python机器学习手写算法系列——CBLOF异常检测
我目前在做一些和异常检测相关的工作,并参加到了pyod里面的CBLOF算法的开发。所以,我对于CBLOF的论文以及pyod里面的实现都非常熟悉。
对于手写算法系列的文章。有兴趣的可以研究一下代码。时间紧的也可以跳过代码不看。但是,即使你并不想看代码,也建议你来看我的文章。毕竟,我是实现了这些代码的,说明我自己首先理解了这些算法,我才好意思写文章。而且在实现的过程中,就像本文一样,可以把一些中间步骤都作图打印出来。
异常检测
异常检测一般来说是一种无监督学习的方法。他在没有标签的情况下,利用各种算法来区分正常值和异常值。
当然,如果有标签,就可以用分类算法解决异常检测了。虽然这也是异常检测,但是这样的算法还是分类算法。只有无监督的异常检测,一般才认为是异常检测算法。
异常检测的算法,从传统的统计方法,到机器学习,再到深度学习,应有尽有。
很多异常检测的算法,都是基于已有的机器学习算法的。比如KNN的异常检测算法,就是看一个点到由近到远第K个点的距离,然后找出距离最大的少数点作为异常。
CBLOF 基于聚类的本地异常因子
我们今天要学的CBLOF也是一种基于其他机器学习算法的异常检测算法。说到基于,就是CBLOF名字里面的B~Based。而他基于的是其他的聚类算法,所以他就是Cluster-Based。LOF三个字母是Local Outlier Factor,本地异常因子。合起来CBLOF 就是 Cluster-based Local Outlier Factor,基于聚类的本地异常因子。

他的一个基本认知是:数据可能会在多个不同的地方聚集,形成簇。当一个点越接近大簇的时候,他是正常点的概率就越高,反之越低。那么,我们只要在CBLOF里面,套一个聚类算法,就能得到这些簇了。一般,我们会用k-means算法,距离就直接用欧氏距离。于是,我们就有了上图当中的四个簇。这里,我们明显看出来,C2和C4是两个大簇,剩下的C1和C3是两个小簇。那么,距离C2或者C4的中心(即K-Means里面的中心,又叫Centroids)越近,就越正常,反之越异常。
数据
这里,我们以一个实际的例子,来具体介绍本算法。
我们这里用销售和利润的数据。你可以在这里找到:
https://community.tableau.com/docs/DOC-1236

我们可以看到,绝大多数点都集中在左中的一小块区域。极少数的点分布在其他区域。
聚类
我们说到,这个算法的第一步是聚类,那么我们就来对他进行聚类。
在聚类之前,我们先对数据进行归一化。这是非常必要的一步。特别是在各种变量的变化范围不一样的情况下。
(篇幅所限,大多数代码就不贴了,文末给出代码地址。)
然后,我们直接用k-means聚类。
km = KMeans(n_clusters=8)
km.fit(X)
聚类以后,我们得到下图。图中按照颜色区分了每个簇
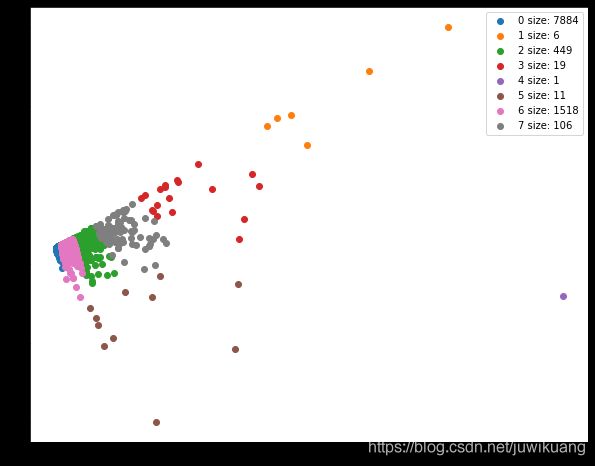
大簇小簇
我现在问你一个问题,哪个簇是最大的?
希望你猜对了,那个看起来最小的蓝色的簇是最大的。最小的簇是紫色的簇,虽然他面积很大,但是他只有一个点。所以,我们这里的大小,是用簇成员的多少(size)来衡量的。
那么其他的簇,哪个算大簇,哪个算小簇呢?
我们先来定义个 ∣ C ∣ |C| ∣C∣,表示簇 C C C的大小(size)。我们把这些簇按照大小排列,则有:
∣ C 1 ∣ ≥ ∣ C 2 ∣ ≥ ∣ C 3 ∣ ≥ . . . ≥ ∣ C k ∣ |C_1|\ge|C_2|\ge|C_3|\ge...\ge|C_k| ∣C1∣≥∣C2∣≥∣C3∣≥...≥∣Ck∣
绝对多数
这是,我们选择大小簇,有两个原则,先说第一个,就是绝对多数原则。也就是说,我们从最大簇开始,一个一个的把他们的size加起来,他们的size要达到总size的绝对多数。而这个绝对多数,是一个可以设置的参数 α \alpha α,他的取值范围是0.5到1,一般取0.9。
突降
第二个原则是突降,突降是用倍数( β \beta β)来衡量的。默认值是5,也就是突降了5倍。
pyod是这样实现的:能找到同时满足两个条件的分割最好。次优是找到满足绝对多数原则的分割。最差是只找到了满足突降原则的分割。
以下是我简单实现。
large_clusters=[]
small_clusters=[]
found_b= False
count=0
clusters = df_cluster_sizes['cluster'].values
n_clusters = len(clusters)
sizes = df_cluster_sizes['size'].values
for i in range(n_clusters):
print(f"-----------iterration {i}--------------")
satisfy_alpha=False
satisfy_beta=False
if found_b:
small_clusters.append(clusters[i])
continue
count+=sizes[i]
print(count)
if count>n_points_in_large_clusters:
satisfy_alpha=True
print(sizes[i]/sizes[i+1])
if i<n_clusters-1 and sizes[i]/sizes[i+1]>beta:
print("beta")
satisfy_beta=True
print(satisfy_alpha, satisfy_beta)
if satisfy_alpha and satisfy_beta:
found_b=True
large_clusters.append(clusters[i])
我们把大簇和小簇分颜色显示,可见大簇里更像正常点,小簇里更像异常点。
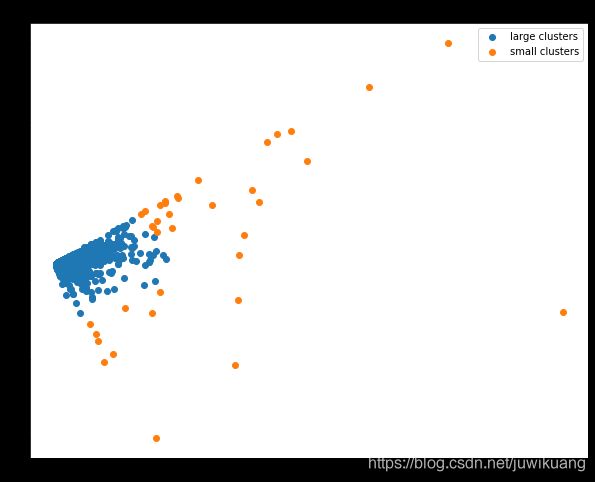
Factor 因子
这里我们要计算CBLOF因子,也就是一个点到最近的大簇的距离。
如果这个点是大簇里面的点,那么直接计算他到簇中心的距离即可。如果这个点不是大簇点,那么就要分别计算其到所有大簇的距离,选最小的那个作为因子。
def get_distance(a,b):
return np.sqrt((a[0]-b[0])**2 + (a[1]-b[1])**2)
def decision_function(X, labels):
n=len(labels)
distances=[]
for i in range(n):
p=X[i]
label = labels[i]
if label in large_clusters:
center = km.cluster_centers_[label]
d=get_distance(p, center)
else:
d=None
for center in large_cluster_centers:
d_temp = get_distance(p, center)
if d is None:
d=d_temp
elif d_temp<d:
d=d_temp
distances.append(d)
distances=np.array(distances)
return distances
distances = decision_function(X, km.labels_)
这里,我们需要介绍一个污染contamination的概念。他是异常检测算法的主要参数。其实他就是表示了异常的比例。一般这个值是1%,我们这里直接使用默认值了。
我们有了contamination 1%,就可以用python里面的百分位函数,找出距离最大的1%的点,把他们作为异常。
threshold=np.percentile(distances, 99)
print(f"threshold is {threshold}")
anomaly_labels = (distances>threshold)*1
这里,我们就得到了异常点。我把我的结果打印出来,并和pyod里面的CBLOF打印的图比较,两者是一样的。
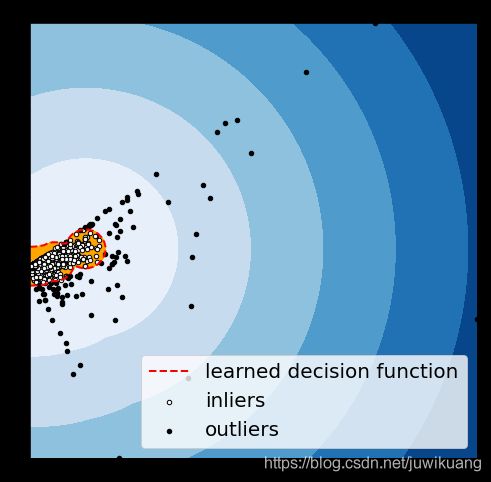
(上图代码抄的Susan Li的文章)
源代码
https://github.com/EricWebsmith/machine_learning_from_scrach
如果你喜欢这个系列,可以收藏我的github项目。所有的算法,会首先在github上面实现,等我有空的时候,才会在csdn上面写文章。目前还有很多算法实现了以后没空写文章的。包括XGB, CatBoost, 周志华的Isolation Forest等。其中Isolation Forest算法,和本文一样,我花了大量的工作在图上。
参考
He, Zengyou, Xiaofei Xu, and Shengchun Deng. “Discovering cluster-based local outliers.” Pattern Recognition Letters 24.9-10 (2003): 1641-1650.
https://github.com/yzhao062/pyod
towardsdatascience.com 网站Susan Li的文章 Anomaly Detection for Dummies