图像金字塔原理与轮廓识别检测
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。一幅图像的图像金字塔是一系列以金字塔形状(自下而上)逐步降低,且来源于同一张原始图的图像分辨率集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。通过图像金字塔,我们能够改变图像的大小。这跟我们之前提到的cv2.resize()函数作用是一致的,resize能够更加精细化地改变图像大小,将其放大或缩小为任意值,而图像金字塔只能够成比例进行放缩。

高斯金字塔
说到高斯金字塔我们都会想起前面说过的高斯滤波,它们都有一个明显的特征就是会对像素点进行加权,高斯滤波通过加权计算覆盖图像的噪音点,而高斯金字塔则是通过加权计算来放大或者缩小图像(无论放大还是缩小,图像都会被模糊,它们都是以牺牲图像部分信息为代价的)。

高斯金字塔缩小,相当于通过卷积来将卷积核内的所有像素点信息进行提取融合,然后去除一半的像素点,用之前一半的像素点来表示图像信息,即便进行过加权计算,图像还是损失了信息(也就是清晰度)。

高斯金字塔放大,将图像像素点扩充为原来的两倍,然后用相同的高斯卷积核进行像素点填充(相当于将原有像素点按比例加权然后分到邻近的像素点上),但是严格来讲高斯放大与缩小并不是逆操作,因为在进行缩小时我们已经将图像一半的像素点去除了,这一部分是无法通过计算完全复原的,只能按照一定的比例将其模糊放大,而剩下的像素点也并不是原图的像素点(因为已经被加权计算过了),也就是说经过高斯放大和缩小之后,整张图像的像素点值都已经被改变,即便我们将图像缩小后再放大,所得到的图像依旧不是原图,它的像素点值已经发生了偏移,得到的只是一个大概。
函数介绍
up = cv2.pyrUp(img):高斯放大函数,传入需要放大的图片即可。
down = cv2.pyrDown(up):高斯缩小函数,传入需要放大的图片即可。
代码实例
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread("XY.jpg")#读入新一的图像
def cv2_imshow(name,img):#构造展示图像的函数
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2_imshow("XY",img)#展示原图像
up = cv2.pyrUp(img)#进行高斯放大
cv2_imshow("up",up)#展示图像
down = cv2.pyrDown(up)#进行高斯缩小
cv2_imshow("down",down)#展示图像
运行结果
原图 放大后再缩小,可以明显发现比原图要模糊


高斯放大后,可以看到图片虽然放大了,但是有一点模糊

拉普拉斯金字塔
在高斯金字塔的运算过程中,图像经过卷积和下采样操作会丢失部分细节信息。为描述这些高频信息,人们定义了拉普拉斯金字塔(Laplacian Pyramid, LP)。也就是用高斯金子塔进行放大再缩小后的图像与原图像相减,就能够得到在这个过程中图像像素点值的偏移量,进而以图像的形式呈现出来(有点像在求图像的残差)。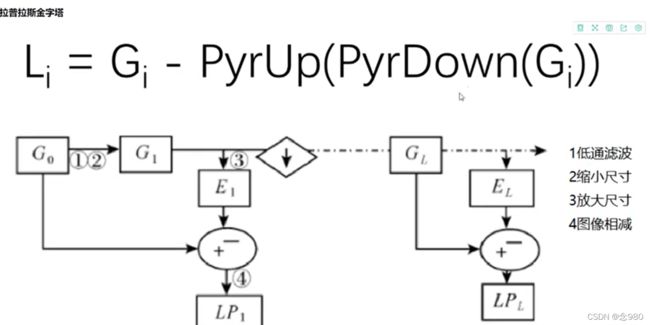
代码实例
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread("XY.jpg")#读入新一的图像
def cv2_imshow(name,img):#构造展示图像的函数
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2_imshow("XY",img)#展示原图像
down = cv2.pyrDown(img)#高斯缩小
down_up = cv2.pyrUp(down)#高斯放大
down_up = cv2.resize(down_up,(220,165))#调整图像大小
laplacian = img - down_up#拉普拉斯金字塔,相当于在求图像残差
cv2_imshow("laplacian",laplacian)#展示图像运行效果
右边的图像计算拉普拉斯金字塔对于图像残差的计算反馈,可以看到基本上整个图像(尤其是轮廓位置)像素点的值都存在不同程度的偏移。
图像轮廓检测
图像轮廓检测其实就是在图像进行过二值化的基础上,将图像的轮廓以线条的形式描出。而即使进行过二值化处理,图像也存在着多个轮廓,因此Opencv给出了cv2.findContours(img,mode,method)函数来计算图像轮廓。
轮廓特征
轮廓特征包括轮廓周长与面积,以及轮廓面积与轮廓矩形的比值。
相关函数介绍:
contours,hierarchy = cv2.findContours(thresh,mode,method):这里的thresh是进行过二值化处理后需要进一步检测轮廓的图像,mode参数是检索模式,method则是轮廓逼近方法的选择,一般我们选择第一个,第二个是当处理时间过长时采用的,一般我们处理的图像图像都比较简单。
具体参数详述于下方图片
关于返回值:
由于版本不同,因此返回值数量不同,在新版本的Opencv中只有两个返回值,轮廓以及轮廓的层级:
contours:是带有轮廓信息的列表(可以根据层级取出不同的轮廓信息)。
hierarchy:如果输入选择cv2.RETR_TREE,则以树形结构组织输出,hierarchy的四列分别对应下一个轮廓编号、上一个轮廓编号、父轮廓编号、子轮廓编号,该值为负数表示没有对应项。
旧版本的Opencv则返回image,contours,hierarchy:imge是一张带有轮廓信息的二值图像。

res = cv2.drawContours(draw_img,contours,-1,(0,0,255),1):画出图像轮廓,draw_img参数是导入要画轮廓信息的图像(可以是彩色图,但是要注意,图像画上轮廓之后就会被保存,无法恢复,因此我们传入的图像应该先备份),contours是该图像的轮廓信息,-1表示画出所有轮廓,0则表示画出第0个轮廓(以此类推),(0,0,255)表示要画的轮廓颜色,1是表示要画的轮廓粗细。
cnt = contours[0]:对处理图像的轮廓进行选定,以进行更有针对性的操作。
x,y,w,h = cv2.boundingRect(cnt):计算出该轮廓所在的矩形,返回值x,y,w,h分别表示矩形左上角的横纵坐标以及图像的宽度和高度。
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2):根据上一个函数得到的返回值画出矩形,img是要画矩形的图像,(x,y)为矩形左上角坐标,(x+w,y+h)为右下角坐标,(0,255,0)是矩形的颜色,2则是矩形线条的宽度。
area = cv2.contourArea(cnt):能够计算指定轮廓的面积。
extent = float(area)/rect_area:计算指定轮廓与矩形的面积比。
cv2.arcLength(cnt,True):计算周长,True表示该轮廓曲线闭合,False则表示轮廓曲线断开。
代码示例
画出轮廓,计算周长和面积
import cv2
import numpy as np
import matplotlib.pyplot as plt
def cv2_imshow(name,img):#构造展示图像的函数
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
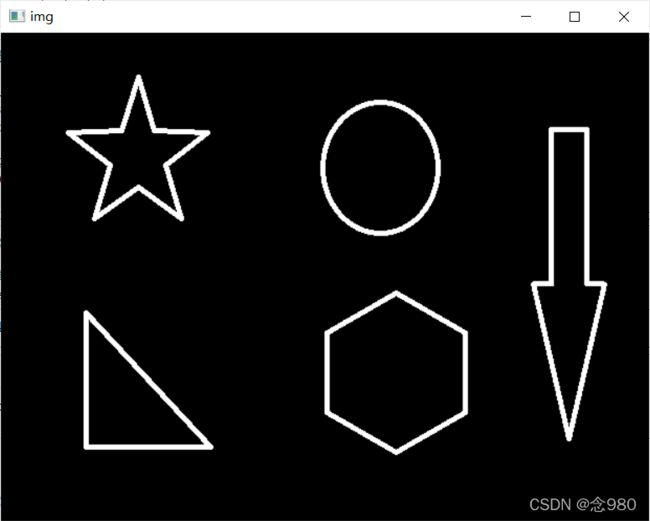
img = cv2.imread("contours.png")#导入原图
cv2_imshow("img",img)#展示原图
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转化为灰度图
ret,thresh = cv2.threshold(img_gray,120,255,cv2.THRESH_BINARY)#进行二值化处理
cv2_imshow("thresh",thresh)#展示二值化处理后的图像
contours,hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)#这个版本只返回两个值,轮廓以及轮廓的层级
draw_img = img.copy()#复制一下原图
res = cv2.drawContours(draw_img,contours,-1,(0,0,255))#-1表示画出全部轮廓,可以单独画出某个轮廓
cv2_imshow("res",res)#展示图像
#轮廓特征(面积与周长)
cnt = contours[3]#指定轮廓
area = cv2.contourArea(cnt)#计算面积
perimeter = cv2.arcLength(cnt,True)#计算周长,True表示该图像曲线闭合运行结果
原图
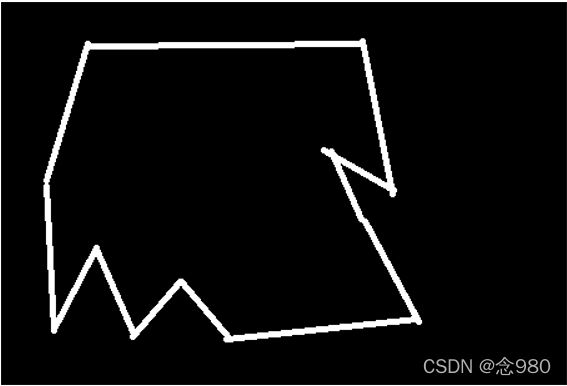
轮廓(内外两层轮廓都画出来了)
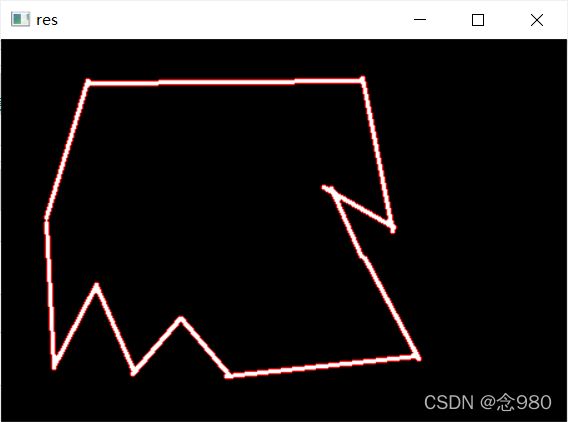
画出轮廓矩形并计算面积比
import cv2
import numpy as np
import matplotlib.pyplot as plt
def cv2_imshow(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img = cv2.imread("contours.png")#读入图像
cv2_imshow("img",img)#展示原图像
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转化为灰度图
ret,thresh = cv2.threshold(img_gray,127,255,cv2.THRESH_BINARY)#转化为二值图像
contours,hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)#计算轮廓
cnt = contours[0]#选定轮廓,可以自由选择,改为1,2,3等等都可以
x,y,w,h = cv2.boundingRect(cnt)#计算矩形的左上点坐标,图片的高和宽(不一定是正数)
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)#给出左上点的和右下点矩形坐标计算出矩形的大小和位置
cv2_imshow("img",img)#展示画好矩形的图像
area = cv2.contourArea(cnt)#计算轮廓面积
rect_area = w*h
extent = float(area)/rect_area#计算轮廓与矩形的面积比
print("轮廓与矩形的面积比为:",extent)运行结果
原图
画好矩形后的图像(可以自由选择轮廓,这里选的是0)

面积比
![]()
图像模板检测匹配
![]()
Opencv提供了cv2.matchTemplate()函数进行简单的图像检测识别,它的原理是读入一张要进行匹配的单通道图像,再读入一张从模板上截下来的单通道图片模板进行匹配,通过将模板在图像上一格一格的进行移动,最后比对出像素最接近的模板区域。该函数使用十分便捷,但通常需要结合其他识别方式使用。
缺点:该函数是通过计算区域像素区域进行匹配的,因此只能识别大小形状都相同的模块,如果将图片截取下来之后,放大原图,函数就难以识别了。而且极易受到图像背景,亮度等因素的影响,精度和识别率都不够高。
注意:在使用该函数时,需要保证传入的图像和模板格式一致,不能出现图像时jpg,模板是png等格式不一的情况,否则会对识别造成很大影响。
函数介绍
res = cv2.matchTemplate(img,template,1):img是要进行匹配的图像,template是模板,1表示识别方式,当然也可以写出具体的参数名,识别方式种类如下。

对应数字

关于返回值
res是一个矩阵,它记录了模板在图像上每移动一次像素点所计算得到的平方差或者相关系数,我们可以通过min_val,max_val,min_loc,max_loc = cv2.minMaxLoc(res)函数来得到它的最大值和最小值以及相对应的坐标,然后在那个位置画出矩形,我们就成功的把检测结果画在了图像上。
import cv2
import numpy as np
import matplotlib.pyplot as plt
def cv2_imshow(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img = cv2.imread("lena2.png",0)
template = cv2.imread("face.png",0)
res = cv2.matchTemplate(img,template,1)#img为要检测的图片,template为模板,1表示检测方式
min_val,max_val,min_loc,max_loc = cv2.minMaxLoc(res)#得到最大最小值及其坐标
h,w = template.shape[:2]#得到模板的高和宽用以确定矩形大小
methods = ['cv2.TM_CCOEFF',"cv2.TM_CCOEFF_NORMED","cv2.TM_CCORR","cv2.TM_CCORR_NORMED","cv2.TM_SQDIFF","cv2.TM_SQDIFF_NORMED"]
for i in methods:
draw_img = img.copy()#复制图像
method = eval(i)
res = cv2.matchTemplate(img,template,method)#模板匹配操作
min_val,max_val,min_loc,max_loc = cv2.minMaxLoc(res)#计算出最大值坐标和最小值坐标
if i in ["cv2.TM_SQDIFF","cv2.TM_SQDIFF_NORMED"]:#判断是否进行归一化操作,寻找匹配的坐标
top_left = min_loc#如果进行了归一化操作,则应选择最小值
else:
top_left = max_loc#如果未进行归一化操作,则选择最大值
bottom_right = (top_left[0]+w,top_left[1]+h)#求出右下角矩形坐标
cv2.rectangle(draw_img,top_left,bottom_right,255,2)#计算矩形的左上点坐标,图片的高和宽(不一定是正数)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.xticks([]),plt.yticks([])#隐藏坐标轴
plt.subplot(122),plt.imshow(draw_img,cmap = 'gray')
plt.xticks([]),plt.yticks([])#隐藏坐标轴
plt.suptitle(i)#显示标题
plt.show()
原图

模板

采用各种检测方式后得到的结果比对

通过结果我们可以看到,在理想的条件(背景不复杂,模板取自原图)下 ,matchTemplate函数还是比较准确的,以及在实际匹配时我们最好选择带归一化的参数,这样识别结果会更加准确。当然不同的情况我们也需要尝试不同的参数,总有一种时比较准确的(可以多试几个)。
加强版,利用循环来进行天天酷跑中的金币识别
import cv2
import numpy as np
import matplotlib.pyplot as plt
def cv2_imshow(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img_rgb = cv2.imread("ku_2.png")
img_gray = cv2.imread("ku_2.png",0)#读入灰度图
cv2_imshow("gray",img_gray)
template = cv2.imread("god_2.png",0)
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)
h,w = template.shape[:2]
threshold = 0.5
#取匹配程度大于50%的坐标
loc = np.where(res>threshold)
for pt in zip(*loc[::-1]):
bottom_right = (pt[0]+w,pt[1]+h)
cv2.rectangle(img_rgb,pt,bottom_right,(0,225,0),1)
cv2_imshow("img_rgb",img_rgb)原图

要识别的金币模板
![]()
结果
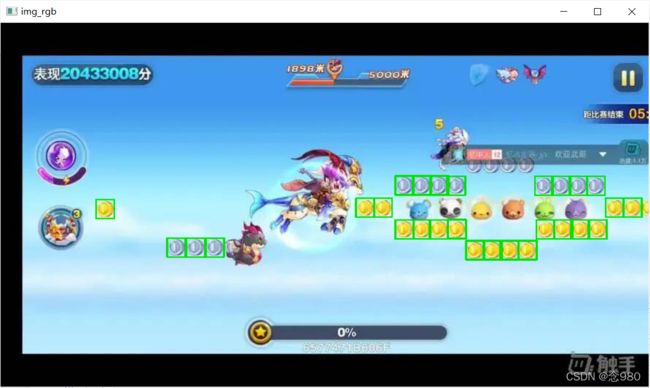
不足:由于matchTemplate函数是将图像和模板都转化为灰度图识别的,因此无法识别颜色,金币和银币都会被识别,并且如果背景比较复杂,将会出现概率很高的误识。并且对于被字幕遮挡住的银币它同样无法识别,识别效果并不是很好。