深度学习之Tensorflow2学习笔记 - CV方向遥感领域
硕士三年,本为CV研究方向专业调参侠,上取发表SCI之荣誉,下得一等奖助学金,本光明前途逐渐显现,却因我大天腐♂之国AI行业变态内卷加之自身无心读博,研三临时转向GIS开发妄图求取工作得以苟活,现重拾CV之心再起,写得如下笔记,回报当年之初心,开拓未来之事业,如有错误,敬请指正。
1. 极为常用的概念(大白话解释)
线性回归:距离地铁站的远近一般会影响房子的租金,距离远近和租金之间的关系就是一个线性相关的关系,这两个数据的之间的换算公式就是线性回归方程,最简单的线性方程就是一元一次方程 y = ax + b
逻辑回归:用来判断是否的公式,比如根据薪资水平、工作环境、离家远近、晋升通道等因素来判断是不是一个好工作就是一个逻辑回归的问题。
损失函数:判断一个公式拟合程度的公式,最后一般会算出来一个数值叫损失值loss,越大表示拟合得越不好。线性回归方程一般用方差作为损失函数。
优化函数:计算机用来减少损失值loss的函数,一般是梯度下降算法,如adam、SGD、RMSprop等
学习速率lr与衰减值decay:学习率是梯度下降算法的变化速率,就是算法的权重值之一;一般学习速率会根据训练的深入而慢慢变慢,衰减值就是学习率变慢的下降率。
反向传播算法:用来传递loss数据的算法。深度学习有非常多的层数,反向传播可以将最终的loss损失值一层一层往回反馈,直到最开始的层,这就让所有的参数因子都可以获取loss程度,然后用优化函数改变其权重数值,从而减少loss。
激活函数:一个模型有多个层次(进行多次回归计算)的时候会有多余或者非常重要的自变量,但人事先是不知道的,激活函数就是在计算的过程中对这些自变量的权重进行非线性变化,以快速强化或者弱化某个因素,以优化模型的拟合(有点遗传算法里面突变的思想,但是两者的数学实现方法是不一样的),常用的有relu、tanh、sigmoid(经典但最近不用了)等。激活函数在每一步矩阵操作之后,非线性变换后再向前传递数值。
交叉熵函数:逻辑回归情况下常用的损失函数。逻辑回归是一种评级的制度,如满分10分最后得分为9分就判断待评价物是比较好的东西,但是方差作为损失函数时候最后的损失值会很大,并不适合逻辑回归做是/否判断,所以出现了交叉熵函数,它会把最后损失值局限到[0,1]之间,这样就方便作为评价指标。
softmax多分类函数:交叉熵函数的加强版,交叉熵只能进行是或否两种类型的判断,如果是3种及以上结果的情况就不行了,所以出现了softmax多分类判断,如根据双方球员的数据判断一场足球赛是客方胜、主方胜、还是平局,softmax会对3种可能都计算出一个概率:客方胜率0.65、主方胜率0.3,平局概率0.05,所有情况概率值加起来肯定等于1
归一化:遥感方向主要都是输入图片为主,输入的时候都要记得除以255来归一化
顺序标签与one-hot编码:假设有一个模型可以对鞋子、包包、衣服的图片进行识别,我们输入一张图片如果输出的结果是[2,0,1],则表明模型认为该图片为衣服概率最大,鞋子概率其次、包包概率最小,这种输出[2,0,1]的形式就表明标签是按照顺序表达;但是如果输出的结果是[0.1, 0.3 , 0.6]则表示模型认为是鞋子的概率是0.1 包包概率是0.3 衣服概率是0.5, 这种表达方式就表明事先对标签进行过one-hot编码,以让输出结果更符合人们常规的概率表达方式。( 顺序标签的使用sparse_categorical_crossentropy作为损失函数,one-hot标签使用categorical_crossentropy)
超参数:需要自己调参而非算法自动优化的参数,如学习率,神经元个数、层数等(做AI工作大部分就 是和超参数打交道,当一个调参侠)
过拟合:过拟合的典型特征为训练数据集精度高但测试数据集精度低
过拟合的优化方法:
① dropout:训练时候随机跳过某些参数参与训练,来防止过拟合。(有点随机森林的意思,因为每次都是随机放弃了某些参数,所以就可以当作把多个相似的模型拿来训练,最后融合起来成了一个适中的模型);
② 正则化:给损失函数增加一个调节的参数,起到微调摆正的作用,俗称自动矫正。
③ 图像增强:增加训练数据,这是防止过拟合的最好办法。
全连接层:上一层的每一个数据都和本层的权重值进行了矩阵计算,即全部节点都有连起来相互计算。
2. Tensorflow2学习顺序
本顺序偏向CV方向的实际项目生产
【基础操作】
data数据输入
卷积神经网络
keras二次封装API
eager动态图
tensorboard可视化面板
迁移学习
多输出模型
模型的保存与恢复
【实操】
目标识别
自动图运算
语义分割
实例分割
全景分割
【项目部署】
本地设备部署深度学习功能
服务器部署深度学习功能
通过API访问服务器的深度学习功能
3. 实战之前的各种基础
3.1 tensorflow的最基础API操作
/** 矩阵乘数值 */
x = [[1.,1.],[1.,1.]]
y = tf.multiply(x,2)
print(y) // tf.Tensor([[2. 2.][2. 2.]], shape=(2, 2), dtype=float64)
/** 矩阵相乘 */
a = [[1.]] // 1后面打个点说明是浮点数float32,不打点后面算出来b的dtype就是int32
b = tensorflow.matmul(a,a)
print(b) // b = tf.Tensor([[1.]], shape=(1, 1), dtype=float32)
/** tensor转矩阵 */
c = b.numpy()
print(c) // [[1.]]
/** 数值类型转换 */
d = tensorflow.cast(b, tf.int32)
print(d) // d = tf.Tensor([[1]], shape=(1, 1), dtype=int32)
/** tf.data.dataset的基本操作 */
dataset = tf.data.Dataset.from_tensor_slices([1, 2, 3]) // 数组转dataset
for element in dataset:
print(element) // tf.Tensor(1, shape=(), dtype=int32) , tf.Tensor(2, shape=(), dtype=int32), tf.Tensor(3, shape=(), dtype=int32)
dataset1 = dataset.repeat(2) // 重复2次(新增一批一样的)
dataset1 = dataset.batch(4) // 平均分成3个批次
dataset1 = dataset.shuffle(buffer_size = 2) // 随机打乱,里面是生成随机数的缓冲区大小
3.2 传统机器学习的弊端
下图为用K-means在CIFAR-10数据集上训练的结果,如图所示第一行一个翻斗立起来的运渣车很多被识别成了马,其他行的错误也和第一行类似,其背后的原因是该算法主要是用于聚类问题,如果用在图片识别上就会关注于图片本身的构图和颜色配置是否相近,而不是聚焦于图片中物体的识别。
后来又想到可以用主成分算法把图中的主体识别区域抠出来然后用K-means来识别,但是效果不尽人意,因为只有在物体和背景在颜色和边缘等条件区别特别明显的时候,物体才会被比较好的分离出来,分离效果都不好给K-means识别就更无从谈起。
机器学习在图像识别领域效果不佳的核心的原因其实都是算法单一、阈值单一、参数过多难以训练、几乎完全靠人工设置,设计之初是给数据分析使用的,并没有考虑图像自身的特性,只能拿来应用于车牌、指纹这种变化不大的情况。

图:k-means算法在CIFAR-10的表现
3.3 神经网络完整训练流程的基本代码
如下代码包含了训练一个神经网络所包含的必有操作,从开始到结束依次为:导入tensorflow库、导入训练与测试数据集、数据归一化、编写模型结构、配置模型结构、将输入加入模型开始云联、验证模型精度、模型拿来识别图像、保存模型为文件、加载保存的模型文件 。(如果用自己的训练集请参考5.1和5.2)
import numpy as np
import tensorflow as tf
from tensorflow import keras
# 准备数据
fashion_mnist = keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()
train_images = train_images / 255.0 # 归一化
test_images = test_images / 255.0
# 编写模型结构
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)) # 传统神经网络模型只接受1*n的模型输入,所以要先压平
keras.layers.Dense(128,activation='relu') # 激活函数
keras.layers.Dense(10,activation='softmax') # 多分类,用softmax
])
# 配置模型参数
model.compile(
optimizer='adam', # 优化函数
loss='sparase_categories_crossentropy', # 没有one-hot编码就用离散交叉熵作为损失函数
metrics=['accuracy'] # 精度的文字标注,可以随便写
)
# 开始训练模型
model.fit(train_images,train_labels,epochs=10)
# 开始验证模型
test_loss, test_accuracy = model.evaluate(
test_images,
test_labels,
verbose = 2 #测试时的显示方式,0只显示精度,1显示精度、进度、loss等,2不显示进度其他都显示
)
# 开始测试
results = model.predict(test_images)
print(results[0]) # [0.001, 0.0002 ..... ], dtype=tf.float32
class_names = ['t-shirt','trouser','pullover','dress','coat','sandal','shirt','sneaker','bag','ankel boot']
print(class_names[np.argmax(result[0])]) // 'dress'
# 保存和读取训练模型文件和权重文件
model.save('20220715105132_train.h5') # 存
model = keras.models.load_model('20220715105132_train.h5') # 读
# 只保存和读取模型结构文件
model_json = model.to_json()
with open ('config.json','w') as json:
json.write(model_json) # 存
with open ('config.json','r') as model_config:
model = keras.models.model_from_json(model_config) # 读
# 保存和读取模型的权重文件
weights = model.get_weights()
model.save_weights('weights.h5') # 存
model.load_weights('weights.h5') # 读3.4 数据增强
模型的效果好不好,最直接有效的方法就是从数据下手,强化数据的质量和数量是上策。一些常用的数据增强代码如下:
train_dataGen = ImageDataGenerator(
rescale=1./255, # 归一化
rotation_range = 40, # 旋转
width_shift_range = 0.2, # 宽度变换
height_shift_range = 0.2, # 高度变换
shear_range = 0.2, # 裁剪
zoom_range = 0.2, # 缩放变换
horizontal_flip = true, # 垂直翻转
fill_mode = 'nearest' # 当进行变换时超出边界的点进行临近处理
)3.5 TFReocrds格式数据的制作与训练时读取
tensorflow推荐的数据集格式,可以加快训练速度(具体怎么加速的不用关心)
tfrecords的制作:
import os
import glob # 查找文件的库
from datetime import datetime
import cv2
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#%matplot inline
# 封装制作数据集函数
def _bytes_feature(val):
if isinstance(val,type(tf.constant(0))):
val = val.numpy()
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[val]))
def _float_feature(val):
return tf.train.Feature(float_list=tf.train.FloatList(value=[val]))
def _int64_feature(val):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[val]))
def image_example(image_string,image_label):
image_shape = tf.image.decode_jpeg(image_string).shape
# 这个feature是自定义的
feature = {
'height':_int64_feature(image_shape[0]),
'width':_int64_feature(image_shape[1]),
'depth':_int64_feature(image_shape[2]),
'label':_int64_feature(image_label),
'image_raw':_bytes_feature(image_string) # 图片RGB数据转成tf内部维护的一种特征字符串
}
# 就是这样制作成tfcords需要的格式,不需要过于深究发生了什么,因为数据格式是他自己发明的
return tf.train.Example(feature=tf.train.Features(feature=feature))
def make_example(img_path,label_name):
labels = {
'dog': 0,
'cat': 1
}
image_string = open(img_path,'rb').read()
image_label = labels[label_name]
image_example(image_string,image_label)
# 开始制作
img_path = './imgs/'
images = glob.glob(img_path + '*.jpg') #找到所有jpg图片并返回列表
record_file = 'images.tfrecord'
#for img_path in images:
# image = mpimg.imread(img_name)
# f,(ax1) = plt.subplots(1,1,figsize=(8,8))
# f.subplots_adjust(hspace=0.2,wspace=0.05)
# ax1.imshow(image) # 显示图片
# ax1.set_title(img_name,fontsize=20) # 给图片打个标题
with tf.io.TFRecordWriter(record_file) as writer:
for fname in images:
with open(fname,'rb') as f:
image_string = f.read()
label = image_labels[os.path.basename(fname).replace('.jpg','')] # 图片名字作为标签
tf_example = image_example(image_string,label)
writer.write(tf.example.SerializeToString())
# 运行完成以后就会生成一个.tfrecord格式的文件
tfrecord加载与使用
raw_train_dataset = tf.data.TFRecordDataset('images.tfrecord')
feature = {
'height': tf.io.FixedLenFeature([],tf.int64),
'width': tf.io.FixedLenFeature([],tf.int64),
'depth': tf.io.FixedLenFeature([],tf.int64),
'label': tf.io.FixedLenFeature([],tf.int64),
'image_raw': tf.io.FixedLenFeature([],tf.string), #这个feature要和制作tfrecord的feature对应
def parse_tf_example(example_proto):
parsed_example = tf.io.parse_single_example(example_proto,feature)
x_train = tf.image.decode_jpeg(parsed_example['image_raw'],channels=3)
x_train = tf.image.resize(x_train,(416,416))
x_train /= 255.
label = parsed_example['lable']
y_train = label
return x_train,y_train
train_data = raw_train_dataset.map(parse_tf.example) # 拿到了训练数据
train.ds = train_data.shuffle(buffer_size = 10000).batch(10).repeat(10)
model = ...
model.complie ....
model.fit(train_ds, epochs = 10) # 使用4. CNN卷积神经网络
意义:CV领域都是以卷积神经网络为基础,专门用于提取图像中物体特征
4.1 基本结构
基本结构:输入层、卷积层、池化层、全连接层
1. 输入层
传统的神经网络都要把w * h * 3大小的图像矩阵转为 1* q的数组传入到模型中,破坏了图像中的空间特征信息,CNN的输入就是直接把w*h*3的原始形状作为输入格式直接传入,这充分保留了空间特征信息。
遥感影像会不止3个波段,但现阶段就以3个波段为例,具体的多波段影像会在后面补充 。
2. 卷积层
如下图所示,左侧紫色加灰色的就是输入的原始图像,是个7*7*3的RGB彩色图像;中间粉红色是两组权重矩阵,也叫卷积核,每组卷积核都有三个3*3*3大小的卷积单元和一个偏量;卷积核不断在原始图片上每隔2个像素的步长扫描一下,这个操作就叫卷积,扫描完一轮就得到被提炼出的数据,即绿色矩阵,绿色矩阵又作为下一层的数据被输入,循环往复再经过几轮优化,就可以识别出物体了。
深度学习的过程就是在不断优化中间红色矩阵的权重,从而让它能从图片中扫描出更好的绿色矩阵数据,以达到更好的识别能力。
究其本质,抽象出来其实还是 y = ax + b ,不用想得太过深奥,只不过其中的y,a,x,b都变成了n维矩阵然后加了很多优化算法以修补。对于只想搞应用的话,不用过分深究其中的数学原理,只需要知道这个过程即可,怎么从理论层面来解释证明模型是那些全世界就只有几百个的巨佬们做的事情。
现在要开始弄一点数学了,不过很简单,步长step_width、卷积核尺寸filter_width 、卷积核个数kernal_count:
输出矩阵的形状为 : output_width = ( input_width - filter_width ) / step_width + 1 ,the same as output_widht , kernal_count
依据上面的公式,套用在下面gif的卷积过程,输出矩阵的形状是 ( 7 - 3 ) / 2 + 1 , ( 7 - 3 ) / 2 + 1 ,2 → 3,3,2 ,和图里面一致
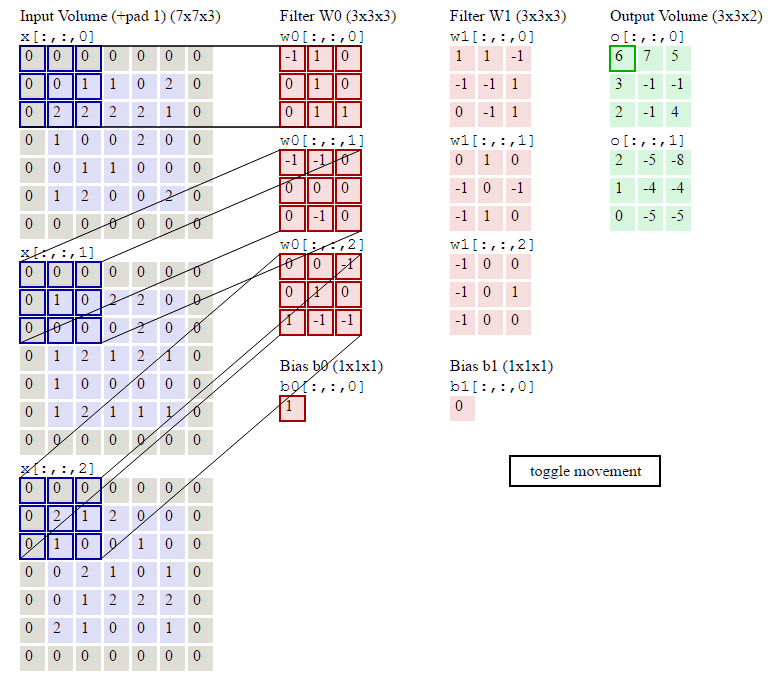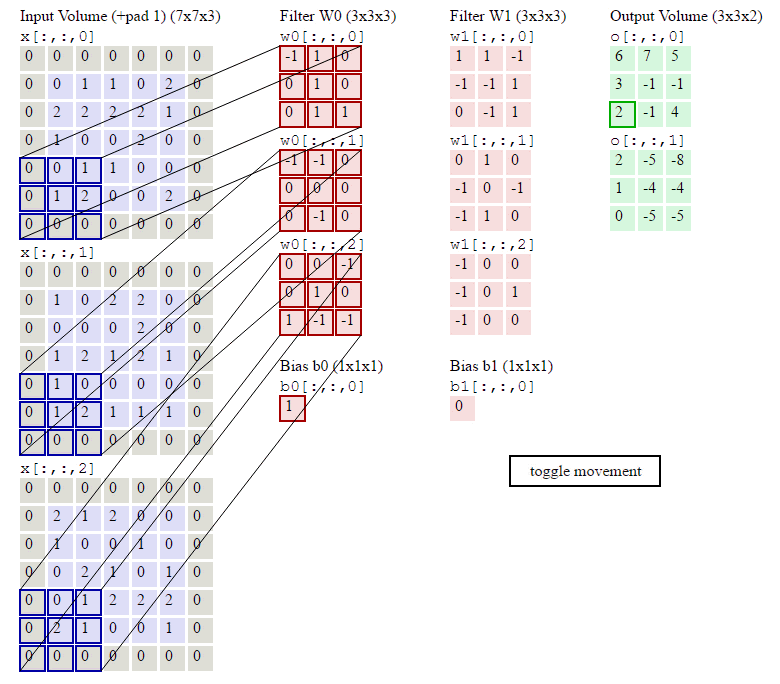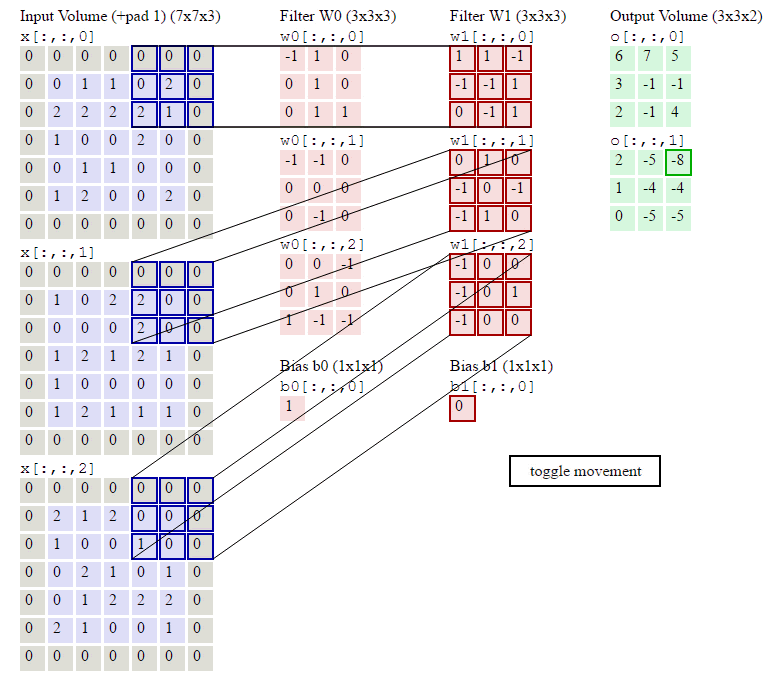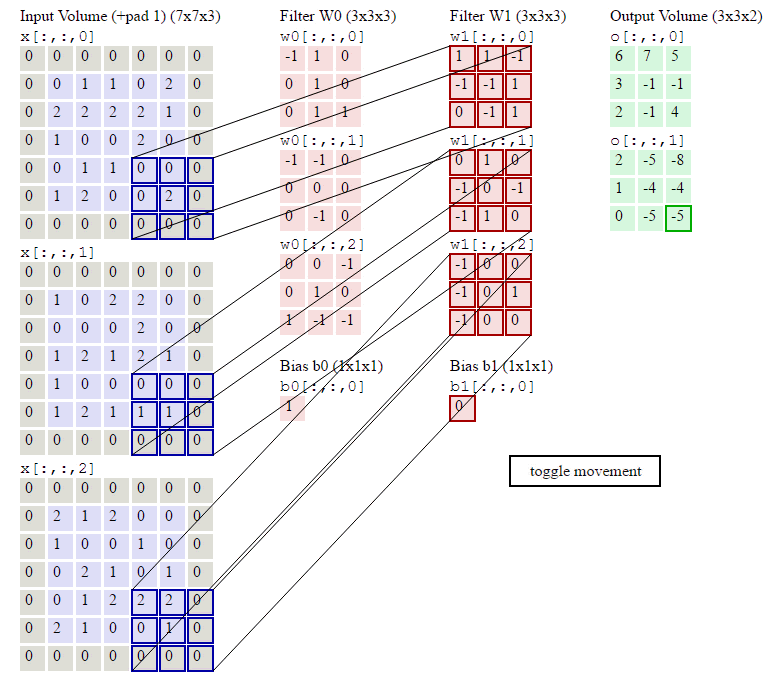
图:卷积操作
3. 池化层
缩小特征图的shape
最大池化:像卷积一样扫描,把特征权重矩阵中选择最大的留下来,因为值越大证明特征越明显所以离下来最大的,如下图所示:
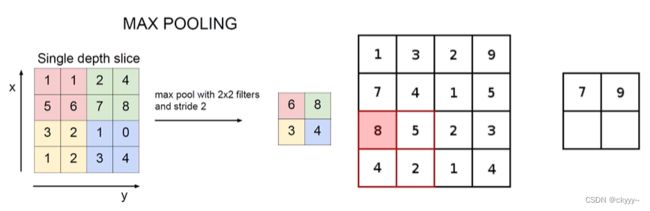
图:最大池化
(已经不怎么用平均池化了,最小池化就更没意义了)
4. 全连接层
① 目的: 把所有提取目标各部分的特征整理起来,最后通过激活函数分类。一般用在模型的最后。
② shape:全连接一个1*1*n的矩阵,它是由x*y*n的一个卷积操作实现的,x和y是多少才能让最后是1*1请看上面卷积操作的计算公式。
③ 较早的深度学习模型都是两个4096的全连接然后再输出给softmax分类,为什么是两个主要是一个全连接层无法解决非线性问题,第一个全连接输出给第二个全连接的时候会接上一个激活函数进行非线性优化,然后第二个全连接再激活一次传给softmax来分类。
4.2 经典CNN网络简介
1. AlexNet
近代CNN的经典开篇之作,原始的卷积 + 激活 + 池化 + 全连接的8层神经网络 ,问题是卷积核过大,shape为11*11, 步长为4 ,对细节特征控制不足
2. VGG
相比于AlexNet加深了层数达到16层,但是参数量相比于AlexNet也翻倍增长,并且发现超过20层以后的效果在下降
3. Resnet
为了应对VGG发现的很深层数效果下降问题,提出了深度残差,核心思想就是检测深层的权重参数,如果该层loss是上升的趋势,则把该层参数抹去用一个残差代替(真实值和预测值之间的差),因为在深层次模型中,假如一共有50层,可能28,29,30层是无用层,则用残差代替思想就可以抛弃掉这三层,从而解决模型越深带来的过拟合问题。
Resnet已经是一个可以直接套用的规范的特征提取网络,无需要再做任何模型结构上的更改(对于普通我等调参侠来说)。在分类、识别、目标检测、提取、检索等任务中都可以直接使用。(具体是拿来做什么任务不在于用什么模型,而是在于用什么损失函数和什么分类器,中间模型就是来提取特征的,CNN还可以用在NLP领域拿来提取文本特征,不光是CV,切记)
5. 图片识别实战
含义:识别出图片中有啥的算法,如下图,话不多说,直接上代码

5.1 图片识别实战入门 : 自己写个模型进行猫狗识别
本实战的数据集只有猫狗两个类型,模型是我们自己写的一个卷积神经网络而不是经典网络,以达到熟悉整个深度学习训练流程和自己动手搭建一个模型的能力。代码为 tensorflow2 + python3.6
# 0 导入模块
import os
import time
import warnings
warnings.filterwarnings("ignore") # 忽略非致命警告提醒
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 1 准备好路径
base_dir = './data'
train_dir = os.path.join(base_dir,'train')
val_dir = os.path.join(base_dir,'val')
train_dog_dir = os.path.join(train_dir,'dog')
train_cat_dir = os.path.join(train_dir,'cat')
val_dog_dir = os.path.join(val_dir,'dog')
val_cat_dir = os.path.join(val_dir,'cat')
# 2 开始构建模型
from tensorflow.keras.applications.inception_v3 import InceptionV3
model = InceptionV3(
input_shape=(75,75,3), # 这里要看API,模型有最小形状要求
include_top = False, # 要不要全连接层,迁移学习几乎都不要全连接层
weights='imagenet' # 迁移训练的权重来源
)
# 控制训练多少层卷积层
trainable_layers = len(model.layers) - 3 # 只训练最后三层
for layer in model.layers[:trainable_layers]:
layer.trainable = False
for layer in model.layers[trainable_layers:]:
layer.trainable = True
# 上面33行抛弃了全连接层,所以要自己设计一个全连接层
my_FC_layer = tf.keras.layers.Flatten()(model.output)
my_FC_layer = tf.keras.layers.Dense(1024,activation='relu')(my_FC_layer)
my_FC_layer = tf.keras.layers.Dropout(0.2)(my_FC_layer)
my_FC_layer = tf.keras.layers.Dense(10,activation='softmax')(my_FC_layer)
model = tf.keras.models.Model(
inputs = model.input,
outputs = my_FC_layer)
model.compile(
optimizer=Adam(lr=0.001),
loss='categorical_crossentropy',
metrics=['acc'])
# 3 数据处理
train_dataGen = ImageDataGenerator(
rescale=1./255,
class_mode='categorical',
rotation_range = 40, # 旋转
width_shift_range = 0.2, # 宽度变换
height_shift_range = 0.2, # 高度变换
shear_range = 0.2, # 裁剪
zoom_range = 0.2, # 缩放变换
horizontal_flip = True # 垂直翻转
)
val_dataGen = ImageDataGenerator(rescale=1./255) #验证没必须数据增强,只用归一化
train_generator = train_dataGen.flow_from_directory(
train_dir,
target_size = (75,75), #对应model的input_shape
batch_size = 12,
class_mode='categorical'
)
val_generator = val_dataGen.flow_from_directory(
val_dir,
target_size = (75,75), #对应model的input_shape
batch_size = 12,
class_mode='categorical'
)
# 4 开始训练
class myCallBack(tf.keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs={}):
self.model.save(time.time() + '.h5')
model.fit_generator(
train_generator,
epoch = 20, # 训练多少次
steps_per_epoch = 100, # 一次几步,如果有2000张图,20个epoch这里就是100
validation_data = val_generator,
validation_steps = 50, # 如果有1000张验证图,20个epoch这里就是50
verbose = 2, # 测试时的显示方式,0只显示精度,1显示精度、进度、loss等,2不显示进度其他都显示
callbacks=[myCallBack()])5.2 使用inceptionV3进行迁移学习
迁移学习就是在别人训练好的一个文件基础上加入自己的数据集再训练,相当于抄作业再根据自己的数据改一改,优势很多不赘述,关键的点有如下:
① 数据量小的情况下,一个类就一两百张图,一般就只重新训练全连接层
② 数据量很大,几百万张,就可以重新全盘训练了
③ 其他情况自己酌情控制重新训练的层数,没有一个定理说多少图重新训练多少层,都是经验之谈
# 0 导入模块
import os
import time
import warnings
warnings.filterwarnings("ignore") # 忽略非致命警告提醒
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 1 准备好路径
base_dir = './data'
train_dir = os.path.join(base_dir,'train')
val_dir = os.path.join(base_dir,'val')
train_dog_dir = os.path.join(train_dir,'dog')
train_cat_dir = os.path.join(train_dir,'cat')
val_dog_dir = os.path.join(val_dir,'dog')
val_cat_dir = os.path.join(val_dir,'cat')
# 2 开始构建模型
from tensorflow.keras.applications.inception_v3 import InceptionV3 # 提前下好放在 C:\Users\{你的用户名}\.keras\models中
model = InceptionV3(
input_shape=(75,75,3), # 这里要看API,模型有最小形状要求
include_top = False, # 要不要全连接层,迁移学习几乎都不要全连接层
weights='imagenet' # 迁移训练的权重来源
)
# 控制训练多少层卷积层
trainable_layers = len(model.layers) - 3 # 只训练最后三层
for layer in model.layers[:trainable_layers]:
layer.trainable = False
for layer in model.layers[trainable_layers:]:
layer.trainable = True
# 上面33行抛弃了全连接层,所以要自己设计一个全连接层
my_FC_layer = tf.keras.layers.Flatten()(model.output)
my_FC_layer = tf.keras.layers.Dense(1024,activation='relu')(my_FC_layer)
my_FC_layer = tf.keras.layers.Dropout(0.2)(my_FC_layer)
my_FC_layer = tf.keras.layers.Dense(2,activation='softmax')(my_FC_layer)
model = tf.keras.models.Model(
inputs = model.input,
outputs = my_FC_layer)
model.compile(
optimizer=Adam(lr=0.001),
loss='categorical_crossentropy',
metrics=['acc'])
# 3 数据处理
train_dataGen = ImageDataGenerator(
rescale=1./255,
class_mode='categorical',
rotation_range = 40, # 旋转
width_shift_range = 0.2, # 宽度变换
height_shift_range = 0.2, # 高度变换
shear_range = 0.2, # 裁剪
zoom_range = 0.2, # 缩放变换
horizontal_flip = True # 垂直翻转
)
# 4 开始训练
class myCallBack(tf.keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs={}):
self.model.save(time.time() + '.h5') # 每训练一步就保存一下训练结果
model.fit_generator(
train_generator,
epoch = 20,
steps_per_epoch = 100,
validation_data = val_generator,
validation_steps = 50,
verbose = 2
callbacks=[myCallBack()])5.3 使用Resnet + tfrecord 进行训练全流程每个步骤详解
1. 网上、实地拍摄、开源数据集等等方法收集数据,为保证效果每类至少500张
2. 数据清洗:裁剪图片让待识别物体处在图片的中间位置、去掉覆盖在物体上的文字水印等干扰
3. 数据分类:分成train训练集、valid验证集、test测试集,比例一般是6:2:2
4. // 未完待续
5.4 遥感影像识别
// 未完待续
6. 目标检测
含义:识别出照片中有啥,并能框选出来的算法,如下图

7. 语义分割
含义:识别出图片中有啥,不框选而是精确抠图

8. 实例分割
含义:识别出有啥、精确抠图、且把每个个体都能挑出来

9. 全景分割
含义:实例分割的基础上,还能分割背景

未完待续 2022-8-4