论文阅读笔记CvT: Introducing Convolutions to Vision Transformers
1 论文简介
论文标题:
CvT: Introducing Convolutions to Vision Transformers
论文发表位置:
ICCV 2021
论文地址:
[2103.15808] CvT: Introducing Convolutions to Vision Transformers (arxiv.org)
[PDF] CvT: Introducing Convolutions to Vision Transformers | Semantic Scholar
论文单位:
McGill University 麦吉尔大学 qs31 加拿大第一 坐落于蒙特利尔
Microsoft Cloud + AI
代码地址:
https://github.com/leoxiaobin/CvT
2 摘要Abstract
本文提出了一种新的网络架构CvT: Convolutional vision Transformer。这个新架构通过在ViT模型中引入卷积,提升了模型的表现和效率,达到了SOTA。
本文的模型有两个重要的改进:
- 包含新式卷积嵌入词向量(convolutional token embedding)的分层Transformer结构。
- 利用了卷积投影( Convolutional Projection)的卷积Transformer Block
上面的改进将CNNs的优势(平移、缩放、畸变不变性shift, scale, distortion invariance)引入到了ViT中,还同时保持了Transformer的长处(动态注意力dynamic attention、全局上下文global context、更好的泛化能力better generalization)。
本文中针对CvT进行了大量的实验,验证了这个模型的有效性。它以更小的参数量和更少的FLOPs达到了比其他ViT模型和ResNet更好的效果。
此外,在大数据集上预训练后,面对下游任务时,经过微调,仍然可以保持模型的优越性。
最后,本文的研究显示,可以将位置编码从本文的模型中安全地移除,尽管它在其他已有的ViT模型中是很重要的一部分,这样做可以在高尺寸视觉任务中进一步简化模型的设计。
3 总结Conclusion
本文中提出了一种将卷积和ViT结合的新的模型结构。这个结构兼具卷积和ViT在视觉任务中的优点。
大量的实验证实了卷积词向量(convolutional token embedding)和卷积投影(Convlutional projection)以及卷积实现的多层级网络结构的有效性,这些设计使得本文的模型使用较少的计算资源消耗实现了优越的性能。
因为卷积操作有着内置的局部上下文结构,本文的CvT不再需要位置编码(positional embedding),这使得本文的模型有能力去适应不同视觉任务的不同输入尺寸。
4 介绍Introduction
近年来,Transformer在NLP领域占据了主导地位。
ViT是首个仅仅使用Transformer的视觉模型,并且获得了良好的图像分类性能。
ViT的不足之处:
在小规模数据上训练时,它的表现弱于同等大小的CNNs。
出现这个现象的原因可能是:
ViT缺少CNN架构的与生俱来的一些重要特性。图片的空间相邻的像素往往有着很高的关联性,因此图片本身具有很强的平面局部结构。而CNN可以迫使模型去捕捉这种局部结构,因为CNN有着局部感受野、共享权重、空间尺寸的下采样的特点,有着平移、缩放、扭曲不变性的特性。
本文提出的解决办法:
本文将卷积引入了ViT中,提出了CvT模型,在提升了模型的表现以及鲁棒性的同时保持着较少的资源消耗。
首先,使用分层的Transformer结构。每一层的开头使用convolutional token embedding,对token map进行卷积操作(后接LayerNorm)。
这使得模型能够捕捉局部信息,缩小序列长度(经过卷积后map尺寸变小,相应的序列就变短了)的同时增加特征向量的维度。
然后修改Transformer Block中self-attention前面的线性投影模块。将其替换为convolutional projection。
这使得模型能够进一步地捕捉局部空间信息,减少注意力机制中的语义模糊性。另一方面,可以使用少量的性能消耗来换取计算复杂度的优化。
总之,本文提出的CvT能够兼具CNN和Transformer的优点。
5 方法Method
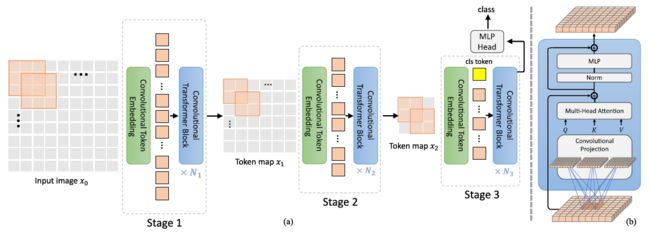
图a是CvT的结构;图b是Convolutional Transformer Block的详细结构。
CvT的结构使用了类似CNN的分层级的结构。
5.1 Convolutional Token Embedding
首先输入特征图会通过Convolutional Token Embedding Layer将序列(序列reshape到二维特征图再操作)映射到新的序列(新序列的维度的尺寸不同,使用带重叠的卷积操作实现),然后通过一个LayerNorm操作。最后是堆叠一系列的Convolutional Transformer Blocks。
与ViT中使用卷积将图片划分为patch的方式的不同:
这里的卷积将feature map划分成不同的patch作为token不同,这里的convolutional token embedding虽然也是一层卷积层,但是每次卷积结果是一个token(1*Ci),通过控制卷积步长控制token的个数(H*W)。
Convolutional Token Embedding的目的:
从低级边缘特征到深层次的语义信息,建模局部空间上下文信息,形成一种类似CNN的分层级结构。
5.2 Convolutional Projection
Convolutional Transformer Blocks的详细结构中,首先使用一个深度可分离卷积(depth-wise convolutional operation)作为Convolutional Projection,将ViT中的标准位置线性投影替换,输出作为Query,Key,Value的值。
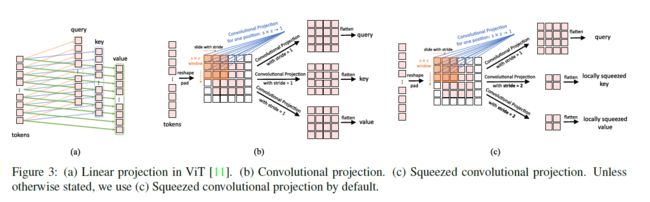
Convolutional Projection的目的:
实现额外的局部空间上下文信息建模,通过将K和V的矩阵下采样使得计算资源消耗更+少。
最后
最后一层会加入分类辅助向量(classification token),最后输入MLP Head去完成分类。