集成学习上——统计学习建模流程
集成学习上——统计学习建模流程
- 机器学习的三大任务
-
- 1.回归
- 2.分类
- 3.无监督学习
- 构建机器学习项目的流程及对基本回归模型和衍生模型的掌握
-
- 一、以线性回归为例使用sklearn构建机器学习项目的完整流程
-
- 1.明确项目任务:回归/分类
- 2.搜集数据集并选择合适的特征
- 3.选择度量模型性能的指标
- 4.选择具体的模型并进行训练以优化模型
- 5.评估模型的性能并调参
- 二、基本的回归模型及其衍生模型
-
- 基本多元线性回归
- 多项式回归
- 广义可加模型(GAM)(待补充)
- 回归树
- 支持向量回归SVR(待补充)
- 机器学习模型优化基础
-
- 一、训练均方误差与测试均方误差
- 二、偏差和方差的分解权衡
- 三、测试误差估计与模型的特征提取
- 四、压缩估计(正则化)
-
- 岭回归
- Lasso
- 五、降维
- 六、对模型超参数进行调参
-
- 参数与超参数
- 网格搜索GridSearchCV():
- 随机搜索 RandomizedSearchCV() :
- 评估模型的性能并调参
-
- 网格搜索和随机网格搜索
- 混淆矩阵和ROC曲线(类别为两类)
机器学习的三大任务
机器学习是一个用数学模型理解数据的过程,在理解数据的过程中通过对模型参数的不断调整来实现对数据特征的一种刻画,这种刻画一方面是对数据信息的一种集中和筛选,另一方面可以被用来对具有类似数据特征的事件进行预测。
机器学习所利用的数据通常由一组向量组成,这组向量中的每个向量都是一个样本,每个向量共p+1个维度,前p个维度的每个维度我们称为一个特征,最后一个维度 我们称为因变量(响应变量)。根据数据是否有因变量。机器学习可分为有监督学习和无监督学习。在有监督学习中,又可根据因变量是连续型变量或离散型变量而分为回归和分类。对无监督学习而言,建模的主要目的是去学习数据本身的结构关系,根据寻找到的结构关系对数据进行划分等其他操作。

一般使用scikit-learn简称sklearn工具库来探索机器学习项目
1.回归
有监督学习中回归的例子,使用sklearn内置数据集Boston房价数据集。sklearn中所有内置数据集都封装在datasets对象内: 返回的对象有:
- data:特征X的矩阵(ndarray)
- target:因变量的向量(ndarray)
- feature_names:特征名称(ndarray)
# 引入相关科学计算包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use("ggplot")
import seaborn as sns
from sklearn import datasets
boston = datasets.load_boston() # 返回一个类似于字典的类
X = boston.data
y = boston.target
features = boston.feature_names
boston_data = pd.DataFrame(X,columns=features)
boston_data["Price"] = y
boston_data.head()

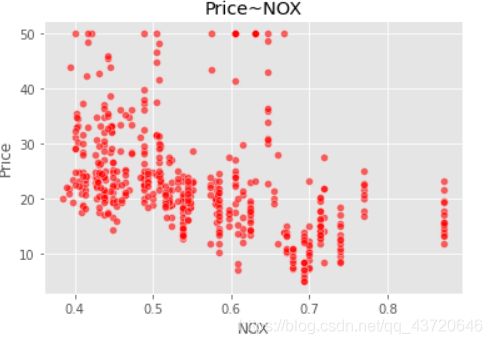
sns.scatterplot(boston_data['NOX'],boston_data['Price'],color="r",alpha=0.6)# alpha参数应该是控制图示红点的深浅
plt.title("Price~NOX")
plt.show()

2.分类
鸢尾花数据集
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
features = iris.feature_names
iris_data = pd.DataFrame(X,columns=features)
iris_data['target'] = y
iris_data.head()

# 可视化特征
marker = ['s','x','o']
for index,c in enumerate(np.unique(y)):#np.unique,去除数组中重复的数字,排序后输出 #enumerate生成器,同时生成索引和值
plt.scatter(x=iris_data.loc[y==c,"sepal length (cm)"],y=iris_data.loc[y==c,"sepal width (cm)"],alpha=0.8,label=c,marker=marker[c])
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.legend()
plt.show()
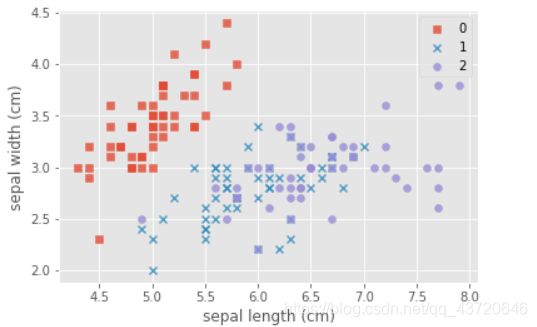

每种不同的颜色和点的样式为一种类型的鸢尾花,数据集有三种不同类型的鸢尾花。因此因变量是一个类别变量,因此通过特征预测鸢尾花类别的问题是一个分类问题。
3.无监督学习
可以使用sklearn生成符合自身需求的数据集
sklearn类和函数的参考网页
# 生成月牙型非凸集
from sklearn import datasets
x, y = datasets.make_moons(n_samples=2000, shuffle=True,
noise=0.05, random_state=None)
for index,c in enumerate(np.unique(y)):
plt.scatter(x[y==c,0],x[y==c,1],s=7)
plt.show()

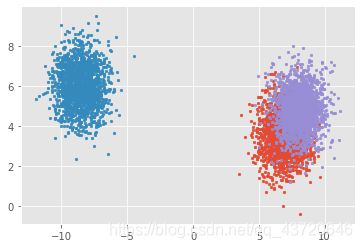
# 生成符合正态分布的聚类数据
from sklearn import datasets
x, y = datasets.make_blobs(n_samples=5000, n_features=2, centers=3)
for index,c in enumerate(np.unique(y)):
plt.scatter(x[y==c, 0], x[y==c, 1],s=7)
plt.show()
构建机器学习项目的流程及对基本回归模型和衍生模型的掌握
一、以线性回归为例使用sklearn构建机器学习项目的完整流程
- 明确项目任务:回归/分类
- 收集数据集并选择合适的特征。
- 选择度量模型性能的指标。
- 选择具体的模型并进行训练以优化模型。
- 评估模型的性能并调参。
1.明确项目任务:回归/分类
任务即为回归
2.搜集数据集并选择合适的特征
import pandas as pd
import numpy as np
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data #使用大写X,X包含多个小x
y = boston.target
features = boston.feature_names
boston_data = pd.DataFrame(X, columns=features)
boston_data["PRICE"] = y
boston_data.head()

3.选择度量模型性能的指标
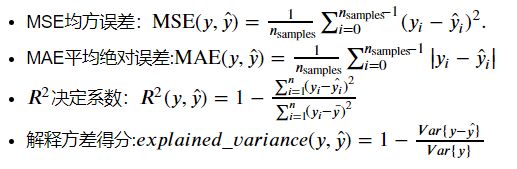
R2 = 1 - [(Sum of Squared Residuals / n) / Variancey_actual]
Explained Variance Score = 1 - [Variance(Ypredicted - Yactual) / Variancey_actual]
Variance(Ypredicted - Yactual) = (Sum of Squared Residuals - Mean Error) / n
(解释方差得分和R^2的区别就在于是否存在平均误差,即有偏和无偏)
4.选择具体的模型并进行训练以优化模型
这里选择线性回归模型
from sklearn import linear_model # 引入线性回归方法
lin_reg = linear_model.LinearRegression() # 创建线性回归的类
lin_reg.fit(X,y) # 输入特征X和因变量y进行训练
print("模型系数:",lin_reg.coef_) # 输出模型的系数
print("模型得分:",lin_reg.score(X,y)) # 输出模型的决定系数R^2
5.评估模型的性能并调参
这里可以通过决定系数看出模型的好坏,不过回归模型没有参数可以调整。
二、基本的回归模型及其衍生模型
基本多元线性回归
线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。通过构建损失函数,来求解损失函数最小时的参数
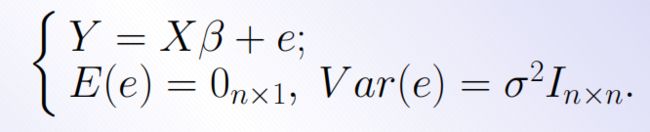



多项式回归
线性回归中,我们假设因变量与特征之间的关系是线性关系,这样的假设使得模型很简单,但是缺点也是显然的,那就是当数据存在非线性关系时,我们使用线性回归模型进行预测会导致预测性能极其低下,因为模型的形式本身是线性的,无法表达数据中的非线性关系。我们一个很自然的想法就是去推广线性回归模型,使得推广后的模型更能表达非线性的关系。

交互项问题


- 两个连续变量构造的交互项
- 两个虚拟变量构造的交互项
- 连续变量与虚拟变量构造的交互项
- 模型低次项的检验必须在高次项(交互项)检验前完成
- 若引入交互项后,即使低次项不显著也要保留
广义可加模型(GAM)(待补充)
通过一些变换,让原本不服从线性关系的响应变量解释变量,转换成线性关系,广义可加模型GAM实际上是线性模型推广至非线性模型的一个框架,在这个框架中,每一个变量都用一个非线性函数来代替,但是模型本身保持整体可加性。GAM模型不仅仅可以用在线性回归的推广,还可以将线性分类模型进行推广。具体的推广形式是:

回归树





树模型的优缺点:
- 树模型的解释性强,在解释性方面可能比线性回归还要方便。
- 树模型更接近人的决策方式。 树模型可以用图来表示,非专业人士也可以轻松解读。
- 树模型可以直接做定性的特征而不需要像线性回归一样哑元化。
- 树模型能很好处理缺失值和异常值,对异常值不敏感,但是这个对线性模型来说却是致命的。
- 树模型的预测准确性一般无法达到其他回归模型的水平,但是改进的方法很多。
支持向量回归SVR(待补充)
机器学习模型优化基础
1、训练均方误差与测试均方误差
2、偏差和方差的分解权衡
3、测试误差估计与模型的特征提取
- 测试误差估计:训练误差修正AIC-BIC、交叉验证
- 特征提取:逐步回归、随机森林
4、压缩估计(正则化)
- 通过增加偏差,减小参数估计值,降低方差,从而降低均方误差
- lasso是特征选取的一种方法
5、降维
- 降维思路
- 主成分
- 因子分析
- 补七种降维方法
遗留问题:
1.自变量个数多于样本量的时候,为什么X^tX不可逆
2.讲岭回归惩罚项选择的时候,回归模型的参数变小,模型方差就变小,可能中间有些推导
一、训练均方误差与测试均方误差
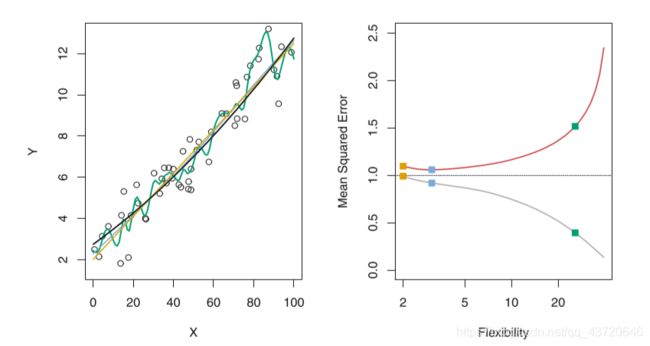

过拟合: 可以看出当模型的训练均方误差达到很小时,测试均方误差反而很大,但是我们寻找的最优的模型是测试均方误差达到最小时对应的模型,因此基于训练均方误差达到最小选择模型本质上是行不同的。正如上右图所示:模型在训练误差很小,但是测试均方误差很大时,我们称这种情况叫模型的过拟合。

二、偏差和方差的分解权衡
分解推导证明
偏差-方差分解(Bias-Variance Decomposition)是一种看待模型复杂度的观点。
给定学习目标和训练集规模,它可以把一种学习算法的期望泛化误差分解为三个非负项的和,即样本真实噪音noise、bias和 variance。
- bias 度量了某种学习算法的平均估计结果所能逼近学习目标的程度;(独立于训练样本的误差,刻画了匹配的准确性和质量:一个高的偏差意味着一个坏的匹配)偏差度量了学习算法期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
- variance 则度量了在面对同样规模的不同训练集时,学习算法的估计结果发生变动的程度。(相关于观测样本的误差,刻画了一个学习算法的精确性和特定性:一个高的方差意味着一个不稳定的匹配)。方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;
- noise 样本真实噪音是任何学习算法在该学习目标上的期望误差的下界;( 任何方法都克服不了的误差)表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度……
泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。 给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。-周志华《机器学习》
一般而言,增加模型的复杂度,会增加模型的方差,但是会减少模型的偏差,我们要找到一个方差–偏差的权衡,使得测试均方误差最。
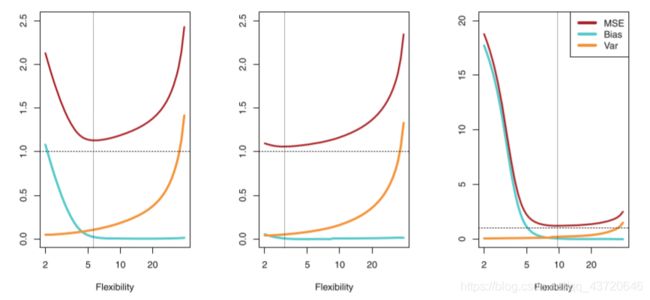
三、测试误差估计与模型的特征提取
在测试误差能够被合理的估计出来以后,我们做特征选择的目标就是:从p个特征中选择m个特征,使得对应的模型的测试误差的估计最小。对应的方法有:

向前逐步选择

随机森林/组合树 (Random Forests)
组合决策树通常又被成为随机森林,它在进行特征选择与构建有效的分类器时非常有用。一种常用的降维方法是对目标属性产生许多巨大的树,然后根据对每个属性的统计结果找到信息量最大的特征子集。例如,我们能够对一个非常巨大的数据集生成层次非常浅的树,每颗树只训练一小部分属性。如果一个属性经常成为最佳分裂属性,那么它很有可能是需要保留的信息特征。随机森林数据属性的统计评分会揭示与其它属性相比,哪个属性才是预测能力最好的属性。
四、压缩估计(正则化)
- 产生偏差,降低方差,从而缩减MSE
- Lasso特征提取
岭回归


Lasso

五、降维
目前为止,我们所讨论的方法对方差的控制有两种方式:一种是使用原始变量的子集,另一种是将变量系数压缩至零。但是这些方法都是基于原始特征 1,…, 得到的,现在我们探讨一类新的方法:将原始的特征空间投影到一个低维的空间实现变量的数量变少,如:将二维的平面投影至一维空间。机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。 y是数据点映射后的低维向量表达,通常y的维度小于x的维度(当然提高维度也是可以的)。f可能是显式的或隐式的、线性的或非线性的。目前大部分降维算法处理向量表达的数据,也有一些降维算法处理高阶张量表达的数据。**之所以使用降维后的数据表示是因为在原始的高维空间中,包含有冗余信息以及噪音信息,在实际应用例如图像识别中造成了误差,降低了准确率;而通过降维,我们希望减少 冗余信息 所造成的误差,提高识别(或其他应用)的精度。又或者希望通过降维算法来寻找数据内部的本质结构特征。**在很多算法中,降维算法成为了数据预处理的一部分,如PCA。事实上,有一些算法如果没有降维预处理,其实是很难得到很好的效果的。 (摘自:rosenor1博客)
方法有:
- 主成分分析
- 因子分析
补充:七种降维方法
六、对模型超参数进行调参
上述对模型的优化都是对模型算法本身的改进,比如:岭回归对线性回归的优化在于在线性回归的损失函数中加入L2正则化项从而牺牲无偏性降低方差。但是在L2正则化中参数 应该选择多少?是0.01、0.1、还是1?我们需要找到一种方式去找到最优参数。这在本质上是一个从集合中寻找最优参数的问题,是一个优化问题。第一反应是梯度下降法或牛顿法,但这两种方法能否解决问题前,我们需要先明确参数和超参数的概念。
参数与超参数
岭回归中的参数 和参数w代表着超参数与参数的概念。参数w是我们通过设定某一个具体的 后使用类似于最小二乘法、梯度下降法等方式优化出来的,我们总是设定了 是多少后才优化出来的参数w。因此,类似于参数w一样,使用最小二乘法或者梯度下降法等最优化算法优化出来的数我们称为参数。**类似于 一样,我们无法使用最小二乘法或者梯度下降法等最优化算法优化出来的数我们称为超参数。**模型参数是模型内部的配置变量,其值可以根据数据进行估计。
| 参数 | 超参数 |
|---|---|
| 进行预测时需要参数 | 超参数通常用于帮助估计模型参数。 |
| 参数定义了可使用的模型 | 超参数通常可以使用启发式设置 启发式搜索 |
| 参数是从数据估计或获悉的 | 超参数通常由人工指定 |
| 参数通常不由编程者手动设置 | 超参数经常被调整为给定的预测建模问题 |
| 参数通常被保存为学习模型的一部分 | |
| 参数是机器学习算法的关键,它们通常由过去的训练数据中总结得出 |
网格搜索GridSearchCV():
网格搜索的思想非常简单,比如你有2个超参数需要去选择,那你就把所有的超参数选择列出来分别做排列组合。举个例子: =0.01,0.1,1.0 和 =0.01,0.1,1.0 ,你可以做一个排列组合,即:{[0.01,0.01],[0.01,0.1],[0.01,1],[0.1,0.01],[0.1,0.1],[0.1,1.0],[1,0.01],[1,0.1],[1,1]} ,然后针对每组超参数分别建立一个模型,然后选择测试误差最小的那组超参数。换句话说,我们需要从超参数空间中寻找最优的超参数,很像一个网格中找到一个最优的节点,因此叫网格搜索。
网格搜索:sklearn.model_selection.GridSearchCV
网格搜索管道:Selecting dimensionality reduction with Pipeline and GridSearchCV
随机搜索 RandomizedSearchCV() :
网格搜索相当于暴力地从参数空间中每个都尝试一遍,然后选择最优的那组参数,这样的方法显然是不够高效的,因为随着参数类别个数的增加,需要尝试的次数呈指数级增长。有没有一种更加高效的调优方式呢?那就是使用随机搜索的方式,这种方式不仅仅高效,而且实验证明,随机搜索法结果比稀疏化网格法稍好(有时候也会极差,需要权衡)。参数的随机搜索中的每个参数都是从可能的参数值的分布中采样的。与网格搜索相比,这有两个主要优点:
- 可以独立于参数数量和可能的值来选择计算成本。
- 添加不影响性能的参数不会降低效率。
随机搜索:sklearn.model_selection.RandomizedSearchCV
SVR例子,使用管道调优
# 我们先来对未调参的SVR进行评价:
from sklearn.svm import SVR # 引入SVR类
from sklearn.pipeline import make_pipeline # 引入管道简化学习流程
from sklearn.preprocessing import StandardScaler # 由于SVR基于距离计算,引入对数据进行标准化的类
from sklearn.model_selection import GridSearchCV # 引入网格搜索调优
from sklearn.model_selection import cross_val_score # 引入K折交叉验证
from sklearn import datasets
boston = datasets.load_boston() # 返回一个类似于字典的类
X = boston.data
y = boston.target
features = boston.feature_names
pipe_SVR = make_pipeline(StandardScaler(),
SVR())
score1 = cross_val_score(estimator=pipe_SVR,
X = X,
y = y,
scoring = 'r2',
cv = 10) # 10折交叉验证
print("CV accuracy: %.3f +/- %.3f" % ((np.mean(score1)),np.std(score1)))
![]()
# 下面我们使用网格搜索来对SVR调参:
from sklearn.pipeline import Pipeline
pipe_svr = Pipeline([("StandardScaler",StandardScaler()),
("svr",SVR())])
param_range = [0.0001,0.001,0.01,0.1,1.0,10.0,100.0,1000.0]
param_grid = [{"svr__C":param_range,"svr__kernel":["linear"]}, # 注意__是指两个下划线,一个下划线会报错的
{"svr__C":param_range,"svr__gamma":param_range,"svr__kernel":["rbf"]}]
gs = GridSearchCV(estimator=pipe_svr,
param_grid = param_grid,
scoring = 'r2',
cv = 10) # 10折交叉验证
gs = gs.fit(X,y)
print("网格搜索最优得分:",gs.best_score_)
print("网格搜索最优参数组合:\n",gs.best_params_)

# 下面我们使用随机搜索来对SVR调参:
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform # 引入均匀分布设置参数
pipe_svr = Pipeline([("StandardScaler",StandardScaler()),
("svr",SVR())])
distributions = dict(svr__C=uniform(loc=1.0, scale=4), # 构建连续参数的分布
svr__kernel=["linear","rbf"], # 离散参数的集合
svr__gamma=uniform(loc=0, scale=4))
rs = RandomizedSearchCV(estimator=pipe_svr,
param_distributions = distributions,
scoring = 'r2',
cv = 10) # 10折交叉验证
rs = rs.fit(X,y)
print("随机搜索最优得分:",rs.best_score_)
print("随机搜索最优参数组合:\n",rs.best_params_)

评估模型的性能并调参
网格搜索和随机网格搜索
# 使用网格搜索进行超参数调优:
# 方式1:网格搜索GridSearchCV()
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
import time
start_time = time.time()
pipe_svc = make_pipeline(StandardScaler(),SVC(random_state=1))
param_range = [0.0001,0.001,0.01,0.1,1.0,10.0,100.0,1000.0]
param_grid = [{'svc__C':param_range,'svc__kernel':['linear']},{'svc__C':param_range,'svc__gamma':param_range,'svc__kernel':['rbf']}]
gs = GridSearchCV(estimator=pipe_svc,param_grid=param_grid,scoring='accuracy',cv=10,n_jobs=-1)
gs = gs.fit(X,y)
end_time = time.time()
print("网格搜索经历时间:%.3f S" % float(end_time-start_time))
print(gs.best_score_)
print(gs.best_params_)

# 方式2:随机网格搜索RandomizedSearchCV()
from sklearn.model_selection import RandomizedSearchCV
from sklearn.svm import SVC
import time
start_time = time.time()
pipe_svc = make_pipeline(StandardScaler(),SVC(random_state=1))
param_range = [0.0001,0.001,0.01,0.1,1.0,10.0,100.0,1000.0]
param_grid = [{'svc__C':param_range,'svc__kernel':['linear']},{'svc__C':param_range,'svc__gamma':param_range,'svc__kernel':['rbf']}]
# param_grid = [{'svc__C':param_range,'svc__kernel':['linear','rbf'],'svc__gamma':param_range}]
gs = RandomizedSearchCV(estimator=pipe_svc, param_distributions=param_grid,scoring='accuracy',cv=10,n_jobs=-1)
gs = gs.fit(X,y)
end_time = time.time()
print("随机网格搜索经历时间:%.3f S" % float(end_time-start_time))
print(gs.best_score_)
print(gs.best_params_)

混淆矩阵和ROC曲线(类别为两类)
# 混淆矩阵:
# 加载数据
df = pd.read_csv("/wdbc.data",header=None)
'''
乳腺癌数据集:569个恶性和良性肿瘤细胞的样本,M为恶性,B为良性
'''
# 做基本的数据预处理
from sklearn.preprocessing import LabelEncoder
X = df.iloc[:,2:].values
y = df.iloc[:,1].values
le = LabelEncoder() #将M-B等字符串编码成计算机能识别的0-1
y = le.fit_transform(y)
le.transform(['M','B'])
# 数据切分8:2
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
from sklearn.svm import SVC
pipe_svc = make_pipeline(StandardScaler(),SVC(random_state=1))
from sklearn.metrics import confusion_matrix
pipe_svc.fit(X_train,y_train)
y_pred = pipe_svc.predict(X_test)
confmat = confusion_matrix(y_true=y_test,y_pred=y_pred)
fig,ax = plt.subplots(figsize=(2.5,2.5))
ax.matshow(confmat, cmap=plt.cm.Blues,alpha=0.3)
for i in range(confmat.shape[0]):
for j in range(confmat.shape[1]):
ax.text(x=j,y=i,s=confmat[i,j],va='center',ha='center')
plt.xlabel('predicted label')
plt.ylabel('true label')
plt.show()

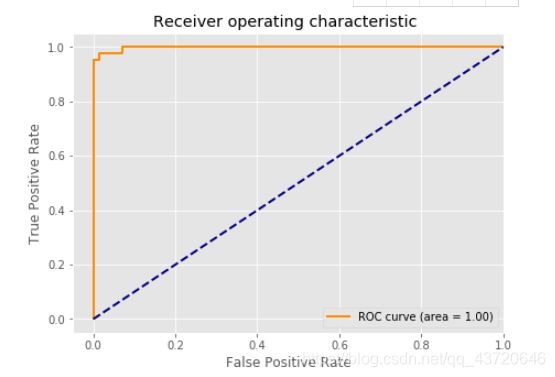
# 绘制ROC曲线:
from sklearn.metrics import roc_curve,auc
from sklearn.metrics import make_scorer,f1_score
scorer = make_scorer(f1_score,pos_label=0)
gs = GridSearchCV(estimator=pipe_svc,param_grid=param_grid,scoring=scorer,cv=10)
y_pred = gs.fit(X_train,y_train).decision_function(X_test)
#y_pred = gs.predict(X_test)
fpr,tpr,threshold = roc_curve(y_test, y_pred) ###计算真阳率和假阳率
roc_auc = auc(fpr,tpr) ###计算auc的值
plt.figure()
lw = 2
plt.figure(figsize=(7,5))
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc) ###假阳率为横坐标,真阳率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([-0.05, 1.0])
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic ')
plt.legend(loc="lower right")
plt.show()