深度学习-Embedding技术总结
深度学习Embedding技术总结
- 介绍下Word2vec
- Word2vec如何进行负采样
- Word2vec对顺序敏感吗
- 介绍下PageRank
- 介绍下Item2vec
- 介绍下Deepwalk
- 介绍下Node2vec
- 用户Embedding方法有哪些
- Embedding冷启动怎么做
介绍下Word2vec
1. Word2vec是什么
Word2vec 是 “word to vector” 的简称,顾名思义,Word2vec 是一个生成对“词”的向量表达的模型。 Word2vec,其实是词嵌入( word embedding) 的一种实现方法。
为了训练 Word2vec 模型,需要准备由一组句子组成的语料库。假设其中一个长度为 T T T 的句子为 w 1 , w 2 , . . . , w T w_1,w_2,...,w_T w1,w2,...,wT,假定每个词都跟其相邻的词的关系最紧密,即每个词都是由相邻词决定的(CBOW模型的主要原理),或者每个词都决定了相邻的词(Skip-gram模型的主要原理)。CBOW模型的输入是 w t w_t wt 周边的词,预测的输出是 w t w_t wt,而 Skip-gram 则相反。经验上讲,Skip-gram 的效果较好。
小结:
1)如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』;
2)而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
2. Skip-gram和CBOW模型的简单结构
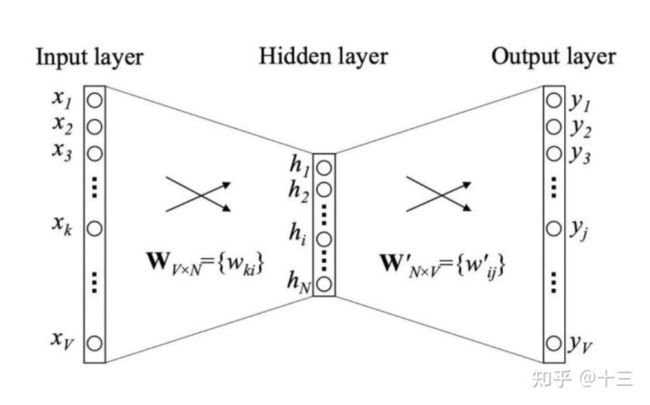
假设语料库中词的数量为 V V V,Word2vec的网络结构可表示为如下形式:
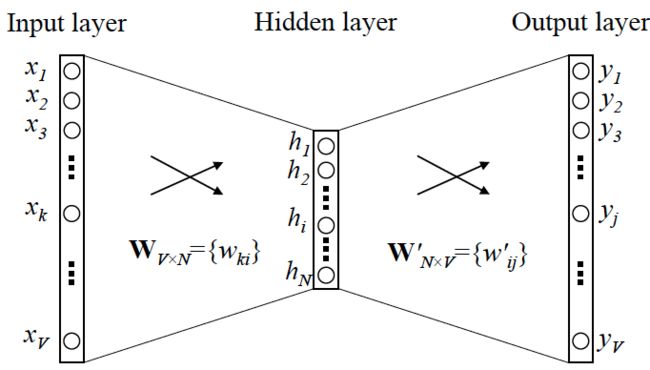
那么,这个图究竟是怎么来的? 因为 Word2vec 本身也是基于语言模型,根据条件概率 p ( w t j ∣ w t ) p(w_{t_j}|w_t) p(wtj∣wt) 的定义,把两个向量的乘积在套上一个 softmax 的形式,就转换成了该图所表示的神经网络结构。左侧输入为某个词 x x x 的 one-hot encoder,右侧输出为这个词的预测结果 y y y (向量维度和 x x x 相同),也就是在 V V V 个词上预测的概率,目标是希望神经网络预测的 y y y 和真实的 y y y 的 one-hot encoder 能够一模一样。
需要说明一点:隐层的激活函数其实是线性的,相当于没做任何处理(这也是 Word2vec 简化之前语言模型的独到之处),我们可以通过反向传播算法训练这个神经网络。用神经网络表示 Word2vec 的模型架构后,在训练过程中就可以通过梯度下降法来求解模型参数。
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个 x x x 的 one-hot encoder: [1,0,0,…,0],它能表示『吴彦祖』这个单词,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,这些权重的个数,跟隐含层节点数是一致的,从而这些权重组成一个向量 v x \pmb{v}_x vvvx 来表示 x x x,而因为每个词语的 one-hot encoder 里面 1 的位置是不同的,所以,这个向量 v x \pmb{v}_x vvvx 就可以用来唯一表示 x x x。
在获得输入向量矩阵 W V × N \pmb{W}_{V \times N} WWWV×N 后,其中每一行对应的权重向量就是通常意义上的“词向量”,也就是上面所说的 v x \pmb{v}_x vvvx。于是,这个权重矩阵自然转换成了 Word2vec 的查找表(lookup table)。例如,输入向量是 10000 个词组成的 one-hot 向量,隐层维度是 300 维,那么输入层到隐层的权重矩阵为 10000 × \times × 300 维。在转换为词向量查找表后,每行的权重即成了对应词的 Embedding 向量。
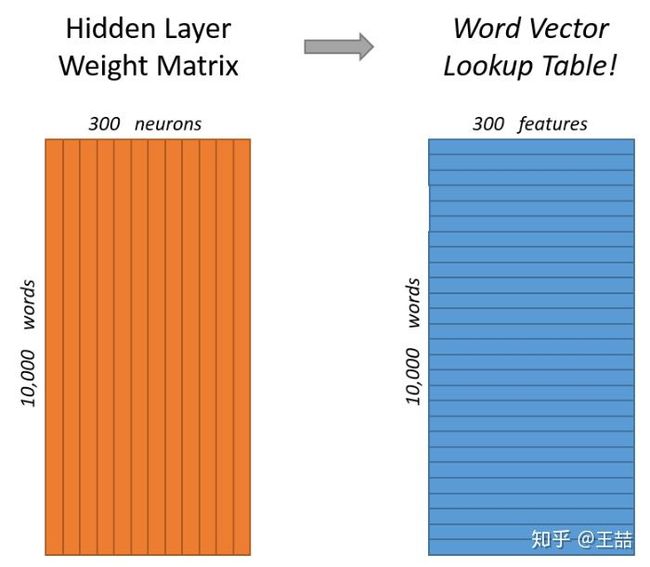
以上,即为 Word2vec 的精髓!
此外,输出 y y y 也是用 V V V 个节点表示的,对应V个词语,所以其实,我们把输出节点置成 [1,0,0,…,0],它也能表示『吴彦祖』这个单词,但是激活的是隐含层到输出层的权重,这些权重的个数,跟隐含层一样,也可以组成一个向量 v y \pmb{v}_y vvvy,跟上面提到的 v x \pmb{v}_x vvvx 维度一样,并且可以看做是词语『吴彦祖』的另一种词向量。而这两种词向量 v x \pmb{v}_x vvvx 和 v y \pmb{v}_y vvvy,正是 Mikolov 在论文里所提到的,『输入向量』和『输出向量』,一般我们用『输入向量』。
需要提到一点的是,这个词向量的维度(与隐含层节点数一致)一般情况下要远远小于词语总数 V V V 的大小,所以 Word2vec 本质上是一种降维操作——把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
3. word2vec两种训练方法损失函数推导
Skip-gram模型

可以看成是 单个x->单个y 模型的并联,cost function 是单个 cost function 的累加(取log之后)。
为了产生模型的正样本,我们选一个长度为2c+1(目标词前后各选c个词)的滑动窗口,从句子左边滑到右边,每滑一次,窗口中的词就形成了我们的一个正样本。
有了训练样本之后我们就可以着手定义优化目标了,既然每个词 w t w_t wt 都决定了相邻词 w t j w_{t_j} wtj,基于极大似然,我们希望所有样本的条件概率 p ( w t + j ∣ w t ) p(w_{t+j}|w_t) p(wt+j∣wt) 之积最大,这里我们使用log probability。我们的目标函数有了:

接下来的问题是怎么定义 p ( w t + j ∣ w t ) p(w_{t+j}|w_t) p(wt+j∣wt) ,作为一个多分类问题,最简单最直接的方法当然是直接用softmax函数,我们又希望用向量 w t w_t wt 表示每个词w,用词之间的内积距离 v i T v j v_i^Tv_j viTvj 表示语义的接近程度,那么我们的条件概率的定义就可以很直观的写出。

其中, w O w_O wO 代表 w t + j w_{t+j} wt+j,被称为输出词; w I w_I wI 代表 w t w_t wt,被称为输入词。
CBOW模型
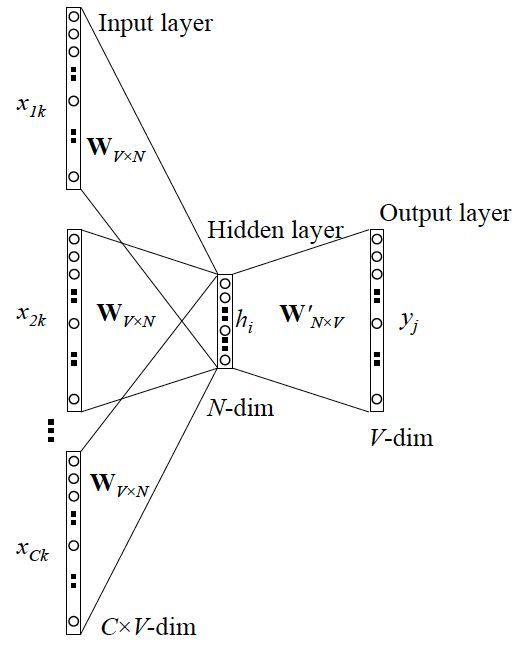
和 Skip-gram 的模型并联不同,这里是输入变成了多个单词,所以要对输入处理下(一般是求和然后平均),输出的 cost function 不变。
目标函数为:
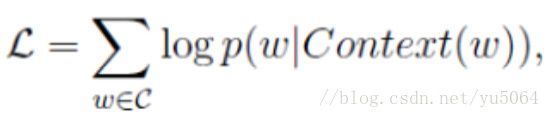
其中, w w w 表示语料库 C C C 中任意一个词。
参考文章
- [NLP] 秒懂词向量Word2vec的本质
- 万物皆Embedding,从经典的word2vec到深度学习基本操作item2vec
- 世上最通俗的理解word2vec
- 浅谈word2vec
- 图解word2vec
- word2vec是如何得到词向量的?
- Bert比之Word2Vec,有哪些进步呢?
- word2vec(二):面试!考点!都在这里
- nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
- 理解 Word2Vec 之 Skip-Gram 模型
- word2vec的通俗理解
- 词语向量化-word2vec简介和使用
- Word2Vec的参数解释
- 一文说懂Cbow和Skipgram
- word2vec中的CBOW模型
- 超详细总结之Word2Vec(一)原理推导
- Word2Vec概述与基于Hierarchical Softmax的CBOW和Skip-gram模型公式推导
- skip-gram和cbow优缺点?
Word2vec如何进行负采样
标准Word2vec存在的问题
以 Skip-gram 模型为例,其核心在于使⽤softmax运算得到给定中心词 w c w_c wc 来⽣成背景词 w o w_o wo 的条件概率:
![]()
该条件概率相应的对数损失:
![]()
由于softmax运算考虑了背景词可能是词典 V V V 中的任⼀词,以上损失包含了词典大小数目项的累加。其实,不论是跳字模型还是连续词袋模型,由于条件概率使用了softmax运算,每⼀步的梯度计算都包含词典大小数目项的累加。对于含几十万或上百万词的较大词典,每次的梯度计算开销可能过大。为了降低该计算复杂度,提出了两种近似训练⽅法,即负采样(negative sampling)和 层序softmax(hierarchical softmax)。
负采样
负采样修改了原来的目标函数。给定中心词 w c w_c wc 的⼀个背景窗口,我们把背景词 w o w_o wo 出现在该背景窗口看作⼀个事件,并将该事件的概率计算为:
![]()
其中的 σ \sigma σ 函数与sigmoid激活函数的定义相同:
![]()
我们先考虑最大化文本序列中所有该事件的联合概率来训练词向量。具体来说,给定⼀个长度为 T T T 的文本序列,设时间步 t t t 的词为 w ( t ) w^{(t)} w(t) 且背景窗口大小为 m m m,考虑最大化联合概率 :

然而,以上模型中包含的事件仅考虑了正类样本。这导致当所有词向量相等且值为无穷大时,以上的联合概率才被最大化为1。很明显,这样的词向量毫无意义。负采样通过采样并添加负类样本使目标函数更有意义。设背景词 w o w_o wo 出现在中心词 w c w_c wc 的⼀个背景窗口为事件 P P P,我们根据分布 p ( w ) p(w) p(w) 采样 K K K 个未出现在该背景窗口中的词,即噪声词。设噪声词 w k ( k = 1 , 2 , . . . , K ) w_k(k=1,2,...,K) wk(k=1,2,...,K) 不出现在中心词 w c w_c wc 的该背景窗口为事件 N k N_k Nk。假设同时含有正类样本和负类样本的事件 P P P, N 1 , . . . , N k N_1,...,N_k N1,...,Nk 相互独立,负采样将以上需要最大化的仅考虑正类样本的联合概率改写为:

其中条件概率被近似表示为:

设文本序列中时间步 t t t 的词 w ( t ) w^{(t)} w(t) 在词典中的索引为 i t i_t it,噪声词 w k w_k wk 在词典中的索引为 h k h_k hk。有关以上条件概率的对数损失为:



现在,训练中每⼀步的梯度计算开销不再与词典大小相关,而与 K K K 线性相关。当 K K K 取较小的常数时,负采样在每⼀步的梯度计算开销较小。
小结
将负采样近似训练方法和标准word2vec进行对比,可以发现负采样在标准word2vec的基础上做了两点改进:
- 1)针对softmax运算导致的每次梯度计算开销过大,将softmax函数调整为sigmoid函数,当然对应的含义也由给定中心词,每个词作为背景词的概率,变成了给定中心词,每个词出现在背景窗口中的概率;
- 2)进行负采样,引入负样本,负采样的名字就是取了第二个改进点。
参考文章
- 自然语言处理-word2vec-负采样/Negative Sampling
- word2vec(二):面试!考点!都在这里
- word2vec中的负采样与分层softmax
- Word2Vec介绍: 为什么使用负采样(negtive sample)?
Word2vec对顺序敏感吗
对顺序敏感的原因,窗口大小选用多少
窗口大小影响 词 和前后多少个词的关系,和语料中语句长度有关,建议可以统计一下语料中,句子长度的分布,再来设置window大小。一般设置成8。
参考文章
- 关于word2vec,我有话要说
- word2vec的经验总结
介绍下PageRank
1. 回顾下TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
上述引用总结就是, 一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。这也就是TF-IDF的含义。TF-IDF分为 TF 和 IDF,下面分别介绍这个两个概念。
1.1 TF
TF(Term Frequency, 词频)表示词条在文本中出现的频率,这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)。TF用公式表示如下
![]()
其中, n i , j n_{i,j} ni,j 表示词条 t i t_i ti 在文档 d j d_j dj 中出现的次数, T F i , j TF_{i,j} TFi,j 就是表示词条 t i t_i ti 在文档 d j d_j dj 中出现的频率。
但是,需要注意, 一些通用的词语对于主题并没有太大的作用, 反倒是一些出现频率较少的词才能够表达文章的主题, 所以单纯使用是TF不合适的。权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。所有统计的文章中,一些词只是在其中很少几篇文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大。IDF就是在完成这样的工作。
1.2 IDF
IDF(Inverse Document Frequency,逆文件频率)表示关键词的普遍程度。如果包含词条 i i i 的文档越少, IDF越大,则说明该词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

其中, ∣ D ∣ |D| ∣D∣ 表示所有文档的数量, j : t i ∈ d j j:t_i \in d_j j:ti∈dj 表示包含词条 t i t_i ti 的文档数量,为什么这里要加 1 呢?主要是防止包含词条 t i t_i ti 的数量为 0 从而导致运算出错的现象发生。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语,表达为:
![]()
2. PageRank的作用
PageRank算法可以用来计算网络中每个节点的重要性,即PR值。
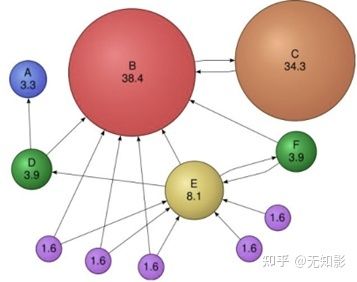
思考:
PageRank相比TF-IDF的优势?
参考文章
- TF-IDF 原理与实现
- TF-IDF与余弦相似性的应用(一):自动提取关键词
- 什么是 tf-idf ?
- PageRank全家桶:PR、PPR、HK-PR、GPR和TPR
- 机器学习十大经典算法-PageRank(附实践代码)
- 从PageRank到反欺诈与TextRank
- PageRank算法详解
- [算法系列03] 浅谈PageRank算法
- PageRank算法原理与实现
- TF-IDF算法和TextRank算法的分析比较
介绍下Item2vec
在word2vec诞生之后,embedding的思想迅速从NLP领域扩散到几乎所有机器学习的领域,我们既然可以对一个序列中的词进行embedding,那自然可以对用户购买序列中的一个商品,用户观看序列中的一个电影进行embedding。而广告、推荐、搜索等领域用户数据的稀疏性几乎必然要求在构建DNN之前对user和item进行embedding后才能进行有效的训练。
具体来讲,如果item存在于一个序列中,item2vec的方法与word2vec没有任何区别。而如果我们摒弃序列中item的空间关系,在原来的目标函数基础上,自然是不存在时间窗口的概念了,取而代之的是item set中两两之间的条件概率。
item2vec的目标函数如下:

其表示大小为K的item set中两两item的log probability之和
小结:
相比于Word2vec利用“词序列”生成词Embedding。Item2vec利用“物品序列”构造物品Embedding。 其中物品序列是由指定用户的浏览购买等行为产生的历史行为序列。
其中 V V V 代表总item个数, N N N 代表item向量的维度,即隐层神经元个数。Item2vec和Word2vec的唯一不同在于,Item2vec没有使用时间窗口的概念,认为一个序列中任意两个物品都相关。item2vec是为了得到item embedding 和 user embedding,然后利用用户向量和物品向量的相似性,在召回层快速得到候选集合。
- item embedding: 收集用户行为序列,采用word2vec思想,生成每个item的Embedding
- user embedding: 由历史item embedding AVG pooling、 SUM pooling 或聚类得到。
参考文章
- 万物皆Embedding,从经典的word2vec到深度学习基本操作item2vec
- DNN论文分享 - Item2vec
- 论文|Item2vec中值得细细品味的8个经典tricks和thinks
- 推荐系统中如何做 User Embedding?
- 【推荐系统】item2vec
- item2vec详解
- 从用户行为去理解内容-item2vec及其应用
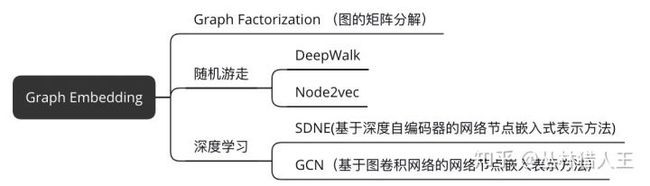
介绍下Deepwalk
1. 直观理解Graph Embedding
Graph Embedding研究的就是用向量来表示图上的节点,且保留了这样一个重要的性质:在图上距离较近的节点,在向量空间中的距离也较近。下图这个例子可以帮助我们理解这个过程:
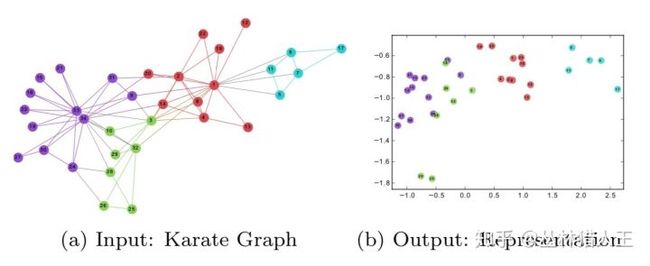
Deepwalk其实属于Graph Embedding中的一种实现方法。
更多内容可阅读图上的机器学习系列-聊聊DeepWalk这篇文章。
2. Deepwalk的思想
在NLP任务中,word2vec是一种常用的word embedding方法,word2vec通过语料库中的句子序列来描述词与词的共现关系,进而学习到词语的向量表示。
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
获取足够数量的节点访问序列后,使用skip-gram model 进行向量学习。
3. 算法
整个DeepWalk算法包含两部分,一部分是随机游走的生成,另一部分是参数的更新。
算法的流程如下:

其中第2步是构建Hierarchical Softmax,第3步对每个节点做γ次随机游走,第4步打乱网络中的节点,第5步以每个节点为根节点生成长度为t的随机游走,第7步根据生成的随机游走使用skip-gram模型利用梯度的方法对参数进行更新。
参数更新的细节如下:

文中还使用了Hierarchical Softmax的方法,这也是词向量中用到的一个重要方法。
总结:
总的来说这篇论文算是network embedding的开山之作,它将NLP中词向量的思想借鉴过来做网络的节点表示,提供了一种新的思路,后面会有好几篇论文使用的也是这种思路,都是利用随机游走的特征构建概率模型,用词向量中Negative Sampling的思想解决相应问题。
思考:
DeepWalk相比序列embedding优缺点,对哪一部分item影响最大?
参考文章
- 【Graph Embedding】DeepWalk:算法原理,实现和应用
- 【论文笔记】DeepWalk
- 生动详解deepwalk算法(graph embedding)
- 网络表示学习(一)–DeepWalk、LINE、Node2Vec、HARP、GraphGAN
- 从入门DeepWalk到实践Node2vec
- 图上的机器学习系列-聊聊DeepWalk
介绍下Node2vec
1. Node2vec核心思想(优化目标)
Node2Vec是一份基于DeepWalk的延伸工作,它改进了DeepWalk随机游走的策略。
Node2Vec认为,现有的方法无法很好的保留网络的结构信息,例如下图所示,有一些点之间的连接非常紧密(比如u, s1, s2, s3, s4),他们之间就组成了一个社区(community)。网络中可能存在着各种各样的社区,而有的结点在社区中可能又扮演着相似的角色(比如u与s6)。
Node2Vec的优化目标为以下两个:
- 让同一个社区内的结点表示能够相互接近(同质性DFS,如u, s1, s2, s3, s4)
- 或在不同社区内扮演相似角色的结点表示也要相互接近。(结构性BFS,如u和s6)
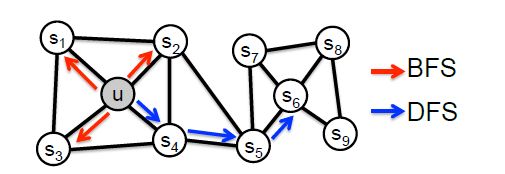
为此,Node2Vec就要在DeepWalk现有的基础上,对随机游走的策略进行优化。Node2Vec提出了两种游走策略:广度优先策略和深度优先策略。
关于同质性和结构性
Node2vec是在DeepWalk的基础上更进一步,通过调整随机游走权重的方法使graph embedding的结果在网络的同质性(homophily)和结构对等性(structural equivalence,下面简称结构性)中进行权衡。
其中,网络的“同质性”指的是距离相近节点的embedding应该尽量近似,如上图中,节点u与其相连的节点s1、s2、s3、s4的embedding表达应该是接近的,这就是“同质性“的体现。
“结构性”指的是结构上相似的节点的embedding应该尽量接近,上图中节点u和节点s6都是各自局域网络的中心节点,结构上相似,其embedding的表达也应该近似,这是“结构性”的体现。
DFS擅长学习网络的同质性,BFS擅长学习网络的结构性。
2. 游走策略
就如上图的标注所示,深度优先游走策略将会限制游走序列中出现重复的结点,防止游走掉头,促进游走向更远的地方进行。而广度优先游走策略相反将会促进游走不断的回头,去访问上一步结点的其他邻居结点。
这样一来,当使用广度优先策略时,游走将会在一个社区内长时间停留,使得一个社区内的结点互相成为context,这也就达到了第一条优化目标。相反,当使用深度优先的策略的时候,游走很难在同一个社区内停留,也就达到了第二条优化目标。
那么如何达到这样的两种随机游走策略呢,这里需要用到两个超参数p和q用来控制深度优先策略和广度优先策略的比重,如下图所示。
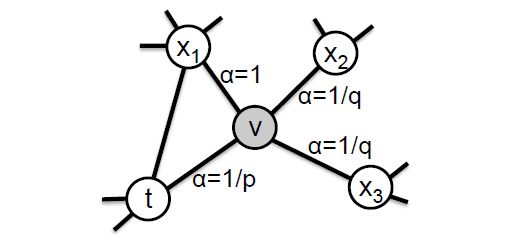
假设现在游走序列从t走到v,这时候需要算出三个系数,分别作为控制下一步走向方向的偏置α
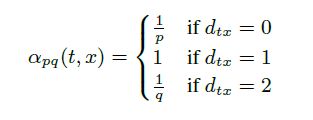
其中d(t, x)代表t结点到下一步结点x的最短路,最多为2。
- 当d(t, x)=0时,表示下一步游走是回到上一步的结点;
- 当d(t, x)=1时,表示下一步游走跳向t的另外一个邻居结点;
- 当d(t, x)=2时,表示下一步游走向更远的结点移动。
而Node2Vec同时还考虑了边权w的影响,所以最终的偏置系数以及游走策略为
![]()
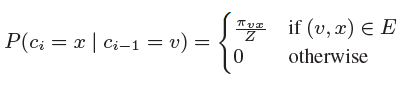
这样一来,就可以看出,超参数p控制的是重新访问原来结点的概率,也就是保守探索系数,而超参数q控制的是游走向更远方向的概率,也就是激进探索系数。如果q较大,那么游走策略则更偏向于广度优先策略,若q较小,则偏向于深度优先策略。
参考文章
- 网络表示学习(一)–DeepWalk、LINE、Node2Vec、HARP、GraphGAN
- node2vec随机游走实现思路
- 【Graph Embedding】node2vec:算法原理,实现和应用
- graph embedding之node2vec
- 关于Node2vec算法中Graph Embedding同质性和结构性的进一步探讨
- node2vec和deep walk到底在捕捉网络的什么特性
- 探索node2vec同质性和结构性之谜
- node2vec原理介绍及实践
用户Embedding方法有哪些
一般来说是利用用户的行为序列去表示。
最原始的还是基于矩阵分解,或者矩阵分解的各种变形。工业场景下并不是个好的选择,存在着计算复杂度高,训练时间长,难以优化等各种各样的问题。
最简单的方法就是将用户有过行为的item序列取平均,作为用户的向量表示。具体做法可以借鉴一下word2vec中的CBOW。
稍微复杂一些,可以参考youtube DNN(双塔模型),添加上用户的属性特征,比如性别,年龄等,再加几层网络,输出隐层作为用户向量表示。
取平均显得有些粗糙,因为用户的兴趣在不断变化,通常越新的行为item,表示用户最近的兴趣,起得作用更大,可以采用GRU,CNN,Transformer等模块来处理item序列,用输出隐层作为用户的向量表示。Transformer尤其好用,会自动地对不同的item选择权重。这些方法一般称为基于session或者基于sequence的推荐算法。具体做法可以搜索GRU4Rec,GRU4Rec+,Caser,SAS4Rec,BERT4Rec。
更多内容强烈推荐阅读知乎高赞解答~
参考文章
- 推荐系统中如何做 User Embedding?
Embedding冷启动怎么做
1. Embedding冷启动问题出现的根源
在着手解决它之前,必须要搞清楚这个问题出现的根源在哪,为什么Embedding冷启动问题那么不好解决。我们以最简单的Word2vec为例(其他所有Embedding方法,不管多复杂,都遵循同样的原则),训练它的最终目的是要得到与onehot输入对应的向量,用这个Embedding向量来表示一个用户,或者一个物品,或者一个特定的特征。
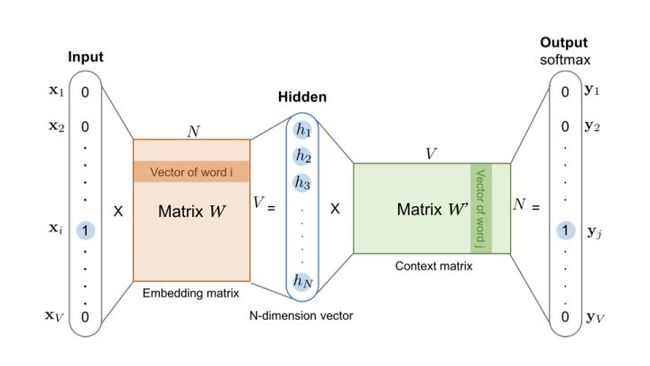
为了生成这样一个Embedding向量,我们就必须完成整个神经网络的训练,拿上面的Word2vec的结构图来说,你必须在Embedding matrix W训练完毕、收敛之后,才能够提取对应的Embedding。
这个时候冷启动的问题就来了,如果在模型训练完毕之后,又来了一个新的user或者item。怎么办?
要想得到新的Embedding,就必须把这个新的user/item加到网络中去,这就意味着你要更改输入向量的维度,这进一步意味着你要重新训练整个神经网络,但是,由于Embedding层的训练往往是整个网络中参数最大,速度最慢的,整个训练过程持续几个小时是非常常见的。这个期间,肯定又有新的item产生,难道整个过程就成一个死局了吗?这个所谓的“死局”就是棘手的Embedding的冷启动问题。
2. 入手解决问题
清楚了问题的根源,我们开始入手分析和解决问题。从整个深度学习推荐系统的框架角度解决这个问题,我觉得可以从四个角度考虑:
- 信息和模型
- 补充机制
- 工程框架
- 跳出固有思维
详情可参考王喆大佬写的如何解决深度推荐系统中的Embedding冷启动问题?这篇文章。
参考文章
- 如何解决深度推荐系统中的Embedding冷启动问题?
- 有哪些解决推荐系统中冷启动的思路和方法?
- 推荐系统如何解决对于使用频率较低的产品的用户特征冷启动的问题?
- 《推荐系统》系列之三:一文读懂冷启动推荐
- 用户增长:新用户冷启动
- 推荐系统 embedding 技术实践总结
- 「今日摘选」推荐中常见的Embedding方法