C++的缺陷和思考(四)
本文继续来介绍C++的缺陷和笔者的一些思考。先序文章请看
C++的缺陷和思考(三)
C++的缺陷和思考(二)
C++的缺陷和思考(一)
私有继承和多继承
C++是多范式语言
在讲解私有继承和多继承之前,笔者要先澄清一件事:C++不是单纯的面相对象的语言。同样地,它也不是单纯的面向过程的语言,也不是函数式语言,也不是接口型语言……
真的要说,C++是一个多范式语言,也就是说它并不是为了某种编程范式来创建的。C++的语法体系完整且庞大,很多范式都可以用C++来展现。因此,不要试图用任一一种语言范式来解释C++语法,不然你总能找到各种漏洞和奇怪的地方。
举例来说,C++中的“继承”指的是一种语法现象,而面向对象理论中的“继承”指的是一种类之间的关系。这二者是有本质区别的,请读者一定一定要区分清楚。
以面向对象为例,C++当然可以面向对象编程(OOP),但由于C++并不是专为OOP创建的语言,自然就有OOP理论解释不了的语法现象。比如说多继承,比如说私有继承。
C++与java不同,java是完全按照OOP理论来创建的,因此所谓“抽象类”,“接口(协议)类”的语义是明确可以和OOP对应上的,并且,在OOP理论中,“继承”关系应当是"A is a B"的关系,所以不会存在A既是B又是C的这种情况,自然也就不会出现“多继承”这样的语法。
但是在C++中,考虑的是对象的布局,而不是OOP的理论,所以出现私有继承、多继承等这样的语法也就不奇怪了。
笔者曾经听有人持有下面这样类似的观点:
- 虚函数都应该是纯虚的
- 含有虚函数的类不应当支持实例化(创建对象)
- 能实例化的类不应当被继承,有子类的类不应当被实例化
- 一个类至多有一个“属性父类”,但可以有多个“协议父类”
等等这些观点,它们其实都有一个共同的前提,那就是“我要用C++来支持OOP范式”。如果我们用OOP范式来约束C++,那么上面这些观点都是非常正确的,否则将不符合OOP的理论,例如:
class Pet {};
class Cat : public Pet {};
class Dog : public Pet {};
void Demo() {
Pet pet; // 一个不属于猫、狗等具体类型,仅仅属于“宠物”的实例,显然不合理
}
Pet既然作为一个抽象概念存在,自然就不应当有实体。同理,如果一个类含有未完全实现的虚函数,就证明这个类属于某种抽象,它就不应该允许创建实例。而可以创建实例的类,一定就是最“具象”的定义了,它就不应当再被继承。
在OOP的理论下,多继承也是不合理的:
class Cat {};
class Dog {};
class SomeProperty : public Cat, public Dog {}; // 啥玩意会既是猫也是狗?
但如果是“协议父类”的多继承就是合理的:
class Pet { // 协议类
public:
virtual void Feed() = 0; // 定义了喂养方式就可以成为宠物
};
class Animal {};
class Cat : public Animal, public Pet { // 遵守协议,实现其需方法
public:
void Feed() override; // 实现协议方法
};
上面例子中,Cat虽然有2个父类,但Animal才是真正意义上的父类,也就是Cat is a (kind of) Animal的关系,而Pet是协议父类,也就是Cat could be a Pet,只要一个类型可以完成某些行为,那么它就可以“作为”这样一种类型。
在java中,这两种类型是被严格区分开的:
interface Pet { // 接口类
public void Feed();
}
abstract class Animal {} // 抽象类,不可创建实例
class Cat extends Animal implements Pet {
public void Feed() {}
}
子类与父类的关系叫“继承”,与协议(或者叫接口)的关系叫“实现”。
与C++同源的Objective-C同样是C的超集,但从名称上就可看出,这是“面向对象的C”,语法自然也是针对OOP理论的,所以OC仍然只支持单继承链,但可以定义协议类(类似于java中的接口类),“继承”和“遵守(类似于java中的实现语义)”仍然是两个分离的概念:
@protocol Pet <NSObject> // 定义协议
- (void)Feed;
@end
@interface Animal : NSObject
@end
@interface Cat : Animal<Pet> // 继承自Animal类,遵守Pet协议
- (void)Feed;
@end
@implementation Cat
- (void)Feed {
// 实现协议接口
}
@end
相比,C++只能说“可以”用做OOP编程,但OOP并不是其唯一范式,也就不会针对于OOP理论来限制其语法。这一点,希望读者一定要明白。
私有继承与EBO
笔者曾经写过一篇专文来解释C++的私有继承和EBO,读者可以阅读《C++的私有继承和EBO》,简单来说,“私有继承”其实对应了OOP理论中的“组合关系”,只是为了压缩空间,采用的私有继承。
谷歌规范中规定了继承必须是public的,这主要还是在贴近OOP理论。另一方面就是说,虽然使用私有继承是为了压缩空间,但一定程度上也是牺牲了代码的可读性,让我们不太容易看得出两种类型之间的关系,因此在绝大多数情况下,还是应当使用public继承。不过笔者仍然持有“万事皆不可一棒子打死”的观点,如果我们确实需要EBO的特性否则会大幅度牺牲性能的话,那么还是应当允许使用私有继承。
多继承
与私有继承类似,C++的多继承同样是“语法上”的继承,而实际意义上可能并不是OOP中的“继承”关系。再以前面章节的Pet为例:
class Pet {
public:
virtual void Feed() = 0;
};
class Animal {};
class Cat : public Animal, public Pet {
public:
void Feed() override;
};
从形式上来说,Cat同时继承自Anmial和Pet,但从OOP理论上来说,Cat和Animal是继承关系,而和Pet是实现关系,前面章节已经介绍得很详细了,这里不再赘述。
但由于C++并不是完全针对OOP的,因此支持真正意义上的多继承,也就是说,即便父类不是这种纯虚类,也同样支持集成,从语义上来说,类似于“交叉分类”。请看示例:
class Organic { // 有机物
};
class Inorganic { // 无机物
};
class Acid { // 酸
};
class Salt { // 盐
};
class AceticAcid : public Organic, public Acid { // 乙酸
};
class HydrochloricAcid : public Inorganic, public Acid { // 盐酸
};
class SodiumCarbonate : public Inorganic, public Salt { // 碳酸钠
};
上面就是一个交叉分类法的例子,使用多继承语法合情合理。如果换做其他OOP语言,可能会强行把“酸”或者“有机物”定义为协议类,然后用继承+实现的方式来完成。但如果从化学分类上来看,无论是“酸碱盐”还是“有机物无机物”,都是一种强分类,比如说“碳酸钠”,它就是一种“无机物”,也是一种“盐”,你并不能用类似于“猫是一种动物,可以作为宠物”的理论来解释,不能说“碳酸钠是一种盐,可以作为一种无机物”。
因此C++中的多继承是哪种具体意义,取决于父类本身是什么。如果父类是个协议类,那这里就是“实现”语义,而如果父类本身就是个实际类,那这里就是“继承”语义。当然了,像私有继承的话表示是“组合”语义。不过C++本身并不在意这种语义,有时为了方便,我们也可能用公有继承来表示组合语义,比如说:
class Point {
public:
double x, y;
};
class Circle : public Point {
public:
double r; // 半径
};
这里Circle继承了Point,但显然不是说“圆是一个点”,这里想表达的就是圆类“包含了”点类的成员,所以只是为了复用。从意义上来说,Circle类中继承来的x和y显然表达的是圆心的坐标。不过这样写并不符合设计规范,但笔者用这个例子希望解释的是C++并不在意类之间实际是什么关系,它在意的是数据复用,因此我们更需要了解一下多继承体系中的内存布局。
对于一个普通的类来说,内存布局就是按照成员的声明顺序来布局的,与C语言中结构体布局相同,例如:
class Test1 {
public:
char a;
int b;
short c;
};
那么Test1的内存布局就是
| 字节编号 | 内容 |
|---|---|
| 0 | a |
| 1~3 | 内存对齐保留字节 |
| 4~7 | b |
| 8~9 | c |
| 9~11 | 内存对齐保留字节 |
但如果类中含有虚函数,那么还会在末尾添加虚函数表的指针,例如:
class Test1 {
public:
char a;
int b;
short c;
virtual void f() {}
};
| 字节编号 | 内容 |
|---|---|
| 0 | a |
| 1~3 | 内存对齐保留字节 |
| 4~7 | b |
| 8~9 | c |
| 9~15 | 内存对齐保留字节 |
| 16~23 | 虚函数表指针 |
多继承时,第一父类的虚函数表会与本类合并,其他父类的虚函数表单独存在,并排列在本类成员的后面。
关于带有虚函数表类以及多继承时的内存布局详情,读者可以参考笔者的另一篇文章《深入C++成员函数及虚函数表》,里面有详细的介绍,在这里就不再赘述。
菱形继承与虚拟继承
C++由于支持“普适意义上的多继承”,那么就会有一种特殊情况——菱形继承,请看例程:
struct A {
int a1, a2;
};
struct B : A {
int b1, b2;
};
struct C : A {
int c1, c2;
};
struct D : B, C {
int d1, d2;
};
根据内存布局原则,D类首先是B类的元素,然后D类自己的元素,最后是C类元素:
| 字节序号 | 意义 |
|---|---|
| 0~15 | B类元素 |
| 16~19 | d1 |
| 20~23 | d2 |
| 24~31 | C类元素 |
如果再展开,会变成这样:
| 字节序号 | 意义 |
|---|---|
| 0~3 | a1(B类继承自A类的) |
| 4~7 | a2(B类继承自A类的) |
| 8~11 | b1 |
| 12~15 | b2 |
| 16~19 | d1 |
| 20~23 | d2 |
| 24~27 | a1(C类继承自A类的) |
| 28~31 | a1(C类继承自A类的) |
| 32~35 | c1 |
| 36~39 | c2 |
可以发现,A类的成员出现了2份,这就是所谓“菱形继承”产生的副作用。这也是C++的内存布局当中的一种缺陷,多继承时第一个父类作为主父类合并,而其余父类则是直接向后扩写,这个过程中没有去重的逻辑(详情参考上一节)。这样的话不仅浪费空间,还会出现二义性问题,例如d.a1到底是指从B继承来的a1还是从C里继承来的呢?
C++引入虚拟继承的概念就是为了解决这一问题。但怎么说呢,C++的复杂性往往都是因为为了解决一种缺陷而引入了另一种缺陷,虚拟继承就是非常典型的例子,如果你直接去解释虚拟继承(比如说和普通继承的区别)你一定会觉得莫名其妙,为什么要引入一种这样奇怪的继承方式。所以这里需要我们了解到,它是为了解决菱形继承时空间爆炸的问题而不得不引入的。
首先我们来看一下普通的继承和虚拟继承的区别:
普通继承:
struct A {
int a1, a2;
};
struct B : A {
int b1, b2;
};
B的对象模型应该是这样的:
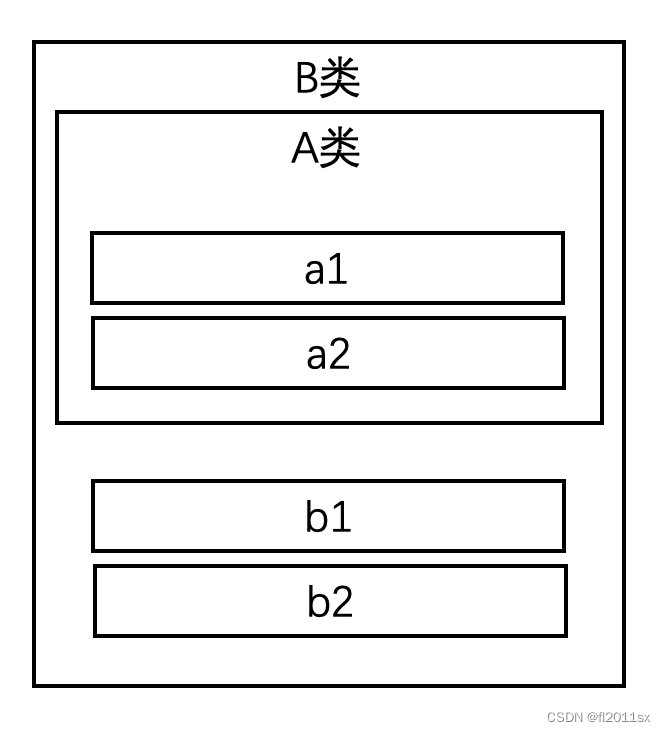
而如果使用虚拟继承:
struct A {
int a1, a2;
};
struct B : virtual A {
int b1, b2;
};
对象模型是这样的:
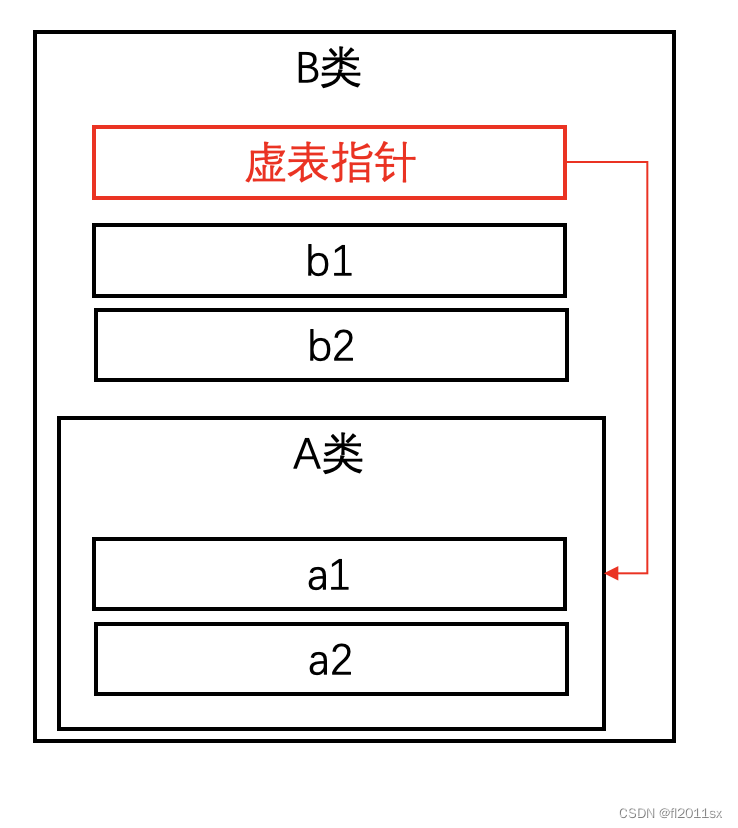
虚拟继承的排布方式就类似于虚函数的排布,子类对象会自动生成一个虚基表来指向虚基类成员的首地址。
就像刚才说的那样,单纯的虚拟继承看上去很离谱,因为完全没有必要强行更换这样的内存布局,所以绝大多数情况下我们是不会用虚拟继承的。但是菱形继承的情况,就不一样了,普通的菱形继承会这样:
struct A {
int a1, a2;
};
struct B : A {
int b1, b2;
};
struct C : A {
int c1, c2;
};
struct D : B, C {
int d1, d2;
};
D的对象模型:

但如果使用虚拟继承,则可以把每个类单独的东西抽出来,重复的内容则用指针来指向:
struct A {
int a1, a2;
};
struct B : virtual A {
int b1, b2;
};
struct C : virtual A {
int c1, c2;
};
struct D : B, C {
int d1, d2;
};
D的对象模型将会变成:
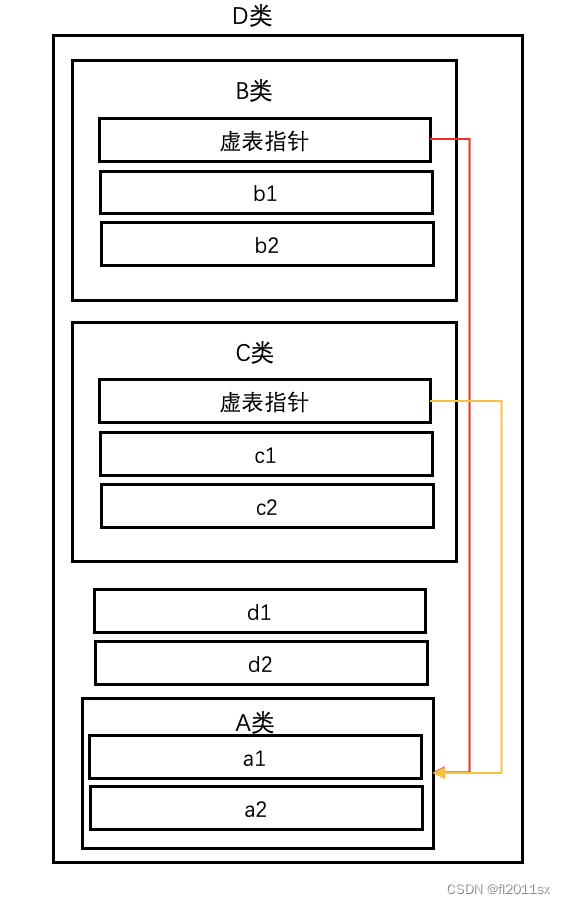
也就是说此时,共有的虚基类只会保存一份,这样就不会有二义性,同时也节省了空间。
但需要注意的是,D继承自B和C时是普通继承,如果用了虚拟继承,则会在D内部又额外添加一份虚基表指针。要虚拟继承的是B和C对A的继承,这也是虚拟继承语法非常迷惑的地方,也就是说,菱形继承的分支处要用虚拟继承,而汇聚处要用普通继承。所以我们还是要明白其底层原理,以及引入这个语法的原因(针对解决的问题),才能更好的使用这个语法,避免出错。
隐式构造
隐式构造指的就是隐式调用构造函数。换句话说,我们不用写出类型名,而是仅仅给出构造参数,编译期就会自动用它来构造对象。举例来说:
class Test {
public:
Test(int a, int b) {}
};
void f(const Test &t) {
}
void Demo() {
f({1, 2}); // 隐式构造Test临时对象,相当于f(Test{a, b})
}
上面例子中,f需要接受的是Test类型的对象,然而我们在调用时仅仅使用了构造参数,并没有指定类型,但编译器会进行隐式构造。
尤其,当构造参数只有1个的时候,可以省略大括号:
class Test {
public:
Test(int a) {}
Test(int a, int b) {}
};
void f(const Test &t) {
}
void Demo() {
f(1); // 隐式构造Test{1},单参时可以省略大括号
f({2}); // 隐式构造Test{2}
f({1, 2}); // 隐式构造Test{1, 2}
}
这样做的好处显而易见,就是可以让代码简化,尤其是在构造string或者vector的时候更加明显:
void f1(const std::string &str) {}
void f2(const std::vector<int> &ve) {}
void Demo() {
f1("123"); // 隐式构造std::string{"123"},注意字符串常量是const char *类型
f2({1, 2, 3}); // 隐式构造std::vector,注意这里是initialize_list构造
}
当然,如果遇到函数重载,原类型的优先级大于隐式构造,例如:
class Test {
public:
Test(int a) {}
};
void f(const Test &t) {
std::cout << 1 << std::endl;
}
void f(int a) {
std::cout << 2 << std::endl;
}
void Demo() {
f(5); // 会输出2
}
但如果有多种类型的隐式构造则会报二义性错误:
class Test1 {
public:
Test1(int a) {}
};
class Test2 {
public:
Test2(int a) {}
};
void f(const Test1 &t) {
std::cout << 1 << std::endl;
}
void f(const Test2 &t) {
std::cout << 2 << std::endl;
}
void Demo() {
f(5); // ERR,二义性错误
}
在返回值场景也支持隐式构造,例如:
struct err_t {
int err_code;
const char *err_msg;
};
err_t f() {
return {0, "success"}; // 隐式构造err_t
}
但隐式构造有时会让代码含义模糊,导致意义不清晰的问题(尤其是单参的构造函数),例如:
class System {
public:
System(int version);
};
void Operate(const System &sys, int cmd) {}
void Demo() {
Operate(1, 2); // 意义不明确,不容易让人意识到隐式构造
}
上例中,System表示一个系统,其构造参数是这个系统的版本号。那么这时用版本号的隐式构造就显得很突兀,而且只通过Operate(1, 2)这种调用很难让人想到第一个参数竟然是System类型的。
因此,是否应当隐式构造,取决于隐式构造的场景,例如我们用const char *来构造std::string就很自然,用一组数据来构造一个std::vector也很自然,或者说,代码的阅读者非常直观地能反应出来这里发生了隐式构造,那么这里就适合隐式构造,否则,这里就应当限定必须显式构造。用explicit关键字限定的构造函数不支持隐式构造:
class Test {
public:
explicit Test(int a);
explicit Test(int a, int b);
Test(int *p);
};
void f(const Test &t) {}
void Demo() {
f(1); // ERR,f不存在int参数重载,Test的隐式构造不允许用(因为有explicit限定),所以匹配失败
f(Test{1}); // OK,显式构造
f({1, 2}); // ERR,同理,f不存在int, int参数重载,Test隐式构造不许用(因为有explicit限定),匹配失败
f(Test{1, 2}); // OK,显式构造
int a;
f(&a); // OK,隐式构造,调用Test(int *)构造函数
}
还有一种情况就是,对于变参的构造函数来说,更要优先考虑要不要加explicit,因为变参包括了单参,并且默认情况下所有类型的构造(模板的所有实例,任意类型、任意个数)都会支持隐式构造,例如:
class Test {
public:
template <typename... Args>
Test(Args&&... args);
};
void f(const Test &t) {}
void Demo() {
f(1); // 隐式构造Test{1}
f({1, 2}); // 隐式构造Test{1, 2}
f("abc"); // 隐式构造Test{"abc"}
f({0, "abc"}); // 隐式构造Test{0, "abc"}
}
所以避免爆炸(生成很多不可控的隐式构造),对于变参构造最好还是加上explicit,如果不加的话一定要慎重考虑其可能实例化的每一种情况。
在谷歌规范中,单参数构造函数必须用explicit限定,但笔者认为这个规范并不完全合理,在隐式构造意义非常明确的时候,还是应当允许使用隐式构造。另外,即便是多参数的构造函数,如果当隐式构造意义不明确时,同样也应当用explicit来限定。所以还是要视情况而定。
C++支持隐式构造,自然考虑的是一些场景下代码更简洁,但归根结底在于C++主要靠STL来扩展功能,而不是语法。举例来说,在Swift中,原生语法支持数组、map、字符串等:
let arr = [1, 2, 3] // 数组
let map = [1 : "abc", 25 : "hhh", -1 : "fail"] // map
let str = "123abc" // 字符串
因此,它并不需要所谓隐式构造的场景,因为语法本身已经表明了它的类型。
而C++不同,C++并没有原生支持std::vector、std::map、std::string等的语法,这就会让我们在使用这些基础工具的时候很头疼,因此引入隐式构造来简化语法。所以归根结底,C++语言本身考虑的是语法层面的功能,而数据逻辑层面靠STL来解决,二者并不耦合。但又希望程序员能够更加方便地使用STL,因此引入了一些语言层面的功能,但它却像全体类型开放了。
举例来说,Swift中,[1, 2, 3]的语法强绑定Array类型,[k1:v1, k2,v2]的语法强绑定Map类型,因此这里的“语言”和“工具”是耦合的。但C++并不和STL耦合,他的思路是{x, y, z}就是构造参数,哪种类型都可以用,你交给vector时就是表示数组,你交给map时就是表示kv对,并不会将“语法”和“类型”做任何强绑定。因此把隐式构造和explicit都提供出来,交给开发者自行处理是否支持。
这是我们需要体会的C++设计理念,当然,也可以算是C++的缺陷。
C风格字符串
字符串同样是C++特别容易踩坑的位置。出于对C语言兼容、以及上一节所介绍的C++希望将“语言”和“类型”解耦的设计理念的目的,在C++中,字符串并没有映射为std::string类型,而是保留C语言当中的处理方式。编译期会将字符串常量存储在一个全局区,然后再使用字符串常量的位置用一个指针代替。所以基本可以等价认为,字符串常量(字面量)是const char *类型。
但是,更多的场景下,我们都会使用std::string类型来保存和处理字符串,因为它功能更强大,使用更方便。得益于隐式构造,我们可以把一个字符串常量轻松转化为std::string类型来处理。
但本质上来说,std::string和const char *是两种类型,所以一些场景下它还是会出问题。
类型推导问题
在进行类型推导时,字符串常量会按const char *来处理,有时会导致问题,比如:
template <typename T>
void f(T t) {
std::cout << 1 << std::endl;
}
template <typename T>
void f(T *t) {
std::cout << 2 << std::endl;
}
void Demo() {
f("123");
f(std::string{"123"});
}
代码的原意是将“值类型”和“指针类型”分开处理,至于字符串,照理说应当是一个“对象”,所以要按照值类型来处理。但如果我们用的是字符串常量,则会识别为const char *类型,直接匹配到了指针处理方式,而并不会触发隐式构造。
截断问题
C风格字符串有一个约定,就是以0结尾。它并不会去单独存储数据长度,而是很暴力地从首地址向后查找,找到0为止。但std::string不同,其内部有统计个数的成员,因此不会受0值得影响:
std::string str1{"123\0abc"}; // 0处会截断
std::string str2{"123\0abc", 7}; // 不会截断
截断问题在传参时更加明显,比如说:
void f(const char *str) {}
void Demo() {
std::string str2{"123\0abc", 7};
// 由于f只支持C风格字符串,因此转化后传入
f(str2.c_str()); // 但其实已经被截断了
}
前面的章节曾经提到过,C++没有引入额外的格式符,因此把std::string传入格式化函数的时候,也容易发生截断问题:
std::string MakeDesc(const std::string &head, double data) {
// 拼凑一个xxx:ff%的形式
char buf[128];
std::sprintf(buf, "%s:%lf%%", head.c_str(), data); // 这里有可能截断
return buf; // 这里也有可能截断
}
总之,C风格的字符串永远难逃0值截断问题,而又因为C++中仍然保留了C风格字符串的所有行为,并没有在语言层面直接关联std::string,因此在使用时一定要小心截断问题。
指针意义不明问题
由于C++保留了C风格字符串的行为,因此在很多场景下,把const char *就默认为了字符串,都会按照字符串去解析。但有时可能会遇到一个真正的指针,那么此时就会有问题,比如说:
void Demo() {
int a;
char b;
std::cout << &a << std::endl; // 流接受指针,打印指针的值
std::cout << &b << std::endl; // 流接收char *,按字符串处理
}
STL中所有流接收到char *或const char *时,并不会按指针来解析,而是按照字符串解析。在上面例子中,&b本身应当就是个单纯指针,但是输出流却将其按照字符串处理了,也就是会持续向后搜索找到0值为止,那这里显然是发生越界了。
因此,如果我们给char、signed char、unsigned char类型取地址时,一定要考虑会不会被识别为字符串。
int8_t和uint8_t
原本int8_t和uint8_t是用来表示“8位整数”的,但是不巧的是,他们的定义是:
using int8_t = signed char;
using uint8_t = unsigned char;
笔者曾经介绍过,由于C语言历史原因,ASCII码只有7位,所以“字符”类型有无符号是没区别的,而当时没有定制规范,因此不同编译器可能有不同处理。到后来干脆把char当做独立类型了。所以char和signed char以及unsigned char是不同类型。这与其他类型不同,例如int和signed int是同一类型。
但是类似于流的处理中,却没有把signed char和unsigned char单独拿出来处理,都是按照字符来处理了(这里笔者也不知道什么原因)。而int8_t和uint8_t又是基于此定义的,所以也会出现奇怪问题,比如:
uint8_t n = 56; // 这里是单纯想放一个整数
std::cout << n << std::endl; // 但这里会打印出8,而不是56
原本uint8_t是想屏蔽掉char这层含义,让它单纯地表示8位整数的,但是在STL的解析中,却又让它有了“字符”的含义,去按照ASCII码来解析了,让uint8_t的定义又失去了原本该有的含义,所以这里也是很容易踩坑的地方。
(这一点笔者真的没想明白为什么,明明是不同类型,但为什么没有区分开。可能同样是历史原因吧,总之这个点可以算得上真正意义上的“缺陷”了。)
第五篇已脱稿,请看C++的缺陷和思考(五)