前言
Gradle自定义Task看起来非常简单,通过tasks.register等API就可以轻松实现。但实际上为了写出高效的,可缓存的,不拖慢编译速度的task,还需要了解更多知识。
本文主要包括以下内容:
- 定义Task
- 查找Task
- 配置Task
- 将参数传递给Task构造函数
- Task添加依赖
- Task排序
- Task添加说明
- 跳过Task
- Task支持增量编译
- Finalizer Task
定义Task
如上所说,自定义Task一般可以通过register API实现
tasks.register("hello") {
doLast {
println("hello")
}
}
tasks.register("copy") {
from(file("srcDir"))
into(buildDir)
}
如果是kotlin或者kts中,也可以通过代理来实现
val hello by tasks.registering {
doLast {
println("hello")
}
}
val copy by tasks.registering(Copy::class) {
from(file("srcDir"))
into(buildDir)
}
register与create的区别
除了上面介绍的register,其实create也可以用于创建Task,那么它们有什么区别呢?
- 通过register创建时,只有在这个task被需要时才会真正创建与配置该Task(被需要是指在本次构建中需要执行该Task)
- 通过create创建时,则会立即创建与配置该Task
总得来说,通过register创建Task性能更好,更推荐使用
查找Task
我们有时需要查找Task,比如需要配置或者依赖某个Task,我们可以通过named方法来查找对应名字的task
tasks.register("hello")
tasks.register("copy")
println(tasks.named("hello").get().name) // or just 'tasks.hello' if the task was added by a plugin
println(tasks.named("copy").get().destinationDir)
也可以使用tasks.withType()方法来查找特定类型的Task
tasks.withType().configureEach { enabled = false } tasks.register("test") { dependsOn(tasks.withType ()) }
除了上述方法,也可以通过tasks.getByPath()方法来查找task,不过这种方式破坏了configuration avoidance和project isolation,因此不被推荐使用
配置Task
在创建了Task之后,我们常常需要配置Task
我们可以在查找到Task之后进行配置
tasks.named("myCopy") { from("resources") into("target") include("**/*.txt", "**/*.xml", "**/*.properties") }
我们还可以将Task引用存储在变量中,并用于稍后在脚本中进一步配置任务。
val myCopy by tasks.existing(Copy::class) {
from("resources")
into("target")
}
myCopy {
include("**/*.txt", "**/*.xml", "**/*.properties")
}
我们也可以在定义Task时进行配置,这也是最常用的一种
tasks.register("copy") { from("resources") into("target") include("**/*.txt", "**/*.xml", "**/*.properties") }
将参数传递给Task构造函数
除了在Task创建后配置参数,我们也可以将参数传递给Task的构建函数,为了实现这点,我们必须使用@Inject注解
abstract class CustomTask @Inject constructor(
private val message: String,
private val number: Int
) : DefaultTask()
然后,我们可以创建一个Task,在参数列表的末尾传递构造函数参数。
tasks.register("myTask", "hello", 42)
需要注意的是,在任何情况下,作为构造函数参数传递的值都必须是非空的。如果您尝试传递一个null值,Gradle 将抛出一个NullPointerException指示哪个运行时值是null.
Task添加依赖
有几种方法可以定义Task的依赖关系,首先我们可以通过名称定义依赖项
project("project-a") {
tasks.register("taskX") {
dependsOn(":project-b:taskY")
doLast {
println("taskX")
}
}
}
project("project-b") {
tasks.register("taskY") {
doLast {
println("taskY")
}
}
}
其次我们也可以通过Task对象定义依赖项
val taskX by tasks.registering {
doLast {
println("taskX")
}
}
val taskY by tasks.registering {
doLast {
println("taskY")
}
}
taskX {
dependsOn(taskY)
}
还有一些更高端的用法,我们可以用provider懒加载块来定义依赖项,在evaluated阶段,provider被传递给正在计算依赖的task
provider块应返回单个对象Task或Task对象集合,然后将其视为任务的依赖项,如下所示:taskx添加了所有以lib开头的对象
val taskX by tasks.registering {
doLast {
println("taskX")
}
}
// Using a Gradle Provider
taskX {
dependsOn(provider {
tasks.filter { task -> task.name.startsWith("lib") }
})
}
tasks.register("lib1") {
doLast {
println("lib1")
}
}tasks.register("lib2") {
doLast {
println("lib2")
}
}
tasks.register("notALib") {
doLast {
println("notALib")
}
}
Task排序
有时候,两个task之间没有依赖关系,但是对两个task的执行顺序却有所要求
任务排序和任务依赖之间的主要区别在于,排序规则不会影响将执行哪些任务,只会影响它们的执行顺序。
任务排序在许多场景中都很有用:
- 强制执行任务的顺序:例如,build 永远不会在clean 之前运行。
- 在构建的早期运行构建验证:例如,在开始发布构建工作之前验证我是否拥有正确的凭据。
- 通过在长时间验证任务之前运行快速验证任务来更快地获得反馈:例如,单元测试应该在集成测试之前运行。
- 聚合特定类型的所有任务的结果的任务:例如测试报告任务组合所有已执行测试任务的输出。
gradle提供了两个可用的排序规则:mustRunAfter 和 shouldRunAfter
当您使用mustRunAfter排序规则时,您指定taskB必须始终在taskA之后运行,这表示为taskB.mustRunAfter(taskA)
而shouldRunAfter规则理加弱化,因为在两种情况下这条规则会被忽略。一是使用这条规则会导致先后顺序成环的情况,二是当并行执行task,并且任务的所有依赖关系都已经满足时,那么无论它的shouldRunAfter依赖关系是否已经运行,这个任务都会运行。
因此您应该在排序有帮助但不是严格要求的情况下使用shouldRunAfter
示例如下:
val taskX by tasks.registering {
doLast {
println("taskX")
}
}
val taskY by tasks.registering {
doLast {
println("taskY")
}
}
// mustRunAfter
taskY {
mustRunAfter(taskX)
}
// shouldRunAfter
taskY {
shouldRunAfter(taskX)
}
需要注意的是,B.mustRunAfter(A)或B.shouldRunAfter(A)并不意味着任务之间存在任何执行依赖关系:
我们可以独立执行A或者任务B。排序规则仅在两个任务都计划执行时才有效。
Task添加说明
您可以为Task添加说明。执行时gradle tasks时会显示此说明。
tasks.register("copy") { description = "Copies the resource directory to the target directory." from("resources") into("target") include("**/*.txt", "**/*.xml", "**/*.properties") }
跳过Task
gradle提供了多种方式来跳过task的执行
使用onlyIf
你可以通过onlyIf为任务的执行添加条件,如果任务应该执行,则应该返回 true,如果应该跳过任务,则返回 false
val hello by tasks.registering {
doLast {
println("hello world")
}
}
hello {
onlyIf { !project.hasProperty("skipHello") }
}
Output of gradle hello -PskipHello
> gradle hello -PskipHello
> Task :hello SKIPPED
如上所示,hello任务被跳过了
使用 StopExecutionException
如果跳过任务逻辑不能使用onlyIf实现,您可以使用StopExecutionException。如果某个Action抛出此异常,则跳过该Action的进一步执行以及该任务的任何后续Action的执行。构建继续执行下一个任务。
val compile by tasks.registering {
doLast {
println("We are doing the compile.")
}
}
compile {
doFirst {
// Here you would put arbitrary conditions in real life.
if (true) {
throw StopExecutionException()
}
}
}
tasks.register("myTask") {
dependsOn(compile)
doLast {
println("I am not affected")
}
}
禁用与启用Task
每个任务都有一个enabled的标志位,默认为true。将其设置为false可以阻止执行任何Task的执行。禁用的任务将被标记为 SKIPPED。
val disableMe by tasks.registering {
doLast {
println("This should not be printed if the task is disabled.")
}
}
disableMe {
enabled = false
}
Task超时
每个Task都有一个timeout属性,可用于限制其执行时间。当一个任务达到它的超时时间时,它的任务执行线程被中断。该任务将被标记为失败。但是Finalizer Task任务仍将运行。
如果构建时使用了--continue参数,其他任务可以在它之后继续运行。不响应中断的task不能超时。Gradle 的所有内置task都会及时响应超时
Task支持增量编译
任何构建工具的一个重要部分是避免重复工作。在编译过程中,就是在编译源文件后,除非发生了影响输出的更改(例如源文件的修改或输出文件的删除),无需重新编译它们。因为编译可能会花费大量时间,因此在不需要时跳过该步骤可以节省大量时间。
Gradle 支持增量构建,当您运行构建时,有些Task被标记为UP-TO-DATE,这就是增量编译生效了
那么Gradle增量编译如何工作?自定义Task如何支持增量编译?我们一起来看看
Task的输入输出
Task最基本的功能就是接受一些输入,进行一系列运算后生成输出。比如在编译过程中,Java源文件是输入,生成的classes文件是输出。其他输入可能包括诸如是否应包含调试信息之类的内容。
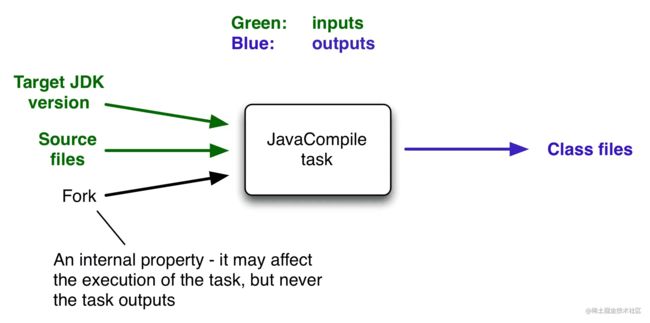
task输入的一个重要特征是它会影响一个或多个输出,从上图中可以看出。根据源文件的内容和target jdk版本,会生成不同的字节码。这使他们成为task输入。
但是编译期的一些其他属性,比如编译最大可用内存,由memoryMaximumSize属性决定,memoryMaximumSize对生成的字节码没有影响。因此,memoryMaximumSize不是task输入,它只是一个内部task属性。
作为增量构建的一部分,Gradle 会检查自上次构建以来是task的输入或输出有没有发生变化。如果没有,Gradle 可以认为task是最新的,因此跳过执行其action。需要注意的是,除非task至少有一个task输出,否则增量构建将不起作用
总得来说:
您需要告诉 Gradle 哪些task属性是输入,哪些是输出。
如果task属性影响输出,请务必将其注册为输入,否则该任务将被认为是最新的而不是最新的。
相反,如果属性不影响输出,则不要将其注册为输入,否则任务可能会在不需要时执行。
还要注意可能为完全相同的输入生成不同输出的非确定性task:不应将这些任务配置为增量构建,因为最新检查将不起作用。
接下来让我们看看如何将task属性注册为输入和输出。
自定义task类型
为了让自定义task支持增量编译,只需要以下两个步骤
- 为每个task输入和输出创建类型化属性(通过 getter 方法)
- 为每个属性添加适当的注解
Gradle 支持四种主要的输入和输出类型:
- 简单值
例如字符串和数字类型。更一般地说,任何一个实现了Serializable的类型。 - 文件系统类型
包括RegularFile,Directory和标准File类,也包括 Gradle 的FileCollection类型的派生类,以及任何可以被Project.file(java.lang.Object)和Project.files(java.lang.Object...)方法接收的参数 - 依赖解析结果
这包括包含Artifact元数据的ResolvedArtifactResult类型和包含依赖图的ResolvedComponentResult类型。请注意,它们仅支持包装在Provider中. - 包装类型
不符合其他几个类型但具有自己的输入或输出属性的自定义类型。task的输入或输出包装在这些自定义类型中。
接下来我们看个例子
假设您有一个task处理不同类型的模板,例如 FreeMarker、Velocity、Moustache 等。它获取模板源文件并将它们与一些模型数据结合以生成不同结果。
此任务将具有三个输入和一个输出:
- 模板源文件
- 模型数据
- 模板引擎
- 输出文件的写入位置
在编写自定义task类时,我们很容易通过注解将属性注册为输入或输出
public abstract class ProcessTemplates extends DefaultTask {
@Input
public abstract Property getTemplateEngine();
@InputFiles
public abstract ConfigurableFileCollection getSourceFiles();
@Nested
public abstract TemplateData getTemplateData();
@OutputDirectory
public abstract DirectoryProperty getOutputDir();
@TaskAction
public void processTemplates() {
// ...
}
}
public abstract class TemplateData {
@Input
public abstract Property getName();
@Input
public abstract MapProperty getVariables();
}
可以看出,我们定义了3个输入,一个输出
- templateEngine,表示使用什么模板引擎,我们传入一个枚举类型,枚举类型都实现了Serializable,因此可作为输入
- sourceFiles,表示源文件,我们传入FileCollection作为输入
- templateData,表示模型数据,自定义类型,在它的内部包装了真正的输入,通过@Nested注解表示
- outputDir,表示输出目录,表示单个目录的属性需要@OutputDirectory注解
当我们重复运行以上task之后,就可以看到以下输出
> gradle processTemplates
> Task :processTemplates UP-TO-DATE
BUILD SUCCESSFUL in 0s
3 actionable tasks: 3 up-to-date
如上所示,task在执行过程中会判断输入输出有没有发生变化,由于task的输入输出都没有发生变化,该task可以直接跳过,展示为up-to-date
除了上述几种注解,还有其他常用注解如@Internal,@Optional,@Classpath等,具体可查看文档:Incremental build property type annotations
声明输入输出的好处
一旦你声明了一个task的正式输入和输出,Gradle 就可以推断出关于这些属性的一些事情。例如,如果一个task的输入设置为另一个task的输出,这意味着第一个task依赖于第二个,gradle可以推断出这一点并添加隐式依赖
推断task依赖关系
想象一个归档task,会将processTemplates task的输出归档。可以看到归档task显然需要processTemplates首先运行,因此可能会添加显式的dependsOn. 但是,如果您像这样定义归档task:
tasks.register("packageFiles") { from(processTemplates.map {it.outputs }) }
Gradle 会自动使packageFiles依赖processTemplates。它可以这样做是因为它知道 packageFiles 的输入之一需要 processTemplates 任务的输出。我们称之为推断的task依赖。
上面的例子也可以写成
tasks.register("packageFiles2") { from(processTemplates) }
这是因为from()方法可以接受task对象作为参数。然后在幕后,from()使用project.files()方法包装参数,进而将task的正式输出转化为文件集合
输入和输出验证
增量构建注解为 Gradle 提供了足够的信息来对带注解的属性执行一些基本验证。它会在task执行之前对每个属性执行以下操作:
- @InputFile- 验证属性是否有值,并且路径是否对应于存在的文件(不是目录)。
- @InputDirectory- 与@InputFile相同,但路径必须对应于目录。
- @OutputDirectory- 验证路径是否是个目录,如果该目录尚不存在,则创建该目录。
如果一个task在某个位置产生输出,而另一个任务task将其作为输入使用,则 Gradle 会检查消费者任务是否依赖于生产者任务。当生产者和消费者任务同时执行时,构建就会失败。
此类验证提高了构建的稳健性,使您能够快速识别与输入和输出相关的问题。
您偶尔会想要禁用某些验证,特别是当输入文件可能实际上不存在时。这就是 Gradle 提供@Optional注释的原因:您使用它来告诉 Gradle 特定输入是可选的,因此如果相应的文件或目录不存在,则构建不应失败。
并行task
定义task输入和输出的另一个好处是:当使用--parallel选项时,Gradle 可以使用此信息来决定如何运行task。
例如,Gradle 将在选择下一个要运行的任务时检查task的输出,并避免并发执行写入同一输出目录的任务。
同样,当另一个task正在运行消耗或创建一些文件时,Gradle 将使用有关task销毁哪些文件的信息(例如,由Destroys注释)来避免运行删除这些文件的task,反之亦然。
它还可以确定创建一组文件的task已经运行,并且使用这些文件的task尚未运行,并且将避免在这中间运行删除这些文件的task。
总得来说,通过以这种方式提供task的输入和输出信息,Gradle 可以推断task之间的创建/消费/销毁关系,并可以确保task执行不会违反这些关系。
增量编译原理解析
上面我们介绍了如何自定义一个支持增量编译的task,那么它的原理是什么呢?
在第一次执行task之前,Gradle 会获取输入的指纹。该指纹包含输入文件的路径和每个文件内容的哈希值。Gradle 然后执行task。如果任务成功完成,Gradle 会获取输出的指纹。该指纹包含一组输出文件和每个文件内容的哈希值。Gradle 会在下次执行task时保留两个指纹。
之后每次执行task之前,Gradle 都会获取输入和输出的新指纹。如果新指纹与之前的指纹相同,Gradle 会假定输出是最新的并跳过该task。如果它们不相同,Gradle 将执行task。Gradle 会在下次执行task时保留两个指纹。
如果文件的统计信息(即lastModified和size)没有改变,Gradle 将重用上次运行的文件指纹。这意味着当文件的统计信息没有更改时,Gradle 不会检测到更改。
Gradle 还将task的代码视为task输入的一部分。当task、其操作或其依赖项在执行之间发生变化时,Gradle 会认为该task已过期。
Gradle 了解文件属性(例如,包含 Java classpath 的属性)是否是顺序敏感的。在比较此类属性的指纹时,即使文件顺序发生变化也会导致task过时。
请注意,如果task指定了输出目录,则自上次执行以来添加到该目录的任何文件都将被忽略,并且不会导致任务过期。这是因为不相关的任务可以共享一个输出目录而不会相互干扰。如果由于某种原因这不是您想要的行为,请考虑使用TaskOutputs.upToDateWhen(groovy.lang.Closure)
一些高端操作
上面介绍的内容涵盖了您将遇到的大多数用例,但有些场景需要特殊处理
将@OutputDirectory链接到@InputFiles
当您想将一个task的输出链接到另一个task的输入时,类型通常匹配,例如,File可以将输出属性分配给File输入。
不幸的是,当您希望将一个task的@OutputDirectory中的文件作为另一个task的@InputFiles属性(类型FileCollection)的源时,这种方法就会失效。
例如,假设您想使用 Java 编译task的输出(通过destinationDir属性)作为自定义task的输入,该task检测一组包含 Java 字节码的文件。这个自定义task,我们称之为Instrument,有一个使用@InputFiles注解的classFiles属性。您最初可能会尝试像这样配置task:
tasks.register("badInstrumentClasses") { classFiles.from(fileTree(tasks.compileJava.map { it.destinationDir })) destinationDir.set(file(layout.buildDirectory.dir("instrumented"))) }
这段代码没有明显的问题,但是您如果实际运行的话可以看到compileJava并没有执行。在这种情况下,您需要通过dependsOn在instrumentClasses和compileJava之间添加显式依赖。因为使用fileTree()意味着 Gradle 无法推断task依赖本身。
一种解决方案是使用TaskOutputs.files属性,如以下示例所示:
tasks.register("instrumentClasses") { classFiles.from(tasks.compileJava.map { it.outputs.files }) destinationDir.set(file(layout.buildDirectory.dir("instrumented"))) }
或者,您可以使用project.files(),project.layout.files(),project.objects.fileCollection()来代替project.fileTree()
tasks.register("instrumentClasses2") { classFiles.from(layout.files(tasks.compileJava)) destinationDir.set(file(layout.buildDirectory.dir("instrumented"))) }
请记住files(),layout.files()和objects.fileCollection()可以将task作为参数,而fileTree()不能。
这种方法的缺点是源task的所有文件输出都成为目标task的输入文件。如果源task只有一个基于文件的输出,就像JavaCompile一样,那很好。但是如果你必须在多个输出属性中选择一个,那么你需要明确告诉 Gradle 哪个task使用以下builtBy方法生成输入文件:
tasks.register("instrumentClassesBuiltBy") { classFiles.from(fileTree(tasks.compileJava.map { it.destinationDir }) { builtBy(tasks.compileJava) }) destinationDir.set(file(layout.buildDirectory.dir("instrumented"))) }
当然你也可以通过dependsOn添加明确的task依赖,但是上面的方法提供了更多的语义,解释了为什么compileJava必须预先运行。
禁用up-to-date检查
Gradle 会自动处理对输出文件和目录的up-to-date检查,但如果task输出完全是另一回事呢?也许它是对 Web 服务或数据库表的更新。或者有时你有一个应该始终运行的task。
这就是doNotTrackState的作用,可以使用它来完全禁用task的up-to-date检查,如下所示:
tasks.register("alwaysInstrumentClasses") { classFiles.from(layout.files(tasks.compileJava)) destinationDir.set(file(layout.buildDirectory.dir("instrumented"))) doNotTrackState("Instrumentation needs to re-run every time") }
如果你的自定义task需要始终运行,那么您也可以在任务类上使用注解@UntrackedTaskTask
提供自定义up-to-date检查
Gradle 会自动处理对输出文件和目录的up-to-date检查,但如果task输出是对 Web 服务或数据库表的更新。在这种情况下,Gradle 无法知道如何检查task是否是up-to-date的。
这是就是TaskOutputs.upToDateWhen方法的作用,使用它我们就可以自定义up-to-date检查的逻辑。例如,您可以从数据库中读取数据库模式的版本号。或者,您可以检查数据库表中的特定记录是否存在或已更改。
请注意,up-to-date检查应该节省您的时间。不要添加比task的标准执行花费更多时间的检查。事实上,如果一个task经常需要运行,因为它很少是up-to-date的,那么它可能根本不值得进行up-to-date检查,如禁用up-to-date中所述。
一个常见的错误是使用upToDateWhen()而不是Task.onlyIf(). 如果您想根据与task输入和输出无关的某些条件跳过任务,那么您应该使用onlyIf(). 例如,如果您想在设置或未设置特定属性时跳过task
Finalizer Task
我们常常使用dependsOn来在一个task之前做一些工作,但如果我们想要在task执行之后做一些操作,该怎么实现呢?
这里我们可以用到finalizedBy方法
val taskX by tasks.registering {
doLast {
println("taskX")
}
}
val taskY by tasks.registering {
doLast {
println("taskY")
}
}
taskX { finalizedBy(taskY) }
如上所示,taskY将在taskX之后执行,需要注意的是finalizedBy并不是依赖关系,就算taskX执行失败,taskY也将正常执行
Finalizer task在构建创建的资源无论构建失败还是成功都必须清理的情况下很有用,一个示例是在集成测试任务中启动的 Web 容器,即使某些测试失败,也应该始终关闭它。这样看来finalizedBy类似java中的finally
要指定Finalizer task,请使用Task.finalizedBy(java.lang.Object...)方法。此方法接受task实例、task名称或Task.dependsOn(java.lang.Object...)接受的任何其他输入
总结
到这里这篇文章已经相当长了,gradle自定义task上手非常简单,但实际上有非常多的细节,尤其是要支持增量编译时。总得来说,为了写出高效的,可缓存的,不拖慢编译速度的task,还是有必要了解一下这些知识的
参考资料
docs.gradle.org/current/use…
以上就是Android开发之Gradle 进阶Tasks深入了解的详细内容,更多关于Android开发Gradle Tasks的资料请关注脚本之家其它相关文章!