基于YOLOv3的道路标识检测并使用OpenVino部署
基于 YOLOv3的道路标识检测并使用OpenVino部署
Neil
系统环境:
Windows 10 家庭中文版 20H2
Visual Studio Community 2019
CUDA V11.1.74
cuDNN V8.0.4
OpenCV V3.4.0
硬件环境:
CPU: Intel(R) Core(TM) i7-8750H @2.20GHz
RAM: 16GB
GPU: NVDIA GeForce GTX1060 GDDR5 @6.0GB (192-bit)
LAPTOP: ROG Strix GL504GM
文章目录
- 基于 ```YOLOv3```的道路标识检测并使用```OpenVino```部署
-
- 壹、配置```Yolov3```环境
-
- 一、下载和安装软件
-
- 1. 安装CUDA
- 2. 安装对应版本的cuDNN
- 3. 安装 OpenCV
- 4. darknet
- 贰、准备工作
-
- 一、下载开源权重
- 二、创建Yolo可识别的文件夹
- 三、准备数据集
- 叁、训练模型
-
- 一、修改配置文件
-
- 1. 在cfg目录下,```.data```文件中存放相关路径。
- 2. 修改cfg文件
- 3. 修改names文件
- 二、开始训练
- 肆、使用模型
- 伍、模型的转换和部署
-
- 一、从Darknet模型转换成TensorFLow模型
- 二、从TensorFlow的Pb模型转换为IR模型
壹、配置Yolov3环境
P.S.
Yolo环境的配置过程中,需要特别注意各个软件之间的版本配合,两个软件版本不契合就会导致系统无法工作。
一、下载和安装软件
P.S.
软件的安装均可以根据自身计算机的情况更换路径。
1. 安装CUDA
NVDIA CUDA下载地址:
https://developer.nvidia.com/cuda-downloads
这里我们应该选择Windows环境并且选择本地安装。下载完成后,打开软件完成安装。

[NVDIA网页界面]
完成安装后,我们需要配置系统环境变量。具体方式如图所示:
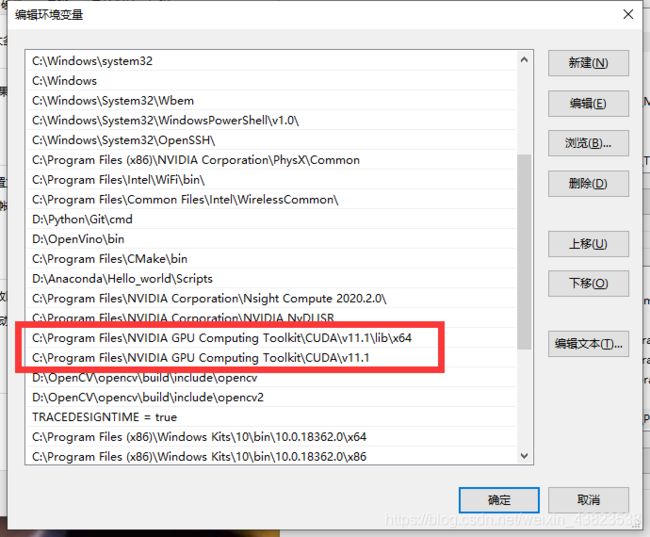
[配置系统环境变量]
配置好系统环境变量之后,可以使用命令行工具检测安装结果。
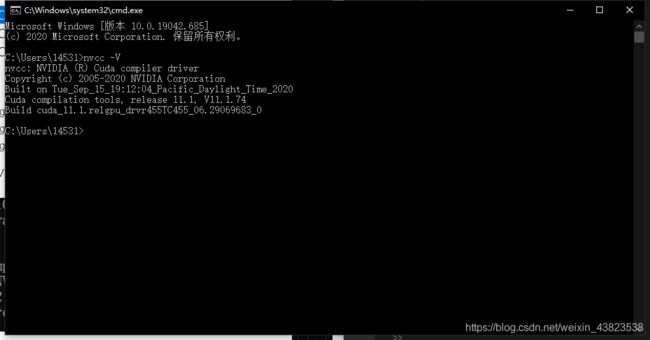
[命令行显示软件版本]
2. 安装对应版本的cuDNN
NVDIA cuDNN下载地址:
https://developer.nvidia.com/rdp/cudnn-download
这里我们应该选择与CUDA对应的软件版本。下载完成后,打开软件完成安装。

[NVDIA cuDNN下载界面]
下载完成后,将得到的压缩包解压得到一个名为“CUDA”的文件夹。

[解压后的文件夹]
将bin\cudnn64_7.dll 复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin
将include\cudnn.h 复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
将lib\x64\cudnn.lib 复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64
3. 安装 OpenCV
OpenCV下载地址:
https://opencv.org/releases/
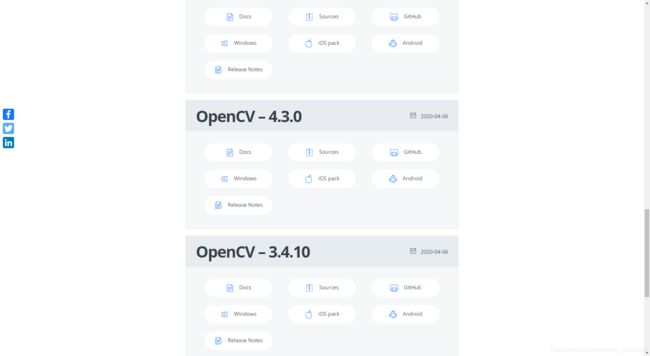
[选择正确版本的OpenCV]

[下载界面]
4. darknet
darknet下载地址:
https://github.com/pjreddie/darknet
从Github下载完成后,首先要做的是移动文件。
将opencv_ffmpeg340_64.dll和opencv_world340.dll移动到darknet\darknet-master\build\darknet\x64

[移动后的文件夹]
生成darknet.exe
- 在darknet-master\build\darknet下,打开darknet.vcxproj ,将CUDA 后的版本号和你安装的一致。利用搜索可以查找,然后修改即可,一共两处。
- 用
Visual Studio打开darknet.sln,修改属性

[darknet.sln]
打开项目之后,选择项目->属性 配置如图所示属性:
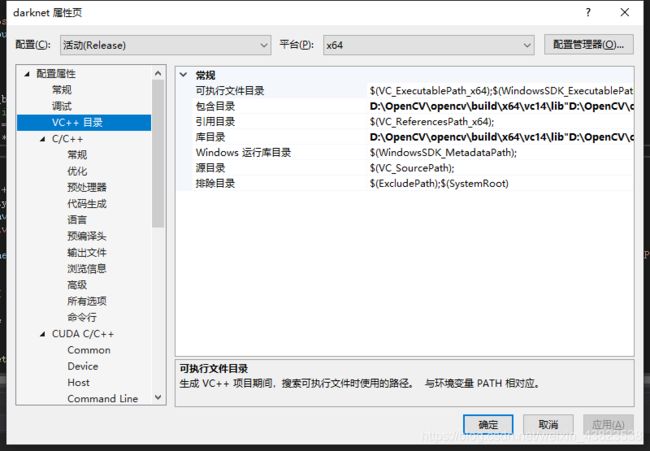

P.S.
注意调试器应该是 Release x64
然后将 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\visual_studio_integration\MSBuildExtensions 所有文件 复制到 C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\BuildCustomizations 中
完成上述步骤后,选择重新生成。出现如下图情况,即成功安装Yolo。
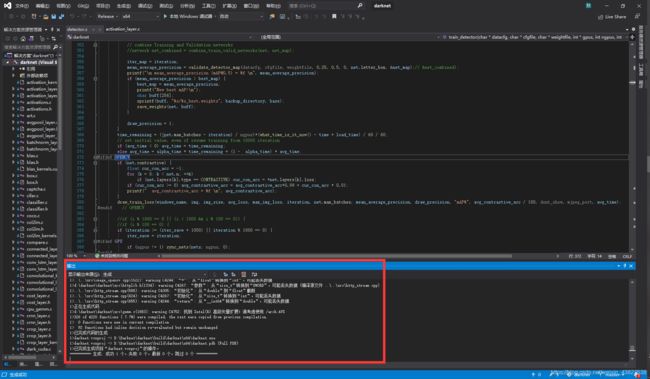
贰、准备工作
一、下载开源权重
在开始实验之前,我们应该先在网络上下载Yolo v3开源权重yolov3.weights,同时也需要下载yolo 53层训练权重darknet53.conv.74。
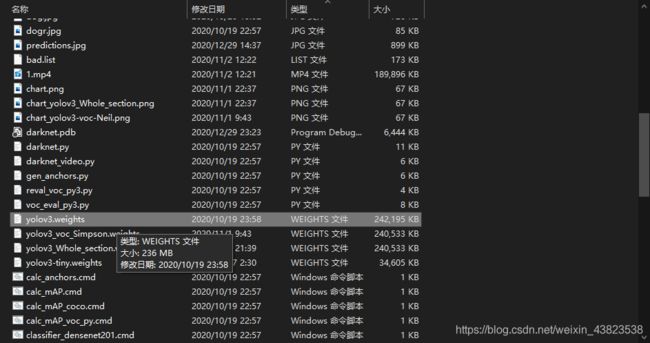

下载好需要的权重后,我们可以使用代码对权重进行测试:
darknet.exe detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
测试结果如下:

[命令]
[运行结果]
二、创建Yolo可识别的文件夹
按照图示的路径创建文件夹即可
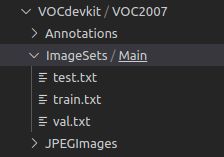
- Anontations用于存放标签xml文件
- JPEGImage用于存放图像
- ImageSets内的Main文件夹用于存放生成的图片名字

[图片名称]
三、准备数据集
由于时间久远,已经不知道是哪个开源数据集。。。
本文中,我们使用LabelImg软件进行标记。

[某开源数据集]
从路径为"/home/vtstar/yolov4/darknet/scripts"下的voc_label.py复制到项目根目录下(darknet),并对其内容进行修改。
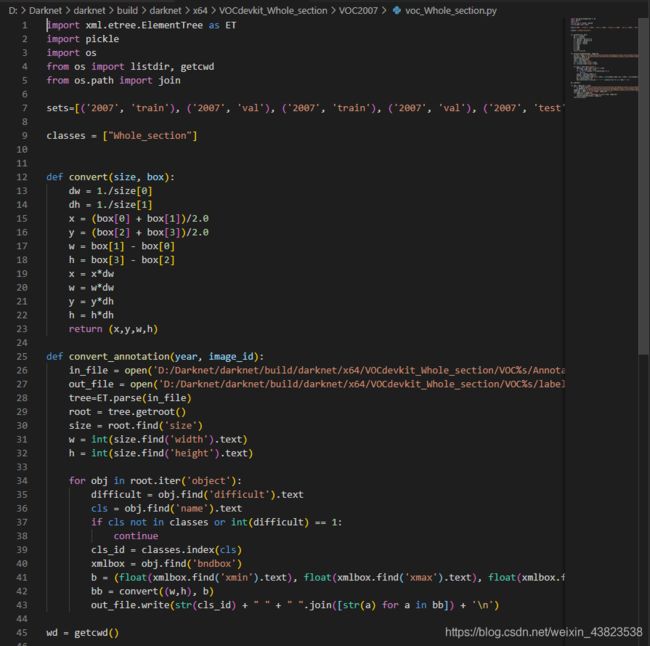
执行voc_label.py,在根目录下将会生成训练需要的文件,即各个训练集中包含图像的路径。

叁、训练模型
一、修改配置文件
1. 在cfg目录下,.data文件中存放相关路径。
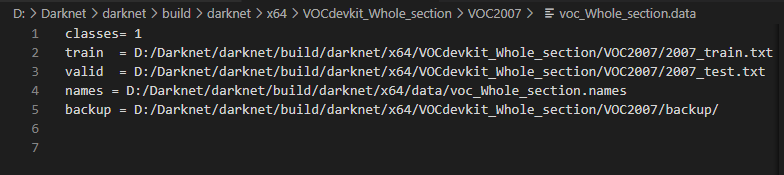
其中路径分别是:
- 类别的数量
- 训练过程中训练数据和验证数据的txt文件(voc_label.py生成的)
- 类别标签名称
- 存放权重的路径
2. 修改cfg文件
训练代数:
- github中给出了max_batches的基本设置方法,2000 × classes。当然,设置的大一些也是可以的,只不过后期基本上在某一值附近震荡。
- 值得注意的是,steps的设置是max_batches × 80% 和 max_batches × 90%/。
网络结构:
- 根据待测目标类别的数量更改YOLO层(3个)和YOLO层前一层的卷积层(3个)
- 包含YOLO前一层卷积层的卷积核个数:(classes + 5)*3
- YOLO层的类别数classes。
- 锚框(可选,kmeans聚类)
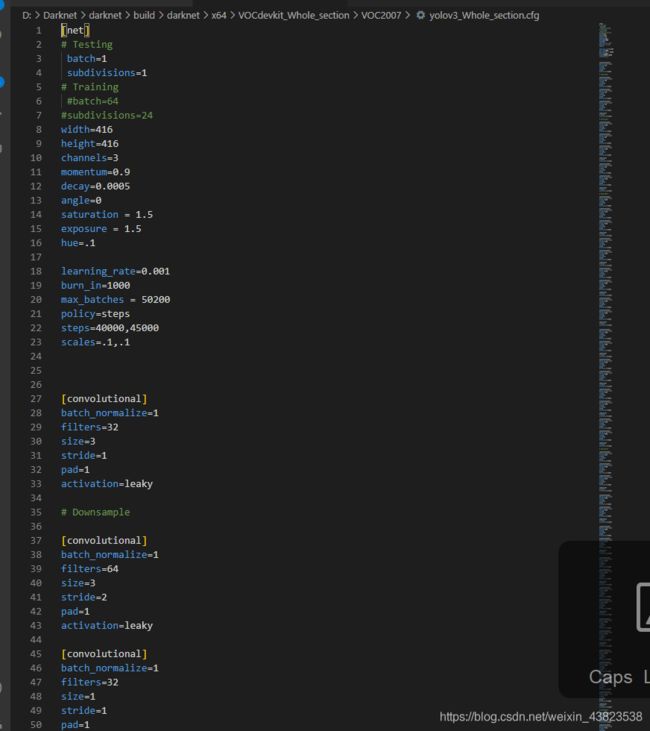
[cfg文件的修改结果]
P.S.
需要注意的是,训练和测试都需要修改CFG文件中[net]中的内容。
3. 修改names文件
修改或者新建coco.names或者voc.names(推荐修改voc.names)
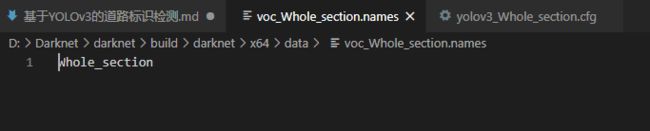
二、开始训练
训练指令:
darknet.exe detector train cfg/voc_Whole_section.data cfg/yolov3_Whole_section.cfg darknet53.conv.74
训练过程中,系统会新建窗口显示当前损失函数。
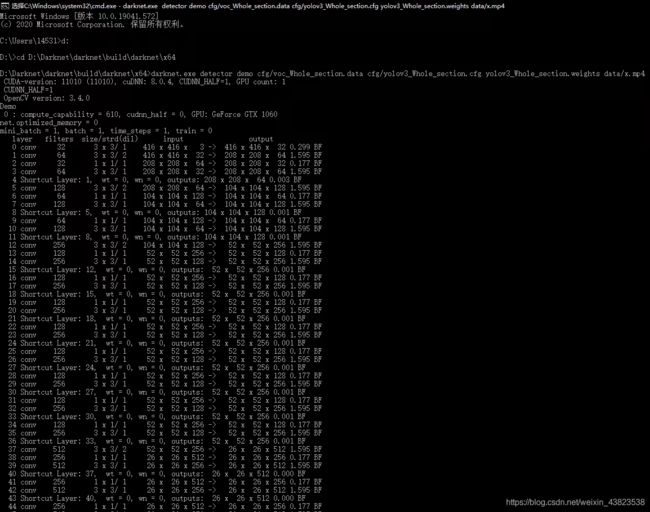
训练过程中,系统会将得到的模型存放在backup文件夹中并不断更新。
肆、使用模型
训练一段时间后,我们会得到相应的训练权重。
P.S.
想要得到好的训练结果,就需要控制训练过程。
尽量减小过拟合。
使用一下指令预测结果:
darknet.exe detector test cfg/voc_Whole_section.data cfg/yolov3_Whole_section.cfg yolov3_Whole_section_last.weights 2.png


伍、模型的转换和部署
一、从Darknet模型转换成TensorFLow模型
我们可以参考开源项目:
https://github.com/mytic123/tensorflow-yolo-v3
里面包含了模型下载和转换的命令。
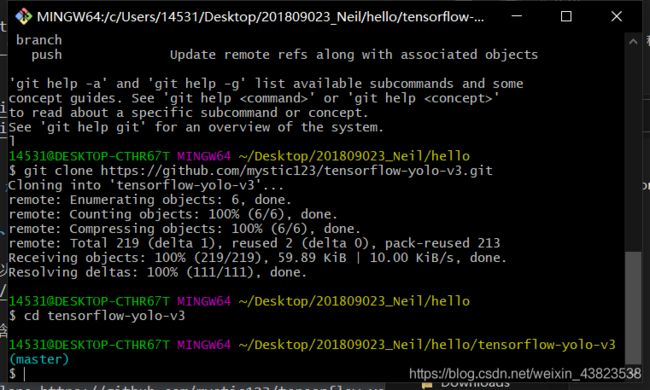
[转换工具]
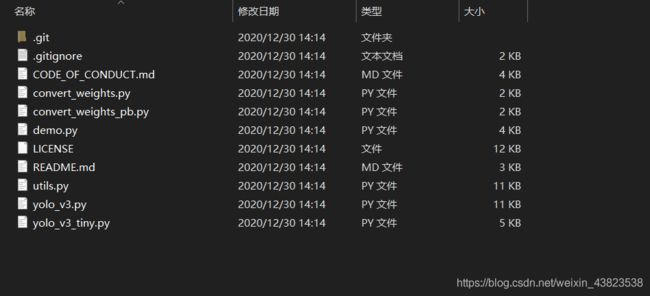
[下载完成]
$python3 ./convert_weights_pb.py
二、从TensorFlow的Pb模型转换为IR模型
- 拷贝frozen_tiny_yolo_v3.pb到OpenVINO所在的F:\IntelSWTools\openvino_2019.1.087\deployment_tools\model_optimizer文件夹下,
- 新建一个yolov3-tiny.json文件,放在F:\IntelSWTools\openvino_2019.1.087\deployment_tools\model_optimizer文件夹下。内容是,注意一下里面classes是你的数据集中目标类别数:
[
{
"id": "TFYOLOV3",
"match_kind": "general",
"custom_attributes": {
"classes": 3,
"coords": 4,
"num": 6,
"mask": [0,1,2],
"anchors":[10,14,23,27,37,58,81,82,135,169,344,319],
"entry_points": ["detector/yolo-v3-tiny/Reshape","detector/yolo-v3-tiny/Reshape_4"]
}
}
]
在F:\IntelSWTools\openvino_2019.1.087\deployment_tools\model_optimizer文件夹下,执行下面的命令来完成pb文件到OpenVINO的IR文件转换过程。
python mo_tf.py --input_model frozen_darknet_yolov3_model.pb
--tensorflow_use_custom_operations_config yolo_v3_tiny.json
--input_shape=[1,416,416,3] --data_type=FP32
因为yolov3-tiny里面的yoloRegion Layer层是openvino的扩展层,所以在vs2015配置lib和include文件夹的时候需要把cpu_extension.lib和extension文件夹加进来。最后include和lib文件夹分别有的文件如下:

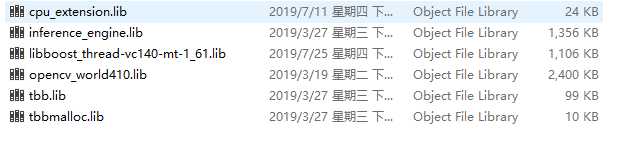
其中cpu_extension.lib在安装了OpenVINO之后可能是没有的,这时候就需要手动编译一下。这个过程很简单,我在后边放了一个链接讲得很清楚了。
把include和lib配置好之后就可以编写代码进行预测了。代码只需要在OpenVINO-YoloV3工程的cpp目录下提供的main.cpp稍微改改就可以了。因为我这里使用的不是原始的Darknet,而是AlexeyAB版本的darknet,所以图像resize到416的时候是直接resize而不是letter box的方式。具体来说修改部分的代码为:
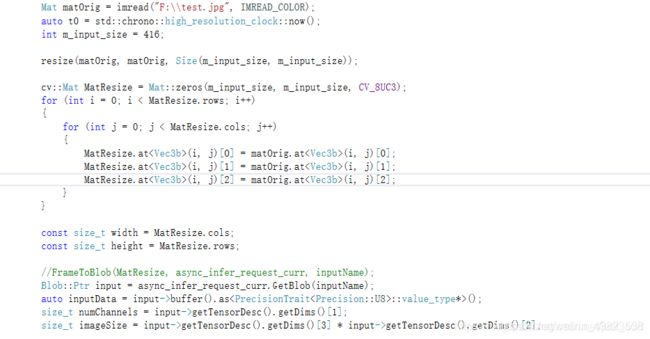
然后除了这个地方,由于使用的YOLOv3,OpenVINO-YoloV3里面的cpp默认使用的是YOLOv3的Anchor,所以Anchor也对应修改一下:

向推理过程了,经过我的测试,相比于原始的darknet测试结果在小数点后两位开始出现差距,从我在几千张图片的测试结果来看,精度差距在1/1000到1/500,完全是可以接受的。
ze到416的时候是直接resize而不是letter box的方式。具体来说修改部分的代码为:
[外链图片转存中…(img-7GnDPITy-1613628295888)]
然后除了这个地方,由于使用的YOLOv3-tiny,OpenVINO-YoloV3里面的cpp默认使用的是YOLOv3的Anchor,所以Anchor也对应修改一下:
[外链图片转存中…(img-INkTiBeJ-1613628295890)]
向推理过程了,经过我的测试,相比于原始的darknet测试结果在小数点后两位开始出现差距,从我在几千张图片的测试结果来看,精度差距在1/1000到1/500,完全是可以接受的。