淘系数据模型治理最佳实践
导读:本次分享题目为淘系数据模型治理,主要介绍过去一年淘系数据治理工作的一些总结。
具体将围绕以下4部分展开
- 模型背景&问题
- 2问题分析
- 3治理方案
- 4未来规划
模型背景&问题
1.整体情况
首先介绍一下淘系的整体数据背景。
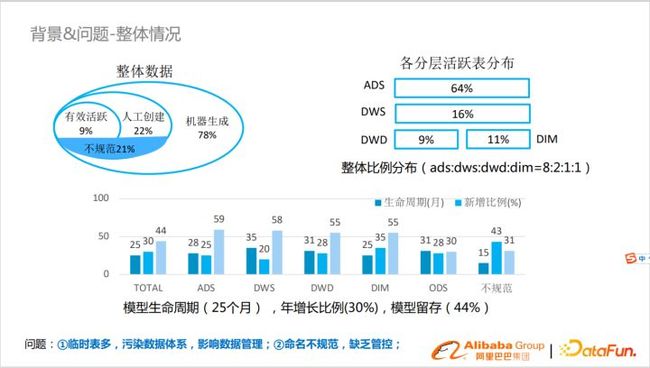
淘系的数据中台成立至今已有7年左右,一直未作数据治理,整体数据生成构成比为:人工创建(22%)+机器生成78%。其中活跃数据占比:9%,不规范数据占比:21%。
数据活跃以倒三角形状分布,整体分布比例为ads:dws:dwd:dim=8:2:1:1,分布还算合理。
上图中下半部分是模型的生命周期,增长和留存情况。淘系的业务还属于快速变化中,模型变化比较快。模型生命周期为25个月,模型年增长比例30%,模型留存44%。
2.公共层
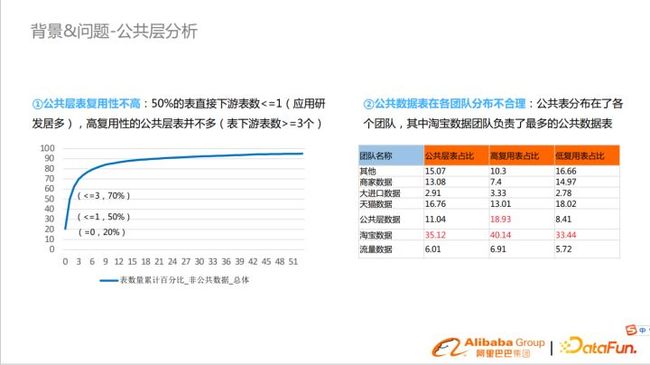
公共层两大核心问题为:
- 首先,公共层表复用性不高。在2014年的时候公共层还比较规范,但可持续性不强。随着时间流逝,业务增长和变化,复用性就逐年降低。因为大部分的数据是应用层做的,他们会开发自己的公共层,复用性降低,大部分都是无效表。
- 另外,公共数据表在各个团队分布不合理。这是由于数据团队多,为了满足业务开发效率,每个团队都有自己的公共表,容易出现公共表复用占比低,重复建设的场景。其中淘宝数据团队负责最多的公共数据表。
3.应用层分析
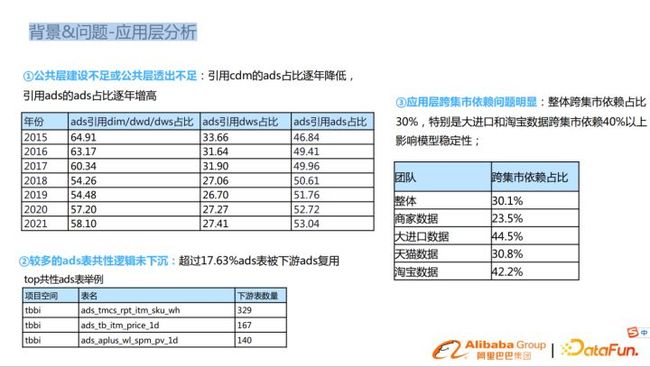
应用层的主要问题包括:
- 第一,公共层建设不足或公共层透出不足。随着时间增长,公共层的指标不能满足ads层的业务需要,ads复用指标逻辑没有下层,引用cdm层的ads表占比逐年降低,引用ads的ads表占比逐年增高。
- 第二,较多的ads表共性逻辑未下沉,统计显示超过17.63%ads表被下游ads复用。
- 第三,跨集市依赖严重,统计显示,整体跨集市依赖占比为30%,特别是大进口和淘宝数据跨集市依赖达到了40%,影响模型的稳定性,影响了模型的下线、修改。
问题分析
1.问题汇总
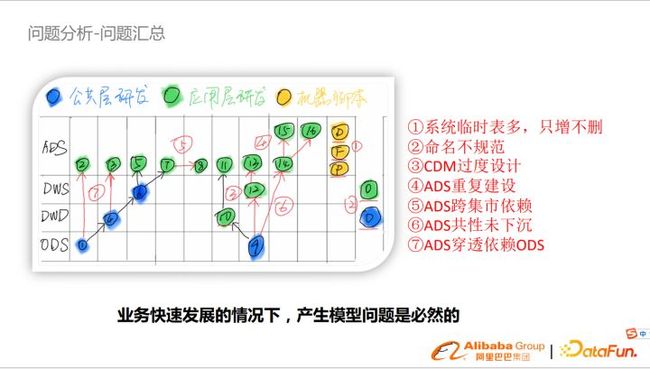
以上这副图是简化后的数据模型,我们可以发现存在很多不规范问题影响了模型的稳定性。业务在快速发展的情况下,为了快速响应业务需求,产生模型问题是必然的。日常工作中,数据研发流程大致如下,接到业务需求,直接引用ODS层表开发ADS数据,待数据需要复用的时候就把逻辑沉淀到公共层,同理指标也会有类似情况。主要问题可以归纳为七点:
- 系统临时表多,只增不删,对于消费侧影响较大,因为表量巨大,有效比例低,很难检索到;
- 命名不规范;
- 公共层过度设计;
- ADS重复建设;
- ADS跨集市依赖;
- ADS共性未下沉;
- ADS穿透依赖ODS。
2.原因分析

从问题分类上看,主要有三大类问题:规范性问题,公共层复用性问题和应用层复用性问题。
从问题原因上看,主要有四大类原因:架构规范,流程机制,产品工具,以及研发能力。
3.模型治理的问题
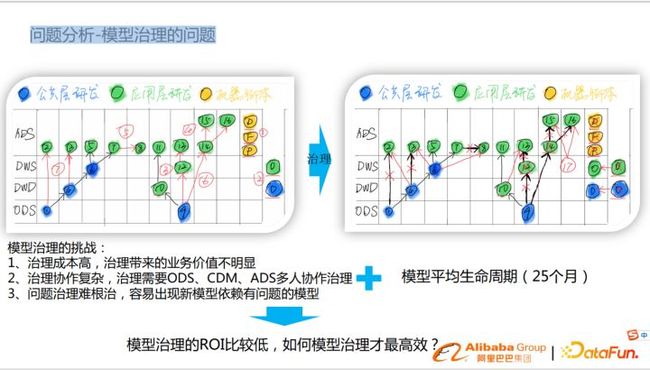
模型治理的挑战:
- 业务价值不明显,治理带来的是长期价值,短期对业务影响不大。
- 治理协作复杂,治理需要ODS、CDM、ADS层多人多团队协作
- 问题治理难根治,容易出现新模型依赖有问题模型
- 模型平均生命周期不长(25个月)
综上所述,模型治理的ROI比较低,我们的问题就是如何模型治理才最高效?
治理方案
1.整体方案
基于以上的问题原因分析,我们制定了如下治理方案。
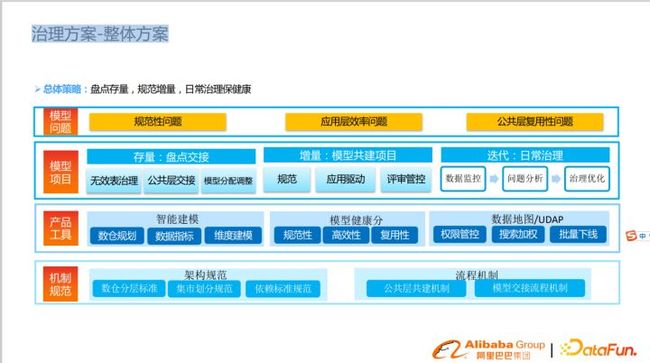
核心策略为以下三点:
1:盘点存量,掌握数据的整体情况
2:规范增量,避免新增模型走老路,重复出现相同问题,考虑到数据的生命周期,历史数据可以先不管。
3:日常治理保健康,以数据化驱动长期治理
2.机制规范
架构分层标准

往年我们关注的是数据视角,今年关注的是业务视角,业务视角核心诉求主要有四点,交付效率、产出时效、质量可靠、成本可控。过去OneData定义了每一层的作用,但每个层次的分工定位不清晰,针对这些问题重新做了清晰的定义。
应用层核心是专注支持业务,需要考虑研发效率、交付数据口径一致性和稳定性。
通过集市规范来控制复杂度,通过轻度聚合的中间层确保口径统一,通过扁平化设计确保稳定。
公共层的核心是抽象复用来提升效率,需要考虑易用性和稳定性。通过规范和冗余宽表提升复用性,通过解耦来确保稳定性。
ODS层的核心是合规高效,需要考虑接入效率和性能稳定。通过工具化提升效率、优化治理确保性能的稳定。特别是在数据达到一定量之后要考虑采用merge的方式接入数据。
集市划分规范
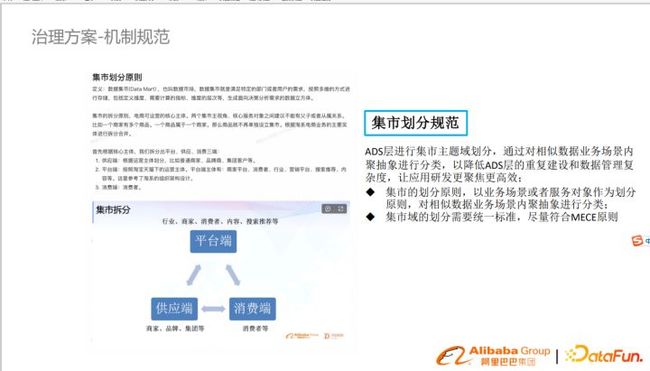
数据集市,是用来满足特定部门或者用户的需求,按照多维的方式进行存储。通过对相似数据业务场景内聚进行抽象分类,以降低ADS层重复建设和数据管理复杂度,让应用研发更聚焦更高效。
集市划分的原则有以下两点:
原则一:以业务场景或者服务对象作为划分原则,对相似数据业务场景内聚抽象进行分类。
原则二:集市划分需要统一标准,尽量符合MECE原则。
公共层共建机制
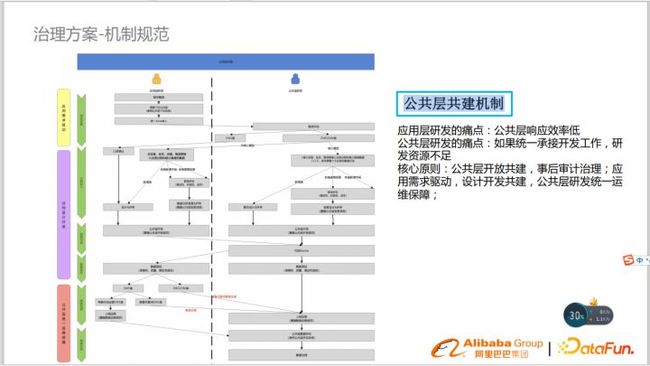
在建设公共层的建设过程中,我们通常会遇到以下两个痛点:
- 应用研发的痛点:公共层相应效率低。
- 公共层研发的痛点:如果统一承接开发工作,涉及的业务很广泛,研发资源不足。
为了解决以上两个痛点,我们通过以下核心原则来解决:
原则一:公共层开放共建,事后审计治理
应用开发整理需求,把需要下沉的公共维度提给公共层研发,公共开发需求评估。
原则二:以应用需求驱动,设计开发共建 以需求为驱动,拆分出核心模型和非核心模型,核心模型公共研发负责,非核心模型由业务开发进行,共同开发以提高效率。
原则三:公共层研发统一运维保障
非核心模型上线并完成相关测试(准确性、确定性、治理)后转交给公共层研发,由公共层统一运维。
3.智能建模
在数据治理中有数据规范与共建机制依然是不够的,还需要结合自动化工具来提升效率、保障规范。我们是从以下4个方面入手的(详情可以体验DataWorks的产品):
- 数据体系目录结构化
- 模型设计线上化
- 打通研发流程(自动化生成简代码)
- 对接地图数据专辑
数据目录体系结构化
形成数据体系目录有利于了解掌握数据,分门别类的方式降低了大家的使用成本。
首先要对表命名做一些管控,我们做了可视化的表命名检测器,来确保规范性。另外,淘系不是一个单空间的数据体系,因此要解决跨多个空间的复杂数据体系的统一建模问题。
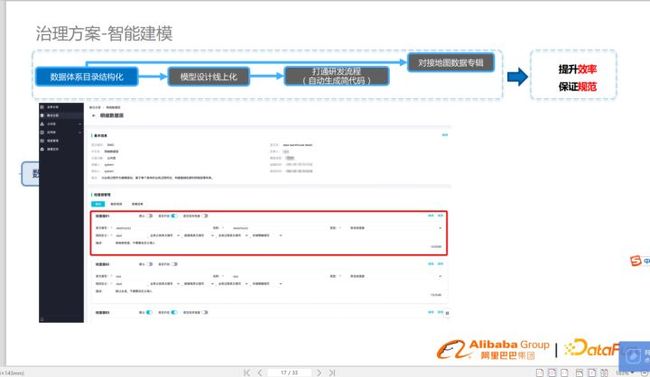

模型设计线上化
改变模型设计方式,由线下设计迁移到线上,通过一些自动化工具,提升效率,保证规范。



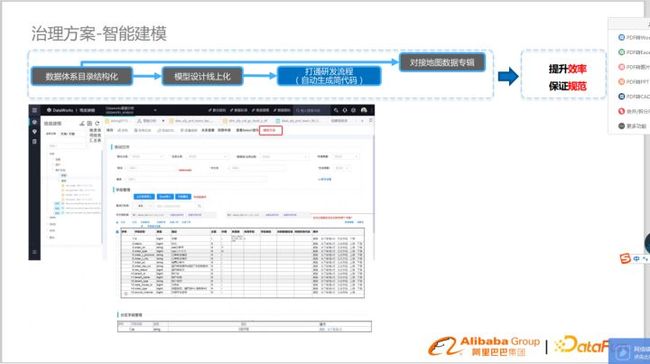
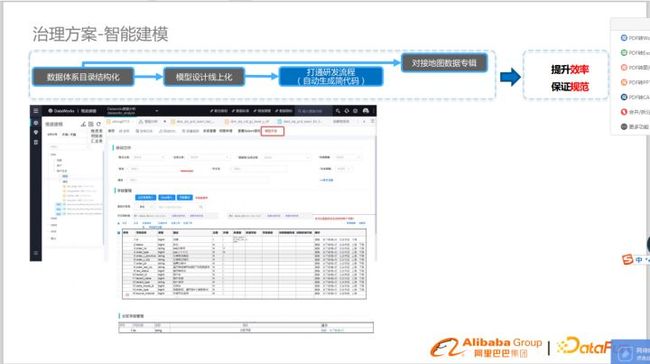
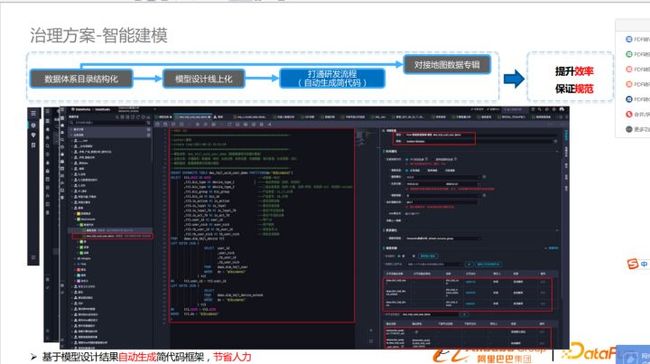
打通研发流程(自动化生成简代码)
模型迁移到线上后,打通研发流程自动生成简代码,生成代码框架,建表语句,显著提高了研发效

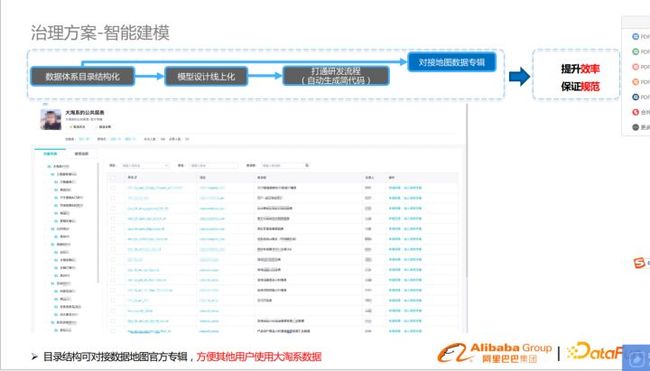
对接地图数据专辑
形成相应的地图数据专辑,方便其他用户使用数据。
4.模型治理
打分模型
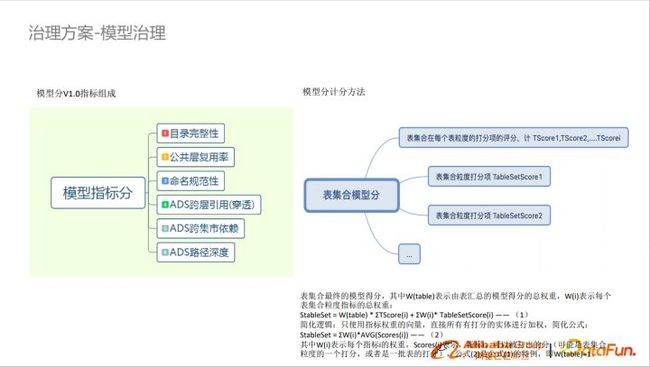
模型治理需要量化,如果没有量化全靠专家经验效率是非常低的,我们通过模型的指标形成到表级别的模型分。通过多维度对模型进行打分。
打分机制
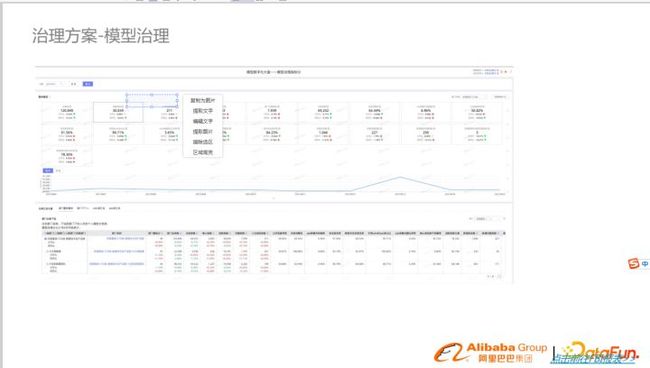
精细化的打分机制,针对团队、数据域、核心进行打分,形成相应的标签。
整体流程

以数据驱动,上图左边,以模型评估数据为出发点,通过各个维度对模型进行评估,得到各个域、各个团队的评分,形成相应的问题标签。
以产品驱动,上图右边,通过专家经验判断新上线模型升级搜索权限、下线模型降权限,让业务迅速感知数据变化,引导业务。
未来规划
应用层效率
在整个数据体系中,应用层的数据体量是最大的,投入了大量的人力。OneData缺少对应用层的数据建设指导,集市高度耦合,给运维效率带来了不少问题,如跨集市依赖、依赖深度的问题。过去都是以业务为主导,为了保障研发效率放弃了部分研发规范,以后要完善应用层的研发规范,同时通过工具做好研发效率与规范的平衡。
架构规范管控
基于分层标准落地,对研发过程规范完善,包括对设计、开发、运维、变更、治理等规范进行细化。
目前核心是表命名规范,对依赖规范、代码规范、运维规范等管控能力尚不足。
产品工具提效
将继续与Dataworks共建。
- 应用层智能建模能力还不能满足研发效率要求,因此会继续功能提效;
- 数据测试功能集成;
- 数据运维功能升级;
- 事中数据治理能力构建(开发助手);
- 事后治理能力提效(批量删除、主动推送优化等);
- 数据地图,找数用数提效。
问答环节
1:核心公共层的建设是自顶向下还是自底向上?
采用的是两者相结合的方式。以需求为驱动,没有需求就会导致过渡设计,在应用层有复用之后再下沉到公共层,这是自顶向下的。 在公共层设计阶段是面向业务过程的,这时是自底向上的。
2:多BU公共层是否需要统一规范?怎么去做?怎么量化价值?
需要做统一的规范,规范利于数据流通,才能体现数据价值 。但是具体怎么规范需要具体去看,如电商、本地生活,业务和目标不一样,很难做到统一的规范
3:怎么判断指标需要下沉到公共层?
公共层的开发是需要成本的,是否需要下沉到公共层核心是看是否需要复用,可以从两个方面入手。
专家经验判断:如电商交易环节数据,这类数据是核心数据,是要建设到公共层的。
事后判断:如玩法之类的业务稳定性不强,那一开始不需要下沉到公共层,避免过度设计,事后再去判断是否需要下沉。
4:关于表、字段的命名规范,是否需要先定义好词根再开发?
需要分开看。对于公共层设计到的业务过程是有限的,对于公共部分要先定义好再开发。对于应用层,维度采用的是总建架构所以还需要先定义,对于指标特别是派生指标是多的,不建议先定义在开发。
5:如何解决口径一致命名不一致,或者口径不一致或者命名一致的场景。
模型是演变的。对于应用层,80%都是自定义的,第一次出现的时候都是不标准的,这部分如果采用先定义后开发的方式,效率是很低的,只有在下沉到公共层的时候才能够管控。对于公共层,能做的是保障核心指标90%的规范与定义统一,剩下的那部分也无法保证。
6:跨集市依赖下沉到公共层的必要性?
短期来看,是没影响的,新增效率高。
长期来会给数据的运维、治理带来很多影响,在数据下线、变更、治理过程中不得不考虑到下游依赖,会影响全流程的开发效率。
原文链接
本文为阿里云原创内容,未经允许不得转载。