深度学习解决大规模文本分类问题 - 综述和实践
from https://zhuanlan.zhihu.com/p/25928551
(1)文本预处理
文本分词
去停用词
(2)文本表示和特征提取
文本表示:
文本表示的目的是把文本预处理后的转换成计算机可理解的方式,是决定文本分类质量最重要的部分。传统做法常用词袋模型(BOW, Bag Of Words)或向量空间模型(Vector Space Model),最大的不足是忽略文本上下文关系,每个词之间彼此独立,并且无法表征语义信息。词袋模型的示例如下:
( 0, 0, 0, 0, .... , 1, ... 0, 0, 0, 0)
一般来说词库量至少都是百万级别,因此词袋模型有个两个最大的问题:高纬度、高稀疏性。词袋模型是向量空间模型的基础,因此向量空间模型通过特征项选择降低维度,通过特征权重计算增加稠密性。
特征提取:
向量空间模型的文本表示方法的特征提取对应特征项的选择和特征权重计算两部分。特征选择的基本思路是根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益、χ²统计量等。
特征权重计算——TF-IDF方法。主要思路是一个词的重要度与在类别内的词频成正比,与所有类别出现的次数成反比。
二、深度学习文本分类方法
2.1文本的分布式表示:词向量(word embedding)
文本的表示通过词向量的表示方式,把文本数据从高纬度高稀疏的神经网络难处理的方式,变成了类似图像、语音的的连续稠密数据。深度学习算法本身有很强的数据迁移性,很多之前在图像领域很适用的深度学习算法比如CNN等也可以很好的迁移到文本领域了。
2.2 深度学习文本分类模型
1)fastText
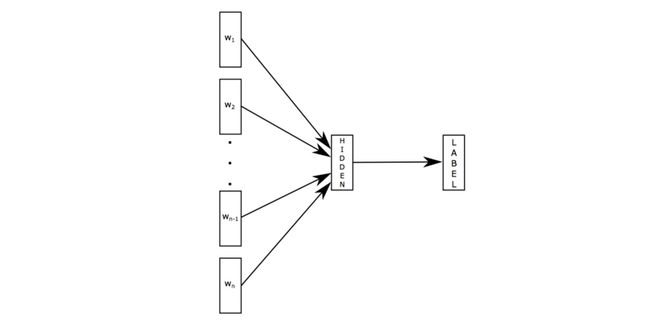
原理是把句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接 softmax 层。其实文章也加入了一些 n-gram 特征的 trick 来捕获局部序列信息。文章倒没太多信息量,算是“水文”吧,带来的思考是文本分类问题是有一些“线性”问题的部分[from项亮],也就是说不必做过多的非线性转换、特征组合即可捕获很多分类信息,因此有些任务即便简单的模型便可以搞定了。
2)TextCNN
本篇文章的题图选用的就是14年这篇文章提出的TextCNN的结构(见下图)。fastText 中的网络结果是完全没有考虑词序信息的,而它用的 n-gram 特征 trick 恰恰说明了局部序列信息的重要意义。卷积神经网络(CNN Convolutional Neural Network)最初在图像领域取得了巨大成功,CNN原理就不讲了,核心点在于可以捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。

TextCNN的详细过程原理图见下:
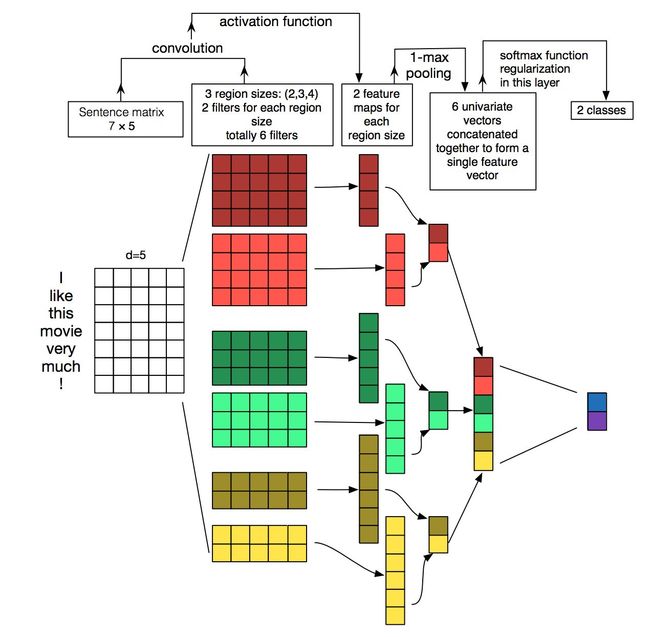
TextCNN详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
以机器翻译为例简单介绍下,下图中 是源语言的一个词, 是目标语言的一个词,机器翻译的任务就是给定源序列得到目标序列。翻译 的过程产生取决于上一个词 和源语言的词的表示 ( 的 bi-RNN 模型的表示),而每个词所占的权重是不一样的。比如源语言是中文 “我 / 是 / 中国人” 目标语言 “i / am / Chinese”,翻译出“Chinese”时候显然取决于“中国人”,而与“我 / 是”基本无关。下图公式, 则是翻译英文第 个词时,中文第 个词的贡献,也就是注意力。显然在翻译“Chinese”时,“中国人”的注意力值非常大。
Attention的核心point是在翻译每个目标词(或 预测商品标题文本所属类别)所用的上下文是不同的,这样的考虑显然是更合理的。
加入Attention之后最大的好处自然是能够直观的解释各个句子和词对分类类别的重要性。

利用前向和后向RNN得到每个词的前向和后向上下文的表示:
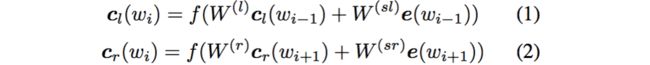
这样词的表示就变成词向量和前向后向上下文向量concat起来的形式了,即:
![]()
最后再接跟TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1就可以了,不再需要更大 filter_size 获得更大视野,这里词的表示也可以只用双向RNN输出。