Hive中的文件存储格式TEXTFILE、SEQUENCEFILE、RCFILE、ORCFILE、Parquet 和 AVRO使用与区别详解
前言
Hive中常用的文件存储格式有:TEXTFILE 、SEQUENCEFILE、RCFILE、ORC、PARQUET,AVRO。其中TEXTFILE 、SEQUENCEFILE、AVRO都是基于行式存储,其它三种是基于列式存储;所谓的存储格式就是在Hive建表的时候指定的将表中的数据按照什么样子的存储方式,如果指定了A方式,那么在向表中插入数据的时候,将会使用该方式向HDFS中添加相应的数据类型。
列式存储和行式存储
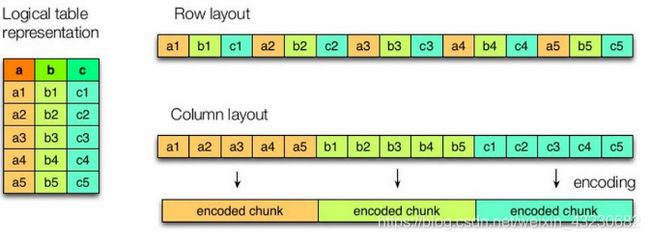
如上图所示,左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
1.行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
2.列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
Hive中几种常用文件存储格式的区别与联系
| 文件存储格式 | 描述 | 建表时如何指定 | 优缺点 |
| TEXTFILE | 文件存储就是正常的文本格式,将表中的数据在hdfs上 以文本的格式存储 ,下载后可以直接查看,也可以使用cat命令查看 |
1.无需指定,默认就是 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' |
1.行存储使用textfile存储文件默认每一行就是一条记录, 2.可以使用任意的分隔符进行分割。 3.但无压缩,所以造成存储空间大。可结合Gzip、Bzip2、Snappy等使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。 |
| SEQUENCEFILE | 在hdfs上将表中的数据以二进制格式编码,并且将数据压缩了,下载数据 以后是二进制格式,不可以直接查看,无法可视化。 |
1.stored as sequecefile 2.或者显示指定: STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat' |
1.sequencefile存储格有压缩,存储空间小,有利于优化磁盘和I/O性能 2.同时支持文件切割分片,提供了三种压缩方式:none,record,block(块级别压缩效率跟高).默认是record(记录) 3.基于行存储 |
| RCFILE | 在hdfs上将表中的数据以二进制格式编码,并且支持压缩。下载后的数据不可以直接可视化。 | 1.stored as rcfile 2.或者显示指定: STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileOutputFormat' |
1.行列混合的存储格式,基于列存储。 2.因为基于列存储,列值重复多,所以压缩效率高。 3.磁盘存储空间小,io小。 |
| ORCFILE | ORC File,全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。 |
|
1.面向列的存储格式 2.由Hadoop中RC files 发展而来,比RC file更大的压缩比,和更快的查询速度 |
| Parquet | Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。 |
Hive 0.13 and later:STORED AS PARQUET; Hive 0.10 - 0.12: |
1.与ORC类似,基于Google dremel 2.Schema 存储在footer 3.列式存储 4.高度压缩比并包含索引 5.相比ORC的局限性,parquet支持的大数据组件范围更广 |
| Avro | Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。 |
1.STORED AS AVRO
|
2.设计的主要目标是为了满足schema evolution 3.schema和数据保存在一起
|
性能测试
新建六张不同文件格式的测试用表:
--textfile文件格式
CREATE TABLE `test_textfile`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile;
--sequence文件格式
CREATE TABLE `test_sequence`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS sequence;
--rc文件格式
CREATE TABLE `test_rc`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS rc;
--orc文件格式
CREATE TABLE `test_orc`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS orc;
--parquet文件格式
CREATE TABLE `test_parquet`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS parquet;
--avro文件格式
CREATE TABLE `test_avro`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS avro;然后,从同一个源表新增数据到这六张测试表,为了体现存储数据的差异性,我们选取了一张数据量比较大的源表(源表数据量为30000000条),根据测试结果从存储空间和SQL查询两个方面进行比较:
| 文件存储格式 | HDFS存储空间 | 不含group by | 含group by |
| TextFile | 7.3 G | 105s | 370s |
| Sequence | 7.8 G | 135s | 385s |
| RC | 6.9 G | 92s | 330s |
| ORC | 246.0 M | 34s | 310s |
| Parquet | 769.0 M | 28s | 195s |
| AVRO | 8.0G | 240s | 530s |
根据性能测试总结
- 从存储文件的压缩比来看,ORC和Parquet文件格式占用的空间相对而言要小得多。
- 从存储文件的查询速度看,当表数据量较大时Parquet文件格式查询耗时相对而言要小得多。
实际情况
根据目前主流的做法来看,Hive中选用ORC和Parquet文件格式似乎更好一点,但是为什么Hive默认的文件存储格式是TextFile?
这是因为大多数情况下源数据文件都是以text文件格式保存(便于查看验数和防止乱码),这样TextFile文件格式的Hive表能直接load data数据。
如果说我们想使用ORC文件或者Parquet文件格式的表数据,可以先通过TextFile表加载后再insert到指定文件存储格式的表中。而这些不同文件格式的表我们可以通过数据分层保存,便于后期进行数据统计。