数据竞赛—二手车价格预测—数据分析
EDA目标
1.EDA的价值主要在于熟悉数据集,了解数据集,对数据集进行验证来确定所获得数据集可以用于接下来的机器学习或者深度学习使用
2.当了解了数据集之后我们下一步就是要去了解变量间的相互关系以及变量与预测值之间的存在关系。
3.引导数据科学从业者进行数据处理以及特征工程的步骤,使数据集的结构和特征集让接下来的预测问题更加可靠
4.完成对于数据的探索性分析,并对于数据进行一些图表或者文字总结并打卡
要求掌握


warnings包,利用过滤器来实现忽略警告语句
seaborn包是对matplotlib的增强版
missingno包每次处理数据时,缺失值是必须要考虑的问题。但是手工查看每个变量的缺失值是非常麻烦的一件事情。missingno提供了一个灵活且易于使用的缺失数据可视化和实用程序的小工具集,使您可以快速直观地总结数据集的完整性。
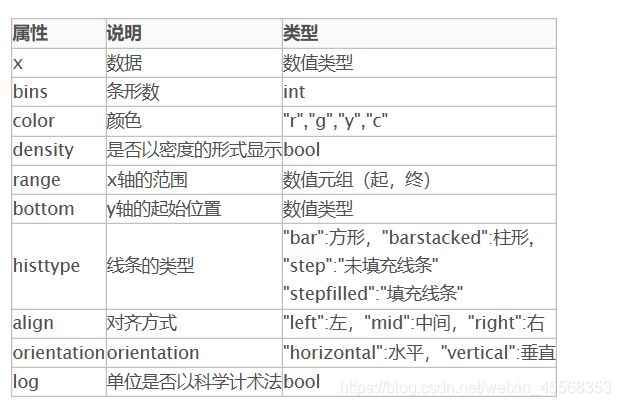
Pandas读取数据之后使用pandas的head()函数的时候,来观察一下读取的数据。head( )函数只能读取前五行数据如下图所示

同理df.tail() 是尾五行
pandas常用函数链接

要养成看数据集的head()以及shape的习惯,这会让你每一步更放心,导致接下里的连串的错误, 如果对自己的pandas等操作不放心,建议执行一步看一下,这样会有效的方便你进行理解函数并进行操作
总览数据概况
1.describe种有每列的统计量,个数count、平均值mean、方差std、最小值min、中位数25% 50% 75% 、以及最大值 看这个信息主要是瞬间掌握数据的大概的范围以及每个值的异常值的判断,比如有的时候会发现999 9999 -1 等值这些其实都是nan的另外一种表达方式,有的时候需要注意下
2.info 通过info来了解数据每列的type,有助于了解是否存在除了nan以外的特殊符号异常
describe()
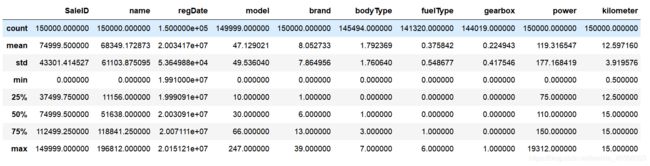
主要是瞬间掌握数据的大概的范围以及每个值的异常值的判断
info来了解数据每列的type
nan可视化
NaN(Not a Number,非数)是计算机科学中数值数据类型的一类值,表示未定义或不可表示的值
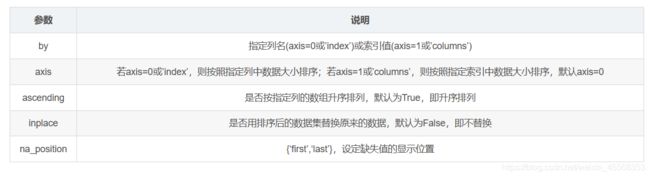
sort_values()函数的具体参数。
DataFrame.sort_values(by=‘##’,axis=0,ascending=True, inplace=False, na_position=‘last’)
通过以上可以很直观的了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于 nan存在的个数是否真的很大,如果很小一般选择填充,如果使用lgb等树模型可以直接空缺,让树自己去优化,但如果nan存在的过多、可以考虑删掉
可视化看下缺失值
无效矩阵的数据密集显示
missingno是一个可视化缺失值的库
msno.matrix(Train_data.sample(250)):sample(250)表示抽取表格中250个样本
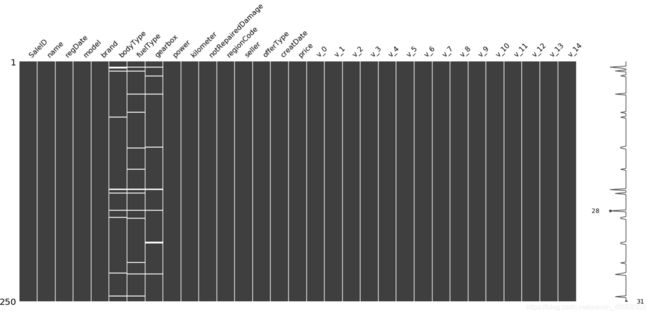
白线越多,代表缺失值越多
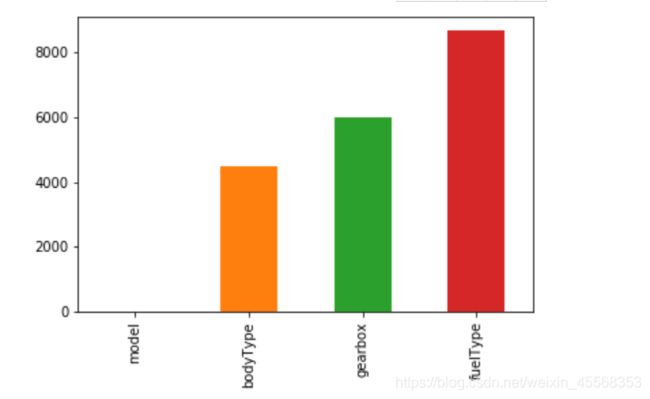
msno.bar(Train_data.sample(1000))
msno.bar 是列的无效的简单可视化
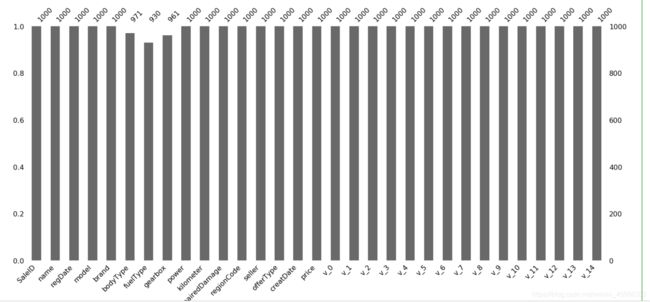
条形图可以更直观的看出每个变量缺失的比例和数量情况
在处理数据的时候,很多时候会遇到批量替换的情况,如果一个一个去修改效率过低,也容易出错。replace()是很好的方法
df.replace(to_replace, value) 前面是需要替换的值,后面是替换后的值
进行上述操作之后,其实原DataFrame是并没有改变的。改变的只是一个复制品
如果需要改变原数据,需要添加常用参数 inplace=True
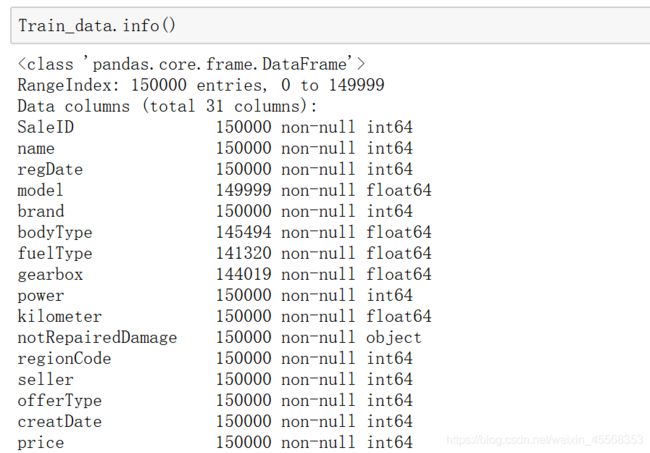
object
检查每个变量的数据类型。我们想要了解数据是否是数字(int64,float64)或不是(对象)
我使用Pandas从csv文件导入了数据框,我做的第一件事是确保它正确读取。我还使用了“isnull()”函数来确保我的数据都不能用于回归。在现实生活中,单个列可能具有整数,字符串或NaN形式的数据,所有这些都在一个地方 - 这意味着您需要检查以确保类型匹配并且适合回归。这个数据集恰好已经非常严格地准备好了,你不会经常在自己的数据库中看到这些数据集。
SciPy
NumPy包中大多数针对数组的函数也包含在SciPy中。SciPy提供预先测试好的例程,因此可以在科学计算应用中节省大量处理时间
SciPy 提供了复制的算法及其在 NumPy 中作为函数的用法。这将分配高级命令和多种多样的类来操作和可视化数据。SciPy 将多个小型包整合在一起,每个包都针对单独的科学计算领域。其中的几个子包是linalg(线性代数)、constants(物理和数学常数)和sparse(稀疏矩阵和相关例程)
import scipy.stats as st
SciPy.stats 是一个大型子包,包含各种各样的统计分布处理函数,可用于操作不同类型的数据集
sns.distplot
seaborn的displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途。具体用法如下
python可视化
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None, color=None, vertical=False, norm_hist=False, axlabel=None, label=None, ax=None)
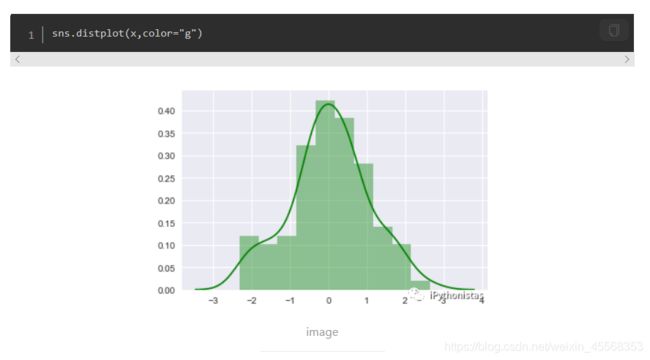
通过hist和kde参数调节是否显示直方图及核密度估计(默认hist,kde均为True)
hist:是否显示直方图
kde:是否显示核函数估计图
fit:控制拟合的参数分布图形
核密度估计(KDE)是一种估计连续随机变量的概率密度函数的方法
stats模块中所有的连续随机变量
dist_names = [ 'alpha', 'anglit', 'arcsine', 'beta', 'betaprime', 'bradford', 'burr', 'cauchy', 'chi', 'chi2', 'cosine', 'dgamma', 'dweibull', 'erlang', 'expon', 'exponweib', 'exponpow', 'f', 'fatiguelife', 'fisk', 'foldcauchy', 'foldnorm', 'frechet_r', 'frechet_l', 'genlogistic', 'genpareto', 'genexpon', 'genextreme', 'gausshyper', 'gamma', 'gengamma', 'genhalflogistic', 'gilbrat', 'gompertz', 'gumbel_r', 'gumbel_l', 'halfcauchy', 'halflogistic', 'halfnorm', 'hypsecant', 'invgamma', 'invgauss', 'invweibull', 'johnsonsb', 'johnsonsu', 'ksone', 'kstwobign', 'laplace', 'logistic', 'loggamma', 'loglaplace', 'lognorm', 'lomax', 'maxwell', 'mielke', 'nakagami', 'ncx2', 'ncf', 'nct', 'norm', 'pareto', 'pearson3', 'powerlaw', 'powerlognorm', 'powernorm', 'rdist', 'reciprocal', 'rayleigh', 'rice', 'recipinvgauss', 'semicircular', 't', 'triang', 'truncexpon', 'truncnorm', 'tukeylambda', 'uniform', 'vonmises', 'wald', 'weibull_min', 'weibull_max', 'wrapcauchy']
st.johnsonsu:无界约翰逊分布
skewness and kurtosis
偏度和峰度
1.偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征
偏度定义中包括正态分布(偏度=0),右偏分布(也叫正偏分布,其偏度>0),左偏分布(也叫负偏分布,其偏度<0)
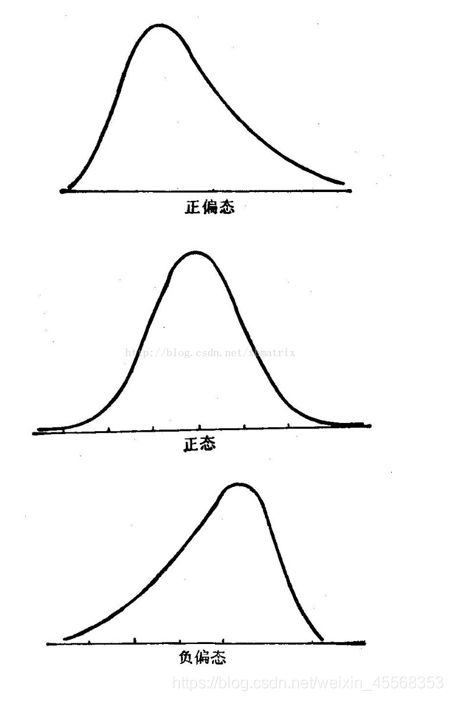
2.峰度(peakedness;kurtosis)又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。直观看来,峰度反映了峰部的尖度
plt.hist(Train_data[‘price’], orientation = ‘vertical’,histtype = ‘bar’, color =‘red’)
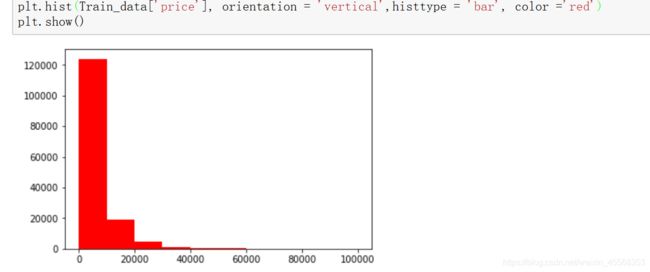
查看频数, 大于20000得值极少,其实这里也可以把这些当作特殊得值(异常值)直接用填充或者删掉,再前面进行
类型特征分析
1.特征分为类别特征和数字特征,并对类别特征查看unique分布
# 数字特征
# numeric_features = Train_data.select_dtypes(include=[np.number])
# numeric_features.columns
# # 类型特征
# categorical_features = Train_data.select_dtypes(include=[np.object])
# categorical_features.columns
这里需要人为根据实际含义来区分
Train_data[cat_fea].nunique():nunique() Return number of unique elements in the object.即返回的是唯一值的个数
unique()是以 数组形式(numpy.ndarray)返回列的所有唯一值(特征的所有唯一值)
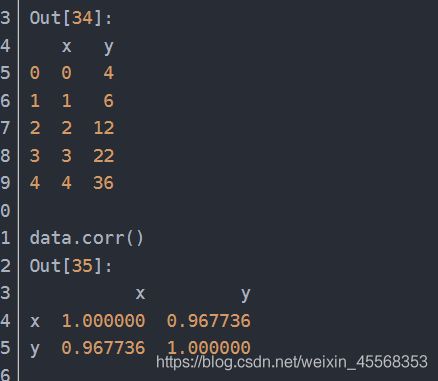
corr()参数解析
DataFrame.corr()参数详解:返回值:各类型之间的相关系数DataFrame表格
创建自定义图像
fig=plt.figure(figsize=(4,3),facecolor='blue')
plt.show()
理解fig,ax = plt.subplots()
f , ax = plt.subplots(figsize = (7, 7))
函数返回一个figure图像和子图ax的array列表
sns.heatmap的用法简介
这里的data,如果接收的是干干净净的numpy二维数组的话,可以看到行标就是0,1,2,如果是DataFrame,就可以用列名来标记了
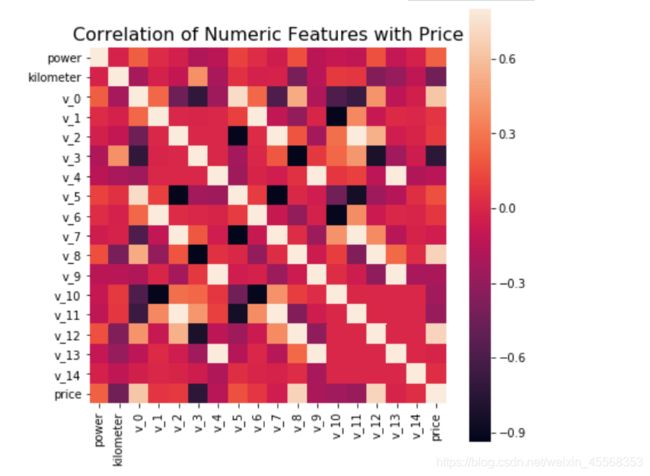
热力图就是把这个二维的数组的数字用热力图的颜色值来表示,数字是一模一样的~
annot: 默认为False,为True的话,会在格子上显示数字
vmax, vmin: 热力图颜色取值的最大值,最小值,默认会从data中推导
square : 为‘True’时,整个网格为一个正方形
heatmap
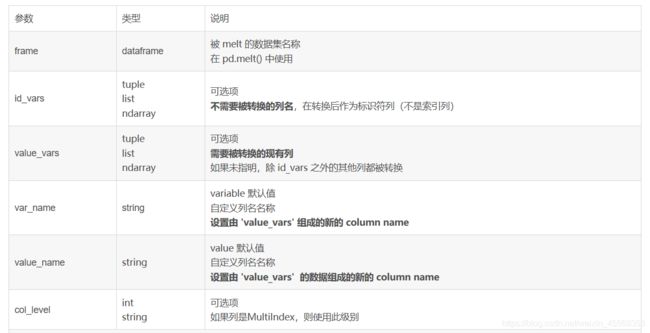
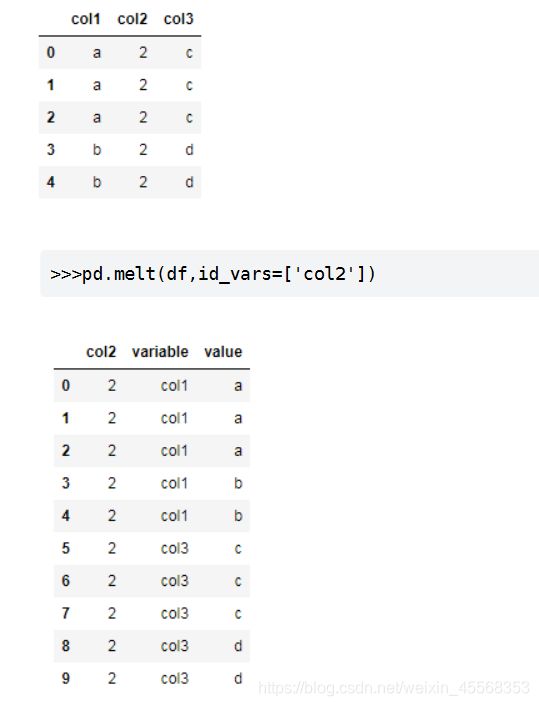
转换数据_melt()
将列名转换为列数据(columns name → column values),重构DataFrame
如果说 df.pivot() 将长数据集转换成宽数据集,df.melt() 则是将宽数据集变成长数据集
melt()的使用1
参数:
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)

melt()的使用2

seaborn可视化之FacetGrid()
1.先sns.FacetGrid画出轮廓
2.然后用map填充内容
FacetGrid当您想要在数据集的子集中分别可视化变量的分布或多个变量之间的关系时,该类非常有用
FacetGrid参数
seaborn.FacetGrid(data, row=None, col=None, hue=None, col_wrap=None, sharex=True, sharey=True, height=3, aspect=1, palette=None, row_order=None, col_order=None, hue_order=None, hue_kws=None, dropna=True, legend_out=True, despine=True, margin_titles=False, xlim=None, ylim=None, subplot_kws=None, gridspec_kws=None, size=None)
多绘图网格详解
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)

在该网格上可视化数据的主要方法是使用该FacetGrid.map()方法
![]()

seaborn设置风格
pairplot中pair是成对的意思,pairplot主要展现的是变量两两之间的关系(线性或非线性,有无较为明显的相关关系)
seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, kind=’scatter’, diag_kind=’hist’, markers=None, size=2.5, aspect=1, dropna=True, plot_kws=None, diag_kws=None, grid_kws=None)
kind:用于控制非对角线上的图的类型,可选"scatter"与"reg"
diag_kind:控制对角线上的图的类型,可选"hist"与"kde"
将 kind 参数设置为 “reg” 会为非对角线上的散点图拟合出一条回归直线,更直观地显示变量之间的关系。
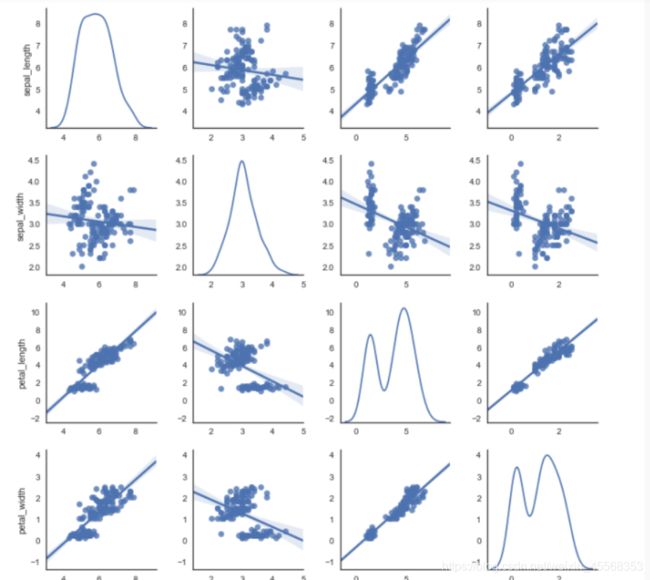
可以通过.columns和.index着两个属性返回数据集的列索引和行索引
多变量的关系可视化
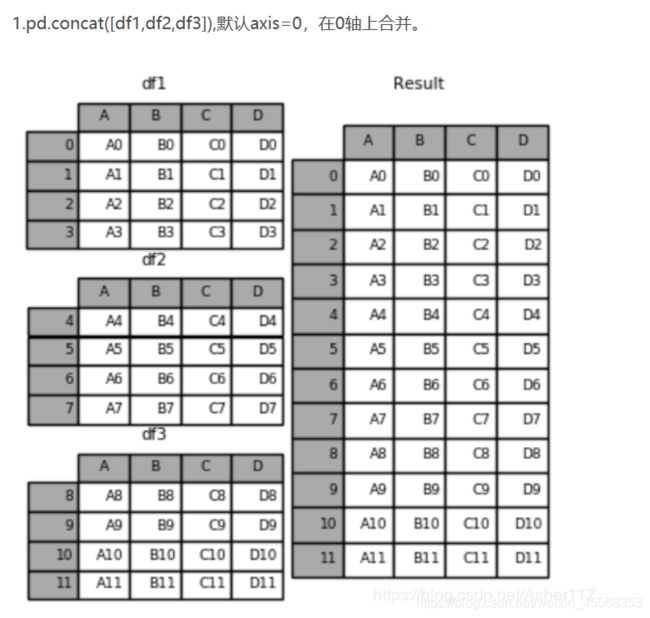
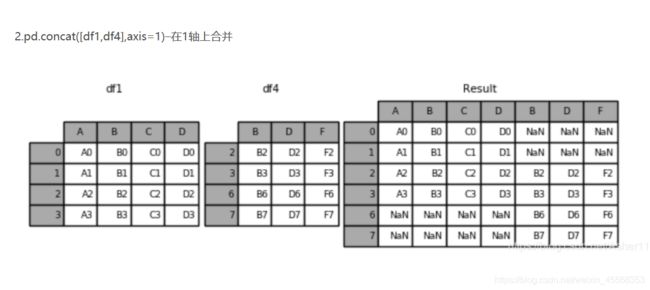
concat():连接函数
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
seaborn.regplot(x, y, data=None,x\_estimator=None,
x\_bins=None,x\_ci='ci', scatter=True,
fit\_reg=True, ci=95, n\_boot=1000,
units=None, order=1, logistic=False,
lowess=False, robust=False, logx=False,
x\_partial=None, y\_partial=None,
truncate=False, dropna=True,
x\_jitter=None, y\_jitter=None, label=None,
color=None, marker='o', scatter\_kws=None,
line\_kws=None, ax=None)

可视化线性回归关系regplot
seaborn常见绘图函数
类别特征分析
因为 name和 regionCode的类别太稀疏了,这里我们把不稀疏的几类画一下
箱形图可视化:通过箱形图可以很直观的读出一组数据的最大值、最小值、中位数、上四分位数、下四分位数、异常值,甚至有的箱形图还能读出平均值

pandas判断缺失值一般采用 isnull(),然而生成的却是所有数据的true/false矩阵,对于庞大的数据dataframe,很难一眼看出来哪个数据缺失,一共有多少个缺失数据,缺失数据的位置
df.isnull().any()则会判断哪些”列”存在缺失值


**fillna()**会填充nan数据,返回填充后的结果。如果希望在原DataFrame中修改,则把inplace设置为True
分别在坐标轴上根据最大值、上四分位数、中位数、下四分位数、最小值的数值画出5条线段
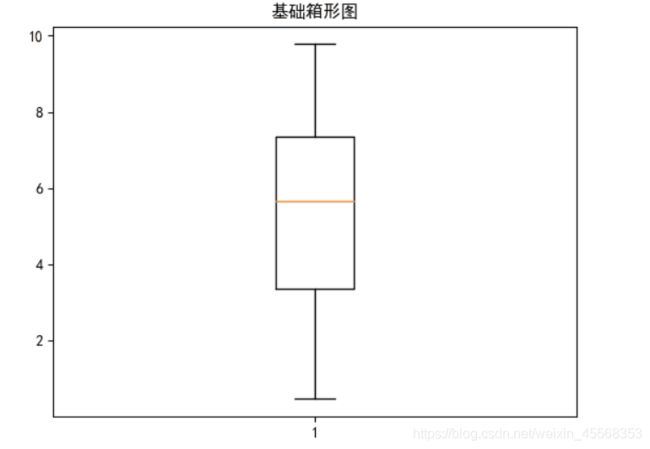
总而言之,箱形图可以很直观的分析数据的离散分布情况,上四分位数与下四分位数的距离越小说明越集中,否则说明越分散
箱形图还有一个优点是相对受异常值的影响比较小,能够准确稳定地描绘出数据的离散分布情况,会比较有利于数据的清洗
小提琴图 (Violin Plot) 用于显示数据分布及其概率密度
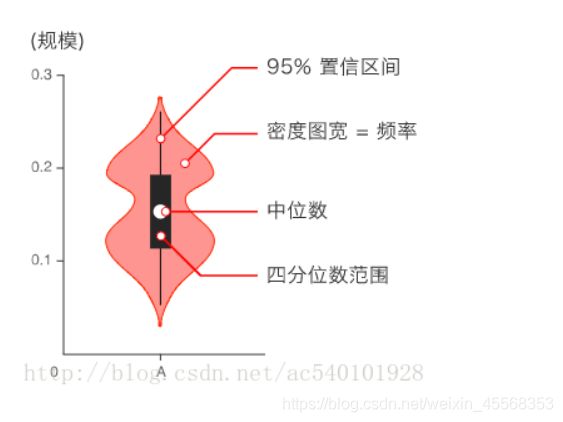
这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表
95% 置信区间,而白点则为中位数
用pandas_profiling生成数据报告
用pandas_profiling生成一个较为全面的可视化和数据报告(较为简单、方便) 最终打开html文件即可
经验总结
EDA:是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。

疑问
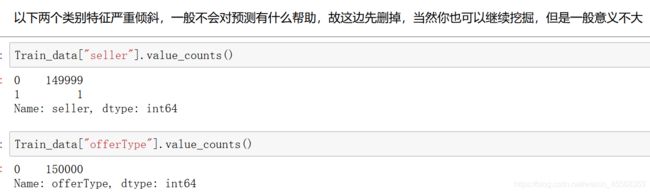
怎么看出这两个类别特征严重倾斜?31个特征一个一个提取