CS224N Assignment3 #3: Dependency Parsing(2022 winter)
课程网站:https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1214/
1. Machine Learning & Neural Networks (8 points)
(a)
i.
使用 m m m更新时,每次 β 1 \beta_1 β1部分的 m m m都和上一个 m m m保持一致,只有 1 − β 1 1-\beta_1 1−β1的部分和当前批次有关,所以能够防止每次更新差距过大。
因为能够防止每次更新的方差过大,所以总体上不会出现特别错误的更新方向,有利于学习到总体上正确的方向,减少受到每个小批次数据分布随机性的影响。
ii.
当 β 2 \beta_2 β2较小的时候能够获取到较大的更新,引入 β 2 \beta_2 β2同样有助于在非平稳问题上表现良好,减少噪声的影响,有助于提高在稀疏梯度上的效果。
(有一说一这里写的语焉不详,因为我也没有去看Adam论文原文hhhh)
Adam原文链接:https://arxiv.org/pdf/1412.6980.pdf
(b)
i.
由 γ ∗ p d r o p + 0 ∗ ( 1 − p d r o p ) = 1 \gamma*p_{drop}+0*(1-p_{drop})=1 γ∗pdrop+0∗(1−pdrop)=1
有 γ = 1 / p d r o p \gamma=1/p_{drop} γ=1/pdrop
ii.
因为在训练过程中使用dropout能够减少隐藏层结点的依赖,防止过拟合。
而在测试过程中使用dropout相当于破坏了神经网络本身的结构,一般会导致结果有明显的下降。
dropout原文链接:https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
2. Neural Transition-Based Dependency Parsing (44 points)
环境配置:按照readme文件提示即可,win10下足以完成实验,不需要GPU,一刻钟的时间足够跑完所有代码了。
(a)
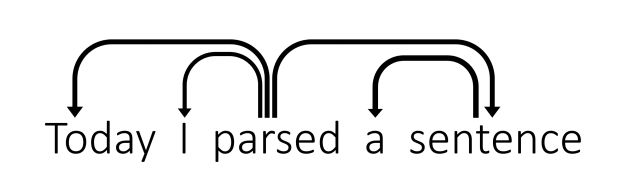
| Stack | Buffer | New Dependency | Trainsitions |
|---|---|---|---|
| [[ROOT],Today,parsed] | [a,sentence] | parsed → \rightarrow →I | LA |
| [[ROOT],Today,parsed,a] | [sentence] | S | |
| [[ROOT],Today,parsed,a,sentence] | [] | S | |
| [[ROOT],Today,parsed,sentence] | [] | sentence → \rightarrow →a | LA |
| [[ROOT],Today,parsed] | [] | parsed → \rightarrow →sentence | RA |
| [[ROOT],parsed] | [] | parsed → \rightarrow →Today | LA |
| [[ROOT]] | [] | [ROOT] → \rightarrow →parsed |
(b)
一个包含n个词的句子需要进行2n步的依存分析,每个词都需要SHIFT操作从Buffer移动到Stack中,并且都需要建立连接被指向(其中一个指向来自于[ROOT]),所以一共需要2n步解析。
©
__init__函数
def __init__(self, sentence):
"""Initializes this partial parse.
@param sentence (list of str): The sentence to be parsed as a list of words.
Your code should not modify the sentence.
"""
# The sentence being parsed is kept for bookkeeping purposes. Do NOT alter it in your code.
self.sentence = sentence
### YOUR CODE HERE (3 Lines)
### Your code should initialize the following fields:
### self.stack: The current stack represented as a list with the top of the stack as the
### last element of the list.
### self.buffer: The current buffer represented as a list with the first item on the
### buffer as the first item of the list
### self.dependencies: The list of dependencies produced so far. Represented as a list of
### tuples where each tuple is of the form (head, dependent).
### Order for this list doesn't matter.
###
### Note: The root token should be represented with the string "ROOT"
### Note: If you need to use the sentence object to initialize anything, make sure to not directly
### reference the sentence object. That is, remember to NOT modify the sentence object.
self.stack = ["ROOT"]
self.buffer = [word for word in sentence]
self.dependencies = []
### END YOUR CODE
按照要求初始化就ok
parse_step函数
def parse_step(self, transition):
"""Performs a single parse step by applying the given transition to this partial parse
@param transition (str): A string that equals "S", "LA", or "RA" representing the shift,
left-arc, and right-arc transitions. You can assume the provided
transition is a legal transition.
"""
### YOUR CODE HERE (~7-12 Lines)
### TODO:
### Implement a single parsing step, i.e. the logic for the following as
### described in the pdf handout:
### 1. Shift
### 2. Left Arc
### 3. Right Arc
if transition == "S":
self.stack.append(self.buffer[0])
self.buffer.pop(0)
elif transition == "LA":
dependent = self.stack.pop(-2)
head = self.stack[-1]
self.dependencies.append((head, dependent))
else:
dependent = self.stack.pop(-1)
head = self.stack[-1]
self.dependencies.append((head, dependent))
### END YOUR CODE
根据三种转移操作的要求对stack和buffer区域进行对应操作,并且注意将依存关系添加到dependencies中。
完成以上修改后可以通过执行python parser_transitions.py part_c 来测试是否成功。
通过完成上述代码以及结合下面的parse()函数,应该能够基本上理解模型是如何执行基于转换的依存解析的。当然这里我们是直接使用了转化操作,但是实际中我们需要基于当前状态预测出相应的转换操作。
(d)
这一部分需要完成小批量(minibatch)数据的加载和处理。
数据类型是前面定义的PartialParse对象(包含了stack、buffer、transitions和dependencies四个部分),需要每次并行处理头mini_batch个对象一步,如果已经完成处理(buffer为空且stack长度为1)就处理接下来的。由于不同句子长度不同处理步数不同,所以每次需要及时更新待处理的对象。
def minibatch_parse(sentences, model, batch_size):
"""Parses a list of sentences in minibatches using a model.
@param sentences (list of list of str): A list of sentences to be parsed
(each sentence is a list of words and each word is of type string)
@param model (ParserModel): The model that makes parsing decisions. It is assumed to have a function
model.predict(partial_parses) that takes in a list of PartialParses as input and
returns a list of transitions predicted for each parse. That is, after calling
transitions = model.predict(partial_parses)
transitions[i] will be the next transition to apply to partial_parses[i].
@param batch_size (int): The number of PartialParses to include in each minibatch
@return dependencies (list of dependency lists): A list where each element is the dependencies
list for a parsed sentence. Ordering should be the
same as in sentences (i.e., dependencies[i] should
contain the parse for sentences[i]).
"""
dependencies = []
### YOUR CODE HERE (~8-10 Lines)
### TODO:
### Implement the minibatch parse algorithm. Note that the pseudocode for this algorithm is given in the pdf handout.
###
### Note: A shallow copy (as denoted in the PDF) can be made with the "=" sign in python, e.g.
### unfinished_parses = partial_parses[:].
### Here `unfinished_parses` is a shallow copy of `partial_parses`.
### In Python, a shallow copied list like `unfinished_parses` does not contain new instances
### of the object stored in `partial_parses`. Rather both lists refer to the same objects.
### In our case, `partial_parses` contains a list of partial parses. `unfinished_parses`
### contains references to the same objects. Thus, you should NOT use the `del` operator
### to remove objects from the `unfinished_parses` list. This will free the underlying memory that
### is being accessed by `partial_parses` and may cause your code to crash.
partial_parses = [PartialParse(sentence) for sentence in sentences]
unfinished_parses = partial_parses[:]
while len(unfinished_parses) > 0:
if len(unfinished_parses) >= batch_size:
mini_batch = unfinished_parses[:batch_size]
else:
mini_batch = unfinished_parses
transitions = model.predict(mini_batch)
pop_list = []
for i in range(len(mini_batch)):
unfinished_parses[i].parse_step(transitions[i])
if len(unfinished_parses[i].buffer) == 0 and len(unfinished_parses[i].stack) == 1:
pop_list.append(i)
for i in range(len(pop_list)):
unfinished_parses.pop(pop_list[i] - i)
dependencies = [partial_parses[i].dependencies for i in range(len(partial_parses))]
### END YOUR CODE
return dependencies
完成后可以使用python parser_transitions.py part_d 来测试代码编写是否正确。
(e)
下面这部分是需要参考论文《A Fast and Accurate Dependency
Parser using Neural Networks》,完成其中的模型。
这篇早期(2014年)的文章模型如下图所示是比较简单的
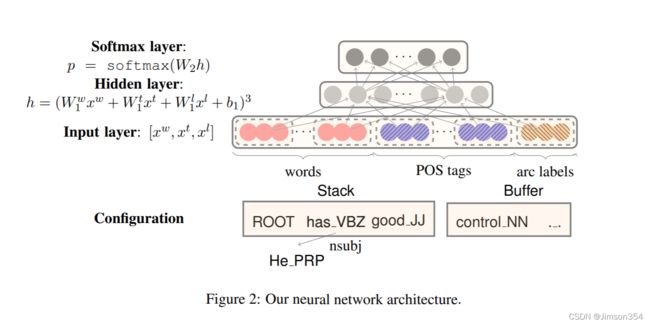
做改动的几个函数都不难,对pytorch不熟悉的话参考一下里面给出的文档链接,写两行测试代码基本就会怎么用了,这里给出一种参考写法
parser_model.py中的
def __init__(self, embeddings, n_features=36,
hidden_size=200, n_classes=3, dropout_prob=0.5):
""" Initialize the parser model.
@param embeddings (ndarray): word embeddings (num_words, embedding_size)
@param n_features (int): number of input features
@param hidden_size (int): number of hidden units
@param n_classes (int): number of output classes
@param dropout_prob (float): dropout probability
"""
super(ParserModel, self).__init__()
self.n_features = n_features
self.n_classes = n_classes
self.dropout_prob = dropout_prob
self.embed_size = embeddings.shape[1]
self.hidden_size = hidden_size
self.embeddings = nn.Parameter(torch.tensor(embeddings))
### YOUR CODE HERE (~9-10 Lines)
### TODO:
### 1) Declare `self.embed_to_hidden_weight` and `self.embed_to_hidden_bias` as `nn.Parameter`.
### Initialize weight with the `nn.init.xavier_uniform_` function and bias with `nn.init.uniform_`
### with default parameters.
### 2) Construct `self.dropout` layer.
### 3) Declare `self.hidden_to_logits_weight` and `self.hidden_to_logits_bias` as `nn.Parameter`.
### Initialize weight with the `nn.init.xavier_uniform_` function and bias with `nn.init.uniform_`
### with default parameters.
###
### Note: Trainable variables are declared as `nn.Parameter` which is a commonly used API
### to include a tensor into a computational graph to support updating w.r.t its gradient.
### Here, we use Xavier Uniform Initialization for our Weight initialization.
### It has been shown empirically, that this provides better initial weights
### for training networks than random uniform initialization.
### For more details checkout this great blogpost:
### http://andyljones.tumblr.com/post/110998971763/an-explanation-of-xavier-initialization
###
### Please see the following docs for support:
### nn.Parameter: https://pytorch.org/docs/stable/nn.html#parameters
### Initialization: https://pytorch.org/docs/stable/nn.init.html
### Dropout: https://pytorch.org/docs/stable/nn.html#dropout-layers
###
### See the PDF for hints.
self.embed_to_hidden_weight = nn.Parameter(nn.init.xavier_uniform_(torch.empty(self.embed_size* self.n_features, self.hidden_size)))
self.embed_to_hidden_bias = nn.Parameter(nn.init.uniform_(torch.empty(self.hidden_size)))
self.hidden_to_logits_weight = nn.Parameter(nn.init.xavier_uniform_(torch.empty(self.hidden_size, self.n_classes)))
self.hidden_to_logits_bias = nn.Parameter(nn.init.uniform_(torch.empty(self.n_classes)))
self.dropout_prob = nn.Dropout(self.dropout_prob)
### END YOUR CODE
def embedding_lookup(self, w):
""" Utilize `w` to select embeddings from embedding matrix `self.embeddings`
@param w (Tensor): input tensor of word indices (batch_size, n_features)
@return x (Tensor): tensor of embeddings for words represented in w
(batch_size, n_features * embed_size)
"""
### YOUR CODE HERE (~1-4 Lines)
### TODO:
### 1) For each index `i` in `w`, select `i`th vector from self.embeddings
### 2) Reshape the tensor using `view` function if necessary
###
### Note: All embedding vectors are stacked and stored as a matrix. The model receives
### a list of indices representing a sequence of words, then it calls this lookup
### function to map indices to sequence of embeddings.
###
### This problem aims to test your understanding of embedding lookup,
### so DO NOT use any high level API like nn.Embedding
### (we are asking you to implement that!). Pay attention to tensor shapes
### and reshape if necessary. Make sure you know each tensor's shape before you run the code!
###
### Pytorch has some useful APIs for you, and you can use either one
### in this problem (except nn.Embedding). These docs might be helpful:
### Index select: https://pytorch.org/docs/stable/torch.html#torch.index_select
### Gather: https://pytorch.org/docs/stable/torch.html#torch.gather
### View: https://pytorch.org/docs/stable/tensors.html#torch.Tensor.view
### Flatten: https://pytorch.org/docs/stable/generated/torch.flatten.html
x = torch.index_select(self.embeddings, 0, torch.flatten(w))
x = x.view(w.shape[0], -1)
### END YOUR CODE
return x
def forward(self, w):
""" Run the model forward.
Note that we will not apply the softmax function here because it is included in the loss function nn.CrossEntropyLoss
PyTorch Notes:
- Every nn.Module object (PyTorch model) has a `forward` function.
- When you apply your nn.Module to an input tensor `w` this function is applied to the tensor.
For example, if you created an instance of your ParserModel and applied it to some `w` as follows,
the `forward` function would called on `w` and the result would be stored in the `output` variable:
model = ParserModel()
output = model(w) # this calls the forward function
- For more details checkout: https://pytorch.org/docs/stable/nn.html#torch.nn.Module.forward
@param w (Tensor): input tensor of tokens (batch_size, n_features)
@return logits (Tensor): tensor of predictions (output after applying the layers of the network)
without applying softmax (batch_size, n_classes)
"""
### YOUR CODE HERE (~3-5 lines)
### TODO:
### Complete the forward computation as described in write-up. In addition, include a dropout layer
### as decleared in `__init__` after ReLU function.
###
### Note: We do not apply the softmax to the logits here, because
### the loss function (torch.nn.CrossEntropyLoss) applies it more efficiently.
###
### Please see the following docs for support:
### Matrix product: https://pytorch.org/docs/stable/torch.html#torch.matmul
### ReLU: https://pytorch.org/docs/stable/nn.html?highlight=relu#torch.nn.functional.relu
x = self.embedding_lookup(w)
relu = nn.ReLU()
h = relu(torch.matmul(x, self.embed_to_hidden_weight) + self.embed_to_hidden_bias)
logits = torch.matmul(h, self.hidden_to_logits_weight) + self.hidden_to_logits_bias
### END YOUR CODE
return logits
run.py中的
def train(parser, train_data, dev_data, output_path, batch_size=1024, n_epochs=10, lr=0.0005):
""" Train the neural dependency parser.
@param parser (Parser): Neural Dependency Parser
@param train_data ():
@param dev_data ():
@param output_path (str): Path to which model weights and results are written.
@param batch_size (int): Number of examples in a single batch
@param n_epochs (int): Number of training epochs
@param lr (float): Learning rate
"""
best_dev_UAS = 0
### YOUR CODE HERE (~2-7 lines)
### TODO:
### 1) Construct Adam Optimizer in variable `optimizer`
### 2) Construct the Cross Entropy Loss Function in variable `loss_func` with `mean`
### reduction (default)
###
### Hint: Use `parser.model.parameters()` to pass optimizer
### necessary parameters to tune.
### Please see the following docs for support:
### Adam Optimizer: https://pytorch.org/docs/stable/optim.html
### Cross Entropy Loss: https://pytorch.org/docs/stable/nn.html#crossentropyloss
optimizer = optim.Adam(parser.model.parameters(), lr=lr)
loss_func = nn.CrossEntropyLoss()
### END YOUR CODE
for epoch in range(n_epochs):
print("Epoch {:} out of {:}".format(epoch + 1, n_epochs))
dev_UAS = train_for_epoch(parser, train_data, dev_data, optimizer, loss_func, batch_size)
if dev_UAS > best_dev_UAS:
best_dev_UAS = dev_UAS
print("New best dev UAS! Saving model.")
torch.save(parser.model.state_dict(), output_path)
print("")
def train_for_epoch(parser, train_data, dev_data, optimizer, loss_func, batch_size):
""" Train the neural dependency parser for single epoch.
Note: In PyTorch we can signify train versus test and automatically have
the Dropout Layer applied and removed, accordingly, by specifying
whether we are training, `model.train()`, or evaluating, `model.eval()`
@param parser (Parser): Neural Dependency Parser
@param train_data ():
@param dev_data ():
@param optimizer (nn.Optimizer): Adam Optimizer
@param loss_func (nn.CrossEntropyLoss): Cross Entropy Loss Function
@param batch_size (int): batch size
@return dev_UAS (float): Unlabeled Attachment Score (UAS) for dev data
"""
parser.model.train() # Places model in "train" mode, i.e. apply dropout layer
n_minibatches = math.ceil(len(train_data) / batch_size)
loss_meter = AverageMeter()
with tqdm(total=(n_minibatches)) as prog:
for i, (train_x, train_y) in enumerate(minibatches(train_data, batch_size)):
optimizer.zero_grad() # remove any baggage in the optimizer
loss = 0. # store loss for this batch here
train_x = torch.from_numpy(train_x).long()
train_y = torch.from_numpy(train_y.nonzero()[1]).long()
### YOUR CODE HERE (~4-10 lines)
### TODO:
### 1) Run train_x forward through model to produce `logits`
### 2) Use the `loss_func` parameter to apply the PyTorch CrossEntropyLoss function.
### This will take `logits` and `train_y` as inputs. It will output the CrossEntropyLoss
### between softmax(`logits`) and `train_y`. Remember that softmax(`logits`)
### are the predictions (y^ from the PDF).
### 3) Backprop losses
### 4) Take step with the optimizer
### Please see the following docs for support:
### Optimizer Step: https://pytorch.org/docs/stable/optim.html#optimizer-step
logits = parser.model(train_x)
loss = loss_func(logits, train_y)
loss.backward()
optimizer.step()
### END YOUR CODE
prog.update(1)
loss_meter.update(loss.item())
print ("Average Train Loss: {}".format(loss_meter.avg))
print("Evaluating on dev set",)
parser.model.eval() # Places model in "eval" mode, i.e. don't apply dropout layer
dev_UAS, _ = parser.parse(dev_data)
print("- dev UAS: {:.2f}".format(dev_UAS * 100.0))
return dev_UAS
(f)
四种解析错误
Prepositional Phrase Attachment Error(介词短语连接错误)
即介词短语被连接到一个错误的head上。
Verb Phrase Attachment Error(动词短语链接错误)
动词短语被连接了一个错误的头。
Modifier Attachment Error(修饰语连接错误)
比如副词被连接了错误形容的对象。
Coordination Attachment Error(并列错误)
第二个并列成分应该连接到第一个并列成分上,否则就是这类错误。
i.
- Error type: Coordination Attachment Error
- Incorrect dependency: looks → \rightarrow →mind
- Correct dependency: eyes → \rightarrow →mind
ii.
- Error type: Prepositional Phrase Attachment Error
- Incorrect dependency: chasing → \rightarrow →fur
- Correct dependency: dogs → \rightarrow →fur
iii.
- Error type: Modifier Attachment Error (副词不能用来形容名词)
- Incorrect: performances → \rightarrow →unexpectedly
- Correct dependency: good → \rightarrow →unexpectedly
iv.
- Error type: Verb Phrase Attachment Error
- Incorrect: crossing → \rightarrow →eating
- Correct dependency: saw → \rightarrow →eating
总体来说照着例子理解不难,不需要什么语言学基础或者区仔细读阅读材料