企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)
目录
- 一、redis集群部署
-
- 1.Redis Cluster(Redis集群)简介
- 2.搭建集群
- 2、redis与mysql的结合
-
- 1.环境部署
- 2.配置 gearman 实现数据同步
一、redis集群部署
- Redis 集群是一个提供在多个Redis节点间共享数据的程序集,Redis集群并不支持处理多个keys的命令,因为需要移动数据,这样在高负载的情况下会发生不可预计的后果。
- Redis 集群的优势:
自动分割数据到不同的节点上。
整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
1.Redis Cluster(Redis集群)简介
- redis集群采用P2P模式,是完全去中心化的,不存在中心节点或者代理节点;redis集群是没有统一的入口的,客户端(client)连接集群的时候连接集群中的任意节点(node)即可,集群内部的节点是相互通信的(PING-PONG机制),每个节点都是一个redis实例;
- 为了实现集群的高可用,即判断节点是否健康(能否正常使用),redis-cluster有这么一个投票容错机制:如果集群中超过半数的节点投票认为某个节点挂了,那么这个节点就挂了(fail)。这是判断节点是否down掉的方法;
- 判断集群down掉的方式:如果集群中任意一个节点挂了,而且该节点没有从节点(备份节点),那么这个集群就down掉;
- 那么为什么任意一个节点挂了(没有从节点)这个集群就挂了呢?, 因为集群内置了16384个slot(哈希槽),并且把所有的物理节点映射到了这16384[0-16383]个slot上,或者说把这些slot均等的分配给了各个节点。当需要在Redis集群存放一个数据(key-value)时,redis会先对这个key进行crc16算法,然后得到一个结果。再把这个结果对16384进行求余,这个余数会对应[0-16383]其中一个槽,进而决定key-value存储到哪个节点中。所以一旦某个节点down了,该节点对应的slot就无法使用,那么就会导致集群无法正常工作。
查看create-cluster文件
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第1张图片](http://img.e-com-net.com/image/info8/b2501e07aa1c49699983042d42d9f91b.jpg)
可以看到里面指定了六个NODES(集群节点)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第2张图片](http://img.e-com-net.com/image/info8/205ebc2654194d4ab66cc4dfb9edb2a2.jpg)
集群的使用:集群并不是由一些普通的Redis实例组成的,集群模式需要通过配置启用;
创建六个以端口号为名字的子目录, 在将每个目录中运行一个 Redis 实例,编辑文件redis.conf
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第3张图片](http://img.e-com-net.com/image/info8/f0a5258e6821432083f747f8b3e41ff5.jpg)
cluster-enabled 选项用于开启实例的集群模式;
配置节点之间超时时间;
cluster-conf-file 选项设定了保存节点配置文件的路径,nodes.conf节点配置文件无须修改, Redis 集群在启动时创建, 并在有需要时自动进行更新。
开启Redis的AOF数据持久化存储,指定redis使用守护线程的方式启动;
编辑完成之后,启动第一个实例
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第4张图片](http://img.e-com-net.com/image/info8/44bec7503c61462983e05482f528dad1.jpg)
查看进程
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第5张图片](http://img.e-com-net.com/image/info8/628ac1a03dd14372a95879b4225f97fa.jpg)
同样的,将7001目录下的redis.conf文件拷贝到其余5个目录,只需修改端口号即可
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第6张图片](http://img.e-com-net.com/image/info8/db77098fbe1d4f2197383633689217a5.jpg)
启动第二个实例
![]()
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第7张图片](http://img.e-com-net.com/image/info8/2b9b3a6a7da84fcfa03506345d51f440.jpg)
依次启动剩余实例
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第8张图片](http://img.e-com-net.com/image/info8/0d49aec921ef4714bb34c9970dbe212d.jpg)
查看进程,可以看到6个redis节点都已经启动成功
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第9张图片](http://img.e-com-net.com/image/info8/782e85d4168148f783fb7f8d3ef31061.jpg)
可以看到生成的 appendonly.aof 日志文件
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第10张图片](http://img.e-com-net.com/image/info8/e5cb3b8b57e549b8ad488bbb0ea9ee81.jpg)
查看帮助文档
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第11张图片](http://img.e-com-net.com/image/info8/ab0ab06043c642d59ae2b70edf4bad3e.jpg)
2.搭建集群
此时已经有6个正在运行中的 Redis 实例,我们需要使用这些实例来创建集群,replicas1 表示我们希望为集群中的每个主节点创建一个从节点;
可以看到,六个节点中, 三个为主节点, 其余三个则是各个主节点的从节点;
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第12张图片](http://img.e-com-net.com/image/info8/1860f894cc85409887df57982fe90f05.jpg)
至此,Redi集群搭建成功,最后一段文字,显示了每个节点所分配的slots(哈希槽),这里总共6个节点,其中3个是从节点,所以3个主节点分别映射了0-5460、5461-10922、10933-16383solts。
集群分片模式
如果Redis只用复制功能做主从,那么当数据量巨大的情况下,单机情况下可能已经承受不下一份数据,更不用说是主从都要各自保存一份完整的数据。在这种情况下,数据分片(哈希分片)是一个非常好的解决办法。
Redis的Cluster正是用于解决该问题。它主要提供两个功能:
(1)自动对数据分片,落到各个节点上;
(2)即使集群部分节点失效或者连接不上,依然可以继续处理命令
输入yes
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第13张图片](http://img.e-com-net.com/image/info8/739d8adc4fe0468ea91899c0dc9f82f5.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第14张图片](http://img.e-com-net.com/image/info8/10147ad3d9ce455287da9bb19f0b3fa2.jpg)
使用集群;
cluster info :查看集群状态
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第15张图片](http://img.e-com-net.com/image/info8/61a9047bb5464b3a8d0e8430b52d6b5a.jpg)
使用redis-cli来进行集群的交互;
使用客户端连接任意一个节点即可,使用-c 表示以集群的方式登录,-p 指定端口;
注意:一定要加上-c,不然节点之间是无法自动跳转的

可以看到主从信息
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第16张图片](http://img.e-com-net.com/image/info8/6836a9179785443c97ef4be40f992cb6.jpg)
注意观察,它会自动切换到另一个redis去写或者读,可以看到在端口为7001的node上进行赋值操作,会重定向到在端口为7002的node上;
可以看到,端口为7006的节点虽然是端口为7001node节点的slave,但仍然能执行复制操作,说明redis集群无中心化的特点,任何节点都能进行读写操作
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第17张图片](http://img.e-com-net.com/image/info8/01595e207c7848669e3e65edcf13fe57.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第18张图片](http://img.e-com-net.com/image/info8/1a0249b8e9c24607b641d7971c43b8f6.jpg)
测试将端口号为7002的redis实例down掉

由于端口号为7002的redis实例是7004的master
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第19张图片](http://img.e-com-net.com/image/info8/f86fec5acfe14e109d7ef55f0a98d288.jpg)
因此,此时看不到7004redis实例的master
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第20张图片](http://img.e-com-net.com/image/info8/980150a7497a44d69319b0610ad0e308.jpg)
重新开启第二个redis实例
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第21张图片](http://img.e-com-net.com/image/info8/3107c9ddf0284d729746707354954b80.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第22张图片](http://img.e-com-net.com/image/info8/9b1ab231eaeb4a7ca6e46384a33ec285.jpg)
此时连接集群节点

可以看到相应的master
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第23张图片](http://img.e-com-net.com/image/info8/46b7d9396de24c5db687aec3180d32af.jpg)
接下来演示节点加入redis集群的操作方式;
同样的继续建立两个以端口号为名字的子目录,在将每个目录中运行一个 Redis 实例,编辑文件redis.conf,修改端口号,启动相应实例
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第24张图片](http://img.e-com-net.com/image/info8/08569089bbce4ac780417abdffd227c2.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第25张图片](http://img.e-com-net.com/image/info8/76b6c768cccc43d6b8b5579934146420.jpg)
添加新的master节点(端口为7007的redis实例);
注意语法,一个新节点IP:端口 空格 一个旧节点IP:端口,注意点是:
1.不能多个新节点一次性添加;
2.新节点后是旧节点
这里是将节点加入了集群中,但是并没有分配slot(哈希槽),所以这个节点并没有真正的开始分担集群工作。
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第26张图片](http://img.e-com-net.com/image/info8/4a282ef53598466aabe5476eaa66443d.jpg)
集群完整性检查:
集群完整性是指所有的槽都分配到存活的redis主节点上,只要16384个槽中有一个槽未被分配,则表示集群不完整
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第27张图片](http://img.e-com-net.com/image/info8/8ccb4cd8a9354fa29de52c5e6038686f.jpg)
接下来为端口号为7007的redis实例分配相应的slave节点(端口号为7008的redis实例),后面要加上对应master的id(上图所示)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第28张图片](http://img.e-com-net.com/image/info8/903f21d833b64068a64f651ccdf1faa7.jpg)
再次进行集群完整性检查,准备为加入集群的新的master(7007)分配哈希槽
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第29张图片](http://img.e-com-net.com/image/info8/a5a12bd5dc604bb5a0f2e70b36e079b6.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第30张图片](http://img.e-com-net.com/image/info8/641b9d2f58f74a81b92b0e810300656d.jpg)
分配slot需要使用以下参数
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第31张图片](http://img.e-com-net.com/image/info8/93da8c434f744e598a7b9ab93f521c48.jpg)
host:port :指定集群的任意一节点进行迁移slot,重新分slots
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第32张图片](http://img.e-com-net.com/image/info8/c01eb0e5a70d40a78cef02ffb776d762.jpg)
设定分配1000个,此时会自动从其余三个master节点为新的master节点分配一部分哈希槽,使得所有槽均匀分配
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第33张图片](http://img.e-com-net.com/image/info8/017ddc7b203d45b4b654629e426b7977.jpg)
再次进行集群完整性检查,可以看到slot已经分配成功
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第34张图片](http://img.e-com-net.com/image/info8/5c20f2abcece4dda81616eb7363dd588.jpg)
测试将第一个redis实例down掉

![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第35张图片](http://img.e-com-net.com/image/info8/34cfac7d026743b89897612e133a4640.jpg)
再将第一个redis实例对应的slave节点的redis实例也down掉;
此时整个redis集群就已经down掉,无法正常工作
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第36张图片](http://img.e-com-net.com/image/info8/d6db527079d8464d81173a853a9a7b68.jpg)
重新启动第二个和第六个redis实例
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第37张图片](http://img.e-com-net.com/image/info8/8883330c18ae4b118cecbf5cfe435bfa.jpg)
可以看到,此时第二个实例自动变为了原本是其slave的端口号为7004的redis节点的slave
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第38张图片](http://img.e-com-net.com/image/info8/c717456668ad4c43b88873396de8db70.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第39张图片](http://img.e-com-net.com/image/info8/2c40fd4e7cc34537a2192ae35ae65bdd.jpg)
输入info,可以看到指定redis服务的详细信息

![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第40张图片](http://img.e-com-net.com/image/info8/25a14b59e69c42dc8466ae8001636260.jpg)
2、redis与mysql的结合
- redis:内存型数据库(数据放在内存 AOF:增量更新 RDB:覆盖),有持久化功能,具备分布式特性,可靠性高,适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统。
mysql:数据放在磁盘,是关系型数据库,主要用于存放持久化数据, - redis和mysql的区别总结
类型上:从类型上来说,mysql是关系型数据库,redis是缓存数据库;
作用上:mysql用于持久化的存储数据到硬盘,功能强大,但是速度较慢;redis用于存储使用较为频繁的数据到缓存中,读取速度快 - 为什么要作缓存
当网站的处理和访问量非常大的时候,我们的数据库的压力就变大了,数据库的连接池,数据库同时处理数据的能力就会受到很大的挑战,一旦数据库承受了其最大承受能力,网站的数据处理效率就会大打折扣。此时就要使用高并发处理、负载均衡和分布式数据库,而这些技术既花费人力,又花费资金。
缓存机制说明:所有的查询结果都放进了缓存,也就是把MySQL查询的结果放到了redis中去, 然后第二次发起该条查询时就可以从redis中去读取查询的结果,从而不与MySQL交互,也就实现了读写分离,也就是Redis只做读操作。由于缓存在内存中,所以查询会很快,从而达到优化的效果,redis的查询速度之于MySQL的查询速度相当于内存读写速度 /硬盘读写速度。
1.环境部署
实验环境:server1(安装httpd,php等) 、server2(作为redis服务器)、 server3(部署mysql数据库服务);
除了server2,停止其余主机的redis服务。
首先将server3上将之前添加的环境变量去掉,恢复初始设定即可
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第41张图片](http://img.e-com-net.com/image/info8/ead8f015396147808a83d5c39da0fa3d.jpg)
server3安装mariadb-server服务
![]()
编辑mysql配置文件
![]()
设定如下;
datadir = path:从给定目录读取数据库文件;
socket = filename:为MySQL客户程序与服务器之间的本地通信指定一个**套接字文件(**仅适用于UNIX/Linux系统;默认设置一般是/var/lib/mysql/mysql.sock文件)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第42张图片](http://img.e-com-net.com/image/info8/1dc65379ac9a47b39b63d7b0bb5b25db.jpg)
启动数据库服务,测试进入数据库
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第43张图片](http://img.e-com-net.com/image/info8/71c01570d77b4577958c379809486179.jpg)
真机将下载的sql数据传给server3
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第44张图片](http://img.e-com-net.com/image/info8/3704869a449b4d7985f035c7d408afab.jpg)
![]()
数据库名为test,表名也是test
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第45张图片](http://img.e-com-net.com/image/info8/8c8a73deb578495c8dd691ace791071b.jpg)
将test.sql文件的内容输入重定向到mysql数据库;
进入数据库查看test表,可以看到数据信息
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第46张图片](http://img.e-com-net.com/image/info8/6227736685e745af8927d8ee860f71b3.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第47张图片](http://img.e-com-net.com/image/info8/ae9b3fd922cb4930bb0ab64bb2bd4449.jpg)
接下来去server2(部署redis服务器),编辑主配置文件
![]()
replicaof用于追随某个节点的redis,被追随的节点为主节点,追随的为从节点;
将replicaof注释掉,此时server2成为单独的master
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第48张图片](http://img.e-com-net.com/image/info8/03930408faef41b8a6575370002a0c29.jpg)
![]()
![]()
查看Redis 服务器的信息
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第49张图片](http://img.e-com-net.com/image/info8/aafa044b6084423c9b3813d6fb25e038.jpg)
接下来对server1进行配置,安装pstree;
Psmisc软件包包含三个帮助管理/proc目录的程序:
fuser 显示使用指定文件或者文件系统的进程的PID;
killall 杀死某个名字的进程,它向运行指定命令的所有进程发出信号;
pstree 树型显示当前运行的进程。

使用killall指令将serve1之前开启的redis服务进程都杀掉
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第50张图片](http://img.e-com-net.com/image/info8/d2224aba50564631aaa105e0e6ee7964.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第51张图片](http://img.e-com-net.com/image/info8/ddaa6f4686fe49778ecd25b5c7ce2d53.jpg)
确保server1的环境变量也为初始设定
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第52张图片](http://img.e-com-net.com/image/info8/b7435522de6d40faa6801d6af039378d.jpg)
安装Apache, PHP,以及php连接mysql库组件
![]()
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第53张图片](http://img.e-com-net.com/image/info8/8a39cdaad55046ecbc487051a4779e9c.jpg)
查看 php 扩展
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第54张图片](http://img.e-com-net.com/image/info8/d931b8f4d4744c409978ba6e298cc457.jpg)
查看当前的php版本

真机获取test.php 文件,传给server1的Apache默认发布目录下
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第55张图片](http://img.e-com-net.com/image/info8/0715c4525feb497384810c4813327d8d.jpg)
编辑test.php文件,设定redis服务提供者为server2,mysql服务提供者为server3
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第56张图片](http://img.e-com-net.com/image/info8/c0d3c3340a7645eb9ecf25989b6347b4.jpg)
接下来进入数据库,添加授权用户操作
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第57张图片](http://img.e-com-net.com/image/info8/8d81d0c702f94aed8690f8f4ff9da494.jpg)
可以看到,此时server1的php 扩展中没有redis模块,这样就无法将其联系起来
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第58张图片](http://img.e-com-net.com/image/info8/66f0ee95b8ab42899221127ecb4f200f.jpg)
真机将指定目录传给server1
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第59张图片](http://img.e-com-net.com/image/info8/0e26d81c5b614fb99d83d1adf4abdecd.jpg)
server1安装相应rpm包
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第60张图片](http://img.e-com-net.com/image/info8/1ef74a094d3c4a2fbc51fae81f1b2f2d.jpg)
启动httpd服务

接着客户端访问网页,可以看到此时还看不到数据,这是因为当用户访问该网页时,其实先去访问的是redis服务,如果有缓存直接获取,没有的话再去mysql数据库取数据,并且会向redis缓存一份
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第61张图片](http://img.e-com-net.com/image/info8/7cb684d8706b46099e6bf6be6689b646.jpg)
刷新后就可以看到数据了
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第62张图片](http://img.e-com-net.com/image/info8/25095bc9eb274e909375c86dd56cf625.jpg)
server2连接Redis服务器;
Get 命令可以获取到指定 key 的值
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第63张图片](http://img.e-com-net.com/image/info8/7aed02dbc2a644c9a8225688c2ea09d2.jpg)
进入数据库,使用UPDATE 命令来更新 MySQL 中的数据
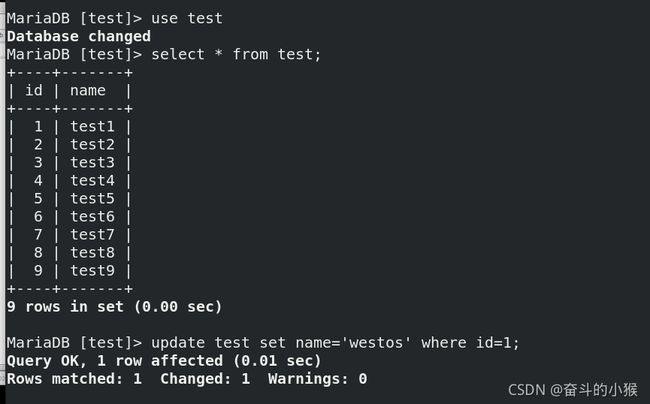
更新成功
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第64张图片](http://img.e-com-net.com/image/info8/929bc9a4b89a46acbb3e5c400c2c23b3.jpg)
但是网页上仍然获取到的是之前的数据,并没有看到数据更新(mysql与redis不能实时同步数据)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第65张图片](http://img.e-com-net.com/image/info8/29dc9f062585430e9bfad1606628dce7.jpg)
除非在redis服务中,手动进行赋值操作
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第66张图片](http://img.e-com-net.com/image/info8/16951e2e3b39400ab5924c94e6db4d18.jpg)
客户端才会看到同步后的数据
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第67张图片](http://img.e-com-net.com/image/info8/fe2febaa2d9642c4aad423c9191ec22a.jpg)
到这里,我们已经实现了 redis 作为 mysql 的缓存服务器,但是如果更新了 mysql,redis
中仍然会有对应的 KEY,数据就不会更新,此时就会出现 mysql 和 redis 数据不一致的情
况。所以接下来就要通过 mysql 触发器将改变的数据同步到 redis 中。
2.配置 gearman 实现数据同步
- Gearman 是一个支持分布式的任务分发框架:
Gearman Job Server:Gearman 核心程序,需要编译安装并以守护进程形式运行在后台。
Gearman Client:可以理解为任务的请求者。
Gearman Worker:任务的真正执行者,一般需要自己编写具体逻辑并通过守护进程方式
运行,Gearman Worker 接收到 Gearman Client 传递的任务内容后,会按顺序处理。 - 大致流程:
下面要编写的 mysql 触发器,就相当于 Gearman 的客户端。修改表,插入表就相当于直接
下发任务。然后通过 lib_mysqludf_json UDF 库函数将关系数据映射为 JSON 格式,然后
通过 gearman-mysql-udf 插件将任务加入到 Gearman 的任务队列中,最后通过
redis_worker.php,也就是 Gearman 的 worker 端来完成 redis 数据库的更新
真机将 lib_mysqludf_json 压缩包传给server3,server3需要编译数据库添加插件
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第68张图片](http://img.e-com-net.com/image/info8/864c9d8e66d44b4faac502f5a2c3bc12.jpg)
安装unzip解压缩工具

解压缩,安装gcc编译工具;
lib_mysqludf_json UDF 库函数将关系数据映射为 JSON 格式。通常,数据库中的数据映
射为 JSON 格式,是通过程序来转换的。
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第69张图片](http://img.e-com-net.com/image/info8/8f3a0c155f614bdc9a9f2c34ba7bc9c5.jpg)
安装 MariaDB-devel (包含开发首要的文件和一些静态库),编译数据库需要mariadb-devel和gcc
![]()
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第70张图片](http://img.e-com-net.com/image/info8/c9dc6ca9e0994c4caf48a9132705f925.jpg)
编译数据库
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第71张图片](http://img.e-com-net.com/image/info8/dbc7cef6de7d4444bdac9d13b3b75a67.jpg)
拷贝 lib_mysqludf_json.so 模块到 mysql 的插件目录
![]()
查看 mysql 的模块目录
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第72张图片](http://img.e-com-net.com/image/info8/9bbcaedd02974afc964fb3868d6f056a.jpg)
注册 UDF 函数,查看函数
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第73张图片](http://img.e-com-net.com/image/info8/39d2ad2ce536452ba9689059e9270ea6.jpg)
安装与配置 gearman:
在server1上安装 gearman 软件包
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第74张图片](http://img.e-com-net.com/image/info8/2079caf64d7e427496f29bd8843945af.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第75张图片](http://img.e-com-net.com/image/info8/efba0cd5fd7d4445a152a139e02f6357.jpg)
启动gearmand服务

真机将 gearman-mysql-udf 插件传给server3![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第76张图片](http://img.e-com-net.com/image/info8/80b5e745be2343b9a2d37302566f4946.jpg)
接下来 server3 安装 gearman-mysql-udf,这个插件是用来管理调用 Gearman 的分布式的队列
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第77张图片](http://img.e-com-net.com/image/info8/2bd81df14bdb43c491d8e70e6274a29d.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第78张图片](http://img.e-com-net.com/image/info8/d9ea00f90500478d9f66be512a14a0b7.jpg)
配置,此时会出现报错,因为需要安装依赖性软件
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第79张图片](http://img.e-com-net.com/image/info8/bbf423ca6b5b481fbb692ff862e18161.jpg)
server1将libgearman、libgearman-devel、libevent-devel的rpm包传给server3
![]()
安装依赖性
![]()
重新配置
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第80张图片](http://img.e-com-net.com/image/info8/693f561a92be4de69348719f17936407.jpg)
编译、安装
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第81张图片](http://img.e-com-net.com/image/info8/0d357b4e89cb467894e0b5ce1f948c65.jpg)
可以看到库函数已经被安装到了/usr/lib64/mysql/plugin目录下
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第82张图片](http://img.e-com-net.com/image/info8/a4cabb9ee3fc45d5a80813225dcd7cd6.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第83张图片](http://img.e-com-net.com/image/info8/43faf9bfb83a46ff8608463509ad9961.jpg)
以软连接的形式
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第84张图片](http://img.e-com-net.com/image/info8/d1cbdd39d5a24379adbf3a4768938829.jpg)
进入数据库,继续注册 UDF 函数;
查看函数
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第85张图片](http://img.e-com-net.com/image/info8/4c80dd11661c4e64a8b9d8d92922f5dd.jpg)
指定 gearman 的服务信息
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第86张图片](http://img.e-com-net.com/image/info8/f032b19436b344258b842ff556c1fe6d.jpg)
编写 mysql 触发器
![]()
将前面的内容注释,后面触发器部分打开
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第87张图片](http://img.e-com-net.com/image/info8/35c5ea4e597c4a059a17ebccac31abcd.jpg)
重新将test.sql文件输入重定向到mysql数据库;
查看触发器
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第88张图片](http://img.e-com-net.com/image/info8/f81baa70206d43e59fa0b7aa5410877b.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第89张图片](http://img.e-com-net.com/image/info8/3d078a34148742b684b9b789666a8717.jpg) server1编写 gearman 的 worker 端
server1编写 gearman 的 worker 端
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第90张图片](http://img.e-com-net.com/image/info8/2a77c27068a94e72bb7260a584ccbed9.jpg)
# vim worker.php
<?php
$worker = new GearmanWorker();
$worker->addServer();
$worker->addFunction('syncToRedis', 'syncToRedis');
$redis = new Redis();
$redis->connect('172.25.36.2', 6379);
while($worker->work());
function syncToRedis($job)
{
global $redis;
$workString = $job->workload();
$work = json_decode($workString);
if(!isset($work->id)){
return false;
}
$redis->set($work->id, $work->name); #这条语句就是将 id 作 KEY 和 name 作 VALUE 分开存储,需要和前面写的 php 测试代码的存取一致。
}
?>
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第91张图片](http://img.e-com-net.com/image/info8/dda6aba3416842f187e8acefb849aed5.jpg)
由于php 扩展没有gearman模块,因此需要安装相应rpm包
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第92张图片](http://img.e-com-net.com/image/info8/4796fce868e440ff9770b1cb8e8fa717.jpg)
接下来后台运行 gearman 的 worker
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第93张图片](http://img.e-com-net.com/image/info8/15c0f79d89b34a97b5c79e083aab4e98.jpg)
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第94张图片](http://img.e-com-net.com/image/info8/32b12d03cf50454cab6f2ff57e845d21.jpg)
此时更新 mysql 中的数据
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第95张图片](http://img.e-com-net.com/image/info8/6bd6738b358b413b8ddf8eff2b35d64a.jpg)
刷新测试页面可以看到数据同步
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第96张图片](http://img.e-com-net.com/image/info8/c554d4a584434eb8ab8c56ef736f4f44.jpg)
查看 redis

再次更新 mysql 中的数据

查看 redis
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第97张图片](http://img.e-com-net.com/image/info8/f3d41d47019b4092b54763c4a3f4d6f4.jpg)
数据仍然同步
![企业运维 --- LAMP架构( redis [2] 集群部署、redis与mysql的结合)_第98张图片](http://img.e-com-net.com/image/info8/79d29fb1b5c043e6a19bf4b1e39c58ce.jpg)