湖仓一体,Hologres加速云数据湖DLF技术原理解析
Hologres(中文名交互式分析)是阿里云自研的一站式实时数仓,这个云原生系统融合了实时服务和分析大数据的场景,全面兼容PostgreSQL协议并与大数据生态无缝打通,能用同一套数据架构同时支持实时写入实时查询以及实时离线联邦分析。它的出现简化了业务的架构,为业务提供实时决策的能力,让大数据发挥出更大的商业价值。从阿里集团诞生到云上商业化,随着业务的发展和技术的演进,Hologres也在持续不断优化核心技术竞争力,为了让大家更加了解Hologres,我们计划持续推出Hologres底层技术原理揭秘系列,从高性能存储引擎到高效率查询引擎,高吞吐写入到高QPS查询等,全方位解读Hologres,请大家持续关注!
往期精彩内容:
- 2020年VLDB的论文《Alibaba Hologres: A cloud-Native Service for Hybrid Serving/Analytical Processing》
- Hologres揭秘:首次揭秘云原生Hologres存储引擎
- Hologres揭秘:Hologres高效率分布式查询引擎
- Hologres揭秘:高性能原生加速MaxCompute核心原理
- Hologers揭秘:优化COPY,批量导入性能提升5倍+
- Hologres揭秘:如何支持超高QPS在线服务(点查)场景
- Hologres揭秘:从双11看实时数仓Hologres高可用设计与实践
- Hologres揭秘:Hologres如何支持超大规模部署与运维
本期我们将带来Hologres高性能分析引擎加速查询云数据湖DLF的技术原理解析。
随着云服务被接受的程度不断提升,云用户日益愿意将其收集的数据存储在低成本的对象存储里,比如OSS,S3等。与此同时,基于云的数据管理方式也得到相应的推广,元数据也不断存储在阿里云DLF(Data Lake Formation)上。OSS和DLF的结合成就了一种新的数据湖搭建方式。这种基于云存储的数据湖集累的数据规模也不断增长,相应的湖仓一体的需求也孕育而生。湖仓一体架构基于开放格式的外部存储,以及高性能的查询引擎,让数据架构灵活、可扩展、可插拔。
Hologres在湖仓一体场景上与DLF天然无缝融合,无需数据导入导出就能实现加速查询由DLF管理存储在OSS的数据,全面兼容访问各种DLF支持文件格式,实现对PB级离线数据的秒级和亚秒级交互式分析。而这一切的背后,都离不开Hologres的DLF-Access引擎,通过DLF-Access实现对DLF元数据以及背后的OSS数据进行访问。另外,通过结合Hologres高性能分布式执行引擎HQE的处理,访问DLF/OSS的性能得到进一步提高。
Hologres加速查询DLF/OSS主要有以下几个优势:
- 高性能:可以直接对DLF/OSS数据加速查询,具有秒级响应的查询性能,在OLAP场景可以直接即席查询,满足绝大多数报表等分析场景。
- 低成本:用户在在DLF/OSS上存储的大量数据,无需迁移和导入数据而由Hologres直接进行访问。在享受云数据湖的低成本基础之上,也避免了数据迁移成本。
- 兼容性:可以实现以高性能和全兼容的方式访问各种DLF文件格式,支持CSV、Parquet、ORC、Hudi、Delta等格式(其中Hudi、Delta在1.3版本支持)。而这些文件格式又是通用数据湖兼容的。
湖仓一体架构介绍
如图所示是Hologres访问DLF/OSS的湖仓一体架构,可以看出整个架构非常简洁:
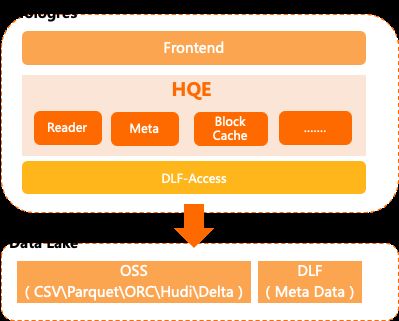
云数据湖里的数据存储在OSS,元数据存储在DLF。当Hologres执行一条Query去加速查询DLF/OSS的数据时,在Hologres端:
- Frontend接收SQL请求,并对SQL进行解析转化,然后通过RPC向DLF-Access请求获取Meta等相关信息。
- HQE(Hologres Engine)通过DLF-Access获取OSS/DLF具体的数据相关信息,再返回给Frontend。
其中DLF-Access是一个分布式的数据访问引擎,由多个平等进程组成,具备横向扩展能力。任何一个进程都可以完成两种角色:
- 处理Meta相关的请求,主要负责获取表、分区元数据、文件分片等功能。
- 负责具体读取或写入数据请求,涉及列裁剪,数据转换,数据封装等功能。
DLF外表引擎核心技术创新
基于DLF-Access的架构,能做到对DLF/OSS的数据高性能加速查询,主要是基于以下技术创新优势:
1)抽象分布式外表
结合DLF/OSS的分布式特性,Hologres抽象了一个分布式的外表,来支持访问包括传统或云数据湖的数据。
2)和 DLF Meta无缝互通
DLF-Access和Data Lake Formation的 Meta 无缝互通,可以做到 Meta 和 Data 实时获取,支持通过Import Foreign Schema命令,同步DLF的元数据到Hologres的外表,实现外表的自动创建。
3)向量化数据读取及转换
DLF-Access能充分利用数据湖列存文件的特点进行向量化的数据读取及转换,进一步提升性能。
4)返回共享式数据格式
DLF-Access转换后的数据格式为共享式的Apache Arrow格式。Hologres可以直接使用返回的数据,避免额外数据序列化及反序列化的开销。
5)Block模式IO
为了避免网络带来的延迟及负载,DLF-Access和Hologres的内部传输数据单位为block,默认为8192行数据。
6)编程语言隔离
Hologres是用C/C++开发出来的云原生OLAP引擎。DLF云数据湖和传统的开源数据湖高度兼容,而开源数据湖大多提供的是基于Java的库。使用独立的DLF-Access引擎架构可以隔离不同编程语种,即避免了原生引擎和虚拟机之间的高成本转换,又保持了对数据湖灵活多样的数据格式的支持。
DLF外表引擎升级到HQE
上面提到了Hologres通过DLF-Access进行查询加速DLF外表,查询时性能可以做到很好,但是和Hologres交互时中间会有一层RPC 交互,在数据量较大时网络会存在一定瓶颈。
因此基于Hologres已有的能力,Hologres V1.3版本对执行引擎进行了优化,支持Hologres HQE查询引擎直读DLF 表,在性能上得到进一步的提升,较早期版本读取有 30%以上的性能提升。
这主要得益于以下几个方面:
1) 节省了 DLF-Access中间 RPC 的交互,节省了一次额外的数据的重分布,在性能上得到进一步的提升。
2) 复用Hologres的Block Cache,这样多次查询时无需访问存储,避免存储IO,直接从内存访问数据,更好的加速查询。
3) 可以复用已有的Filter Pushdown(下推)能力,减少需要处理的数据量。
4) 在底层的IO层实现了预读和Cache,更进一步加速Scan时的性能。
对事务数据湖(Hudi、Delta)的支持
目前DLF支持了事务数据湖所用的Hudi,Delta等表格式。Hologres利用DLF-Access直接读取这些表中的数据,而不增添任何额外的操作,满足了用户对实时湖仓一体架构的设计需求。
总结
Hologres通过DLF-Access与DLF/OSS深度整合,充分利用Hologres和DLF/OSS的各自优势,以极致性能为目标,直接加速查询云数据湖数据,让用户更方便高效的进行交互式分析,同时也极大降低了分析成本,实现湖仓一体的分析能力。
作者简介:Xuefu Zhang,阿里巴巴资深技术专家,现从事Hologres研发工作。
后续我们将会陆续推出有关Hologres的技术底层原理揭秘系列,敬请持续关注!往期精彩内容:
- 2020年VLDB的论文《Alibaba Hologres: A cloud-Native Service for Hybrid Serving/Analytical Processing》
- Hologres揭秘:首次揭秘云原生Hologres存储引擎
- Hologres揭秘:Hologres高效率分布式查询引擎
- Hologres揭秘:高性能原生加速MaxCompute核心原理
- Hologers揭秘:优化COPY,批量导入性能提升5倍+
- Hologres揭秘:如何支持超高QPS在线服务(点查)场景
- Hologres揭秘:从双11看实时数仓Hologres高可用设计
了解Hologres:https://www.aliyun.com/product/bigdata/hologram