Hive 学习笔记(二)使用窗口函数over实现电商常见五个需求| 查询某个时期购买过的顾客以及总人数| 顾客购买明细以及总额 | 按照日期对花费进行累加 |查询顾客上次购买时间 | 查询前20%时间
若发现文章有误,敬请指正,感谢
文章目录
- 参考资料
- 一、运行环境
- 二、准备测试数据
- 三、OVER() 窗口函数
- 需求一:查询在某年某月购买过商品的顾客以及总人数
- 需求二:查询顾客的购买明细以及月购买总额
- 需求三:将每个顾客的花费按照日期进行累加
- 3.1 按名称分组统计花费
- 3.2 按名称分组,并按消费日期累加
- 3.3 在上一个基础上,添加由起点到当前行的聚合
- 需求四:查看顾客上次的购买时间
- 需求五:查询前20%时间的订单信息
参考资料
视频链接
一、运行环境
- Vmware
- CentOS 7 操作系统
- JDK 8
- MySQL8
- Hadoop3.3.0(单节点)
- HIve 3.1.2 on YARN
节点分配:
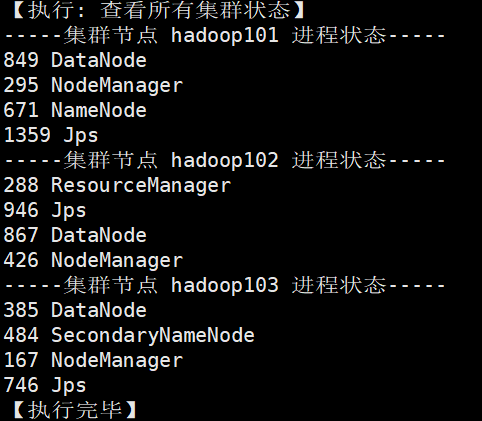
其中MySQL和Hive都安装在hadoop101节点
二、准备测试数据
客户的消费情况(客户昵称、消费日期、消费金额)cost.txt
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
将该文本数据保存到本地,等会加载到Hive数据表
进入Hive Shell,创建测试的表
hive (default)> create table testover(
> name string,
> orderdate string,
> cost int)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
加载本地数据
hive (default)> load data local inpath "/opt/module/hive/data/cost.txt" into table testover;
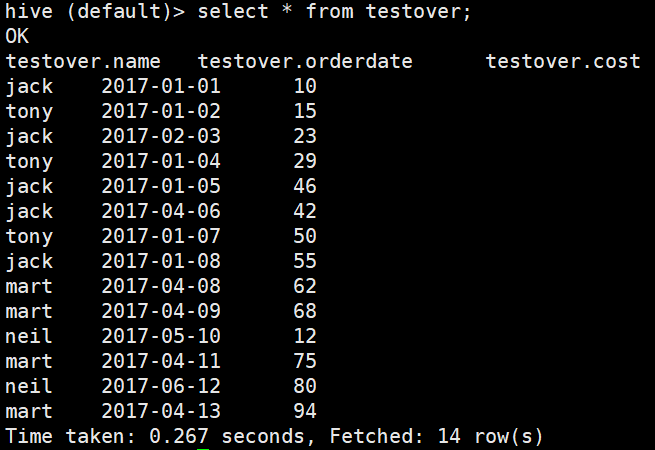
hive (default)> select * from testover;
查询结果:
三、OVER() 窗口函数
OVER(): 指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
常用参数有:
| 参数名 | 描述 |
|---|---|
| CURRENT ROW | 当前行 |
| n PRECEDING | 往前 n 行数据 |
| n FOLLOWING | 往后 n 行数据 |
| UNBOUNDED | 起点 ,后面通常要接PRECEDING或者FOLLOWING |
| UNBOUNDED PRECEDING | 表示从前面的起点 |
| UNBOUNDED FOLLOWING | 表示到后面的终点 |
| LAG(col,n,default_val) | 往前第 n 行数据 |
| LEAD(col,n, default_val) | 往后第 n 行数据 |
| NTILE(n) | 把有序窗口的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对 于每一行,NTILE 返回此行所属的组的编号。注意:n 必须为 int 类型。 |
标准语法:
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
需求一:查询在某年某月购买过商品的顾客以及总人数
这里以2017年4月份为例
SELECT
name,
count(*) over() person_count
FROM testover
WHERE substring(orderdate, 1, 7) = '2017-04'
GROUP BY name;
运行结果:
name person_count
mart 2
jack 2
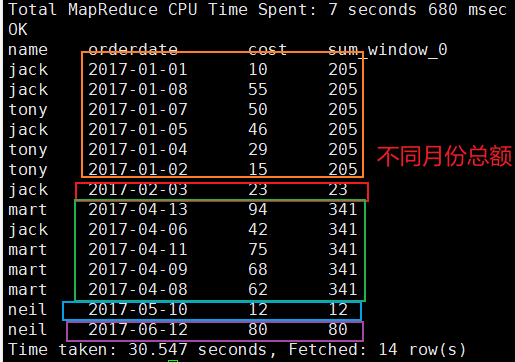
需求二:查询顾客的购买明细以及月购买总额
SELECT
name,
orderdate,
cost,
sum(cost) OVER(partition by month(orderdate))
FROM testover;
查询结果:
需求三:将每个顾客的花费按照日期进行累加
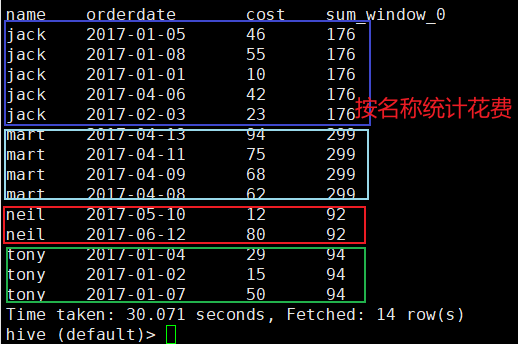
3.1 按名称分组统计花费
SELECT
name,orderdate,cost,
SUM(cost) OVER(partition by name)
FROM testover;
运行结果:
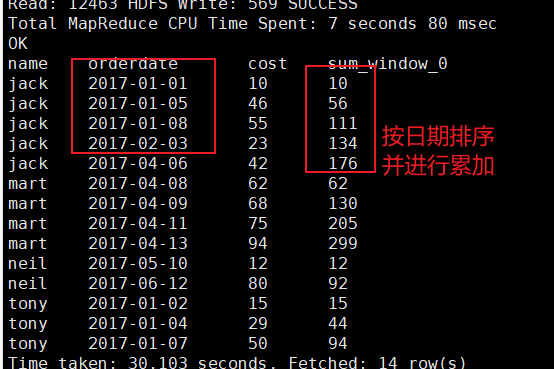
3.2 按名称分组,并按消费日期累加
SELECT
name,orderdate,cost,
SUM(cost) OVER(partition by name order by orderdate)
FROM testover;
运行结果:
3.3 在上一个基础上,添加由起点到当前行的聚合
SELECT
name,orderdate,cost,
SUM(cost) OVER(partition by name order by orderdate rows BETWEEN UNBOUNDED PRECEDING AND CURRENT row)
FROM testover;
运行结果和上一个相同,因为业务场景就是在求同一个窗口所有行的顾客花费
这里应用到了ROWS BETWEEN … AND 语句。
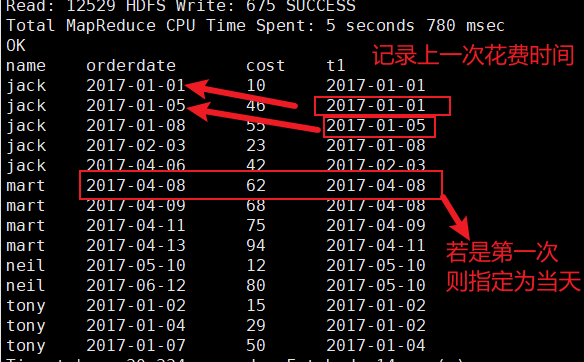
需求四:查看顾客上次的购买时间
SELECT name, orderdate, cost,
LAG(orderdate, 1, orderdate) OVER(partition by name order by orderdate) as t1
FROM testover;
运行结果:
需求五:查询前20%时间的订单信息
SELECT * FROM
(
SELECT name,orderdate,cost,
ntile(5) over(order by orderdate) sorted from testover
) t
WHERE sorted = 1;
运行结果:
