谭传奇-individual_project_word_frequency
首先,印证了闫导的一句话,一星期都在写软工作业
其实也没有那么夸张了,装Win7花了1天,装VS2012加熟悉Win7花了接近2天
真正写作业的时间也没有那么长
言归正传
我估计大概用5个小时左右,实际前前后后大大小小时间加起来6、7个小时吧
算法与实现都比较简单
时间主要花费在了对C#的不熟悉上
Dictionary是第一次用,ArrayList的sort也是第一次用,也是第一次实现Icompare接口,查资料花了不少的时间
PS: 发现MSDN真是个好东西,特别方便
首先说算法吧,想到的有2个
1、把所有word(包括重复的)排序,相同的(Extendedmode里相同的即相似的)肯定在按word排序后是连续的,相邻的两两之间比较一下,就可以确定word的value,再对value排序,时间复杂度nlogn,但在相同的词比较多的情况下,内存使用很大
2、对所有word,依次判断是否已存在,已存在直接把value+1,不存在则添加。
实现方法:用C++实现,map,Key是word,能在nlogn内首先单词的查找与插入,然后对所有单词进行排序,排序也是nlogn的时间
由于C++实现查询所有文件夹与文件等操作不是很方便,于是想用C#,C#有SortedDictionary可以实现与map一样的功能
但C#中,Dictionary是hash的,hash比平衡树要快一点,所以最后直接使用Dictionary了
至于大小写不敏感以及字符串处理,都是细节问题了,不再赘述了
先贴一个性能分析吧
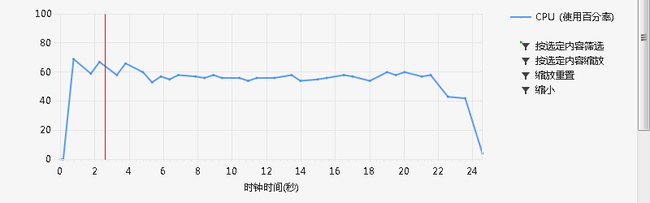
 (这是数据规模)
(这是数据规模)
性能分析时 有这样一个提醒
![]()
由于在字符串处理中,使用了+,即string+string,貌似很浪费时间
改成StringBuilder,使用StringBuilder.Append,运行时间加快了1/4

而对另一个提醒,研究了好久也没研究明白,还望知道的牛人给予解答
通过这次个人作业,首先对VS2012有了一定的了解,尤其是性能分析
读文件夹、读文件,这些在之前,我们只学习算法或数据结构是不曾涉及到的
这次作业算法很容易想到也很容易实现,但不会读入什么也做不了
不过这些东西,包括Dictionary、ArrayList等,都是很容易在网上查阅到的
相同的问题已经有很多人碰到过了,查一下再研读一下别人的代码,理解也挺容易的
还有的话,也是加深了对C#的理解吧,特别是C#库中很方便的集合或方法
最后程序写的还是偏C风格的,不是很面向对象,比如两个需求,其实可以用两个类实现接口,这样有三个需求也好实现,这一点可以改进
最后感谢一下Anran、Skyjoker两位队友,在实现Icompare时给了非常宝贵的建议