kafka 文件存储 消息同步机制
1. kafka broker存储原理
1.1 文件存储位置
- 配置文件: config/server.properties
logs.dor
默认:/tmp/kafka-logs
1.1.1 Partition分区
为了实现横向扩展,把不同的数存放在不同的Broker上,同时降低单台服务器的访问压力,我们把一个topic中的数据分割中多个partition。
一个partition中的消息是有序的,但是全局不一定。

1.1.2 Replica副本
为了提高分区的可靠性,kafka设计了副本机制。
创建副本命令:
./kafka-topics.sh --create --bootstrap-server 172.0.0.1:9092 --replication-factor 4 --partitions 1 --topic overrep
部分数量需要小于等于Broker的数量,否则就会报错。由于这个机制,所以不论哪个broker宕机都可以完成切换。
这些所有的副本分为两种角色,Leader、Follower。leader负责对外的读写,follower唯一任务就是从leader异步拉取数据。由于所有的读写都发生leader上,所以就没有数据一致性问题。
./kafka-topics.sh --create --bootstrap-server 192.168.8.146:9092 --replication-factor 3 --partitions 3 --topic a3part3rep
查看副本分布情况:
./kafka-topics.sh --topic a3part3rep --describe --bootstrap-server 127.0.0.1:9092

1.1.4 副本在Broker的分布
分布策略由AdminUtils.scala的assignReplicasToBrokers函数决定,规则如下:
- first of all,副本因子不能大于Broker的个数;
- 第一个分区(编号为0的分区)的第一个副本放置位置是随机从brokerList选择的(Broker的副本);
- 其他分区的第一个副本防止位置相对于对于第0个分区一次往后移;
如果有5个broker,5个分区,假设第一个分区的第一个副本放在第三个broker,那么第二个分区的第一个副本放在第四个broker,第三个分区的第一个副本放在第五个broker,依次类推。
这样的好处是,所有分区leader都可以平均分布在不同的broker,避免多个分区的leader分布在同一个broker上,降低了单个分区的读写压力。
- 每个分区剩余的副本相对与第一个副本防止位置其实由nextReplicaShift决定的,而这个数字是随机的。
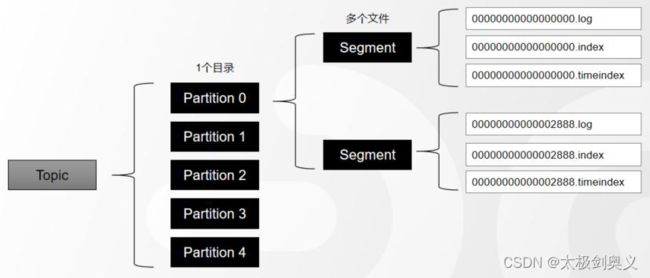
1.1.5 Segment
为了防止Log不断追加导致文件过大,导致检索信息效率变低,一个Partiton又被划分多个Segment来组织数据
在磁盘上,每个Segment由一个log文件和2个index文件组成

- log日志文件(日志就是数据)
在一个Segment文件里面,日志是追加写人的,如果满足一定条件,就会切分日志文件,产生一个新的S二哥门头。
当一个Segment写满以后,会创建一个新的Segment,用最新的Offset作为名称。
segment的默认大小是1073741824 bytes(1G),这个参数可以由 log.segment.bytes
当消息的最大的时间戳和当前系统时间戳的差值较大,也会创建一个新的Segment,有一个默认参数
,168 个小时(一周):log.roll.hours=168 | log.roll.ms 如果服务器上此写入的消息是一周之前的,旧的Segment旧不写了,重新创建一个新的Segment。
当offset索引文件或者timestamp索引文件达到了一定的大小,默认是10M:log.index.size.max.bytes 。也就是索引文件写满了,数据文件也要跟着拆分,不然这一套东西对不上
- .index偏移量(Offset)索引文件
- .timeindex时间戳(timestamp)索引文件
1.1.6 索引
由于一个Segment的文件里面可能存放很多消息,如果根据Offset获取消息,必须要有一种快速检索消息的机制。这个就是索引。在kafka中涉及了两种索引。
1.1.6.1 .log Offset索引文件
偏移量索引文件记录的是Offset和消息物理地址(在Log文件中的位置)的映射关系。时间戳索引文件记录的是时间戳和Offset的关系。
内容是二进制的文件,不能以纯文件形式查看。bin目录下有dumplog工具。
查看最后10条件Offset索引
./kafka-dump-log.sh --files
/tmp/kafka-logs/mytopic-0/00000000000000000000.index|head -n 10
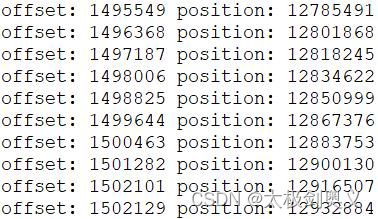
根据结果查看,索引并不是连续的,这个是由于kafka使用的是稀疏索引
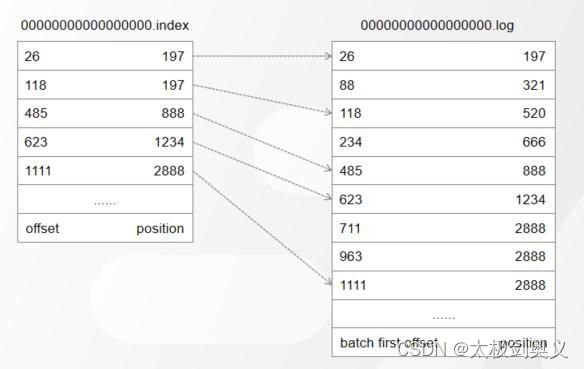
根据消息大小来控制的稀疏度,默认是4KB:
log.index.interval.bytes=4096
只要写入的消息超过了4KB,偏移量索引文件.index和时间戳文件索引.timeindex就会增加一天索引记录(索引项)。
- 越是稀疏,插入、删除时需要开销旧越小。
- 检索复杂度O(long2n)+O(m),n时索引文件里面索引的个数,m位稀疏程度
1.1.6.2 .timeindex 时间戳索引文件
时间戳索引文件存在的意义:
- 如果要基于时间切片日志文件,必须要记录时间戳;
- 如果要基于时间清理消息,有时间戳才方便清理;
时间戳有两种,一种就是producer创建时间,一个是写入broker的时间。可由参数控制:
log.message.timestamp.type=CreateTime
默认是创建时间。可以调整为日志写入时间:log.message.timestamp.type=LogAppendTime
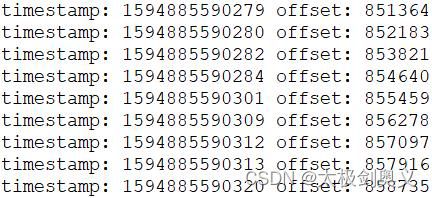
查看最早10条时间戳索引
./kafka-dump-log.sh --files /tmp/kafka-logs/mytopic-0/00000000000000000000.timeindex|head -n 10
1.1.6.3 检索原理
检索Offset=10001 过程:
- 消费者在消费的时候就会确定partition,首先需要确定segment。segment文件时Base Offset命名的,所以可以用二分法确定。
- 这个segment中,通过.log文件找到position
- 得到position后,到对应log文件李开始查找Offset,和消息的Offset比较,直到找到消息。
不使用B+Tree?
kafka是写多,查少,在写入B+Tree,大量的插入就会非常消耗性能
1.2 消息保留机制
1.2.1 开关与策略
消息清理开关默认是开启的
log.cleaner.enable=true
kafka里面提供了两种方式,一种是直接删除delete,一种是压缩compact。默认是删除。
log.cleanup.policy=delete
1.2.2 删除策略
日志删除是通过定时任务实现的,默认5分钟执行依次,查找需要删除的数据
log.retention.check.interval.ms=300000
- 第一种是通过时间删除
删除老数据,需要定义哪些数据是老数据,控制参数,默认是一周:
log.retention.hours=168
- 第二种是通过文件大小
配置日志文件大小来删除,先删除旧的消息,删除到不超过这个大小为止,默认是-1,表示不限制大小
log.retention.bytes
log.retention.bytes 指的是所有日志文件的总大小,可以对单个segment文件大小限制。
log.segment.bytes
默认是1G
1.2.3 压缩策略
压缩的不是对文件常规压缩,而是重新排序,结果数据。如:一条消息key=k1,然后对这条数据做了多次的修改,但是日志文件中会记录多条,压缩就是把中间过程去掉,直接保留结果数据。
根据开发以及实际习惯,极少出现修改修改message的情况,所以这个功能其实没啥用。
1.3 高可用
1.3.1 Controller选举
kafka早期使用zk直接选举partition的Leader,使用了zk的三个机制:
- watch机制
- 临时节点
- 顺序不重复节点
这样实现比较简单,但存在一定的弊端,zk是cp模型,在分区和副本数量较多时,所有的副本都直接进行选举的话,一旦出现某个节点的增减,就会造成较大的watch事件被触发,zk出现负载过重,不堪重负。
现在的实现方式:
不是所有的replica都参与选举,而是由其中一个broker来统一控制,这个Broker的角色叫做Controller。
如果Redis Sentinel的架构,机型故障转移的时候,必须要首先冲所有哨兵中选举一个负责做故障转移的节点一样。kafka也要先从所有Broker中选出唯一的一个Controller。
所有的broker会重试在Zookeeper中创建临时节点/controller,只有一个能创建成功(根据broker的创建时间)。
如果Controller挂掉了或者网络问题,zk上的临时节点就会消失。其他的Broker通过watch监听到Controller下线的消息后,开始选举Controller。
一个节点成为Controller之后,它就赋予了更多的责任和能力:
- 监听Broker变化。
- 监听Topic变化。
- 监听Partition变化。
- 获取所有管理Broker、Topic、partition的信息。
- 管理Partition的主从信息。
1.3.2 分区副本Leader选举
https://kafka.apache.org/documentation/#replication
https://kafka.apache.org/documentation/#design_replicatedlog
Controller确定以后,就可以开始做分区选主的事情。不是所有的Replica都有资格选举资格。
一个分区所有的副本,都叫做Assigned-Replicas(AR)。
这些所有的副本中,跟Leader数据保持一定程度同步的,叫做In-Sync Replicas(ISR)。
副本中同步较为滞后的副本叫做Out-Sync-Replicas(OSR)。
AR = ISR+OSR,正常情况,OSR为空。
默认情况下只有ISR集合中的副本才能有资格被选举Leader。如果ISR为空,可以这只ISR之外的副本参与选举:
unclean.leader.election.enable=false
把这个参数改成true即可,不建议使用,会造成数据丢失。
Paxos选举算法:
- ZAB(zk)
- Raft(Redis Sentinel)
主要思想就是:先到先得、少数服从多数。
kafka使用的不是这些方法,而是用了自己实现的算法。由于ZAB协议可能出现多个分裂现象(节点不能互通的时候,出现多个Leader)、惊群效应(大量Watch事件被触发)。
kafka的选举算法和微软的ParificA算法。
这种算法中,默认让ISR中的一个Replica变成Leader。比如ISR是1 2 4,则优先让1成为Leader。然后后再依次考虑其后。
1.3.3 主从同步
Leader确定之后,客户端的读写只能操作Leader节点。Follower需要向Leader同步数据。
不同的Replica的Offset是不一样的,那具体怎么同步的呢。
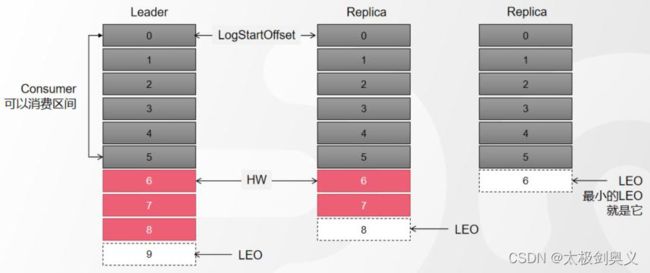
LEO(Log End Offset):下一条等待写入消息的Offset(最新的Offset + 1),图中的 9 8 6,使用命令:
./kafka-consumer-groups.sh --bootstrap-server 192.168.8.146:9092 --describe --group test-group
HW(High Watermark):ISR中最小的LEO。Leader会管理所有ISR中最小的LEO作为HW,目前是6。
Consumer最多只能消费到HW之前的位置(Offset 5)。也就是其他副本没有同步的消息,是不能被消费的。
如此设计原因是如果消息被成功消费了,Consumer Group的Offset会偏大。如果Leader崩溃,中间会缺失消息。
- Follower节点会向Leader发送一个fetch请求,Leader向Follower发送数据后,即需要更新Follower的LEO。
- Follower接收到数据响应后,依次写入消息并更新LEO。
- Leader更新HW
kafka设计了独特的ISR复制,可以再保障数据一致性情况下又可提高吞吐量。
1.3.4 Replica故障处理
- Replica故障
首先Follower发生故障,会先被提出ISR。
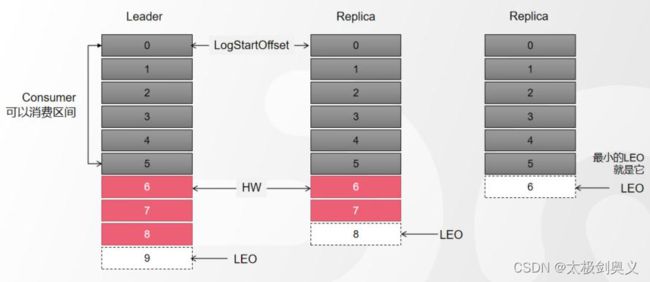
如果当第一个副本(图中间Broker)宕机。恢复后,首先根据当前的HW(6),把高于HW的消息截掉6、7。然后向Leader同步消息。追上leader之后(30秒),重新加入ISR。 - Leader故障
假设图中Leader发生故障。
为了保障数据一致,其他的Follower需要把高于HW的消息截取到。
然后Replica2同步数据。
这种机制只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。