小样本学习(FSL):Few-shot Learning 综述【模型微调(Fine-tunning)、数据增强、迁移学习(Transfer Learning)】
分类非常常见,但如果每个类只有几个标注样本,怎么办呢?
比如:我们打造了一个智能对话开发平台以赋能第三方开发者来开发各自业务场景中的任务型对话,其中一个重要功能就是对意图进行分类。大量平台用户在创建一个新对话任务时,并没有大量标注数据,每个意图往往只有几个或十几个样本。
面对这类问题,有一个专门的机器学习分支——Few-shot Learning 来进行研究和解决。
一、小样本学习方法
1、基于模型微调的小样本学习
基于模型微调的方法是小样本学习较为传统的方法,该方法通常在大规模数据上预训练模型,在目标小样
本数据集上对神经网络模型的全连接层或者顶端几层进行参数微调,得到微调后的模型.若目标数据集和源数
据集分布较类似,可采用模型微调的方法.
为了使微调后的小样本分类模型取得较好的效果,使用何种微调方法需要被考虑.Howard 等人[14]在 2018
年提出了一个通用微调语言模型(universal language model fine-tuning,简称 ULMFit).与其他模型不同的是,此方
法使用了语言模型而非深度神经网络.该模型分为3个阶段:(1) 语言模型预训练;(2) 语言模型微调;(3) 分类器
微调.该模型的创新点在于改变学习速率来微调语言模型,主要体现在两个方面.
- 传统方法认为,模型每一层学习速率相同;而ULMFit中,语言模型的每一层学习速率均不相同.模型底 层表示普遍特征,这些特征不需要很大调整,所以学习速率较慢;而高层特征更具有独特性,更能体现
出任务和数据的独有特征,于是高层特征需要用更大的学习速率学习.总体看来,模型底层到最高层
学习速率不断加快. - 对于模型中的同一层,当迭代次数变化时,自身学习率也会相应地产生变化.作者提出了斜三角学习
率的概念,当迭代次数从 0 开始增加时,学习速率逐渐变大;当迭代次数增长到某个固定值时,此时已
经学习到了足够知识,固定值之后的学习率又开始逐步下降.
论文从纵向和横向两个维度学习速率的变化对语言模型进行微调,让模型更快地在小样本数据集上收敛;
同时,让模型学习到的知识更符合目标任务.另外,Nakamura 等人[42]提出了一种微调方法,主要包含以下几个机 制:(1) 在小样本类别上再训练的过程使用更低的学习率;(2) 在微调阶段使用自适应的梯度优化器;3) 当源数
据集和目标数据集之间存在较大差异性时,可以通过调整整个网络来实现.
基于模型微调的方法较简单,但是在真实场景中,目标数据集和源数据集往往并不类似,采用模型微调的方
法会导致模型在目标数据集上过拟合.为解决模型在目标数据集上过拟合的问题,两种解决思路被提出:基于数
据增强和基于迁移学习的方法.
2、基于数据增强的小样本学习
小样本学习的根本问题在于样本量过少,从而导致样本多样性变低.在数据量有限的情况下,可以通过数据
增强(data augmentation)[43]来提高样本多样性.数据增强指借助辅助数据或辅助信息,对原有的小样本数据集进 行数据扩充或特征增强.数据扩充是向原有数据集添加新的数据,可以是无标签数据或者合成的带标签数据;特
征增强是在原样本的特征空间中添加便于分类的特征,增加特征多样性.基于上述概念,本文将基于数据增强的
方法分为基于无标签数据、基于数据合成和基于特征增强的方法三种.接下来,就这 3 种方法分别介绍小样本
学习的进展.
2.1 基于无标签数据的方法
基于无标签数据的方法是指利用无标签数据对小样本数据集进行扩充,常见的方法有半监督学习和直推式学习等。
在半监督学习的思想下,同时受到 CNN 可迁移性的启发,提出利用一个附加 的无监督元训练阶段,让多个顶层单元接触真实世界中大量的无标注数据.通过鼓励这些单元学习无标注数据
中低密度分离器的 diverse sets,捕获一个更通用的、更丰富的对视觉世界的描述,将这些单元从与特定的类别集 的联系中解耦出来(也就是不仅仅能表示特定的数据集).
直推式学习可看作半监督学习的子问题.直推式学习假设未标注数据是测试数据,目的是在这些未标记数据上取得最佳泛化能力.
2.2 基于数据合成的方法
基于数据合成的方法是指为小样本类别合成新的带标签数据来扩充训练数据,常用的算法有生成对抗网络(generative adversarial net)
Mehrotra 等人[54]将 GAN 应用到小样本学习中,提出了生成对抗残差成对网 络(generative adversarial residual pairwise network)来解决单样本学习问题.算法使用基于 GAN 的生成器网络对
不可见的数据分布提供有效的正则表示,用残差成对网络作为判别器来度量成对样本的相似性,如图 1 的流程
图所示.
2.3 基于特征增强的方法
以上两种方法都是利用辅助数据来增强样本空间,除此之外,还可通过增强样本特征空间来提高样本的多
样性,因为小样本学习的一个关键是如何得到一个泛化性好的特征提取器.
3、基于迁移学习的小样本学习
基于模型微调的方法在源数据集和目标数据集分布大致相同时有效,分布不相似时会导致过拟合问题
迁移学习则解决了这个问题.迁移学习只需要源领域和目标领域存在一定关联,使得在源领域和数据中学习到的知识和特征能够帮助在目标领域训练分类模型,从而实现知识在不同领域之间的迁移.
一般来说,源领域和目标领域之间的关联性越强,那么迁移学习的效果就会越好.
在迁移学习中,数据集被划分为 3 部分:
- 训练集(training set):源数据集,一般包含大量的标注数据;
- 支持集(support set):目标领域中的训练样本,包含少量标注数据;
- 查询集(query set):目标领域中的测试样本;
根据迁移学习的方法不同,本文将其分为基于度量学习、基于元学习和基于图神经网络的方法
3.1 基于度量学习的方法
3.2 基于元学习的方法
元学习(meta-learning)也叫做学会学习(learning to learn)[84],是机器学习领域一个前沿的研究框架,针对于
解决模型如何学习的问题.元学习的目的是让模型获得一种学习能力,这种学习能力可以让模型自动学习到一
些元知识.元知识指在模型训练过程之外可以学习到的知识,比如模型的超参数、神经网络的初始参数、神经
网络的结构和优化器等[85].在小样本学习中,元学习具体指从大量的先验任务中学习到元知识,利用以往的先验
知识来指导模型在新任务(即小样本任务)中更快地学习.
3.3 基于图神经网络的方法
在计算机科学中,图作为一种数据结构,由点和边构成.图这种数据结构,具有表现力强和展示直观的优点.随着近年来机器学习的兴起,机器学习逐渐被应用到图的分析上.图神经网络是一种基于深度学习的处理图领域信息的模型,由于其较好的性能和可解释性,它最近已成为一种广泛应用的图分析方法[96].图神经网络有很多种变体,比较常用的有图卷积神经网络(graph convolutional network)、门控图神经网络(gated graph neural network)和图注意力网络(graph attention network)等.
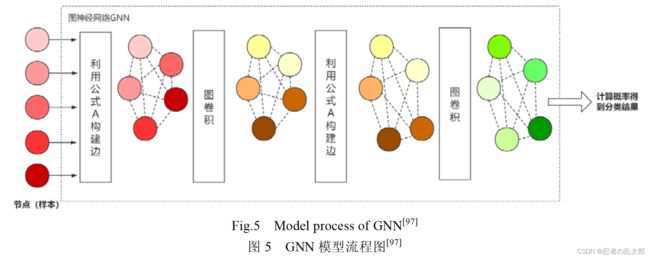
Garcia 等人[97]在 2018 年使用图卷积神经网络实现小样本图像分类.在图神经网络里,每一个样本被看作图 中的一个节点,该模型不仅学习每个节点的嵌入向量,还学习每条边的嵌入向量.卷积神经网络将所有样本嵌入
到向量空间中,将样本向量与标签向量连接后输入图神经网络,构建每个节点之间的连边;然后通过图卷积更新
节点向量,再通过节点向量不断更新边的向量,这就构成了一个深度的图神经网络.如图 5 所示,5 个不同的节点
输入到GNN中,根据公式A构建边,然后通过图卷积更新节点向量,再根据A更新边,再通过一层图卷积得到最
后的点向量,最后计算概率.
上面的方法是对图中的节点进行分类,Kim 等人[98]从另一个方面进行考虑,对图中的边进行分类.首先,对 图中的边特征向量进行初始化,边的特征向量有两维:第 1 维表示相连的两个节点属于同一类的概率,第 2 维表
示它们不属于同一类的概率.随后,用边的特征向量更新节点向量,边的两维特征分别对应节点的类内特征和类
间特征.经过多次更新后,对边进行二分类,得到两个节点是否属于同一类.
二、数据集与实验
在小样本图像分类任务中,一些标准数据集被广泛使用.单样本学习最常用的是 Omniglot 数据集[100],小样
本学习最常用的数据集是 miniImageNet[101].除此之外,常用数据集还有 CUB[102]、tieredImageNet[50]等,同时, CIFAR- 100、Stanford Dogs 和 Stanford Cars 常用作细粒度小样本图像分类.接下来对每个数据集进行简单介绍.
(1) Omniglot 包含 50 个字母的 1 623 个手写字符,每一个字符都是由 20 个不同的人通过亚马逊的
Mechanical Turk[103]在线绘制的. (2) miniImageNet 是从 ImageNet[104]分割得到的,是 ImageNet 的一个精缩版本,包含 ImageNet 的 100 个类
别,每个类别含有 600 个图像.一般 64 类用于训练,16 类用于验证,20 类用于测试.
(3) tieredImageNet 是 Mengye 等人[50]在 2018 年提出的新数据集,也是 ImageNet 的子集.与 miniImageNet 不同的是,tieredImageNet 中类别更多,有 608 种. (4) CUB(caltech-UCSD birds)是一个鸟类图像数据集,包含 200 种鸟类,共计 11 788 张图像.一般 130 类用
于训练,20 类用于验证,50 类用于测试.
(5) CIFAR-100 数据集:共 100 个类,每个类包含 600 个图像,分别包括 500 个训练图像和 100 个测试图像.
CIFAR-100 中的 100 个子类所属于 20 个父类,每个图像都带有一个子类标签和一个父类标签.
(6) Stanford Dogs:一般用于细粒度图像分类任务.包括 120 类狗的样本共计 20 580 个图像,一般 70 类用
于训练,20 类用于验证,30 类用于测试.
(7) Stanford Cars:一般用于细粒度图像分类任务.包括 196 类车的样本共计 16 185 个图像,一般 130 类用
于训练,17 类用于验证,49 类用于测试.
本文选取一些著名模型在上述数据集上的实验结果进行总结,所有方法都选取了5-way 1-shot(即5个类别, 每个类别具有 1 个样本)和 5-way 5-shot(即 5 个类别,每个类别具有 5 个样本)的结果进行对比.图像分类的任务
一般使用 CNN 作为嵌入网络,常用的有 VGG,Inception 和 Resnet 等.具体见表 1.
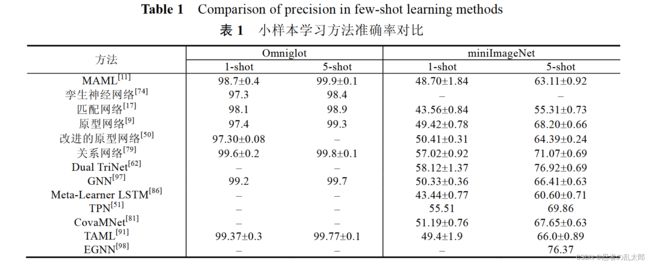
表 1 选取了 Omniglot 和 miniImageNet 数据集的实验结果作为对比参考,因为其他的数据集使用次数较少, 所以在此不多加讨论.由表 1 可看出,每个数据集中 5-shot 的准确率均比 1-shot 的高.表明训练数据越多,学到的 特征也越多,分类效果越好.在 Omniglot 数据集上,所有模型在 1-shot 场景下的准确率都达到了 97%,在 5-shot 任务下的准确率均达到了 98%,可提升空间较少;在 miniImageNet 数据集上,不同模型之间的提升较大,在 1-shot 任务下效果最好的模型比效果最差的准确率提升了 15%左右,在 5-shot 任务下准确率提升了高达 21%,表明在 此数据集上还有较大的提升空间.
三、总结、挑战、展望
1、小样本学习总结
由于真实世界的某些领域中样本量很少或标注样本很少,而样本标注工作会耗费大量时间和人力,近年来,
小样本学习逐渐成为人们重点关注的问题.本文介绍了图像分类和文本分类两个任务中小样本学习的研究进
展,总体上看,小样本图像分类已有了许多性能优异的算法模型,但小样本文本分类仍是个亟待解决的问题.根
据小样本学习方法的不同,本文将其分为基于模型微调、基于数据增强和基于迁移学习的方法这 3 类,其中,基
于数据增强的方法可以细分为基于无标签数据、基于数据合成和基于特征增强的方法这3种,基于迁移学习的
方法可以细分为基于度量学习、基于元学习和基于图神经网络的方法这 3 种.本文对以上几种方法做了总结,
并且比较了它们的优点和缺点,具体见表 2.

总体来说,小样本学习研究已有很大进展,但和人类分类准确率相比还有很大差距.为了解决基于模型微调
方法带来的过拟合问题,基于数据增强和基于迁移学习的方法被提出.基于数据增强的方法是对小样本数据集
进行数据扩充或特征增强,这种方法可以不对模型进行参数调整,但是容易引入噪声数据.基于迁移学习的方法
是将旧领域学到的知识迁移到新领域,并且不需要两者之间有很强的关联性,但关联性越强,迁移效果越好.在
基于迁移学习的方法中,基于度量学习的方法最简单、容易操作,只需要通过距离来衡量样本之间的相似度,但
是学习到的知识太少.基于元学习比基于度量学习的方法学习能力更强,可以学习到更多知识.基于图神经网络
的方法在 3种方法中展示最为直观、可解释性较强,但样本总数变大时,会导致计算复杂度增高.
2、小样本学习挑战
尽管近年来小样本学习已经得到深入研究,并且取得了一定进展,但仍面临着一些挑战.
(1) 强制的预训练模型[4]
在已有的小样本学习方法中,不管是基于模型微调的方法还是基于迁移学习的方法,都需要在大量的非目
标数据集上对模型进行预训练,致使“小样本学习”一定程度上变成个伪命题.因为模型的预训练依旧需要大量
标注数据,从本质上来看,与小样本学习的定义背道而驰.从根本上解决小样本问题,就要做到不依赖预训练模
型,可以研究利用其他先验知识而非模型预训练的方法.
(2) 深度学习的可解释性
由于深度学习模型本身是一个黑盒模型,在基于迁移学习的小样本深度学习模型中,人们很难了解到特征
迁移和参数迁移时保留了哪些特征,使得调整参数更加困难[105].提高深度学习的可解释性,能帮助理解特征迁移,在源领域和目标领域之间发现合适的迁移特征[106].在此方面已有了一些工作
(3) 数据集挑战
现有的小样本学习模型都需要在大规模数据上预训练,图像分类任务中已经有了 ImageNet 作为预训练数 据集,而文本分类中,缺少类似的预训练数据集,所以需要构建一个被各种任务广泛使用的小样本文本分类预训
练数据集.同时,在小样本图像分类任务中,miniImageNet和 omniglot是两个被广泛使用的标准数据集.但在小样 本文本分类任务中,不同工作所采用的目标数据集千差万别,有很多都是网上爬取的数据集.所以,构建一个适
用于文本分类任务的小样本目标数据集是需要考虑的问题.为解决这个问题,Han 等人[108]在 2018 年提出了一
个小样本关系抽取数据集 FewRel,其中包含 100 种分类,共 70 000 个实例,规模和 miniImageNet 相当.
(4) 不同任务之间复杂的梯度迁移[90]
在基于元学习的小样本学习方法中,从不同任务中学习元知识的过程梯度下降较慢.将模型迁移到新任务
中时,由于样本数量较少,所以期望模型能在目标数据集上快速收敛,在此过程中,梯度下降较快.针对基于元学
习的方法设计合理的梯度迁移算法,也是目前需要研究并亟待解决的问题.
(5) 其他挑战
在小样本文本分类中,不同语言的分类难度不同.英文的文本分类比较成熟,但是中文分类由于分词等问
题,目前还不是很成熟.另外,跨语种或者多语种的文本分类是一个难题,由于源语言与目标语言的特征空间相
差甚大,同时,各国的语言、文字又包含了不同的语言学特征,这无疑加大了跨语言文本分类的难度[105].
3、小样本学习展望
通过对当前小样本学习研究进展的梳理,可以展望未来小样本学习的发展方向.
- 在数据层面,尝试利用其他先验知识训练模型,或者更好地利用无标注数据.为了使小样本学习的概
念更靠近真实,可以探索不依赖模型预训练、使用先验知识(例如知识图谱)就能取得较好效果的方法.
虽然在很多领域中标注样本数量很少,但真实世界中存在的大量无标注数据蕴含着大量信息,利用无
标注数据的信息训练模型,这个方向也值得深入研究. - 基于迁移学习的小样本学习面临着特征、参数和梯度迁移的挑战.为更好地理解哪些特征和参数适
合被迁移,需要提高深度学习的可解释性;为使模型在新的领域新任务中快速收敛,需要设计合理的
梯度迁移算法. - 针对基于度量学习的小样本学习,提出更有效的神经网络度量方法.度量学习在小样本学习中的应用
已经相对成熟,但是基于距离函数的静态度量方法改进空间较少,使用神经网络来进行样本相似度计
算将成为以后度量方法的主流,所以需要设计性能更好的神经网络度量算法. - 针对基于元学习的小样本学习,设计更好的元学习器.元学习作为小样本学习领域刚兴起的方法,目
前的模型还不够成熟.如何设计元学习器,使其学习到更多或更有效的元知识,也将是今后一个重要
的研究方向. - 针对基于图神经网络的小样本学习,探索更有效的应用方法.图神经网络作为这几年比较火热的方
法,已经覆盖到很多领域,并且可解释性强、性能好,但是在小样本学习中应用的模型较少.如何设计图
网络结构、节点更新函数和边更新函数等方面,值得进一步探究. - 尝试不同小样本学习方法的融合.现有小样本学习模型都是单一使用数据增强或迁移学习的方法,今
后可以尝试将二者进行结合,从数据和模型两个层面同时进行改进,以达到更好的效果.同时,近年来,
随着主动学习(active learning)[109]和强化学习(reinforcement learning)[110]框架的兴起,可以考虑将这些
先进框架应用到小样本学习上.
参考资料:
小样本学习(Few-shot Learning)综述
Generalizing from a Few Examples: A Survey on Few-Shot Learning
什么是小样本学习?这篇综述文章用166篇参考文献告诉你答案
赵凯琳,靳小龙,王元卓.小样本学习研究综述.软件学报,2021,32(2):349−369. http://www.jos.org.cn/1000-9825/ 6138.htm