卷积神经网络基础知识五(mobilenet)
一.简单介绍
1.1 绪论
论文下载地址:
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1704.04861v1
MobileNetV2: Inverted Residuals and Linear Bottlenecks
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1801.04381
Searching for MobileNetV3
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1905.02244
1.2 背景
存在问题
自从AlexNet在2012年赢得ImageNet大赛的冠军一来,卷积神经网络就在计算机视觉领域变得越来越流行,一个主要趋势就是为了提高准确率就要做更深和更复杂的网络模型,然而这样的模型在规模和速度方面显得捉襟见肘,在许多真实场景,比如机器人、自动驾驶、增强现实等识别任务及时地在一个计算力有限的平台上完成,这是我们的模型的局限性所在。
解决办法
(1)对复杂模型采取剪枝、量化、权重共享等方法,压缩模型得到小模型;
(2)直接设计小模型进行训练。
MobileNet系列
MobileNet系列就属于第二种情况。
MobileNet V1核心在于使用深度可分离卷积取代了常规的卷积。
MobileNet V2在MobileNet V1的基础山进行了如下改进:
- 去掉了bottleneck的非线性激活层
- 使用Inverted residual block
MobileNet V3
它是mobilnet的最新版,据说效果还是很好的。
作为一种轻量级网络,它的参数量还是一如既往的小。
它综合了以下四个特点:
1、MobileNetV1的深度可分离卷积(depthwise separable convolutions)。
2、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。
3、轻量级的注意力模型。
4、利用h-swish代替swish函数。
二.基础理论部分
2.1 发展历程
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入
式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降
低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,
但模型参数只有VGG的1/32).
2.2 MobileNet简介
为什么要设计mobilenet?
传统卷积神经网络,内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行,因此为移动端和嵌入式端深度学习应用设计的网络,使得在cpu上也能达到理想的速度要求。
mobilenet网络的特点:
- 轻量化
- 放弃pooling直接采用stride = 2进行卷积运算
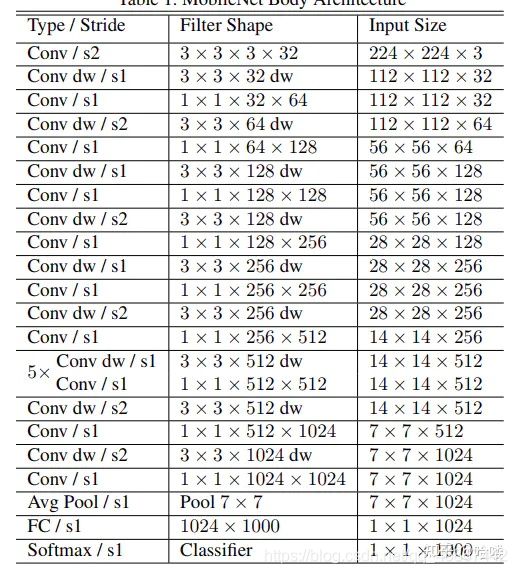
网络结构
创新点
1.depthwise separable convolutions(深度可分离卷积)
标准卷积:
图(a):特点是卷积核的通道数等于输入特征图的通道数 depthwise卷积:
图(b):特点是卷积核的通道数为1
1x1卷积:(pointwise卷积)
本质上就是1x1的卷积核,通道数等于输入特征图的通道数。


在设计网络是一个depthwise 和1x1卷积以及BN、relu的结构关系如图:

2:用两个超参数来控制网络计算速度与准确度之间的平衡
宽度调节参数和分辨率参数。
mobilenetv2 与mobilenetV1 不同点
1、引入了shortcut结构(残差网络)
2、在进行depthwise之前先进行1x1的卷积增加feature map的通道数,实现feature maps的扩张。(inverted residual block,一般的residual block是两头channel多 featuremap的通道少(沙漏形态)。而inverted residual block是两头通道少,中间feature的通道多(梭子形态))
3、pointwise结束之后弃用relu激活函数,改用linear激活函数,来防止relu对特征的破坏。

MobileNetV3特有的bneck结构
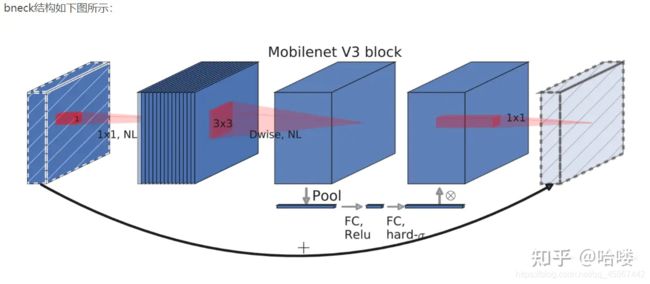
它综合了以下四个特点:
a、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)

即先利用1x1卷积进行升维度,再进行下面的操作,并具有残差边。
b、MobileNetV1的深度可分离卷积(depthwise separable convolutions)

在输入1x1卷积进行升维度后,进行3x3深度可分离卷积。
c、轻量级的注意力模型
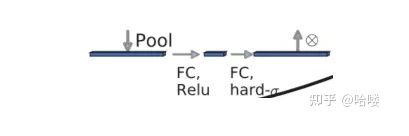
这个注意力机制的作用方式是调整每个通道的权重。
d、利用h-swish代替swish函数

在结构中使用了h-swish激活函数,代替swish函数,减少运算量,提高性能。
附加知识:
在进行深度卷积的时候,每个卷积核只关注单个通道的信息,而在逐点卷积中,每个卷积核可以联合多个通道的信息。以下我们通过一个具体的例子说明常规卷积与深度可分离卷积的区别。以下讨论均基于padding=same的情况。
常规卷积操作如下图:

假设输入层为一个大小为64×64像素、三通道彩色图片。经过一个包含4个卷积核的卷积层,卷积核尺寸为3×3×3。最终则会输出4个Feature Map,且尺寸与输入图像尺寸相同。
深度可分离卷积操作中深度卷积如下图:

图中深度卷积使用的是3个尺寸为3×3的卷积核,经过该操作之后,输出的特征图尺寸为64×64×3。
深度可分离卷积操作中逐点卷积如下图:

图中逐点卷积使用的是4个尺寸为1×1×3的卷积核,经过该操作之后,输出的特征图尺寸就为64×64×4。
为什么要用这种方式代替常规卷积呢?
假设输入图像尺寸为DF∗DF∗MDF∗DF∗M,标准卷积核尺寸为DK∗DK∗M∗NDK∗DK∗M∗N,其中MM为通道数,NN为卷积核个数。
采用标准卷积核进行卷积时,输出尺寸为DF∗DF∗NDF∗DF∗N,计算量为DK∗DK∗M∗N∗DF∗DFDK∗DK∗M∗N∗DF∗DF。
采用可分离卷积的计算量为:
DK∗DK∗M∗DF∗DF+M∗N∗DF∗DFDK∗DK∗M∗DF∗DF+M∗N∗DF∗DF
前半部分为尺寸为DF∗DF∗MDF∗DF∗M的原图经过MM个DK∗DKDK∗DK的卷积核的计算量,后半部分为尺寸为DF∗DF∗MDF∗DF∗M的特征图经过NN个1∗1∗M1∗1∗M的卷积核的计算量。
则,可分离卷积相对常规卷积的计算量对比为:
DK∗DK∗M∗DF∗DF+M∗N∗DF∗DF/DK∗DK∗M∗N∗DF∗DF=1/N+1/D^2K
卷积核的个数一般比较大,在此可以忽略,而最常使用的卷积核尺寸为3∗33∗3,这样,可分离卷积相对常规卷积,计算量就降为了1919。
V2版本相对于V1版本,主要是针对激活函数进行了思考,并且引入了残差连接。
使用如ReLUReLU之类的激活函数能够给神经网络带来如下好处:1. 压缩模型参数,这可有效地使得模型计算量变小;2. 给神经网络引入非线性变化,使得模型能够拟合任意复杂的函数。
总结:理论上普通卷积计算量是DW+PW的8到9倍。因此Deptwise Convolution可以大大减少运算量和参数数量。
那么mobilenet v3又引入了哪些黑科技呢?
1.引入SE结构
在bottlenet结构中加入了SE结构,并且放在了depthwise filter之后,如下图。因为SE结构会消耗一定的时间,所以作者在含有SE的结构中,将expansion layer的channel变为原来的1/4,这样作者发现,即提高了精度,同时还没有增加时间消耗。并且SE结构放在了depthwise之后。

2.修改尾部结构:
在mobilenetv2中,在avg pooling之前,存在一个1x1的卷积层,目的是提高特征图的维度,更有利于结构的预测,但是这其实带来了一定的计算量了,所以这里作者修改了,将其放在avg pooling的后面,首先利用avg pooling将特征图大小由7x7降到了1x1,降到1x1后,然后再利用1x1提高维度,这样就减少了7x7=49倍的计算量。并且为了进一步的降低计算量,作者直接去掉了前面纺锤型卷积的3x3以及1x1卷积,进一步减少了计算量,就变成了如下图第二行所示的结构,作者将其中的3x3以及1x1去掉后,精度并没有得到损失。这里降低了大约15ms的速度。
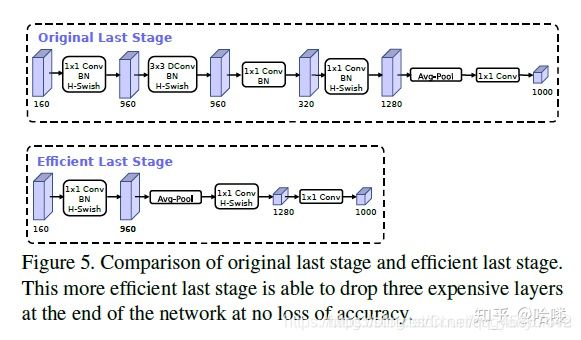
3.修改channel数量
修改头部卷积核channel数量,mobilenet v2中使用的是32 x 3 x 3,作者发现,其实32可以再降低一点,所以这里作者改成了16,在保证了精度的前提下,降低了3ms的速度。,这里给出了mobilenet v2以及mobilenet v3的结构对比:


4.非线性变换的改变
使用h-swish替换swish,swish是谷歌自家的研究成果,颇有点自卖自夸的意思,这次在其基础上,为速度进行了优化。swish与h-swish公式如下所示,由于sigmoid的计算耗时较长,特别是在移动端,这些耗时就会比较明显,所以作者使用ReLU6(x+3)/6来近似替代sigmoid,观察下图可以发现,其实相差不大的。利用ReLU有几点好处,1.可以在任何软硬件平台进行计算,2.量化的时候,它消除了潜在的精度损失,使用h-swish替换swith,在量化模式下回提高大约15%的效率,另外,h-swish在深层网络中更加明显。

三.网络实战(Pytorch)
3.1 数据集准备
本文采用博主提供的花分类数据集,下载地址如下:https://link.zhihu.com/?target=http%3A//download.tensorflow.org/example_images/flower_photos.tgz
3.2 项目下载
项目下载链接:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
3.3 开发环境搭建
Anaconda创建虚拟环境 编辑器pycharm 深度学习框架Pytorch python3.6
详细环境可参考我的知乎主页:https://www.zhihu.com/people/shi-wo-89-57/posts
3.4 模型训练
在项目Test6_mobilenet文件夹下创建新文件夹"flower_data";
将下载的数据集解压到flower_data文件夹下;
执行"split_data.py"脚本自动将数据集划分成训练集train和验证集val;
执行train.py文件 注意将数据路径修改为当前文件夹下;
使用迁移学习方式进行训练,预训练权重mobilenet_v2-pre.pth;
生成MobileNetV2.pth权重文件 。
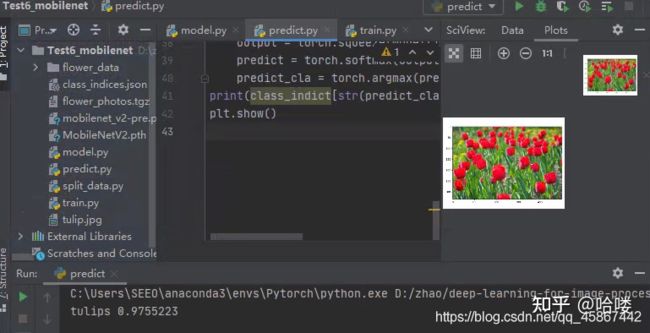
3.5 结果展示
- 利用生成MobileNetV2.pth权重文件 下载一张tulip.jpg照片用于测试
- 执行predict.py文件用于测试
- 结果展示图
参考
MobileNet - 范中豪 - 博客园 https://link.zhihu.com/?target=https%3A//www.cnblogs.com/zhhfan/p/11968044.html
mobileNet https://link.zhihu.com/?target=https%3A//www.jianshu.com/p/854cb5857070
经典卷积模型之MobileNetV3 https://link.zhihu.com/?target=https%3A//www.jianshu.com/p/562c57ad835c
mobilenet系列之又一新成员—mobilenet-v3_小菜鸟的AI之路-CSDN博客_mobilenetv3
https://link.zhihu.com/?target=https%3A//blog.csdn.net/Chunfengyanyulove/article/details/91358187
由于水平有限,文章中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!有任何疑问的小伙伴都可以私信,大家一起学习交流。