Lesson 12.5 softmax回归建模实验
Lesson 12.5 softmax回归建模实验
接下来,继续上一节内容,我们进行softmax回归建模实验。
- 导入相关的包
# 随机模块
import random
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# numpy
import numpy as np
# pytorch
import torch
from torch import nn,optim
import torch.nn.functional as F
from torch.utils.data import Dataset,TensorDataset,DataLoader
from torch.utils.tensorboard import SummaryWriter
# 自定义模块
from torchLearning import *
# 导入以下包从而使得可以在jupyter中的一个cell输出多个结果
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
查看自定义模块是否导入成功
tensorGenCla?
#Signature:
#tensorGenCla(
# num_examples=500,
# num_inputs=2,
# num_class=3,
# deg_dispersion=[4, 2],
# bias=False,
#)
#Docstring:
#分类数据集创建函数。
#
#:param num_examples: 每个类别的数据数量
#:param num_inputs: 数据集特征数量
#:param num_class:数据集标签类别总数
#:param deg_dispersion:数据分布离散程度参数,需要输入一个列表,其中第一个参数表示每个类别数组均值的参考、第二个参数表示随机数组标准差。
#:param bias:建立模型逻辑回归模型时是否带入截距
#:return: 生成的特征张量和标签张量,其中特征张量是浮点型二维数组,标签张量是长正型二维数组。
#File: f:\code file\pytorch实战\torchlearning.py
#Type: function
一、softmax回归手动实现
根据此前的介绍,面对分类问题,更为通用的处理办法将其转化为哑变量的形式,然后使用softmax回归进行处理,这种处理方式同样适用于二分类和多分类问题。此处以多分类问题为例,介绍softmax的手动实现形式。
【补充】softmax的另一种理解角度
我们都知道,softmax是用于挑选最大值的一种方法,通过以下公式对不同类的计算结果进行数值上的转化
δ k = e z k ∑ K e k \delta_k = \frac{e^{z_k}}{\sum^Ke^k} δk=∑Kekezk
这种转化可以将结果放缩到0-1之间,并且使用softmax进行最大值的比较,相比max(softmax是max的柔化版本),能有效避免损失函数求解时在0点不可导的问题,损失函数的函数特性,将是后续我们选择优化算法的关键。具体我们可以通过下述图像进行比较。
from matplotlib import pyplot
def max_x(x, delta=0.):
x = np.array(x)
negative_idx = x < delta
x[negative_idx] = 0.
return x
x = np.array(range(-10, 10))
s_j = np.array(x)
hinge_loss = max_x(s_j, delta=1.)
pyplot.plot(s_j, hinge_loss)
pyplot.title("Max Function")
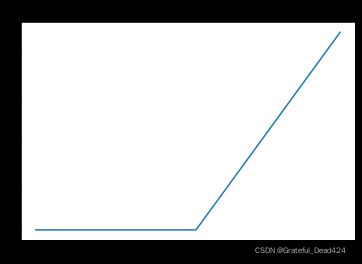
def cross_entropy_test(s_k, s_j):
soft_max = 1/(1+np.exp(s_k - s_j))
cross_entropy_loss = -np.log(soft_max)
return cross_entropy_loss
s_i = 0
s_k = np.array(range(-10, 10))
soft_x = cross_entropy_test(s_k, s_i)
pyplot.plot(x, hinge_loss)
pyplot.plot(range(-10, 10), soft_x)
pyplot.title("softmax vs Max")
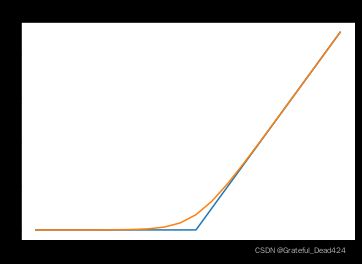
我们以三分类数据集为例,手动构建softmax回归。
1.生成数据集
利用此前的数据集生成函数,创建一个三分类、且内部离散程度不是很高的分类数据集
# 设置随机数种子
torch.manual_seed(420)
features, labels = tensorGenCla(bias=True, deg_dispersion=[6, 2])
plt.scatter(features[:, 0], features[:, 1], c = labels)

features
#tensor([[-6.0141, -4.9911, 1.0000],
# [-4.6593, -6.7657, 1.0000],
# [-5.9395, -5.2347, 1.0000],
# ...,
# [ 6.4622, 4.1406, 1.0000],
# [ 5.7278, 9.2208, 1.0000],
# [ 4.9705, 3.1236, 1.0000]])
2.建模流程
- Stage 1.模型选择
围绕建模目标,我们可以构建一个只包含一层的神经网络进行建模。
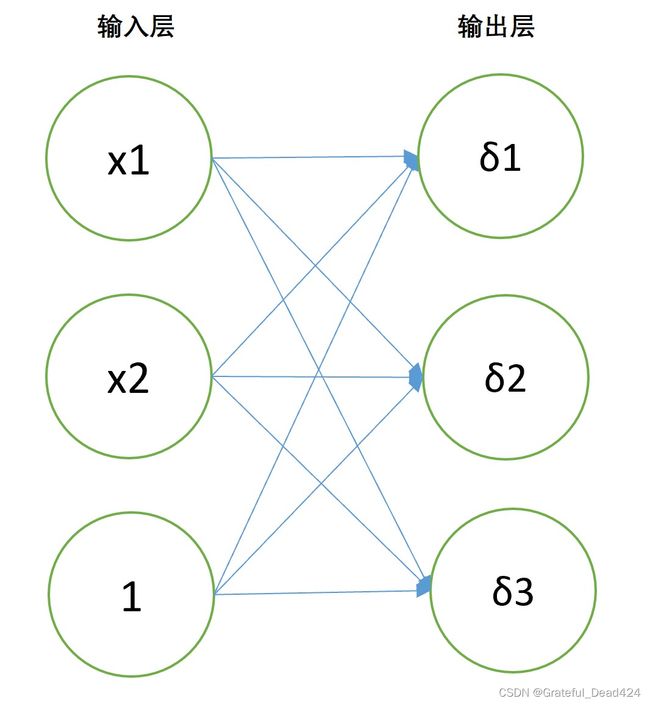
根据此前课程的介绍,输出层的每个神经元输出结果都代表某条样本在三个类别中softmax后的取值,此时神经网络拥有两层,且是全连接。此时从特征到输出结果,就不再是简单的线性方程变换,而是矩阵相乘之后进行softmax转化。
def softmax(X, w):
m = torch.exp(torch.mm(X, w))
sp = torch.sum(m, 1).reshape(-1, 1)
return m / sp
此处X是特征张量,w是由两层之间的连接权重所组成的矩阵,且w的行数就是输入数据特征的数量,w的列数就是输出层的神经元个数,或者说就是分类问题的类别总数。计算过程我们可以通过下述例子进行说明:
f = features[: 10]
l = labels[: 10]
f
l
#tensor([[-6.0141, -4.9911, 1.0000],
# [-4.6593, -6.7657, 1.0000],
# [-5.9395, -5.2347, 1.0000],
# [-7.0262, -4.5792, 1.0000],
# [-2.3817, -5.1295, 1.0000],
# [-0.7093, -5.4693, 1.0000],
# [-4.1530, -6.8751, 1.0000],
# [-1.9636, -3.3003, 1.0000],
# [-6.5046, -6.0710, 1.0000],
# [-6.1291, -7.1835, 1.0000]])
#tensor([[0],
# [0],
# [0],
# [0],
# [0],
# [0],
# [0],
# [0],
# [0],
# [0]])
w = torch.arange(9).reshape(3, 3).float()
w
#tensor([[0., 1., 2.],
# [3., 4., 5.],
# [6., 7., 8.]])
m1 = torch.mm(f, w)
m1
#tensor([[ -8.9733, -18.9785, -28.9837],
# [-14.2971, -24.7221, -35.1471],
# [ -9.7042, -19.8785, -30.0527],
# [ -7.7375, -18.3429, -28.9483],
# [ -9.3886, -15.8998, -22.4111],
# [-10.4079, -15.5865, -20.7651],
# [-14.6253, -24.6535, -34.6816],
# [ -3.9010, -8.1649, -12.4289],
# [-12.2130, -23.7886, -35.3642],
# [-15.5506, -27.8632, -40.1758]])
此时,上述矩阵的每一行都代表每一条数据在三个类别上的线性方程计算结果,然后需要进行softmax转化
torch.sum(w, 1)
#tensor([ 3., 12., 21.])
torch.exp(m1)
#tensor([[1.2675e-04, 5.7245e-09, 2.5854e-13],
# [6.1777e-07, 1.8336e-11, 5.4426e-16],
# [6.1026e-05, 2.3275e-09, 8.8770e-14],
# [4.3617e-04, 1.0809e-08, 2.6787e-13],
# [8.3669e-05, 1.2439e-07, 1.8493e-10],
# [3.0193e-05, 1.7016e-07, 9.5900e-10],
# [4.4494e-07, 1.9640e-11, 8.6693e-16],
# [2.0222e-02, 2.8446e-04, 4.0014e-06],
# [4.9654e-06, 4.6637e-11, 4.3803e-16],
# [1.7639e-07, 7.9282e-13, 3.5635e-18]])
torch.sum(torch.exp(m1), 1) # 计算每一行的exp之后求和
#tensor([1.2675e-04, 6.1779e-07, 6.1028e-05, 4.3619e-04, 8.3794e-05, 3.0364e-05, 4.4495e-07, 2.0511e-02, 4.9655e-06, 1.7639e-07])
torch.exp(m1) / torch.sum(torch.exp(m1), 1).reshape(-1, 1)
#tensor([[9.9995e-01, 4.5163e-05, 2.0398e-09],
# [9.9997e-01, 2.9681e-05, 8.8098e-10],
# [9.9996e-01, 3.8138e-05, 1.4546e-09],
# [9.9998e-01, 2.4781e-05, 6.1412e-10],
# [9.9851e-01, 1.4845e-03, 2.2070e-06],
# [9.9436e-01, 5.6040e-03, 3.1583e-05],
# [9.9996e-01, 4.4139e-05, 1.9484e-09],
# [9.8594e-01, 1.3869e-02, 1.9509e-04],
# [9.9999e-01, 9.3923e-06, 8.8216e-11],
# [1.0000e+00, 4.4946e-06, 2.0202e-11]])
上述结果的每一行就是经过sofrmax转化之后每一条数据在三个不同类别上的取值。该函数和nn.functional中softmax函数功能一致。只不过需要注意的是,我们定义的softmax函数需要输入原始数据和系数矩阵,而F.softmax需要输入输出节点中经过线性运算的结果以及softmax的方向(按行还是按列)。
softmax(f, w)
#tensor([[9.9995e-01, 4.5163e-05, 2.0398e-09],
# [9.9997e-01, 2.9681e-05, 8.8098e-10],
# [9.9996e-01, 3.8138e-05, 1.4546e-09],
# [9.9998e-01, 2.4781e-05, 6.1412e-10],
# [9.9851e-01, 1.4845e-03, 2.2070e-06],
# [9.9436e-01, 5.6040e-03, 3.1583e-05],
# [9.9996e-01, 4.4139e-05, 1.9484e-09],
# [9.8594e-01, 1.3869e-02, 1.9509e-04],
# [9.9999e-01, 9.3923e-06, 8.8216e-11],
# [1.0000e+00, 4.4946e-06, 2.0202e-11]])
F.softmax(m1, 1)
#tensor([[9.9995e-01, 4.5163e-05, 2.0398e-09],
# [9.9997e-01, 2.9681e-05, 8.8098e-10],
# [9.9996e-01, 3.8138e-05, 1.4546e-09],
# [9.9998e-01, 2.4781e-05, 6.1412e-10],
# [9.9851e-01, 1.4845e-03, 2.2069e-06],
# [9.9436e-01, 5.6040e-03, 3.1583e-05],
# [9.9996e-01, 4.4139e-05, 1.9484e-09],
# [9.8594e-01, 1.3869e-02, 1.9509e-04],
# [9.9999e-01, 9.3923e-06, 8.8216e-11],
# [1.0000e+00, 4.4946e-06, 2.0202e-11]])
- Stage 2.确定目标函数
此时目标函数就是交叉熵损失函数。由于标签已经经过了哑变量转化,因此交叉熵的主体就是每条数据的真实类别对应概率的累乘结果。作为多分类问题的最通用的损失函数,我们有必要简单回顾交叉熵计算过程:
f = torch.tensor([[0.6, 0.2, 0.2], [0.3, 0.4, 0.3]])
l = torch.tensor([0, 1])
f
l
#tensor([[0.6000, 0.2000, 0.2000],
# [0.3000, 0.4000, 0.3000]])
#tensor([0, 1])
其中f代表两条数据在三个类别上通过softmax输出的比例结果,l代表这两条数据的真实标签,我们可以将这两条数据在不同类别上的概率取值看成是随机变量,而这两个随机变量在真实类别上的联合概率分布的具体取值则是0.6*0.4,进一步,交叉熵损失函数 = -log(所有数据的在真实类别上的联合概率分布) / 数据总量。据此我们可定义交叉熵损失函数如下:
def m_cross_entropy(soft_z, y):
y = y.long()
prob_real = torch.gather(soft_z, 1, y)
return (-(1/y.numel()) * torch.log(prob_real).sum())
注意,根据对数运算性质,有 l o g ( x 1 x 2 ) = l o g ( x 1 ) + l o g ( x 2 ) log(x_1x_2)=log(x_1)+log(x_2) log(x1x2)=log(x1)+log(x2),因此我们可以将交叉熵损失函数中联合概率分布的累乘转化为累加,如果是累乘可以使用以下函数进行计算。但此处更推荐使用累加而不是累乘进行计算,大家想想是什么原因?
#def m_cross_entropy(soft_z, y):
# y = y.long()
# prob_real = torch.gather(soft_z, 1, y)
# return (-(1/y.numel()) * torch.log(torch.prod(prob_real)))
gather函数基本使用方法
l
f
#tensor([0, 1])
#tensor([[0.6000, 0.2000, 0.2000],
# [0.3000, 0.4000, 0.3000]])
torch.gather(f, 1, l.reshape(-1, 1).long()) # 相当于批量索引
#tensor([[0.6000],
# [0.4000]])
再在外侧乘以-1/N即可构成哑变量情况下分类问题的交叉熵损失函数的计算结果。
-1 / 2 * (torch.log(torch.tensor(0.6) * torch.tensor(0.4)))
#tensor(0.7136)
-1 / 2 * (torch.log(torch.tensor(0.6))+torch.log(torch.tensor(0.4)))
#tensor(0.7136)
当然也可以直接使用上述定义的m_cross_entropy函数进行计算
m_cross_entropy(f, l.reshape(-1, 1).long())
#tensor(0.7136)
当然,我们也可以使用nn.CrossEntropyLoss()完成交叉熵损失函数的计算,需要注意的是,nn.CrossEntropyLoss()会自动完成softmax过程,调用该函数时,我们只需要输入线性方程计算结果即可。
f = features[: 10]
l = labels[: 10]
w = torch.arange(9).reshape(3, 3).float()
f
l
w
#tensor([[-6.0141, -4.9911, 1.0000],
# [-4.6593, -6.7657, 1.0000],
# [-5.9395, -5.2347, 1.0000],
# [-7.0262, -4.5792, 1.0000],
# [-2.3817, -5.1295, 1.0000],
# [-0.7093, -5.4693, 1.0000],
# [-4.1530, -6.8751, 1.0000],
# [-1.9636, -3.3003, 1.0000],
# [-6.5046, -6.0710, 1.0000],
# [-6.1291, -7.1835, 1.0000]])
#tensor([[0],
# [0],
# [0],
# [0],
# [0],
# [0],
# [0],
# [0],
# [0],
# [0]])
#tensor([[0., 1., 2.],
# [3., 4., 5.],
# [6., 7., 8.]])
criterion = nn.CrossEntropyLoss()
criterion(torch.mm(f, w), l.flatten())
#tensor(0.0021)
m_cross_entropy(softmax(f, w), l)
#tensor(0.0021)
需要注意的是,交叉熵损失函数本质上还是关于w参数的函数方程。我们在进行反向传播时也是将w视为叶节点,通过梯度计算逐步更新w的取值。
- Stage 3.定义优化算法
首先需要定义在softmax回归下的准确率计算函数
def m_accuracy(soft_z, y):
acc_bool = torch.argmax(soft_z, 1).flatten() == y.flatten()
acc = torch.mean(acc_bool.float())
return(acc)
上述函数的soft_z是经过softmax转化之后模型整体输出结果。其中argmax返回最大值的索引值
torch.argmax(torch.tensor([1, 2]))
#tensor(1)
而对于从0开始进行计数的类别来说,以及softmax函数的输出结果——每一行代表每一条数据在各类别上的softmax取值,我们对softmax的输出结果进行逐行的最大值索引值的计算,即可直接得出每一条数据在当前模型计算结果下所属类别的判别结果。
softmax(f, w)
torch.argmax(softmax(f, w), 1)
#tensor([[9.9995e-01, 4.5163e-05, 2.0398e-09],
# [9.9997e-01, 2.9681e-05, 8.8098e-10],
# [9.9996e-01, 3.8138e-05, 1.4546e-09],
# [9.9998e-01, 2.4781e-05, 6.1412e-10],
# [9.9851e-01, 1.4845e-03, 2.2070e-06],
# [9.9436e-01, 5.6040e-03, 3.1583e-05],
# [9.9996e-01, 4.4139e-05, 1.9484e-09],
# [9.8594e-01, 1.3869e-02, 1.9509e-04],
# [9.9999e-01, 9.3923e-06, 8.8216e-11],
# [1.0000e+00, 4.4946e-06, 2.0202e-11]])
#tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
上述准确率函数可直接输入线性方程组计算结果,也可输入softmax之后的结果,softmax本身不影响大小排序。
梯度调整的函数继续沿用sgd函数。
def sgd(params, lr):
params.data -= lr * params.grad
params.grad.zero_()
- Stage.4 训练模型
# 设置随机数种子
torch.manual_seed(420)
# 数值创建
features, labels = tensorGenCla(bias = True, deg_dispersion = [6, 2])
plt.scatter(features[:, 0], features[:, 1], c = labels)

# 设置随机数种子
torch.manual_seed(420)
# 初始化核心参数
batch_size = 10 # 每一个小批的数量
lr = 0.03 # 学习率
num_epochs = 3 # 训练过程遍历几次数据
w = torch.randn(3, 3, requires_grad = True) # 随机设置初始权重
# 参与训练的模型方程
net = softmax # 使用回归方程
loss = m_cross_entropy # 交叉熵损失函数
train_acc = []
# 模型训练过程
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w), y)
l.backward()
sgd(w, lr)
train_acc = m_accuracy(net(features, w), labels)
print('epoch %d, acc %f' % (epoch + 1, train_acc))
#- 模型调试
首先,先尝试多迭代几轮,观察模型收敛速度
# 设置随机数种子
torch.manual_seed(420)
# 迭代轮数
num_epochs = 20
# 设置初始权重
w = torch.randn(3, 3, requires_grad = True)
# 设置列表容器
train_acc = []
# 执行迭代
for i in range(num_epochs):
for epoch in range(i):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w), y)
l.backward()
sgd(w, lr)
train_acc.append(m_accuracy(net(features, w), labels))
# 绘制图像查看准确率变化情况
plt.plot(list(range(num_epochs)), train_acc)
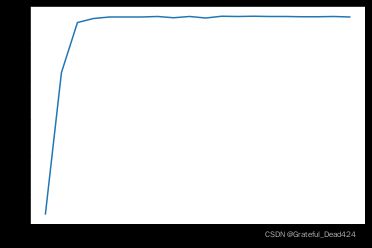
train_acc
#[tensor(0.4473),
# tensor(0.8220),
# tensor(0.9547),
# tensor(0.9653),
# tensor(0.9693),
# tensor(0.9693),
# tensor(0.9693),
# tensor(0.9707),
# tensor(0.9673),
# tensor(0.9707),
# tensor(0.9667),
# tensor(0.9713),
# tensor(0.9707),
# tensor(0.9713),
# tensor(0.9707),
# tensor(0.9707),
# tensor(0.9700),
# tensor(0.9700),
# tensor(0.9707),
# tensor(0.9693)]
和此前的逻辑回归实验结果类似,在数据内部离散程度较低的情况下,模型收敛速度较快。当然,这里我们可以进行简单拓展,那就是当每一轮epoch时w都进行不同的随机取值,会不会影响模型的收敛速度。
# 取10组不同的w,在迭代10轮的情况下观察其收敛速度
for i in range(10):
# torch.manual_seed(420)
w = torch.randn(3, 3, requires_grad = True)
train_acc = []
for epoch in range(10):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w), y)
l.backward()
sgd(w, lr)
train_acc.append(m_accuracy(net(features, w), labels))
plt.plot(list(range(10)), train_acc)
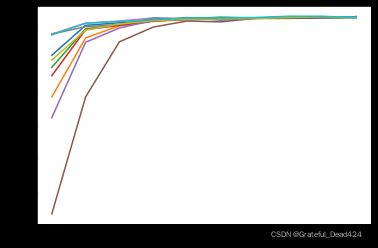
能够发现,尽管初始w的随机取值会影响前期模型的准确率,但在整体收敛速度较快的情况下,基本在5轮左右模型都能达到较高的准确率。也就是说,损失函数的初始值点各不相同,但通过一轮轮梯度下降算法的迭代,都能够找到(逼近)最小值点。此处即验证了梯度下降算法本身的有效性,同时也说明对于该数据集来说,找到(逼近)损失函数的最小值点并不困难。
二、softmax回归的快速实现
接下来,尝试通过调库快速sofrmax回归。经过一轮手动实现,我们已经对softmax回归的各种建模细节以及数学运算过程已经非常熟悉,调库实现也就更加容易。
- 定义核心参数
batch_size = 10 # 每一个小批的数量
lr = 0.03 # 学习率
num_epochs = 3 # 训练过程遍历几次数据
- 数据准备
# 设置随机数种子
torch.manual_seed(420)
# 创建数据集
features, labels = tensorGenCla(deg_dispersion = [6, 2])
labels = labels.float() # 损失函数要求标签也必须是浮点型
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
features
#tensor([[-6.0141, -4.9911],
# [-4.6593, -6.7657],
# [-5.9395, -5.2347],
# ...,
# [ 6.4622, 4.1406],
# [ 5.7278, 9.2208],
# [ 4.9705, 3.1236]])
- Stage 1.定义模型
class softmaxR(nn.Module):
def __init__(self, in_features=2, out_features=3, bias=False):
# 定义模型的点线结构
super(softmaxR, self).__init__()
self.linear = nn.Linear(in_features, out_features)
def forward(self, x): # 定义模型的正向传播规则
out = self.linear(x)
return out
# 实例化模型和
softmax_model = softmaxR()
由于我们所采用的
CrossEntropyLoss类进行的损失函数求解,该类会自动对输入对象进行softmax转化,因此上述过程仍然只是构建了模型基本架构。
- Stage 2.定义损失函数
criterion = nn.CrossEntropyLoss()
- Stage 3.定义优化方法
optimizer = optim.SGD(softmax_model.parameters(), lr = lr)
- Stage 4.模型训练
def fit(net, criterion, optimizer, batchdata, epochs):
for epoch in range(epochs):
for X, y in batchdata:
zhat = net.forward(X)
y = y.flatten().long() # 损失函数计算要求转化为整数
loss = criterion(zhat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
接下来,即可执行模型训练
fit(net = softmax_model,
criterion = criterion,
optimizer = optimizer,
batchdata = batchData,
epochs = num_epochs)
查看模型训练结果
softmax_model
#softmaxR(
# (linear): Linear(in_features=2, out_features=3, bias=True)
)
# 查看模型参数
print(list(softmax_model.parameters()))
#[Parameter containing:
#tensor([[-0.3947, -0.7395],
# [ 0.1667, -0.2784],
# [ 0.6445, 0.2392]], requires_grad=True), Parameter containing:
#tensor([-0.9082, 1.5810, -0.6922], requires_grad=True)]
# 计算交叉熵损失
criterion(softmax_model(features), labels.flatten().long())
#tensor(0.1668, grad_fn=)
# 借助F.softmax函数,计算准确率
m_accuracy(F.softmax(softmax_model(features), 1), labels)
#tensor(0.9620)
F.softmax(softmax_model(features), 1)
#tensor([[9.5957e-01, 4.0428e-02, 6.4515e-06],
# [9.5540e-01, 4.4593e-02, 5.5352e-06],
# [9.6062e-01, 3.9378e-02, 5.7618e-06],
# ...,
# [4.5679e-03, 1.5779e-01, 8.3765e-01],
# [2.4782e-04, 2.0569e-02, 9.7918e-01],
# [2.3951e-02, 3.7729e-01, 5.9876e-01]], grad_fn=)
2.模型调试
首先,上述结果能否在多迭代几轮的情况下逐步提升
# 设置随机数种子
torch.manual_seed(420)
# 创建数据集
features, labels = tensorGenCla(deg_dispersion = [6, 2])
labels = labels.float() # 损失函数要求标签也必须是浮点型
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
#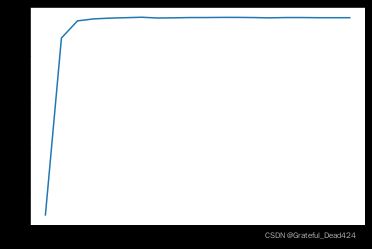
和手动实现相同,此处模型也展示了非常快的收敛速度。当然需要再次强调,当num_epochs=20时,SF1参数已经训练了(19+18+…+1)次了。
然后考虑增加数据集分类难度
# 设置随机数种子
torch.manual_seed(420)
# 创建数据集
features, labels = tensorGenCla(deg_dispersion = [6, 4])
labels = labels.float() # 损失函数要求标签也必须是浮点型
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
#
# 设置随机数种子
torch.manual_seed(420)
# 初始化核心参数
num_epochs = 20
SF1 = softmaxR()
cr1 = nn.CrossEntropyLoss()
op1 = optim.SGD(SF1.parameters(), lr = lr)
# 创建列表容器
train_acc = []
# 执行建模
for epochs in range(num_epochs):
fit(net = SF1,
criterion = cr1,
optimizer = op1,
batchdata = batchData,
epochs = epochs)
epoch_acc = m_accuracy(F.softmax(SF1(features), 1), labels)
train_acc.append(epoch_acc)
# 绘制图像查看准确率变化情况
plt.plot(list(range(num_epochs)), train_acc)
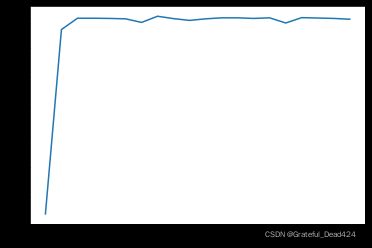
train_acc
#[tensor(0.1420),
# tensor(0.7607),
# tensor(0.7987),
# tensor(0.7987),
# tensor(0.7980),
# tensor(0.7967),
# tensor(0.7847),
# tensor(0.8053),
# tensor(0.7973),
# tensor(0.7913),
# tensor(0.7967),
# tensor(0.8000),
# tensor(0.8000),
# tensor(0.7980),
# tensor(0.8000),
# tensor(0.7827),
# tensor(0.8007),
# tensor(0.7993),
# tensor(0.7980),
# tensor(0.7953)]
我们发现,收敛速度仍然很快,模型很快就到达了比较稳定的状态。但和此前的逻辑回归实验相同,模型结果虽然比较稳定,但受到数据集分类难度提升影响,模型准确率却不高,基本维持在80%左右。一般来说,此时就代表模型抵达了判别效力上界,此时模型已经无法有效捕捉数据集中规律。
但到底什么叫做模型判别效力上界呢?从根本上来说就是模型已经到达(逼近)损失函数的最小值点,但模型的评估指标却无法继续提升。首先,我们可以初始选择多个w来观察损失函数是否已经逼近最小值点而不是落在了局部最小值点附近。
# 初始化核心参数
cr1 = nn.CrossEntropyLoss()
# 创建列表容器
train_acc = []
# 执行建模
for i in range(10):
SF1 = softmaxR()
op1 = optim.SGD(SF1.parameters(), lr = lr)
fit(net = SF1,
criterion = cr1,
optimizer = op1,
batchdata = batchData,
epochs = 10)
epoch_acc = m_accuracy(F.softmax(SF1(features), 1), labels)
train_acc.append(epoch_acc)
train_acc
#[tensor(0.7940),
# tensor(0.7900),
# tensor(0.7960),
# tensor(0.7880),
# tensor(0.7887),
# tensor(0.7980),
# tensor(0.7980),
# tensor(0.7873),
# tensor(0.7960),
# tensor(0.8000)]
初始化不同的w发现最终模型准确率仍然是80%左右,也从侧面印证迭代过程没有问题,模型已经到达(逼近)最小值点。也就是说问题并不是出在损失函数的求解上,而是出在损失函数的构造上。此时的损失函数哪怕取得最小值点,也无法进一步提升模型效果。而损失函数的构造和模型的构造直接相关,此时若要进一步提升模型效果,就需要调整模型结构了。这也将是下一阶段模型调优核心讨论的内容。
补充阅读内容
【损失损失函数取值和模型评估指标之间关系】
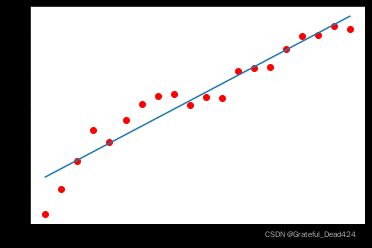
很多时候,损失函数求得最小值也不一定能够使得模型获得较好的拟合效果。
def plot_polynomial_fit(x, y, deg):
p = np.poly1d(np.polyfit(x, y, deg))
t = np.linspace(0, 1, 200)
plt.plot(x, y, 'ro', t, p(t), '-')
n_dots = 20
x = np.linspace(0, 1, n_dots) # 从0到1,等宽排布的20个数
y = np.sqrt(x) + 0.2*np.random.rand(n_dots) - 0.1
plot_polynomial_fit(x, y, 1)
【关于PyTorch GPU运算的相关介绍】
在课程刚开始的时候,我们就介绍了关于pytorch GPU版本的安装,如果此前安装过GPU版本PyTorch,此处就可以使用GPU进行运算了。在PyTorch 1.0版本之后,CPU计算的代码和GPU计算的代码基本可以通用,甚至可以通过全局变量直接控制一份代码在CPU和GPU上快速切换。
当然,GPU运算也分为分布式GPU计算和单GPU运算,二者在代码规则上并无区别,单在计算流程上略有不同,此处先介绍单GPU计算方法,分布式GPU运算将在后续进行讲解。
但通过实践我们能够看出,GPU计算在小规模运算时并无优势,另外,由CPU运算切换至GPU运算也非常便捷,因此如果暂时没有GPU环境的同学也不用太担心,可用先了解GPU运算背后原理,待有条件时再进行实践。
- 测试是否可进行GPU计算
根据此前介绍,我们可用通过torch.cuda.is_available()判断是否可用GPU进行计算
torch.cuda.is_available()
#True
- CPU存储与GPU存储
CPU运算和GPU运算的核心区别就在于张量存储位置的区别,如果张量是存储在GPU上,则张量运算时就会自动调用CUDA进行GPU运算。默认情况下创建的张量是存储在CPU内存上,也就是默认情况张量都是CPU运算。
tc = torch.randn(4)
tc
#tensor([ 1.1650, 2.0070, 0.6959, -0.4931])
通过.cuda或者.cpu即可生成一个存储在gpu或者cpu上的相同数据的对象
tg = tc.cuda()
tg
#tensor([ 1.1650, 2.0070, 0.6959, -0.4931], device='cuda:0')
tg.cpu()
#tensor([ 1.1650, 2.0070, 0.6959, -0.4931])
当然,我们也可用通过.to()方法来进行转化
tg.to('cpu')
#tensor([ 1.1650, 2.0070, 0.6959, -0.4931])
tc.to('cuda')
#tensor([ 1.1650, 2.0070, 0.6959, -0.4931], device='cuda:0')
- device属性
通过张量的device属性,我们能够查看张量存储信息,并且能在创建张量时就直接创建存储在同一个GPU上的张量
tg.device
#device(type='cuda', index=0)
torch.randn(4, device=tg.device)
#tensor([ 0.2777, 0.2940, 0.9860, -0.4056], device='cuda:0')
- CPU张量和GPU张量彼此不能相互运算
torch.dot(tg, tc)
#RuntimeError: expected all tensors to be on the same device. Found: cuda:0, cpu
当然,如果是分布式GPU运算,存储在不同GPU上的张量彼此也无法运算
- 模型参数存储位置
通过前例我们也发现了,在实例化模型的过程中,如果需要在GPU上运行,则需要在实例化过程对模型进行.cuda操作,核心作用就是将模型的参数保存在GPU上,从而可以和同样在GPU上的数据进行计算。当然,我们可以通过以下方式让模型和数据自动在cpu和gpu上切换。
CUDA = torch.cuda.is_available()
if CUDA:
features = features.cuda()
labels = labels.cuda()
model = model_class().cuda()
else:
model = model_class()
- 模型运算
接下来,我们可以尝试将上述模型的运行过程放在GPU上执行。
#创建数据
torch.manual_seed(420)
features, labels = tensorGenCla(deg_dispersion = [6, 4])
labels = labels.float()
features = features.cuda()
labels = labels.cuda()
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
#此时features已保存在GPU上,根据标记能看出目前是保存在第一块GPU上。如果要将其转移至CPU上,可通过.cpu方法在cpu上新生成一个数据。
而利用GPU进行计算时,则需要在实例化模型时加上.cuda,使得模型初始化参数也保存在GPU上。
# 初始化核心参数
num_epochs = 20
SF4 = softmaxR().cuda()
cr4 = nn.CrossEntropyLoss()
op4 = optim.SGD(SF4.parameters(), lr = lr)
# 创建列表容器
train_acc = []
import time
start = time.perf_counter()
# 执行建模
for epochs in range(num_epochs):
fit(net = SF4,
criterion = cr4,
optimizer = op4,
batchdata = batchData,
epochs = epochs)
epoch_acc = m_accuracy(F.softmax(SF4(features), 1), labels)
epoch_acc = epoch_acc.cpu()
train_acc.append(epoch_acc)
# 绘制图像查看准确率变化情况
plt.plot(list(range(num_epochs)), train_acc)
finish = time.perf_counter()
time_cost = finish - start
print("计算时间:%s" % time_cost)
#计算时间:14.391150299999936
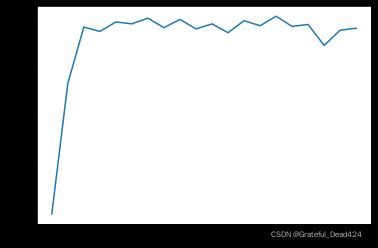
从直观感受上来看,在当前运算规模上,GPU的计算速度并不比CPU快。
#创建数据
torch.manual_seed(420)
features, labels = tensorGenCla(deg_dispersion = [6, 4])
labels = labels.float()
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = 10, shuffle = True)
#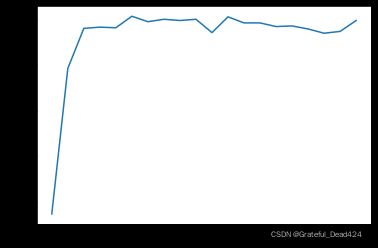
限于在当前的运算规模,GPU运算对计算效率并不如CPU。但针对此模型,我们可以增加带入训练的数据集大小、减少每次训练的小批数据量(增加每一个epoch的迭代次数)、增加整体迭代次数,在运算时间超过4小时时,GPU计算速度将超过CPU计算速度,如以下规模的计算:
【以下代码运算量较大,谨慎运行!!!】
【以下代码运算量较大,谨慎运行!!!】
【以下代码运算量较大,谨慎运行!!!】
#创建数据
torch.manual_seed(420)
features, labels = tensorGenCla(num_examples=100000, deg_dispersion = [6, 4])
labels = labels.float()
features = features.cuda()
labels = labels.cuda()
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
# 设置随机数种子
torch.manual_seed(420)
# 初始化核心参数
num_epochs = list(range(1, 61))
SF4 = softmaxR().cuda()
cr4 = nn.CrossEntropyLoss()
op4 = optim.SGD(SF4.parameters(), lr = lr, momentum=0.3)
# 创建列表容器
train_acc = []
# 减少每批输入的数据量
batchData = DataLoader(data, batch_size = 5, shuffle = True)
import time
start = time.perf_counter()
# 执行建模
for epochs in num_epochs:
fit(net = SF4,
criterion = cr4,
optimizer = op4,
batchdata = batchData,
epochs = epochs)
epoch_acc = m_accuracy(F.softmax(SF4(features), 1), labels)
epoch_acc = epoch_acc.cpu()
train_acc.append(epoch_acc)
# 绘制图像查看准确率变化情况
plt.plot(num_epochs, train_acc)
finish = time.perf_counter()
time_cost = finish - start
print("计算时间:%s" % time_cost)
# 设置随机数种子
torch.manual_seed(420)
features, labels = tensorGenCla(num_examples=100000, deg_dispersion = [6, 4])
labels = labels.float()
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = 5, shuffle = True)
# 初始化核心参数
num_epochs = list(range(1, 61))
SF3 = softmaxR()
cr3 = nn.CrossEntropyLoss()
op3 = optim.SGD(SF3.parameters(), lr = lr, momentum=0.3)
# 创建列表容器
train_acc = []
import time
start = time.perf_counter()
# 执行建模
for epochs in num_epochs:
fit(net = SF3,
criterion = cr3,
optimizer = op3,
batchdata = batchData,
epochs = epochs)
epoch_acc = m_accuracy(F.softmax(SF3(features), 1), labels)
train_acc.append(epoch_acc)
# 绘制图像查看准确率变化情况
plt.plot(num_epochs, train_acc)
finish = time.perf_counter()
time_cost = finish - start
print("计算时间:%s" % time_cost)
通过此前的实验我们发现,在数据量和运算规模较小的情况下(当然也是神经网络层数较少的原因),GPU运算速度甚至要慢于CPU的计算速度,因此一般课上我们都采用CPU进行计算,待有接触到大规模神经网络的时候再开启GPU加速,当然肯定还是处在CPU可运算的范围。
【本节函数模块添加】
本节课程结束后,需要将以下函数写入torchLearning模块,方便后续调用。
- sigmoid、logistic、cal、accuracy、cross_entropy
- acc_zhat、softmax、m_cross_entropy、m_accuracy
下节课开始,我们将正式进入到神经网络优化算法部分内容。