【论文翻译】Learning Generalizable and Identity-Discriminative Representations for Face Anti-Spoofing
Abstract
由于人脸认证系统的高安全性需求,面部反欺骗(a.k.a演示攻击检测)已引起越来越多的关注。当训练和测试欺骗样本拥有相似的模式时,现有的基于CNN的方法通常很好地识别欺骗攻击,但它们的性能会在未知场景的测试欺骗攻击上急剧下降。在本文中,我们试图通过设计两个新颖性的CNN模型来提高方法的泛化能力和适用性。首先,我们针对CNN模型提出了一种简单但有效的总成对混淆(TPC)损失函数,这增强了学习演示攻击(PA)的通用性表现。其次,我们将快速域适应(FDA)组件纳入CNN模型,以减轻数据在不同域的变化带来的负面影响。此外,我们提出的模型,名为可推广面部认证CNN(GFA-CNN),以多任务方式工作,同时执行面部反欺骗和面部识别。实验结果表明,GFA-CNN优于以前的人脸反欺骗方法,并且很好地保留了输入人脸图像的身份信息。
Face anti-spoofing (a.k.a presentation attack detection) has drawn growing attention due to the high security de- mand in face authentication systems. Existing CNN-based approaches usually well recognize the spoofing faces when training and testing spoofing samples display similar pat- terns, but their performance would drop drastically on test- ing spoofing faces of unseen scenes. In this paper, we try to boost the generalizability and applicability of these methods by designing a CNN model with two major novelties. First, we propose a simple yet effective Total Pairwise Confusion (TPC) loss for CNN training, which enhances the general- izability of the learned Presentation Attack (PA) representa- tions. Secondly, we incorporate a Fast Domain Adaptation (FDA) component into the CNN model to alleviate negative effects brought by domain changes. Besides, our proposed model, which is named Generalizable Face Authentication CNN (GFA-CNN), works in a multi-task manner, perform- ing face anti-spoofing and face recognition simultaneously. Experimental results show that GFA-CNN outperforms pre- vious face anti-spoofing approaches and also well preserves the identity information of input face images.
1. Introduction
尽管近年取得了显着进步,但人脸识别系统的安全性仍然容易受到打印照片或重放视频的演示攻击(PA)的影响。为了抵消PA,面部反欺骗[25,19]被开发出来并作为面部识别之前的一个步骤。
早期的面部反欺骗方法主要采用手工制作的功能,如LBP [8],HoG [16]和SURF [5],以找出现场和欺骗面孔之间的差异。在[27]中,CNN首次用于面部反欺骗,在数据库内测试中取得了显着的性能。在他们的工作之后,已经提出了许多基于CNN的方法,几乎所有方法都将面部反欺骗视为二元(实时与欺骗)分类问题。然而,考虑到CNN的巨大解决方案空间,这些方法往往会遭受过度拟合以及对新PA模式和环境的不良通用性。在这项工作中,我们试图使反欺骗系统能够部署在各种环境中,即具有良好的通用性。
Despite the recent noticeable advances, the security of face recognition systems is still vulnerable to Presentation Attacks (PA) with printed photos or replayed videos. To counteract PA, face anti-spoofing [25, 19] is developed and serves as a pre-step prior to face recognition.
Earlier face anti-spoofing approaches mainly adopt handcrafted features, like LBP [8], HoG [16] and SURF [5], to find the differences between live and spoofing faces. In [27], CNN was used for face anti-spoofing for the first time, with remarkable performance achieved in intra- database tests. Following their work, a number of CNN-based methods have been proposed, almost all treating face anti-spoofing as a binary (live vs. spoofing) classification problem. However, given the enormous solution space of CNN, these methods tend to suffer overfitting and poor gen- eralizability to new PA patterns and environments. In this work, we attempt to enable an anti-spoofing system to be deployed in various environments, i.e. with good generaliz- ability.
对于基于CNN的方法,区分现场与欺骗面部的重要线索是欺骗模式,包括颜色失真,莫尔图案,形状变形,欺骗伪像(例如反射)等。在CNN模型训练期间 ,强大的模式会产生更多的贡献,并且由此产生的模型对它们更具辨别力。 但是,如果测试数据中没有这些模式,性能将严重下降。 基于CNN的方法倾向于过度学习某些强烈的欺骗模式,因此普遍性较差[19]。 除了过度拟合之外,数据的域转移[18]也是面部反欺骗方法普遍性差的重要原因。 这里的域是指某个获取图像的环境,包括各种因素,如照明,背景,面部外观,相机类型等。考虑到现实世界环境的巨大差异,不同的样本具有不同的域是非常常见的。 例如,即使在相同面部的情况下,如果用不同的纸片(例如光泽纸和粗糙纸)再现,两个纸张攻击的域可能是完全不同的。 这种域差异可能导致特征空间中不同样本的分布不相似,并导致模型在新域上失败。
For CNN-based methods, an important clue to differen- tiate live vs. spoofing faces is the spoof pattern, including color distortion, moir ́e pattern, shape deformation, spoofing artifacts (e.g., reflection), etc. During CNN model train- ing, strong patterns make more contributions, and the resultant model is more discriminative for them. However, if these patterns are absent in the testing data, the performance would severely drop. The CNN-based methods tend to over- fit to some strong spoof patterns and thus suffer poor generalizability [19]. Apart from overfitting, domain shift [18] is also an important reason for the poor generalizability of face anti-spoofing methods. A domain here refers to a certain environment where an image is acquisited, consisting of various factors such as illumination, background, facial appearance, camera type, etc. Considering the huge diver- sity of real world environments, it is very common that dif- ferent samples have different domains. For example, the domains of two paper attacks may be quite different even in case of the same face if reproduced with different pieces of paper (e.g. glossy vs. rough paper). Such domain variance may lead to distribution dissimilarity of different samples in the feature space and cause the models to fail on new domains.
图1:我们的CNN框架以多任务方式工作,一次性解决人脸识别和面部反欺骗问题。 它利用完全成对混淆(TPC)丢失和快速域适应(FDA)来增强学习的演示攻击(PA)功能的通用性,并改善不同场景中的面部反欺骗性能。
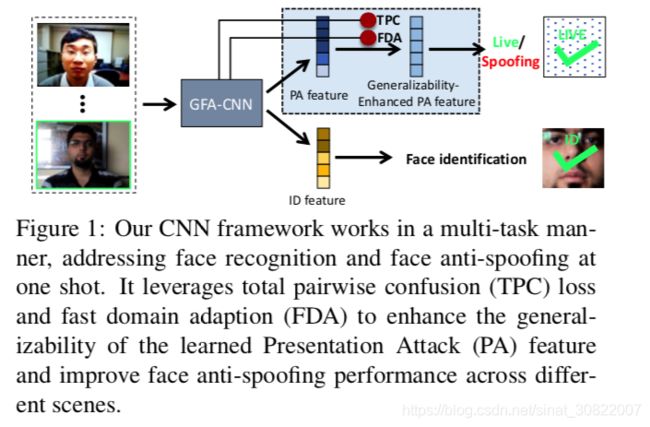
基于上述观察,我们提出了一种新的整体成对混合(TPC)损失,以平衡所有相关欺骗模式的影响,并采用快速域适应(FDA)模型[11]来缩小特征空间域中不同样本的分布差异。 然后我们获得一个广义面部认证CNN模型,简称为GFA-CNN。 与现有的面部反欺骗方法不同,我们的GFA-CNN以多任务方式工作,同时进行面部反欺骗和人脸识别,如图1所示。 这两个任务的CNN层共享相同的参数,我们的模型工作效率很高。针对面部反欺骗的五个流行基准的广泛实验证明了我们的方法优于现有技术的优势。 我们的代码和经过训练的模型将在论文接受后提供。 我们的贡献总结如下:
Based on the above observations, we propose a new Total Pairwise Confusion (TPC) loss to balance the contributions of all involved spoof patterns, and also employ a Fast Domain Adaptation (FDA) model [11] to narrow the distribution discrepancy of samples from different domains in the feature space. We then obtain a Generalizable Face Authentication CNN model, shorted as GFA-CNN. Different from prior methods that take face anti-spoofing as a pre-step of face authentication, our GFA-CNN works in a multi-task manner, performing simultaneously face anti-spoofing and face recognition, as shown in Fig. 1. Since the CNN layers of the two tasks share the same parameters, our model works with high efficiency.
Extensive experiments on five popular benchmarks for face anti-spoofing demonstrate the superiority of our method over the state-of-the-arts. Our code and trained models will be available upon acceptance. Our contribu- tions are summarized as follows:
我们提出了总成对混淆(TPC)损失,以有效地减轻基于CNN的面部反欺骗模型的过度拟合问题到数据集特定的欺骗模式,这改善了面部反欺骗方法的普遍性。
•我们采用快速域适应(FDA)模型来学习更强大的演示攻击(PA)表示,从而减少特征空间中的域移位。
•我们开发了面向身份验证的多任务CNN模型。 我们的GFA-CNN同时执行反欺骗和面部识别。
We propose a Total Pairwise Confusion (TPC) loss to effectively relieve the overfitting problems of CNN- based face anti-spoofing models to dataset-specific spoof patterns, which improves generalizability of face anti-spoofing methods.
• We incorporate the Fast Domain Adaptation (FDA) model to learn more robust Presentation Attack (PA) representations, which reduces domain shift in the feaure space.
• We develop a multi-task CNN model for face authentication. Our GFA-CNN performs jointly face anti- spoofing and face recognition.
图2:拟议的GFA-CNN的架构。 整个网络包含两个分支。 面部反欺骗分支(上部)将由FDA转换的域自适应图像作为输入,并通过TPC损失和防欺骗损失进行优化,面部识别分支(底部)将裁剪的面部图像作为输入并通过 最大限度地减少Recog损失。 结构设置显示在每个块的顶部,其中“ID号”表示参与训练中的分类数。 两个分支在训练期间共享参数。

大多数先前的面部反欺骗方法利用预定义的特征(例如LBP [8],HoG [16]和SURF [5])利用实时和欺骗面部之间的纹理差异,随后将其馈送到监督分类器(例如, SVM,LDA)用于二进制分类。 然而,这种手工制作的特征对不同的照明条件,相机设备,特定身份等非常敏感。尽管在内部数据集协议下实现了显着的性能,但来自不同环境的样本可能使模型失败。 为了获得具有更好的可普遍性的特征,一些方法利用时间信息,例如, 利用活体面部的自发动作,如眨眼[20]和嘴唇运动[15]。 虽然这些方法对于照片攻击是有效的,但是当攻击者通过切割眼睛/嘴巴位置的纸张模拟这些动作时,它们会变得脆弱。
Most previous approaches for face anti-spoofing exploit texture differences between live and spoofing faces with pre-defined features such as LBP [8], HoG [16], and SURF [5], which are subsequently fed to a supervised classifier (e.g., SVM, LDA) for binary classification. However, such handcrafted features are very sensitive to different illumination conditions, camera devices, specific identities, etc. Though noticeable performance achieved under the intradataset protocol, the sample from a different environment may fail the model. In order to obtain features with better generalizability, some approaches leverage temporal information, e.g. making use of the spontaneous motions of the live faces, such as eye-blinking [20] and lip motion [15]. Though these methods are effective against photo attacks, they become vulnerable when attackers simulate these mo- tions through a paper with eye/mouth positions cut.
最近,已经提出了基于深度学习的方法[27,17]来解决面部反欺骗。 他们通过将面部反欺骗作为二元分类问题来使用CNN来学习高度辨别力的表示。 然而,他们中的大多数容易遭受过度拟合。 目前公开的面部反欺骗数据集太有限,无法涵盖各种潜在的欺骗类型。 Liu等人最近的一项工作[19]。 利用深度图和rPPG信号作为辅助监督来训练CNN,而不是将面部反欺骗视为简单的二元分类问题,以避免过度拟合。 面部反欺骗的另一个关键问题是域名转移。 为了弥补训练和测试域之间的差距,[17]通过最小化跨域特征分布的不相似性,即最小化表示之间的最大平均差异距离,将CNN推广到未知条件。
Recently, deep learning based methods [27, 17] have been proposed to address face anti-spoofing. They use CNNs to learn highly discriminative representations by taking face anti-spoofing as a binary classification problem. However, most of them easily suffer overfitting. Current publicly available face anti-spoofing datasets are too limted to cover various potential spoofing types. A very recent work [19] by Liu et al. leverages the depth map and rPPG signal as auxiliary supervision to train CNN instead of treating face anti-spoofing as a simple binary classification problem in order to avoid overfitting. Another critical issue for face anti-spoofing is domain shift. To bridge the gap between training and testing domains, [17] generalizes CNN to unknown conditions by minimizing the feature distribution dissimilarity across domains, i.e. minimizing the Maximum Mean Discrepancy distance among representations.
图3:学习的特征分布w /和w/o Ltpc的可视化比较。 没有Ltpc,特征分布是多样的和特定于人的(左),而对于Ltpc,特征分布变得紧凑和均匀(右)。 l是分类超平面。 从颜色角度易于看清。


据我们所知,几乎所有以前的作品都将面部反欺骗作为面部识别前的一个步骤,并将其作为二元分类问题来解决。 与以往的文献相比,我们一举解决了面部反欺骗和人脸识别问题。 与我们最相关的工作是[23],它提出了一个双层框架,以确保用户对识别系统的真实性,即通过生物识别系统监控用户是否作为活体亦或是欺骗攻击。 这个系统执行基于指纹,手掌静脉打印,面部等的认证,具有两个分离的层:反欺骗由CNN赋能学习表征,而识别人脸是基于诸如ORB点的预定义手工特征。
To our best knowledge, almost all previous works take face anti-spoofing as a pre-step prior to face recognition and address it as a binary classification problem. Compared with previous literature, we solve face anti-spoofing and face recognition at one shot. A most related work to ours is [23], which proposed a two-tier framework to ensure the authenticity of the user to the recognition system, namely, monitoring whether the user has passed the biometric system as a live or spoofing one. It performs authentication based on fingerprint, palm vein print, face, etc., with two separated tiers: the anti-spoofing is powered by CNN learned representations while the recognition is based on pre-defined handcrafted features like ORB points.
与[23]不同,我们以多任务方式构建我们的GFA-CNN,我们的框架可以识别给定面部的身份,同时判断面部是活的还是欺骗性的。 值得一提的是,对于人脸识别,我们的方法在LFW数据库中实现了高达97.1%的单模型精度[12],这甚至可以与现有技术相媲美(97.1%的精度不值得夸耀,有点托大,by 译者注)。
Different with [23], we build our GFA-CNN in a multi- task manner, our framework can recognize the identity of a given face, and meanwhile judge whether the face is a live or spoofing one. It is worth mentioning that for face recognition, our method achieves single-model accuracy up to 97.1% on the LFW database [12], which is even compa- rable to state-of-the-arts.
3. Generalizable Face Authentication CNN
3.1. Multi-Task Network Architecture
所提出的普适面部认证-CNN(GFA-CNN)能够以相互提升的方式共同解决人脸识别和人脸反欺骗。 该网络有两个分支:面部反欺骗分支和人脸识别分支。 每个分支由5个CNN层和3个完全连接(FC)层组成,每个块包含3个CNN层。 参数在这两个分支之间共享。 通过最小化TPC损失和人脸反欺骗损失(防欺骗损失)训练面部反欺骗分支,同时通过优化面部识别损失(Recg-loss)来训练面部识别分支。 反欺骗分支采用带背景的人脸作为输入原始图像,而识别分支采用裁剪的人脸作为输入。 在输入到面部反欺骗分支之前,通过给定的目标域图像将训练图像迁移到目标域。 在测试阶段,每个查询图像都会迁移到目标域,然后传播到网络中。
The proposed Generalizable Face Authentication CNN (GFA-CNN) is able to jointly address face recognition and face anti-spoofing in a mutual boosting way. The network has two branches: the face anti-spoofing branch and the face recognition branch. Each branch consists of 5 blocks of CNN layers and 3 fully connected (FC) layers, and each block contains 3 CNN layers. The parameters are shared between these two branches. The face anti-spoofing branch is trained by minimizing TPC loss and face anti-spoofing loss (Anti-loss), while the face recognition branch is trained by optimizing face recognition loss (Recg-loss). The anti- spoofing branch takes as input raw face images with back- ground, while the recognition branch takes cropped faces as input. Before fed to the face anti-spoofing branch, the train- ing images are transferred to a target domain by a given target-domain image. In testing phase, each query image is transferred to the target domain and then propagated for- ward the network.
CNN模块的结构与VGG16的结构部分相同。 在训练之前,首先在VGG面部数据集上训练CNN块以获得面部识别的基本权重。 除了最后一层FC层的输出尺寸外,FC防欺骗和人脸识别分支的FC层具有相同的结构。 面部反欺骗分支对于最后一个FC层采用2维,而面部识别分支中最后一个FC层的尺寸取决于训练中涉及的人脸类型数量。 总体目标损失函数是
L = Lanti +λ1* Lid +λ2* Ltpc,(1)
其中Lanti和Lrecg分别是面部反欺骗和人脸识别的交叉熵损失,Ltpc是总成对混淆(TPC)损失,λ1和λ2是两个损失中的加权参数。
The CNN blocks are structured the same with the convo- lution part of VGG16. Before training, the CNN blocks are first trained on the VGG-face dataset to obtain fundamental weights for face recognition. The FC layers of face anti- spoofing and face recognition branches have the same struc- ture except for the output dimension of the last FC layer. The face anti-spoofing branch takes 2 dimensions for the last FC layer, while the dimensions of the last FC layer in the face recognition branch depend on the number of sub- jects involved in training. The overall objective function is
L = Lanti +λ1 ∗Lid +λ2 ∗Ltpc, (1)
where Lanti and Lrecg are the cross entropy losses for face anti-spoofing and face recognition respectively, Ltpc is the Total Pairwise Confusion (TPC) loss, and λ1 and λ2 are the weighting parameters among different losses.
3.2. Total Pairwise Confusion Loss
为了学习适应不同环境条件的演示攻击(PA)表示,我们提出了一种新的总成对混淆(TPC)损失。 我们的灵感来自成对混淆(PC)损失[10],它通过故意在特征激活中引入混淆来解决细粒度视觉分类中的过度拟合问题。 我们修改他们的混淆实现,使其适用于面部反欺骗任务。 我们的TPC损失定义为:

其中xi和xj是两个随机选择的图像(样本对),M是训练中涉及的样本对的总数,ψ(x)表示面部反欺骗分支的第二个全连接层的表示(见图2)。
(译者注: 论文【10】可参考https://blog.csdn.net/Jadelyw/article/details/82988498 个人感觉类似孪生网络,或facenet的tripletloss的概念,区别是存在两个fc层,在倒数第二层提取出特征进行欧式距离的计算)
In order to learn Presentation Attack (PA) representations that are adaptable to varying environment conditions, we propose a novel Total Pairwise Confusion (TPC) loss. Our inspiration comes from the pairwise confusion (PC) loss [10] that tackles the overfitting issue in fine-grained visual classification by intentionally introducing confusion in the feature activations. We modify their confusion imple- mentation to make it applicable to the face anti-spoofing task. Our TPC loss is defined as

where xi and xj are two randomly selected images (sample pair), M is the total number of sample pairs involved in training and ψ(x) denotes the representations of the second fully connected layer of the face anti-spoofing branch.
我们的Ltpc与原始PC损失的区别有两点:1)TPC损失使来自训练集的随机样本对的分布距离最小化,而不是来自两个不同类别的样本对,以迫使CNN学习更细微的判别性特征。 2)我们最小化特征空间中的欧几里德距离,而原始PC损失为了使同一样本对中的样本具有相似的条件概率分布,最小化概率空间中的距离(softmax的输出)。
Our Ltpc differs from the original PC loss in two-fold: 1) TPC loss minimizes the distribution distance of a random sample pair from the training set, rather than the sample pair from two different categories, to force CNN to learn slightly less discriminative features. 2) We minimize the Euclidean distance in the feature space while the original PC loss min- imizes the distance in the probability space (output of soft- max) to make samples in the same pair have a similar con- ditional probability distribution.
我们的修改基于以下考虑:1)将面部反欺骗视为二元分类时,跨类别的混淆不会过分影响PA功能在区分活体和欺骗样本的可区分性。 2)相同类型相关的面部样本通常会聚集在特征空间中,而对所有样本实施混淆可以压缩并均匀化整个特征分布(参见图3),从而有利于泛化性能。 3)作为更简单结构的二元分类问题,在特征空间内对模型进行正则化比在输出概率空间内强制正则化更有用。
Our modifications are based on below considerations: 1) With face anti-spoofing taken as a binary classification is- sue, confusion across categories would not excessively af- fect the discriminability of the PA feature on differentiating live vs. spoofing samples. 2) Face samples related to the same subject would usually cluster in the feature space, and implementing confusion on all samples could compact and homogenize the whole feature distribution (see Fig. 3), thus benefiting generalization performance. 3) As a binary classification problem of simpler structure, regularizing the model within the feature space would be more useful than imposing regularization within the output probabilistic space.
图4:SSF的贡献平衡过程。 FC层中较暗的颜色表示对分类的贡献较高,而较浅的颜色表示较低的贡献。 每个网格代表一个SSF。 Ltpc和Lanti之间的权衡游戏可以平衡SSF对最终决策的贡献。
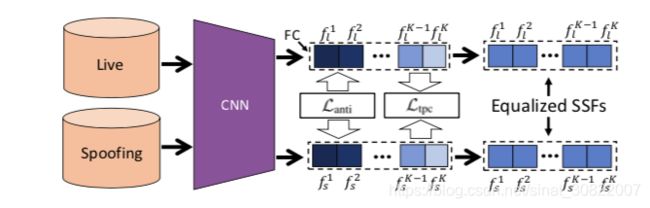
Figure 4: The contribution-balanced process of SSFs. Darker color in the FC layer indicates a higher contribu- tion to the classification while lighter color indicates lower. Each grid represents an SSF. The trade-off game between Ltpc and Lanti can balance the contributions of SSFs to the final decision.
我们的Ltpc可以有效地提高其PA表示的普遍性。可以理解如下。假设PA表示中有K个分量,每个对应一个欺骗模式,称为这项任务的欺骗模式特征(SSF)。如如图4所示,不同的SSF对最终决定有不同程度的贡献。如果我们将活体和欺骗样本的特征分别定义为Fl =(f1l,f2l,...,fKl)和Fs =(f1s,f2s,...,fKs),其中fil是活体样本的第i个SSF,fis是欺骗样本的第i个SSF。 SSF基于他们对活体和欺骗分类的重要性排名。一方面,L anti为了更好的分类旨在扩大在F1和Fs之间距离。另一方面Ltpc试图缩小F1和之间的差异Fs。f1l / s对于活体和欺骗样本来说拥有最大的差异贡献值,但它将受到Ltpc的最大削弱。而不太重要的SSF的贡献,例如fK-1 l / s和fK l / s ,将被L增强以抵消分类的损失。在这种权衡中,所有SSF的贡献趋于均衡,这意味着决策中涉及更多的欺骗模式,而不仅仅是针对训练集的一些强大的欺骗模式。这可以有效地缓解过度拟合风险。如果某些欺骗模式在测试中消失,那么其他模式仍然可以做出公平的决定,确保CNN不会过度适应某些特征。
Our Ltpc can effectively improve the generalizability of PA representations. This can be understood as follows. Suppose there are K components in the PA representations, each corresponding to one spoof pattern, which is called a Spoof-pattern Specific Feature (SSF) in this work. As shown in Fig. 4, different SSFs contribute differently to the final decision. If we define the feature for a live and a spoofing sample as Fl = (f1l ,f2l ,...,fKl ) and Fs = (f1s,f2s,...,fKs ), respectively, where fi is the ith SSF of the live sample and fi ls is the ith SSF of the spoofing sample. The SSFs are ranked based on their importance to the classification of live vs. spoofing. On one hand, Lanti aims to enlarge the distance between Fl and Fs for better discrimination. On the other hand, Ltpc attempts to narrow the difference between Fl and Fs. As f1l/s contributes the most to the differentiation of live and spoofing samples, it will be impaired the most by Ltpc. However, the contributions of less important SSFs, such as fK−1 and fK , will be enhanced by L to offset l/s l/s anti the impaired discriminative ability. In this trade-off game, the contributions of all SSFs tend to be equalized, meaning more spoof patterns are involved in the decision rather than just a couple of strong spoof patterns specific to the train- ing set. This could effectively alleviate overfitting risks. If some spoof patterns disappear in testing, a fair decision can still be achieved by other patterns, ensuring CNN would not overfit to some specific features.
3.3. Fast Domain Adaptation
除了提出的TPC损失平衡每种欺骗模式之外,我们还应用FDA来减少特征空间中的域迁移以进一步提高我们框架的可通用性。通常,图像包含两个组件:内容和外观[21]。 外观信息(例如,颜色,局部结构)构成来自特定领域的图像的风格,并且主要由CNN的底层中的特征表示[13]。 对于面部反欺骗,面部样本数据之间的域差异可能会在特征空间中引入分布差异并且会损害反欺骗性能。 在这里,我们使用FDA来减轻域变化带来的负面影响。 FDA包括图像变换网络f(·),其从给定图像x:y = f(x)生成合成图像y,以及损失网络φ(·),计算其内容重建损失L content 和域重建损失 L domain。
(译者注:【21】可以参考 https://blog.csdn.net/z0n1l2/article/details/81677178 以及
https://blog.csdn.net/sunyao_123/article/details/81294724
)
Besides the proposed TPC loss that balances the contribution of each spoof pattern, we also apply FDA to reduce domain shift in the feature space to further improve the gen- eralizability of our framework.
Generally, an image contains two components: content and appearance [21]. The appearance information (e.g., colors, localised structures) makes up the style of images from a certain domain and is mostly represented by features in the bottom layers of CNN [13]. For face anti-spoofing, the domain variance among face samples may introduce the distribution dissimilarity in the feature space and hurt anti- spoofing performance. Here, we employ the FDA to alleviate negative effects brought by domain changes. The FDA consists of an image transformation network f(·) that generates a synthetic image y from a given image x: y = f (x), and a loss network φ(·) that computes content reconstruction loss L content and domain reconstruction loss L domain.
图5:FDA的结果示例。 中间列中图像的左上和右下图像是预期要传输的目标域图像。 奇数行的图像来自MSU-MFSD; 偶数行的图像来自Replay-Attack。

Figure 5: Example results by FDA. The upper left and bot- tom right images of the images in the middle column are the target-domain images expected to be transferred. Images of odd rows are from MSU-MFSD; images of even rows are from Replay-Attack.
设φj(·)为网络φ(·)的第j层,其形状为Cj×Hj×Wj。 当内容重构损失在输入图像y中偏离输入x时,内容重建损失会对输出图像y进行惩罚。 因此,我们最小化y和x的特征表示之间的欧几里德距离:
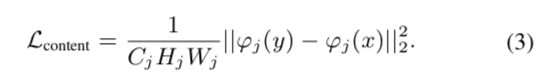
域重建损失使输出图像y与目标域图像yd具有相同的域。 然后,我们最小化Y和yd的Gram矩阵之间差异的平方Frobenius范数:

通过将φj重新整形为矩阵κ,Gj =κκT/ CjHjWj来计算Gram矩阵。 然后通过求解以下目标函数生成最优图像y ˆ:

其中P是网络f(·)的最佳参数,x是内容图像,y = f(x),yd是目标域图像,λc和λs是标量。 通过求解方程(5),x被转移到y,保留x的内容和yd的域。
图5显示了我们的一些域转移样本。 从训练数据中采样目标域图像。 第4.2节中提供了关于w /和FDA之间的特征多样性的详细分析。
Let φj(·) be the jth layer of φ(·) with the shape of Cj × Hj × Wj. The content reconstruction loss penalizes the output image y when it deviates in content from the input x. We thus minimize the Euclidean distance between the feature representations of y and x:

The domain reconstruction loss enables the output image y to have the same domain with the target-domain image yd. We then minimize the squared Frobenius norm of the difference between the Gram matrices of y and yd:
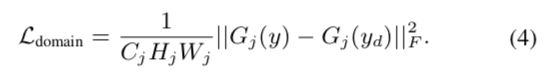
The Gram matrix is computed by reshaping φj into a matrix κ, Gj = κκ T /CjHjWj. Then the optimal image yˆ is generated by solving the following objective function:

where P is the optimal parameters of network f (·), x is the content image, y = f(x), yd is the target-domain image, and λc and λs are scalars. By solving Eqn. (5), x is trans- ferred to yˆ, preserving the content of x with the domain of yd.
Fig. 5 shows some of our domain transferred samples. The target-domain image is sampled from the training data. Detailed analysis on the feature diversity between domains w/ and w/o FDA is provided in Sec. 4.2.
4. Experiments
4.1. Experimental Setup
Datasets. We evaluate GFA-CNN on five face anti- spoofing benchmarks: CASIA-FASD [28], Replay-Attack [8], MSU-MFSD [26], Oulu-NPU [7] and SiW [19]. CASIA-FASD and MSU-MFSD are small datasets, con- taining 50 and 35 subjects, respectively. Oulu-NPU and SiW are high-resolution databases published very recently. Oulu-NPU contains 4 testing protocols: Protocol 1 evalu- ates the environment condition variations; Protocol 2 exam- ines the influences of different spoofing mediums; Protocol 3 estimates the effects of different input cameras; Protocol 4 considers all the challenges above. We conduct intradatabase tests on MSU-MFSD and Oulu-NPU, respectively. Cross-database tests are performed between CASIA-FASD vs. Replay-Attack and MSU-MFSD vs. Replay-Attack, re- spectively. The face recognition performance is evaluated on SiW, which contains 165 subjects with large variations in poses, illumination, expressions (PIE), and different dis- tances from subject to camera. The LFW, the most widely used benchmark for face recognition, is also used to evalu- ate the face recognition performance.
数据集。我们在五个面部反欺骗基准上评估GFA-CNN:CASIA-FASD [28],Replay-Attack [8],MSU-MFSD [26],Oulu-NPU [7]和SiW [19]。 CASIA-FASD和MSU-MFSD是小型数据集,分别包含50和35个科目。 Oulu-NPU和SiW是最近出版的高分辨率数据库。 Oulu-NPU包含4个测试协议:协议1评估环境条件的变化;协议2检查了不同欺骗媒介的影响;协议3估计了不同输入摄像机的影响;协议4包括了上述所有挑战。我们分别对MSU-MFSD和Oulu-NPU进行数据库内测试。跨数据库测试分别在CASA-FASD 与 Replay-Attack 和 MSU-MFSD与Replay-Attack之间进行。人脸识别性能在SiW上进行评估,其中包含165个受试者,其姿势,光照,表情(PIE)以及从受试者到相机的不同距离有很大差异。 LFW是最广泛使用的人脸识别基准,也用于评估人脸识别性能。
实施细节。 我们使用TensorFlow [1]实现GFA-CNN。 使用Adam优化器,学习率从0.0003开始,每2000步后衰减一半。 批量大小设置为32公式(1)中的λ1和λ2 分别设定为0.1和2.5e-5。 所有实验均根据数据集中提供的方案进行。 CNN层在VGG-face数据集上进行了预训练[22]。 考虑数据平衡,我们使用水平和垂直翻转对CASIA-FASD,MSU-MFSD和Replay-Attack训练集中的活体样本采用三倍,同时通过水平翻转使SiW训练集中的活体样本加倍。
Implementation Details. The proposed GFA-CNN is implemented with TensorFlow [1]. We use Adam optimizer with a learning rate beginning at 0.0003 and decaying half after every 2,000 steps. The batch size is set as 32. λ1 and λ2 in Eqn. (1) are set as 0.1 and 2.5e−5, respectively. All experiments are performed according to the protocols provided in the datasets. The CNN layers are pre-trained on the VGG-face dataset [22]. For data balance, we triple the live samples in the training set of CASIA-FASD, MSU- MFSD and Replay-Attack with horizontal and vertical flip- ping, while doubling the live samples in the training set of SiW by just flipping horizontally.
评估指标。 我们有两个评估协议,即测试内和交叉测试,分别测试来自训练集领域的样本,而不是来自训练集领域的样本。 我们使用以下指标报告结果。
测试内评估:等错误率(EER),攻击呈现分类错误率(APCER),善意呈现分类错误率(BPCER)和ACER =(APCER + BPCER)/ 2。 交叉测试评估:HTER。
Evaluation Metrics. We have two evaluation protocols, intra-test and cross-test, which test samples from and not from the domain of the training set, respectively. We report our results with the following metrics. Intra-test evaluation:
Equal Error Rate (EER), Attack Presentation Classification Error Rate (APCER), Bona Fide Presentation Classification Error Rate (BPCER) and, ACER=(APCER+BPCER)/2. Cross-test evaluation: HTER.
表1:消融研究(HTER%)。 +“表示使用相应的组件,而 - ”表示删除组件。 粗体数字是最好的结果。

Table 1: Ablation study (HTER %). +” means the corre- sponding component is used, while -” indicates removing the component. The numbers in bold are the best results.
4.2. Ablation Study
(译者注:ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study。说白了,ablation study就是一个模型简化测试,看看取消掉模块后性能有没有影响。根据奥卡姆剃刀法则,简单和复杂的方法能够达到一样的效果,那么简单的方法更好更可靠。)
我们进行消融分析,以揭示TPC损失和FDA在我们的框架中的作用。我们通过添加/消除TPC和FDA来重新训练建议的网络。如表格所示。 1,如果TPC被移除,MFSD的内部测试HTER分别下降2.9%(w / FDA)和4.1%(不含FDA)。由于Replay-Attack通常没有严重的过度拟合,因此在HTER上使用FDA,0.3%(w / FDA)和0.6%(不含FDA)时,改善的性能并不显着是合理的。
对于交叉测试,如果TPC被消融,对于MFSD→Replay1,HTER显着降低超过10%,对于Replay→MFSD,无论是否使用FDA,超过8%。通过使用TPC和FDA实现了最佳的交叉测试结果,表明FDA可以进一步提高所提出方法的普遍性。
为了评估w /和不含FDA的域之间的特征多样性,我们通过对称KL分歧来计算特征差异。类似于[21],我们将来自CNN的特征嵌入的信道的平均值表示为F.给定F的高斯分布,具有平均μ和方差σ2,域A和B之间的该信道的对称KL发散是:


将D(FiA || FiB)表示为第i个通道的对称KL散度。 然后将层的平均特征发散定义为

其中C是该层的通道号。 该度量测量域A和B的特征分布之间的距离。我们计算CNN模型中每个层的特征偏差以进行比较。 特别是,我们分别从MSU-MFSD和Replay-Attack中随机选择5,000个面部样本。 每个数据集都被视为一个域。 然后将这些样品送入预先训练的VGG16 [24]模型,以计算Eqn后各层的KL散度。(8)。 比较结果如图6所示。可以看出,在FDA中,MSU-MFSD与Replay-Attack之间的特征差异显着减小。
图6:MSU-MSFD和重放攻击之间的特征差异比较。 x轴上的数字对应于VGG16的CNN层。
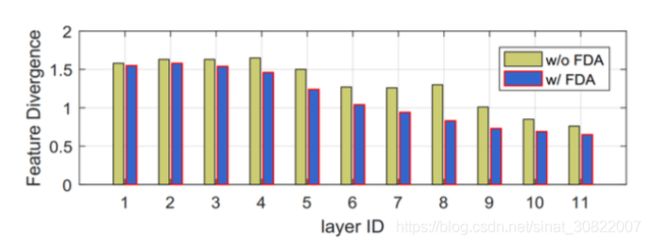
Figure 6: Feature divergence comparison between MSU- MFSD and Replay-Attack. The numbers on x-axis corre- spond to the CNN layer of VGG16.
We perform ablation analysis to reveal the role of TPC loss and FDA in our framework. We retrain the proposed network by adding/ablating TPC and FDA. As shown in Tab. 1, if TPC is removed, the HTER of intra-test on MFSD drops by 2.9% (w/ FDA) and 4.1% (w/o FDA), respectively. Since Replay-Attack is usually free of severe overfitting, it is reasonable to see the improved performance is not sig- nificant when using FDA, 0.3% (w/ FDA) and 0.6% (w/o FDA) on HTER.
For cross-test, if TPC is ablated, the HTER dramatically decreases by over 10% for MFSD → Replay1, and over 8% for Replay → MFSD, no matter FDA is used or not. The best cross-test result is achieved by using both TPC and FDA, indicating FDA can further improve the generalizabil- ity of the proposed method.
To evaluate the feature diversity between domains w/ and w/o FDA, we calculate the feature divergence via symmet- ric KL divergence. Similar to [21], we denote the mean value of a channel from the feature embedding of CNN as F. Given a Gaussian distribution of F, with mean μ and variance σ2, the symmetric KL divergence of this channel between domain A and B is

Denote D(FiA||FiB) as the symmetric KL divergence of the ith channel. Then the average feature divergence of the layer is defined as
where C is the channel number of this layer. This metric measures the distance between the feature distributions of domain A and B. We calculate the feature divergence of each layer in a CNN model for comparison. In particular, we randomly select 5,000 face samples from MSU-MFSD and Replay-Attack, respectively. Each dataset is considered as one domain. These samples are then fed to a pre-trained VGG16 [24] model to calculate the KL divergence at each layer following Eqn. (8). The comparison results are shown in Fig. 6. As can be seen, with the FDA, the feature diver- gence between MSU-MFSD and Replay-Attack is signifi- cantly reduced.
4.3. Face Anti-spoofing Evaluation
内部测试。我们对MSU-MFSD和Oulu-NPU进行内部测试。表2显示了我们的方法与MSU-MFSD上其他最先进方法的比较。对于Oulu-NPU,我们参考[2]中的面部反欺骗竞赛结果,并使用每个协议中最好的两个进行比较。所有结果均在表 3。
如表2所示,GFA-CNN达到7.5%的EER,在所有比较方法中排名第3。考虑到GFA-CNN不是为了在测试内设置中追求高性能而盲目设计,这个结果是令人满意的。在我们的实验中,我们发现所提出的TPC损失可能会略微降低测试内性能,主要是因为TPC损失会损害训练数据集中几个最强SSF的贡献。这些数据集特定功能的削弱可能反过来影响测试内的性能(但是,它们可能会提高交叉测试的性能)。根据表3,我们的方法在4个协议中的3个中实现了最低的ACER。对于最具挑战性的协议4,我们实现了8.9%的ACER,比最佳表现低1.1%。

Intra-Test. We perform intra-test on MSU-MFSD and Oulu-NPU. Tab. 2 shows the comparisons of our method with other state-of-the-art methods on MSU-MFSD. For Oulu-NPU, we refer to the face anti-spoofing competition results in [2] and use the best two for each protocol for com- parison. All results are reported in Tab. 3.
As shown in Tab. 2, GFA-CNN achieves the EER of 7.5%, ranking the 3rd among all the compared methods. This result is satisfactory considering GFA-CNN is not de- signed blindly to pursue high performance in the intra- test setting. In our experiments, we find the proposed TPC loss may slightly decrease the intra-test performance, mainly because TPC loss impairs the contributions of several strongest SSFs w.r.t the training datasets. The weaken- ing of these dataset-specific features may in turn affect the intra-test performance (however, they may improve the per- formance in cross-test). According to Tab. 3, our method achieves the lowest ACER in 3 out of 4 protocols. For the most challenging protocol 4, we achieve the ACER of 8.9%, which is 1.1% lower than the best performer.
交叉测试。为了证明GFA-CNN的强大普遍性,我们通过与其他现有技术进行比较,对CASIA-FASD,Replay-Attack和MSU-MFSD进行交叉测试。我们采用最广泛使用的交叉测试设置:CASIA-FASD vs. Replay-Attack和MSU-MFSD vs. Replay-Attack,并在Tab中报告比较结果。 表4可以看出,GFA-CNN在交叉测试中达到了最低的HTER:CASIA→重播,MFSD→重播和重播→MFSD。特别是对于重播→MFSD,与最好的最先进技术相比,GFA-CNN将交叉测试HTER降低了8.3%。然而,我们也观察到GFA-CNN与Replay Attack→CASIA-FASD的最佳方法相比具有相对更差的HTER。这可能是由于当要传输的源域图像的分辨率远高于目标域图像的分辨率时,FDA的“质量下降”。在Replay-Attack→CASIA-FASD的交叉测试中,目标域图像选自Replay-Attack,低分辨率为320×240。但是,CASIA-FASD包含大量高分辨率图像这种“分辨率差距”导致FDA的“质量下降”,如图7中最右边的图像所示。
Cross-Test. To demonstrate the strong generalizability of GFA-CNN, we perform cross-test on CASIA-FASD, Replay-Attack, and MSU-MFSD by comparing with other state-of-the-arts. We adopt the most widely used cross- test settings: CASIA-FASD vs. Replay-Attack and MSU- MFSD vs. Replay-Attack, and report comparison results in Tab. 4. As can be seen, GFA-CNN achieves the lowest HTERs in cross-test: CASIA → Replay, MFSD → Replay and Replay → MFSD. Especially for Replay → MFSD, GFA-CNN reduces the cross-testing HTER by 8.3% com- pared with the best state-of-the-art.
However, we also observe GFA-CNN has a relatively worse HTER compared with the best method on Replay At- tack → CASIA-FASD. This is probably due to the “qual- ity degradation” by FDA when the resolution of a source- domain image to be transferred is much higher than that of the target-domain image. During the cross-testing on Replay-Attack → CASIA-FASD, the target-domain image is selected from Replay-Attack with a low-resolution of 320 × 240. However, CASIA-FASD contains quite a number of images with high-resolution of 720 × 1280. Such a “resolution gap” leads to a “quality degradation” of FDA, as shown in the rightmost image in Fig. 7.
表4:CASIA-FASD,重播攻击和MSU-MFSD的交叉测试结果(HTER%)。 - “表示相应的结果未提供用。 粗体数字是最好的结果。
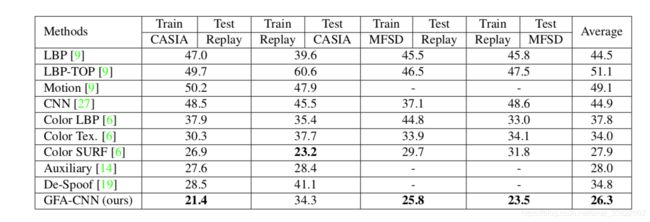
Table 4: Cross-test results (HTER %) on CASIA-FASD, Replay-Attack, and MSU-MFSD. -” indicates the corresponding result is unavailable. The numbers in bold are the best results.
图7:FDA以不同的分辨率转移的结果。 左上角图像是目标域图像。 对于每个块的其他图像,左边的图像是原始图像,右边是转移的图像。 位于每个图像左上角的绿色数字表示分辨率。

Figure 7: Results transferred by FDA with different res- olutions. The top left image is the target-domain image. For other images of each block, the left one is the original image, and the right is the transferred image. The green number located at the top left of each image indicates the resolution.
4.4. Face Recognition Evaluation
我们进一步评估了我们的GFA-CNN在SiW和LFW上的人脸识别性能。由于我们的方法不是专门针对人脸识别,我们只采用VGG-16作为基线。在LFW上,我们遵循提供的协议来执行测试。在SiW上,我们使用90个科目进行训练,另外75个科目进行测试,这是它的默认数据分割。该数据集还提供与每个主题相对应的正面遗留面部图像。在测试阶段,我们选择测试集的每个主题作为图库面的遗留图像,并使用测试集中的所有图像(包括实时和欺骗)作为探测面。
人脸验证的ROC曲线如图8所示。可以观察到,GFA-CNN在LFW上分别达到VGG16的竞争结果,分别为97.1%和97.6%。然而,当在SiW上测试时,GFA-CNN的精确度下降远低于VGG16:GFA-CNN的准确度降低了4.5%,而VGG16降低了14%。性能下降主要是由于欺骗介质的面部再现,其中一些更精细的面部细节可能会丢失。然而,与VGG16相比,GFA-CNN仍然达到了令人满意的性能。这主要是因为面部反欺骗和面部识别任务相互增强,使得面部识别学习的表现对欺骗模式不那么敏感。

We further evaluate the face recognition performance of our GFA-CNN on SiW and LFW. Since our method is not targeted specifically at face recognition, we only adopt VGG-16 as the baseline. On LFW, we follow the provided protocol to perform testing. On SiW we use 90 subjects for training and the other 75 subjects for testing, which is its default data splitting. This dataset also provides a frontal legacy face image corresponding to each subject. At the testing phase, we select the legacy image w.r.t each subject of the testing set as the gallery faces, and use all images in the testing set (including both live and spoofing) as the probe faces.
The ROC curves of face verification are shown in Fig. 8. As can be observed, GFA-CNN achieves competitive results to VGG16 on LFW, 97.1% and 97.6%, respectively. How- ever, when testing on SiW, the declined accuracy of GFA- CNN is much lower than that of VGG16: the accuracy of GFA-CNN reduces by 4.5%, while VGG16 drops by 14%. The degraded performance is mainly due to face reproduc- tion by spoofing mediums, in which some of the finer facial details might be lost. However, GFA-CNN still achieves satisfactory performance compared with VGG16. This is mainly because the face anti-spoofing and face recognition tasks mutually enhance each other, making the representa- tions learned for face recognition less sensitive to spoof patterns.
4.5. Discussions on Multi-task Setting
在本小节中,我们将研究多任务学习如何影响面部反欺骗的模型性能。我们在没有面部识别分支的情况下重新训练我们的模型,保持超参数不变并使用与GFA-CNN相同的协议进行评估。从实验中,我们观察到多任务训练略微降低了面部反欺骗的测试内性能(分别在MSU-MFSD和Replay-Attack上下降2.5%和0.3%)。这是合理的,因为单个模型学会执行两个不同的任务。然而,与单一任务训练相比,实现了两个优点。首先,训练过程变得更加稳定,anti-loss损失逐渐减少,而不是经过单一任务训练后的一些步骤急剧下降,这表明多任务设置有助于克服过度拟合。其次,如图8所示,多任务训练有助于学习对用于面部识别的欺骗模式不太敏感的面部表示。这主要得益于在卷积层中共享参数,提供更通用的融合特征。
In this subsection, we investigate how the multi-task learning affects model performance for face anti-spoofing. We retrain our model without the face recognition branch, keep hyper-parameters unchanged and evaluate with the same protocol as the GFA-CNN. From the experiments, we observe the multi-task training slightly decreases the intra- test performance of face anti-spoofing (dropping 2.5% and 0.3% on MSU-MFSD and Replay-Attack, respectively). This is reasonable, since the single model learns to perform two different tasks. However, two advantages are achieved compared with the single task training. Firstly, the training process becomes more stable with the Anti-loss decreasing gradually, rather than dropping sharply after some steps by single task training, suggesting multi-task setting can help overcome overfitting. Secondly, as shown in Fig. 8, multi- task training helps learn face representations less sensitive to spoof patterns for face recognition. This mainly benefits from sharing parameters in the convolutional layers, giving more generic fusion features.
5. Conclusion
本文提出了一种新颖的CNN模型,以相互促进的方式共同修饰人脸识别和面对反欺骗。 为了学习面部反欺骗的更具概括性的演示攻击(PA)表示,我们提出了一种新的总成对混淆(TPC)损失来平衡每个欺骗模式的贡献,防止PA表示过度拟合到数据集特定的欺骗模式。 快速域适应(FDA)也被纳入我们的框架,以减少来自不同领域的面部样本的分布不相似性,进一步增强PA表示的稳健性。 面部反欺骗和人脸识别数据集的广泛实验表明,我们的GFA-CNN不仅在交叉测试中实现了面部反欺骗的卓越性能,而且还实现了高精度的面部识别。
This paper presents a novel CNN model to jointly ad- dress face recognition and face anti-spoofing in a mutual boosting way. In order to learn more generalizable Pre- sentation Attack (PA) representations for face anti-spoofing, we propose a novel Total Pairwise Confusion (TPC) loss to balance the contribution of each spoof pattern, preventing the PA representations from overfitting to dataset-specific spoof patterns. The Fast Domain Adaptation (FDA) is also incorporated into our framework to reduce distribution dis- similarity of face samples from different domains, further enhancing the robustness of PA representations. Extensive experiments on both face anti-spoofing and face recognition datasets show that our GFA-CNN achieves not only superior performance for face anti-spoofing on cross-tests, but also high accuracy for face recognition.
Acknowledgement References
- [1] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, et al. Tensor- flow: a system for large-scale machine learning. In OSDI, volume 16, pages 265–283, 2016. 5
- [2] Z. Boulkenafet, J. Komulainen, Z. Akhtar, A. Benlam- oudi, D. Samai, S. E. Bekhouche, A. Ouafi, F. Dornaika, A. Taleb-Ahmed, L. Qin, et al. A competition on generalized software-based face presentation attack detection in mobile scenarios. In IJCB, pages 688–696, 2017. 6
- [3] Z. Boulkenafet, J. Komulainen, and A. Hadid. Face anti- spoofing based on color texture analysis. In ICIP, pages 2636–2640, 2015. 6
- [4] Z.Boulkenafet,J.Komulainen,andA.Hadid.Facespoofing detection using colour texture analysis. T-IFS, 11(8):1818– 1830, 2016. 6
- [5] Z. Boulkenafet, J. Komulainen, and A. Hadid. Face anti- spoofing using speeded-up robust features and fisher vector encoding. IEEE Signal Processing Letters, 24(2):141–145, 2017. 1, 2, 6
- [6] Z. Boulkenafet, J. Komulainen, and A. Hadid. On the gen- eralization of color texture-based face anti-spoofing. Image and Vision Computing, 77:1–9, 2018. 7
- [7] Z.Boulkenafet,J.Komulainen,L.Li,X.Feng,andA.Hadid. Oulu-npu: A mobile face presentation attack database with real-world variations. In FG, pages 612–618, 2017. 4
- [8] I.Chingovska,A.Anjos,andS.Marcel.Ontheeffectiveness of local binary patterns in face anti-spoofing. In BIOSIG, 2012. 1, 2, 4
- [9] T.deFreitasPereira,A.Anjos,J.M.DeMartino,andS.Mar- cel. Can face anti-spoofing countermeasures work in a real world scenario? In ICB, pages 1–8, 2013. 7
- [10] A. Dubey, O. Gupta, P. Guo, R. Raskar, R. Farrell, and N. Naik. Pairwise confusion for fine-grained visual classi- fication. In ECCV, pages 70–86, 2018. 3
- [11] L. Engstrom. Fast style transfer. https://github. com/lengstrom/fast-style-transfer/, 2016. 2
[12] G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller. La- beled faces in the wild: A database forstudying face recog- nition in unconstrained environments. In ECCVW, 2008. 3
[13] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, pages 694–711, 2016. 4
[14] A. Jourabloo, Y. Liu, and X. Liu. Anti-spoofing via noise modeling. arXiv:1807.09968, 2018. 7
Face de-spoofing:
arXiv preprint
[15] K. Kollreider, H. Fronthaler, M. I. Faraj, and J. Bigun. Real- time face detection and motion analysis with application in liveness assessment. T-IFS, 2(3):548–558, 2007. 2
[16] J.Komulainen,A.Hadid,andM.Pietikainen.Contextbased face anti-spoofing. In BTAS, pages 1–8, 2013. 1, 2
[17] H. Li, P. He, S. Wang, A. Rocha, X. Jiang, and A. C. Kot. Learning generalized deep feature representation for face anti-spoofing. T-IFS, 13(10):2639–2652, 2018. 2
[18] H. Li, W. Li, H. Cao, S. Wang, F. Huang, and A. C. Kot. Unsupervised domain adaptation for face anti-spoofing. T- IFS, 13(7):1794–1809, 2018. 1
[19] Y. Liu, A. Jourabloo, and X. Liu. Learning deep models for face anti-spoofing: Binary or auxiliary supervision. In CVPR, pages 389–398, 2018. 1, 2, 4, 7
[20] G. Pan, L. Sun, Z. Wu, and S. Lao. Eyeblink-based anti- spoofing in face recognition from a generic webcamera. 2007. 2
[21] X. Pan, P. Luo, J. Shi, and X. Tang. Two at once: Enhanc- ing learning and generalization capacities via ibn-net. arXiv preprint arXiv:1807.09441, 2018. 4, 5
[22] O. M. Parkhi, A. Vedaldi, A. Zisserman, et al. Deep face recognition. In BMVC, volume 1, page 6, 2015. 5
[23] M. Sajjad, S. Khan, T. Hussain, K. Muhammad, A. K. San- gaiah, A. Castiglione, C. Esposito, and S. W. Baik. Cnn- based anti-spoofing two-tier multi-factor authentication sys- tem. Pattern Recognition Letters, 2018. 3
[24] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 6
[25] X. Tan, Y. Li, J. Liu, and L. Jiang. Face liveness detection from a single image with sparse low rank bilinear discrimi- native model. In ECCV, pages 504–517, 2010. 1
[26] D. Wen, H. Han, and A. K. Jain. Face spoof detection with image distortion analysis. T-IFS, 10(4):746–761, 2015. 4, 6 [27] J. Yang, Z. Lei, and S. Z. Li. Learn convolutional neural net-
work for face anti-spoofing. arXiv preprint arXiv:1408.5601,
2014. 1, 2, 7 [28] Z. Zhang, J. Yan, S. Liu, Z. Lei, D. Yi, and S. Z. Li. A face
antispoofing database with diverse attacks. In ICB, pages 26–31, 2012. 4