SkYjoKEr - 词频统计工程总结T博特别版
听说按照T博流量算分,怒转至T博。
一、首先是对于需求和基本方案:
重新列一下需求,国行中文版。
Word 单词定义:
i.至少含有三个字符、且开头三个字符必须是字母;
eg.hao123 == word;123hao!=word
ii.不包含任何非字母或者数字的字符;
助教后来说这个本质就是认为除了字母和数字以外都算分隔符的意思。
iii.对于同一个单词的计数,大小写不敏感;
eg.File == FILE == file
扩展模式下进一步:
两个单词仅有尾部数字不同时,认为是同一个单词。打印时并不忽略数字。
eg. win985 == win98 == win1
输出要求:按出现次数排序从大到小排序,每行打印。
<word>: number
<word>为该计数单词在统计文件中出现的ascii码顺序最靠前形式。出现次数相同按 <word>的ascii码序排序。
基本方案:仔细看发现自己对需求理解给错了,人家说的是不区分大小写计词,但是排序的时候还是按ascii码序排,然后不同大小写版本以最靠前的ascii码出现值为准。那这样使用二叉树排序插入+合并排序的方案就没戏了,因为二叉树key一旦定了就不改了,最后还是要重排ascii序。所以还是学乖了,用哈希加快排。
二、上版中存在的问题和修正
1、没有把世界上一切除了英文字母和数字以外的字符都当作分隔符,导致各种中文乱码都进来了,这次直接不用string.Split()分词,自己动手读把。
2、没有记录输入单词的原始形式,只按照比对key全部输出小写版本。嗯就是说每次添加单词还得记录单词的原始形式,包括扩展模式下的数字后缀。同时要对已存在的最前原始形式进行比对,更新ascii码最靠前的原始形式。
3、没有做开始3个字符是否是字母的检查。
三、实现一下程序
1、首先自己写以下读取器。基本步骤
a.从文件按行读取,因为回车一定是分隔符所以这个没压力
b.按逐字符检查是否是数字或者字母,
if 是,追加到缓冲
else 否,认为监测到分隔符,检查缓冲区字符串是否符合word定义。
if 是,添加单词
else 否,抛弃缓冲区
一开始用的string作为缓冲区,后来注意到string的cat比较花时间,使用char[]作为缓冲区,代码最后是这样:
#endif using (StreamReader sr = new StreamReader(file)) { while (!sr.EndOfStream) { // read line; string line = sr.ReadLine() + ' '; char[] word = new char[WORD_MAXLENGTH]; int word_cur = 0; // parse word from line; for (int i = 0; i < line.Length; i++) { if (char.IsLetter(line[i]) || char.IsNumber(line[i])) { // appendix letter word[word_cur++] = line[i]; } else { int j; for (j = 0; j < word_cur && j < word.Length && j < WORD_MINLENGTH; j++ ) { if (char.IsNumber(word[j])) break; } if (j == WORD_MINLENGTH) { AddWord(new string(word, 0, word_cur)); } word_cur = 0; #if DEBUG count++; #endif } } } } #if DEBUG Console.WriteLine(count + " Words Counted"); #endif }
嗯,这样比Split快,而且修正了错误。
2、在网上查了资料,看到关于List.sort()和快排的帖子http://www.pin5i.com/showtopic-24424.html。学习受教了。
不过人家写的这个快排貌似略长。我用了自己以前写的C++版的快排,改了一下,然后加上了小串改用插入排序的改进。但是我试了试好像并不是明显比我之前的合并排序快,有两次还慢了,难道我快排又写史了……
class QuickSort { static Random rand = new Random(); // ISort by Glede static void ISort<T>(T[] list, int left, int right, Comparison<T> comparison) { for(int i = left; i < right - 1; i++) { int min = i; for (int j = i + 1; j < right; j++) { if (comparison(list[j], list[min]) < 0) min = j; } T temp = list[i]; list[i] = list[min]; list[min] = temp; } } // QuickSort by Glede static void QSort<T>(T[] list, int left, int right, Comparison<T> comparison) { int length = right - left; int border = left + rand.Next() % length; T temp = list[border]; list[border] = list[left]; int i = left; int j = right-1; while (i < j){ for (; i < j && comparison(list[j], temp) >= 0; j--) ; if( i == j) break; else list[i++] = list[j]; for (; i < j && comparison(list[i], temp) <= 0 ; i++) ; if( i == j) break; else list[j--] = list[i]; } list[i] = temp; if( i - left >= 10 ) QSort(list, left, i, comparison); else ISort(list, left, i, comparison); if( right - i >= 10) QSort(list, i + 1, right, comparison); else ISort(list, i + 1, right, comparison); } public static void Sort<T>(T[] list, Comparison<T> comparison) { if (list.Length >= 10) QSort(list, 0, list.Length, comparison); else ISort(list, 0, list.Length, comparison); } }
后来听安然说C#里有快排,感觉又给跪了。
3、写个WordInfo,基本记录方法是记录key识别键、display打印形式、count出现次数。普通模式下key是输入的形式key的ToUpper()或者ToLower(),扩展模式还要先过滤后缀数字。
建立哈希表,一个Dictionary<string, WordInfo>worddict。worddict的key即WordInfo.key。
添加单词的步骤:
a.从输出的string建立一个新的 WordInfo wi,根据wi.key去哈希表里搜
b.使用worddict.TryGetValue测试是否存在wi.key
if 否,添加这个key, WordInfo
else 是,将存在的Value更新一下,count++,如果wi.display的ascii码序更靠前,则display更新为wi.display。
象征性地贴代码,之所以要贴我只是因为SortedDictionary我也试试开过了,但是我不会用……:
public void AddWord(string word) { WordInfo wi = new WordInfo(word, mode); // added to word list tree #if HASH string key = wi.GetKey(); WordInfo value; if (hashlist.TryGetValue(key, out value)) value.update(wi); else hashlist.Add(key, wi); #else // old codes using BTree #endif return; }
哈希真快啊真快啊真快。
小插曲:一开始用的 key 是 char[],结果尼玛hash出来每个char[]都不一样,133MB的数据输出了一个90+MB的txt……
4、打印什么的用原来的就可以了。事实上这样这个工程应该这样就结束了,也就是可以用了。但是这个东西要做性能测试的。
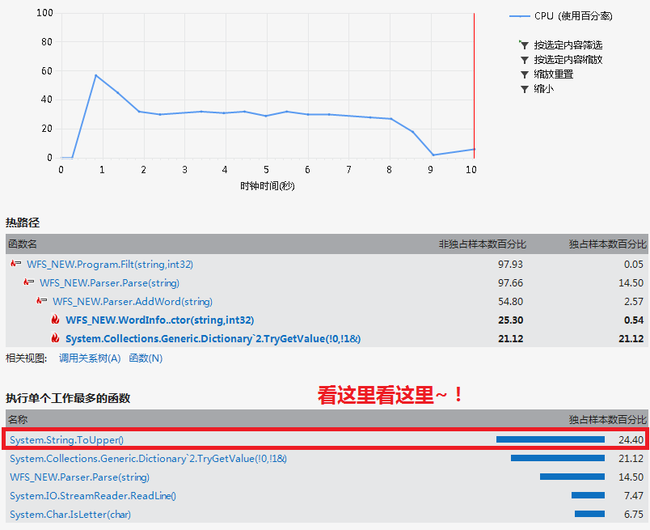
嗯,肯定是这样的……。这个事情还可以考虑到hash到相同的单词,程序都要干一件很讨厌的事情,要试试比对一下display。每次比对都是一个比较字符串啊,而且大部分情况下这个字符串很可能是相等的,那就是从头比到尾。不过这好像并不关系到为什么它大部分时间是在ToUpper()...
中场休息:
我认为这个程序当然是那有改进的余地的,而且我一开始也不打算使用这个基本的记录方式,每次检测到相同单词都要再比一个字符串太蛋疼了,因为我们在产生Key的时候,一定会经过一个ToUpper()或者ToLower(),而比较display的过程实质上比较的只不过是两个display的大小写。这很蛋疼。所以我一开始就是用的一个改进的单词记录方法。
5、改进的单词记录方法:
WordInfo中包含一个key识别键,这个识别键其实包含了单词的字母信息,那么只需要再有一个指定其大小写的信息,就可以还原为它的输入状态,也就是display。那么key是怎么来的呢?key是我们的输入状态string.toLower() (或者 toUpper()来的)。做这件事情的时候我们实际上已经得到了它每个字符大小写的信息了。由于大小写只是01状态,那么用一个uint可以记录一个32个字符长的单词的大小写信息,一个ulong可以记录64个字符长的单词的大小写信息。我认为一般uint就够用了,英文单词应该没有那么太长的,程序猿应该更不喜欢打很长的标识符。(虽然后来测试的时候被数据抽了一巴掌,原来真的有32位以上长度的单词……好吧,我用了ulong)
对大小写信息进行编码之后,我们得到了一个uint(或者ulong),编码顺序要对,使得这个数字的大小能够代表大小写先后顺序,这样每次在更新WordInfo的时候,得到更靠前的ascii码通常只需要比较两个uint的大小(或者ulong = = 讨厌的ulong),这就达到了优化的目的——至少理论上是这样。
然后考虑一下扩展模式下的数字后缀,这个东西和大小写不一样,虽然它是数字,但它依然是一个字符串,0001和01不一样,不得已会需要用一个string sufNum去记录它,也需要在更新的时候增加一步判断。这个事情不是特别麻烦,而且必须得干。
最后,在记录完成之后的排序需要用到的是它的最后显示形式,需要从大小写信息和key和numSuf来解码还原一个我们记录的、ascii码最靠前的输入形式,成为我们输出的display,我们还是需要一个string display来记录这个结果以加快对display的多次访问。
那么经过这样的设计一个改进的WordInfo出炉了。象征性地贴一下代码大概什么样子:
class WordInfo { public char[] key; public string sufNum; public int count; public string display; #if INT64 public ulong caseValue; #else public uint caseValue; #endif public WordInfo(string word, int mode) { char[] wordkey; caseValue = 0; sufNum = string.Empty; count = 1; display = null; // seperate suffix numbers int i = word.Length; if (mode == Program.MODE_EXTEND) { for (i = word.Length; i > Parser.WORD_MINLENGTH; i--) { if (!char.IsNumber(word[i - 1])) { break; } } if (i != word.Length) { sufNum = word.Substring(i); } } // encode caseValue wordkey = new char[i]; int currentValue = 1; for (i--; i >= 0; i--) { if (char.IsLower(word[i])) { #if INT64 caseValue += (ulong)(1 * currentValue); #else caseValue += (uint)(1 * currentValue); #endif wordkey[i] = word[i]; } else { #if INT64 caseValue += (ulong)(0 * currentValue); #else caseValue += (uint)(0 * currentValue); #endif wordkey[i] = char.ToLower(word[i]); } currentValue *= 2; } key = wordkey; } public static int CompareKey(WordInfo a, WordInfo b) { // compare a.key b.key // not for Dictionary } public static int CompareCaseValue(WordInfo a, WordInfo b) { // compare a.GetDisplay() b.GetDisplay() } public static int CompareValue(WordInfo a, WordInfo b) { // compare count // if a.count == b.count compare ascii } public static int CompareValueReverse(WordInfo a, WordInfo b) { // compare count reverse // if a.count == b.count compare ascii (no need to reverse) } public void update(WordInfo value) { count += value.count; if( caseValue < value.caseValue) return; else if( caseValue > value.caseValue ) { caseValue = value.caseValue; sufNum = value.sufNum; return; } else if( sufNum.CompareTo(value.sufNum ) > 0 ) { sufNum = value.sufNum; } } public string GetKey() { return new string(key); } public string GetDisplay() {
if(display == null) { // decode display from key & caseValue & sufNum } return display; } }
6、性能测试
调试一通之后嗯,编解码没问题。然后理论上这能带来性能的提升,实际上我数学很差。必须要做一下实际的测试。
还是刚才那个测试数据,使用改进的记录方法:
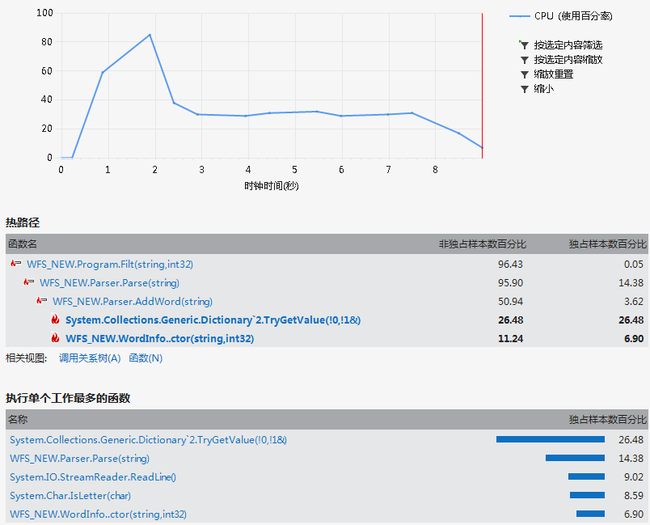
快的不多,总算快了哈。切换着各做5次测试,结果改进的记录方式都能快1秒左右,定性来说和理论还是符合的。数据大一般都能快一些,除非一样的词很少很少很少……
虽然优化的不多但是有一点总归是一点。。嗯。。
感谢队友Anran和Tjamie的提醒和数据对比。
后来:
Anran说Array.Sort()是快排,我试了试,貌似确实是,可是和我写的快排比略不稳定,有时进8秒,有时上12秒……。
可是Anran的代码没用这么干能杀入到8秒左右……。(牛X给跪)