【进阶版】机器学习之特征降维、超参数调优及检验方法(04)
目录
-
- 欢迎订阅本专栏,持续更新中~
-
- 本专栏前期文章介绍!
- 机器学习配套资源推送
- 进阶版机器学习文章更新~
- 点击下方下载高清版学习知识图册
- 线性判别分析(LDA)
- 主成分分析(PCA)
- 超参数调优
- 检验方法
- 每文一语
欢迎订阅本专栏,持续更新中~
本专栏包含大量代码项目,适用于毕业设计方向选取和实现、科研项目代码指导,每一篇文章都是通过原理讲解+代码实战进行思路构建的,如果有需要这方面的指导可以私信博主,获取相关资源及指导!
本专栏前期文章介绍!
机器学习算法知识、数据预处理、特征工程、模型评估——原理+案例+代码实战
机器学习之Python开源教程——专栏介绍及理论知识概述
机器学习框架及评估指标详解
Python监督学习之分类算法的概述
数据预处理之数据清理,数据集成,数据规约,数据变化和离散化
特征工程之One-Hot编码、label-encoding、自定义编码
卡方分箱、KS分箱、最优IV分箱、树结构分箱、自定义分箱
特征选取之单变量统计、基于模型选择、迭代选择
机器学习八大经典分类万能算法——代码+案例项目开源、可直接应用于毕设+科研项目
机器学习分类算法之朴素贝叶斯
【万字详解·附代码】机器学习分类算法之K近邻(KNN)
《全网最强》详解机器学习分类算法之决策树(附可视化和代码)
机器学习分类算法之支持向量机
机器学习分类算法之Logistic 回归(逻辑回归)
机器学习分类算法之随机森林(集成学习算法)
机器学习分类算法之XGBoost(集成学习算法)
机器学习分类算法之LightGBM(梯度提升框架)
机器学习自然语言、推荐算法等领域知识——代码案例开源、可直接应用于毕设+科研项目
【原理+代码】Python实现Topsis分析法(优劣解距离法)
机器学习推荐算法之关联规则(Apriori)——支持度;置信度;提升度
机器学习推荐算法之关联规则Apriori与FP-Growth算法详解
机器学习推荐算法之协同过滤(基于用户)【案例+代码】
机器学习推荐算法之协同过滤(基于物品)【案例+代码】
预测模型构建利器——基于logistic的列线图(R语言)
基于surprise模块快速搭建旅游产品推荐系统(代码+原理)
机器学习自然语言处理之英文NLTK(代码+原理)
机器学习之自然语言处理——中文分词jieba库详解(代码+原理)
机器学习之自然语言处理——基于TfidfVectorizer和CountVectorizer及word2vec构建词向量矩阵(代码+原理)
机器学习配套资源推送
专栏配套资源推荐——部分展示(有需要可去对应文章或者评论区查看,可做毕设、科研参考资料)
自然语言处理之文本分类及文本情感分析资源大全(含代码及其数据,可用于毕设参考!)
基于Word2Vec构建多种主题分类模型(贝叶斯、KNN、随机森林、决策树、支持向量机、SGD、逻辑回归、XGBoost…)
基于Word2Vec向量化的新闻分本分类.ipynb
智能词云算法(一键化展示不同类型的词云图)运行生成HTML文件
协同过滤推荐系统资源(基于用户-物品-Surprise)等案例操作代码及讲解
Python机器学习关联规则资源(apriori算法、fpgrowth算法)原理讲解
机器学习-推荐系统(基于用户).ipynb
机器学习-推荐系统(基于物品).ipynb
旅游消费数据集——包含用户id,用户评分、产品类别、产品名称等指标,可以作为推荐系统的数据集案例
进阶版机器学习文章更新~
【进阶版】机器学习之基本术语及模评估与选择概念总结(01)
【进阶版】机器学习之模型性能度量及比较检验和偏差与方差总结(02)
【进阶版】机器学习之特征工程介绍及优化方法引入(03)
前期我们对机器学习的基础知识,从基础的概念到实用的代码实战演练,并且系统的了解了机器学习在分类算法上面的应用,同时也对机器学习的准备知识有了一个相当大的了解度,而且还拓展了一系列知识,如推荐算法、文本处理、图像处理。以及交叉学科的应用,那么前期你如果认真的了解了这些知识,并加以利用和实现,相信你已经对机器学习有了一个“量”的认识,接下来的,我将带你继续学习机器学习学习,并且全方位,系统性的了解和深入机器学习领域,达到一个“质”的变化。
点击下方下载高清版学习知识图册
机器学习Python算法知识点大全,包含sklearn中的机器学习模型和Python预处理的pandas和numpy知识点

线性判别分析(LDA)
线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的降维方法。和主成分分析PCA不考虑样本类别输出的无监督降维技术不同,LDA是一种监督学习的降维技术,数据集的每个样本有类别输出。
LDA分类思想简单总结如下:
- 多维空间中,数据处理分类问题较为复杂,LDA算法将多维空间中的数据投影到一条直线上,将d维数据转化成1维数据进行处理。
- 对于训练数据,设法将多维数据投影到一条直线上,同类数据的投影点尽可能接近,异类数据点尽可能远离。
- 对数据进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定样本的类别。
如果用一句话概括LDA思想,即“投影后类内方差最小,类间方差最大”。
假设有红、蓝两类数据,这些数据特征均为二维,如下图所示。我们的目标是将这些数据投影到一维,让每一类相近的数据的投影点尽可能接近,不同类别数据尽可能远,即图中红色和蓝色数据中心之间的距离尽可能大。
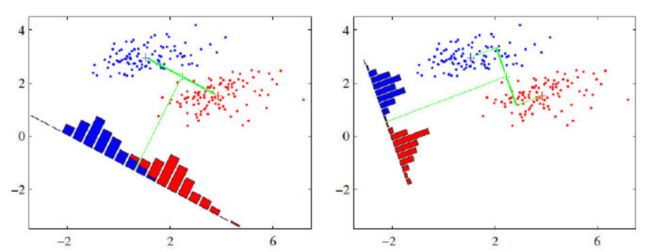
从上图直观看出,右图红色数据和蓝色数据在各自的区域来说相对集中,根据数据分布直方图也可看出,所以右图的投影效果好于左图,左图中间直方图部分有明显交集。
以上例子是基于数据是二维的,分类后的投影是一条直线。如果原始数据是多维的,则投影后的分类面是一低维的超平面。

主成分分析(PCA)
- PCA就是将高维的数据通过线性变换投影到低维空间上去。
- 投影思想:找出最能够代表原始数据的投影方法。被PCA降掉的那些维度只能是那些噪声或是冗余的数据。
- 去冗余:去除可以被其他向量代表的线性相关向量,这部分信息量是多余的。
- 去噪声,去除较小特征值对应的特征向量,特征值的大小反映了变换后在特征向量方向上变换的幅度,幅度越大,说明这个方向上的元素差异也越大,要保留。
- 对角化矩阵,寻找极大线性无关组,保留较大的特征值,去除较小特征值,组成一个投影矩阵,对原始样本矩阵进行投影,得到降维后的新样本矩阵。
- 完成PCA的关键是——协方差矩阵。协方差矩阵,能同时表现不同维度间的相关性以及各个维度上的方差。协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。
之所以对角化,因为对角化之后非对角上的元素都是0,达到去噪声的目的。对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉,即去冗余。

降维的必要性:
- 多重共线性和预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。
- 高维空间本身具有稀疏性。一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有2%。
- 过多的变量,对查找规律造成冗余麻烦。
- 仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
降维的目的:
- 减少预测变量的个数。
- 确保这些变量是相互独立的。
- 提供一个框架来解释结果。相关特征,特别是重要特征更能在数据中明确的显示出来;如果只有两维或者三维的话,更便于可视化展示。
- 数据在低维下更容易处理、更容易使用。
- 去除数据噪声。
- 降低算法运算开销。
超参数调优
为了进行超参数调优,我们一般会采用网格搜索、随机搜索、贝叶斯优化等算法。在具体介绍算法之前,需要明确超参数搜索算法一般包括哪几个要素。
一 是目标函数,即算法需要最大化/最小化的目标;
二是搜索范围,一般通过上限和 下限来确定;
三是算法的其他参数,如搜索步长。
- 网格搜索,可能是最简单、应用最广泛的超参数搜索算法,它通过查找搜索范 围内的所有的点来确定最优值。如果采用较大的搜索范围以及较小的步长,网格 搜索有很大概率找到全局最优值。然而,这种搜索方案十分消耗计算资源和时间,特别是需要调优的超参数比较多的时候。因此,在实际应用中,网格搜索法一般会先使用较广的搜索范围和较大的步长,来寻找全局最优值可能的位置;然 后会逐渐缩小搜索范围和步长,来寻找更精确的最优值。这种操作方案可以降低 所需的时间和计算量,但由于目标函数一般是非凸的,所以很可能会错过全局最 优值。
- 随机搜索,随机搜索的思想与网格搜索比较相似,只是不再测试上界和下界之间的所有值,而是在搜索范围中随机选取样本点。它的理论依据是,如果样本点集足够 大,那么通过随机采样也能大概率地找到全局最优值,或其近似值。随机搜索一 般会比网格搜索要快一些,但是和网格搜索的快速版一样,它的结果也是没法保证的。
- 贝叶斯优化算法,贝叶斯优化算法在寻找最优最值参数时,采用了与网格搜索、随机搜索完全 不同的方法。网格搜索和随机搜索在测试一个新点时,会忽略前一个点的信息; 而贝叶斯优化算法则充分利用了之前的信息。贝叶斯优化算法通过对目标函数形状进行学习,找到使目标函数向全局最优值提升的参数。
检验方法
KS检验
Kolmogorov-Smirnov检验是基于累计分布函数的,用于检验一个分布是否符合某种理论分布或比较两个经验分布是否有显著差异。
- 单样本K-S检验是用来检验一个数据的观测经验分布是否符合已知的理论分布。
- 两样本K-S检验由于对两样本的经验分布函数的位置和形状参数的差异都敏感,所以成为比较两样本的最有用且最常用的非参数方法之一。

T检验
T检验,也称student t检验,主要用户样本含量较小,总体标准差未知的正态分布。
t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
t检验分为单总体检验和双总体检验。
F检验
T检验和F检验的由来:为了确定从样本中的统计结果推论到总体时所犯错的概率。
F检验又叫做联合假设检验,也称方差比率检验、方差齐性检验。是由英国统计学家Fisher提出。通过比较两组数据的方差,以确定他们的精密度是否有显著性差异。
Grubbs检验
一组测量数据中,如果个别数据偏离平均值很远,那么称这个数据为“可疑值”。用格拉布斯法判断,能将“可疑值”从测量数据中剔除。
卡方检验
卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,卡方值越大,越不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合。
-
提出原假设H0:总体X的分布函数F(x);
-
将总体x的取值范围分成k个互不相交的小区间A1-Ak;
-
把落入第i个区间Ai的样本的个数记做fi,成为组频数,f1+f2+f3+…+fk = n;
-
当H0为真时,根据假设的总体理论分布,可算出总体X的值落入第i个小区间Ai的概率pi,于是n*pi就是落入第i个小区间Ai的样本值的理论频数;
-
当H0为真时,n次试验中样本落入第i个小区间Ai的频率fi/n与概率pi应该很接近。基于这种思想,皮尔逊引入检测统计量:

-
在H0假设成立的情况下服从自由度为k-1的卡方分布。
KS检验与卡方检验
相同点:都采用实际频数和期望频数只差进行检验
不同点:
- 卡方检验主要用于类别数据,而KS检验主要用于有计量单位的连续和定量数据。
- 卡方检验也可以用于定量数据,但必须先将数据分组才能获得实际的观测频数,而KS检验能直接对原始数据进行检验,所以它对数据的利用比较完整。
每文一语
我们一路奋战,不是为了改变世界,而是为了不让世界改变我们。