)准备需要解析的数据(获取网页数据) 2)基于网页源代码创建BeautifulSoup对象 3)获取标签 soup.select(css选择器):获取css选择器选中的所有标签,返回值是一个列表,列表中的元素是标签对象。 soup.select_one(css选择器):获取css选择器选中的第一个标签,返回值是一个标签对象。 标签对象.select(css选择器):在指定标签中获取css选择器选中的所有标签,返回值是一个列表,列表中的元素是标签对象。 标签对象.select_one(css选择器):在指定标签中获取css选择器选中的第一个标签,返回值是一个标签对象。 4)获取标签内容和标签属性 a.获取标签内容:标签对象.text b.获取标签属性:标签对象.attr[属性名]# 一个bs4使用的完整代码 # 导入解析相关类 from bs4 import BeautifulSoup # bs4的用法 # 1)准备需要解析的数据(获取网页数据) html = open('files/test.html', encoding='utf-8').read() # 2)基于网页源代码创建BeautifulSoup对象:soup对象代表网页对应的html标签(整个网页) soup = BeautifulSoup(html, 'lxml') # 3)获取标签 # soup.select(css选择器):获取css选择器选中的所有标签,返回值是一个列表,列表中的元素是标签对象。 # soup.select_one(css选择器):获取css选择器选中的第一个标签,返回值是一个标签对象。 result = soup.select('p') print(result) # [你是大笨蛋
] result = soup.select_one('p') print(result) #你是大笨蛋
# 标签对象.select(css选择器):在指定标签中获取css选择器选中的所有标签,返回值是一个列表,列表中的元素是标签对象。 # 标签对象.select_one(css选择器):在指定标签中获取css选择器选中的第一个标签,返回值是一个标签对象。 # 4)获取标签内容和标签属性 p = soup.select_one('p') img = soup.select_one('img') # a.获取标签内容:标签对象.text print(p.text) # 你是大笨蛋 # b.获取标签属性:标签对象.attr[属性名] print(img.attrs['src']) # 123