链表oj刷题——6道进阶题目
目录
1.链表分割
题目:
思路:
2.链表的回文结构
题目:
思路:
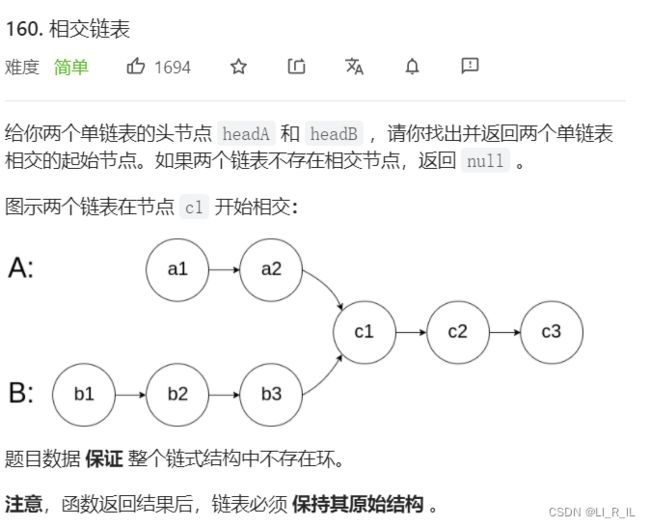
3. 输入两个链表,找出它们的第一个公共结点。
题目:
思路一:
思路二:
思路三:
4. 给定一个链表,判断链表中是否有环
题目:
思路:
5. 给定一个链表,返回链表开始入环的第一个结点。 如果链表无环,则返回 NULL
题目:
思路:
6. 给定一个链表,每个结点包含一个额外增加的随机指针,该指针可以指向链表中的任何结点或空结点。
题目:
思路:
1.链表分割
题目:
链表分割_牛客题霸_牛客网
现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
相对顺序不能变
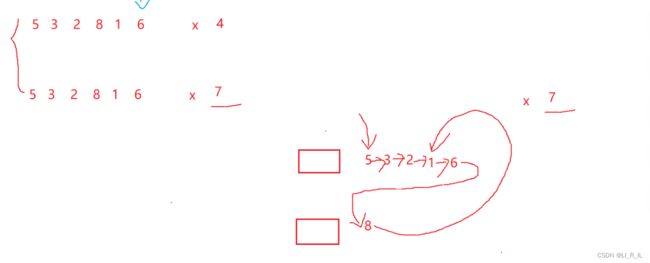
5 3 2 8 1 6 x=4
3 2 1 5 8 6
思路:
1.定义两个链表:
less
greater
lesshead和greaterhead是哨兵位的头结点
2.
比x小的尾插到less链表
比x大的尾插到great链表
3.
两个链接到一起,lesstail->next指向greaterhead->next
最后将两个lesshead和greaterhead释放掉

建议定义哨兵位,比较简单
分析极端场景
- 都比x小
- 都比x大
- 有大有小
注意:
第三种场景中可能会出现代还
代还,此时8还是指向1
解决方法:
greatertail->next = NULL;

此方法是带哨兵位的头结点
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
// write code here
struct ListNode* greaterhead, *greatertail,*lesshead,*lesstail;//一次性定义四个指针
greaterhead = greatertail = (struct ListNode*)malloc(sizeof(struct ListNode));
lesshead = lesstail = (struct ListNode*)malloc(sizeof(struct ListNode));
greatertail->next = NULL;
lesstail->next = NULL;
struct ListNode* cur = pHead;//pHead是现有链表的头指针
while(cur)
{
//链表中小于x的数将被尾插进less链表中
if(cur->val < x)
{
lesstail->next = cur;//尾插进去
lesstail = lesstail->next;//更新lesstail
}
//比x大的数被尾插进great链表中
else
{
greatertail->next = cur;
greatertail = greatertail->next;
}
cur = cur->next;//更新cur
}
//链接两个链表
lesstail->next = greaterhead->next;
//解决代还现象
greatertail->next = NULL;
struct ListNode* head = lesshead->next;//定义头指针
//将两个哨兵位释放掉
free(greaterhead);
free(lesshead);
return head;//返回重新排列后的链表的头指针
}
};注意:
这道题在vs中想要调试的时候可能与其他题目调试有所不一样,因为代码中含有C++的代码,与C语言的语法有所差异,调试的时候就有可能编译不过去。
方法:
把struct加上,把它当成C语言的函数进行调试,可以把C++的部分去掉
2.链表的回文结构
题目:

链表的回文结构_牛客题霸_牛客网
1 2 2 1
1 2 3 2 1
就是看链表是否对称
思路:
之前写过数组判断回文的方法:
给定两个指针(下标也可),一个在左一个在右,往中间走。
但是单链表并不支持如此写法。
那么此题的方法是什么呢?
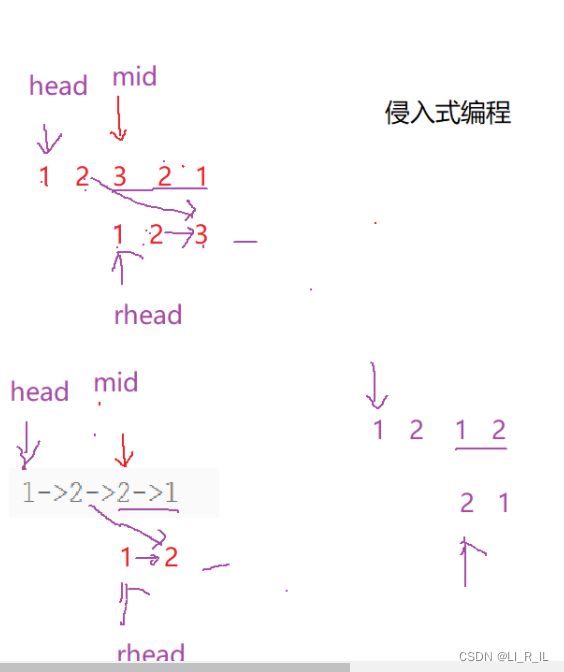
使用快慢指针找到中间结点,将后半段逆置,再去比较
若全部相等就是回文
解决奇数和偶数的问题:
无论是奇偶数,都从中间数开始
奇数链表相交
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
//逆置
struct ListNode* reverseList(struct ListNode* head){
//空链表逆置还是空
if(head==NULL)
return NULL;
struct ListNode* n1,*n2,*n3;
n1 = NULL;
n2 = head;
n3 = n2->next;
while(n2)
{
//倒指向
n2->next = n1;
//迭代
n1 = n2;
n2 = n3;
if(n3)//判断n3是否为空
n3 = n3->next;
}
return n1;
}
//快慢指针
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* slow,*fast;
slow = fast = head;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
//比较
class PalindromeList {
public:
bool chkPalindrome(ListNode* A) {
// write code here
struct ListNode* head = A;
struct ListNode* mid = middleNode(head);
struct ListNode* rhead = reverseList(mid);//reverse颠倒
while(head && rhead)
{
//对比逆置后的后半段链表与前半段链表相等与否
if(head->val != rhead->val)//不相等代表不是回文指针
{
return false;
}
//相等一个之后也要接着往下走对比之后的结点
else
{
head = head->next;
rhead = rhead->next;
}
}
return true;//都相等就返回true,代表是回文链表
}
};但此种代码的缺点:
属于侵入式编程
3. 输入两个链表,找出它们的第一个公共结点。
题目:
力扣
注意:
链表可以相交但不能交叉
因为一个结点只有一个next
怎么判断相交呢?
思路一:
两个链表对比,不能比值一定要比结点的地址
所有结点都对比一遍
时间复杂度
思路二:
求尾结点,地址相同
思路三:
求出A的长度lenA 5
求出B的长度lenB 3
让长的A先走,会有差距步 2
差距步走完之后,
走到两个链表对应的同一个结点,对比地址
地址不同,两个指针同时走,若相同则是相交点
O(N)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
//处理极端环境:如果有空链表,那么一定不会相交
if(headA == NULL || headB == NULL)
return NULL;
struct ListNode* curA = headA,*curB = headB;
int lenA = 1;
int lenB = 1;//因为是使用a++,所以从1开始就不会少一个
//计算两个链表的结点个数
while(curA->next)
{
curA = curA->next;
lenA++;
}
while(curB->next)
{
curB = curB->next;
lenB++;
}
//先处理两个链表都没有地址相同的结点的情况————不相交就返回NULL
if(curA != curB)
{
return NULL;
}
//接下来处理可能结点地址相等的情况
//先假设长链表为B,短链表为A
struct ListNode* shortList = headA,*longList = headB;
//如果假设情况与实际不符,就修正
if(lenA > lenB)
{
shortList = headB;
longList = headA;
}
//计算一个差值gap
int gap = abs(lenA - lenB);//abs是用来求绝对值的
//让长链表先走gap步
while(gap--)
{
longList = longList->next;
}
//gap步走完之后,若两个链表对应结点还不相等就接着往下对比
while(shortList != longList)//当相等时结束循环
{
shortList = shortList->next;
longList = longList->next;
}
//结束循环就可以返回相交结点
return shortList;//return longList;//两种写法都一样
}
};4. 给定一个链表,判断链表中是否有环
题目:

力扣
思路:
链表代还(环形链表)
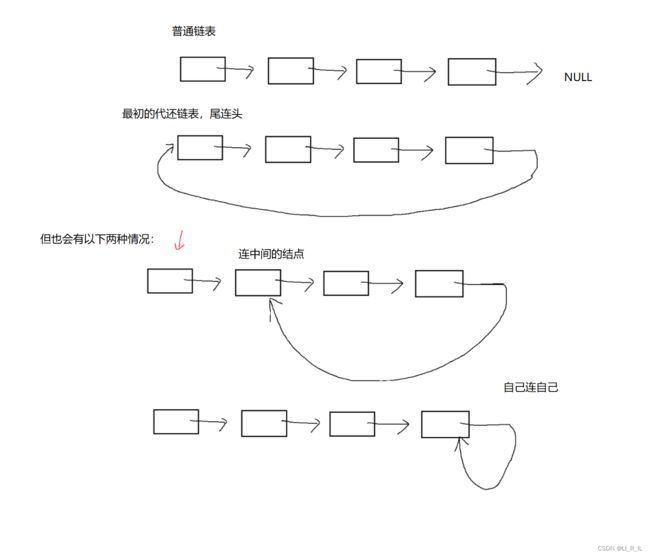
判断链表是否为环形链表:
采用快慢指针,就想龟兔赛跑。
如果是环形链表,快慢指针进入代还链表区域就会产生追及问题,它们会在环里相遇,即快指针追上慢指针,追上就相等。
若不是环形链表,则快指针会先一步走到链表的末尾

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
struct ListNode* fast = head,*slow = head;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
return true;
}
return false;
}
};
- 为什么快指针每次走两步,慢指针走一步可以?
结论:一定可以追上。
证明:
当slow刚走到入环结点的时候,fast可能已经在环里走了好多圈了,所以当slow进环的时候fast走了多远此时不好说,但我们可以假设slow进环的时候,与fast的距离相差为n(注意:只有进环的时候才会产生追击问题)
slow一步,fast两步
进环之后,slow每走一步快慢指针之间的距离每次缩小1
当n变为0之后两个指针就会相遇
- 快指针一次走3步,走4步,...n步行吗?
不一定。
假设slow进环的时候,与fast的距离相差为n
假设c是环的大小
slow 1 fast 3 距离每次缩小2
n若是偶数,可以相遇
但n若是奇数,n永远也不能为0,就不可能追上相遇
当n是-1时,他们之间的距离变成了c-1
此时开始新的一轮追击,就看c-1是奇数还是偶数
偶数可以追上,奇数不能追上(死循环)
4步……n步道理同上类似,大家可以自己进行推理。
5. 给定一个链表,返回链表开始入环的第一个结点。 如果链表无环,则返回 NULL
题目:
力扣
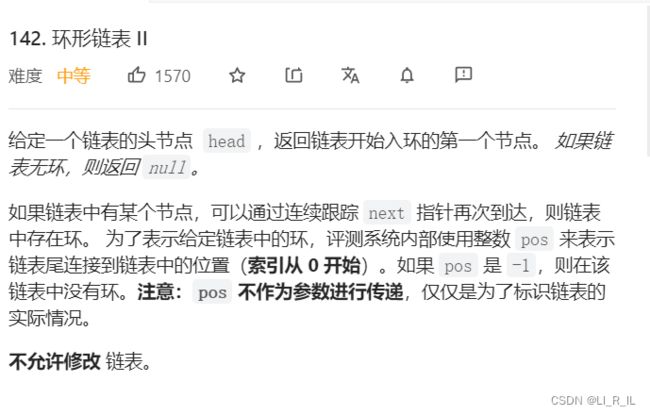
思路:
慢指针从入环开始,在一圈之内一定会追上相遇
因为追击过程中,他们距离每次缩小1,不会错过。他们的相对距离最多就1圈。
所以slow最多走一圈,fast就追上了
fast最多走两圈
slow走的路程 = L+X
fast走的路程 = L+C+X(只适用于前缀短环很大的情况)
假设slow在进环前,fast在环里面转了n圈(n>=1)(环很小的情况)
fast走的路程 = L+N*C+X
公式的推导:
2*(L+X) = L+N*C+X
L+X = N*C
L=N*C-X
L= (N-1)*C + (C-X)
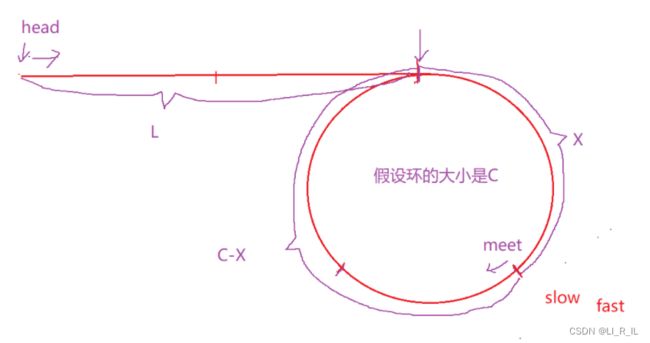
这个公式告诉我们一个结论:
当一个指针从meet开始走,另外一个指针从head开始走,他们会在入口点相遇
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode* fast = head,*slow = head;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
{
struct ListNode* meet = slow;
while(meet != head)
{
meet = meet->next;
head = head->next;
}
return meet;
}
}
return NULL;
}这道题的代码并不难,最大的难点还是在思路上,只要能想出并且推导出公式,代码就可以顺水推舟继续下去
还有另外一种思路:
转换成head链表和newhead链表的相交问题,求交点。
但这个代码我就不写了,大家需要的话可以自己下去练习一下。
6. 给定一个链表,每个结点包含一个额外增加的随机指针,该指针可以指向链表中的任何结点或空结点。
题目:
要求返回这个链表的深度拷贝。
力扣
复制带随机指针的链表

思路:
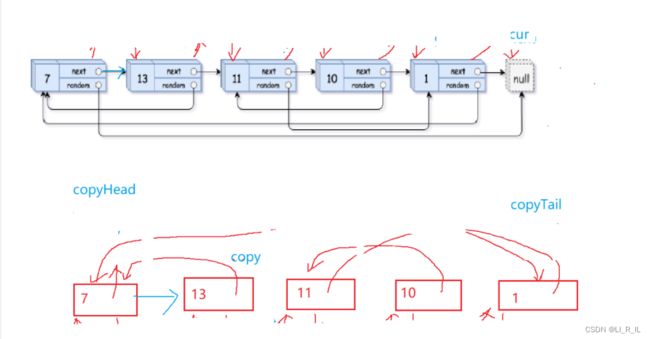
麻烦的是random
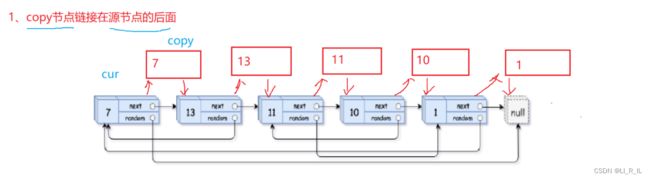
1.将copy结点链接在源节点的后面(为复制做准备)
2.复制的时候不要直接链接起来
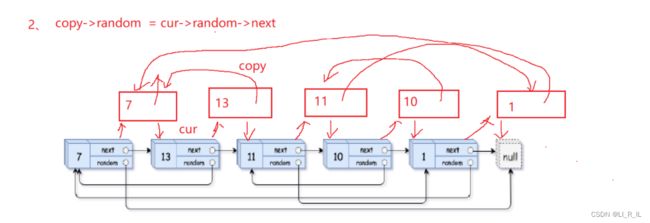
copy->random = cur->random->next
意思就是,你要copy的random就是源节点的random的copy也就是random->next
3.把拷贝结点解下来,链接到一起,恢复原链表
把copy拿下来尾插
/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head) {
//1.将copy结点链接在源节点的后面(为复制做准备)
//对应插入过程
struct Node* cur = head;
while(cur)
{
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
copy->val = cur->val;
copy->next = cur->next;
cur->next = copy;
cur = copy->next;
}
//复制的时候不要直接链接起来 控制random
//2.你要copy的random就是源节点的random的copy也就是random->next
cur = head;
while(cur)
{
struct Node* copy = cur->next;
if(cur->random == NULL)
copy->random = NULL;
else
copy->random = cur->random->next;
cur = copy->next;
}
//3.把拷贝结点解下来,链接到一起,恢复原链表
cur = head;
struct Node* copyHead = NULL,*copyTail = NULL;
while(cur)
{
struct Node* copy = cur->next;
struct Node* next = copy->next;
//把copy拿下来尾插
if(copyTail == NULL)
{
copyHead = copyTail = copy;
}
else
{
copyTail->next = copy;
copyTail = copyTail->next;//copytail不用置空,本来就是空
}
cur->next = next;
cur = next;
}
return copyHead;
}