(六)kafka1.0新版的生产者和消费者demo以及源码
(六)kafka1.0版本的生产者和消费者
文章目录
- (六)kafka1.0版本的生产者和消费者
- 1:生产者
-
- 1.1:设计原理
-
- 1.1.1:消息发送的简要过程
- 1.2:示例代码
- 1.3:生产者模块源码介绍
-
- 1.3.1:produce的三大模块分析模块
-
- 1:ProducerSendThread模块
- 2:DefaultEventHandler
- 1.4:生产者发送模式
-
- 1.4.1:同步模式:sync
- 1.4.2:异步模式:async
- 2:消费者
-
- 2.1:shell消费
- 2.2:高级消费者代码示例
- 2.3:消费者源码详解
-
- 2.3.1:消费者流程
- 2.3.2:源码解读
- 3:生产和消费的速度
-
- 3.1:生产者速度
- 3.2:消费速度:
1:生产者
1.1:设计原理
生产者就是将消息发送到指定topic的partition中。
1.1.1:消息发送的简要过程
kafka的生产者对象KafkaProducer
kafka包装的消息对象:KeyedMessage
发送接口;send方法
1:调用send接口,先判断发送方式同步异步,调用底层的scala写的producer方法
2:为消息选择发送的分区,分别进行缓存。根据发送消息是否有主键key分为两种
有主键:hash分区,key散裂化取模分区
无主键:采用轮询分区
3:进入缓冲区,进行时间和消息数的判断,达到要求批量发送
4:将数据分broker统一发送来降低网络io

1.2:示例代码
编程思路:创建KafkaProducer对象,创建KeyedMessage对象包装消息再通过send方法进行发送。
private static Properties props=null;
static {
props = new Properties();
props.put("bootstrap.servers"," hdp01:9092,hdp02:9092,hdp03:9092");
/**Set acknowledgements for producer requests. 为生产者请求设置确认。*/
props.put("acks", "all");
/**If the request fails, the producer can automatically retry, 如果请求失败,生产者可以自动重试,*/
props.put("retries", 0);
/**Specify buffer size in config 在配置中指定缓冲区大小*/
props.put("batch.size", 16384);
/**Reduce the no of requests less than 0 将请求的no减少到0以下*/
props.put("linger.ms", 1);
/**The buffer.memory controls the total amount of memory available to the producer for buffering.*/
/**缓冲。内存控制生产者用于缓冲的可用内存总量。*/
props.put("buffer.memory", 8400000); //1G
/**序列化器接口的键*/
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
/**值。*/
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
}
public static void kafka_producer(){
// 步骤1:创建KafkaProducer对象
Producer producer = new KafkaProducer(props);
for(int i = 0; i < 10; i++){
//步骤2:包装消息
ProducerRecord producerRecord = new ProducerRecord("t-1810-1", "key"+Integer.toString(i), Integer.toString(i));
try {
//步骤3:发送
producer.send(producerRecord, new Callback() { //重写方法,捕捉发送状态,调用回调函数
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e!=null){
e.printStackTrace();
}
}
});
} catch (Exception e) {
System.out.println("send message failed");
e.printStackTrace();
}
}
System.out.println("Message sent successfully");
}
public static void main(String[] args) {
producer.kafka_producer();
}
1.3:生产者模块源码介绍
send最终调用
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
// 1.1:获取元数据
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 1.2:序列化 key、value
byte[] serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
byte[] serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
//1.3:为消息选择分区。
// 如果为空,会计算 key 的 hash 值,再和该主题的分区总数取余得到分区号;
// 如果 key 也为空,客户端会生成递增的随机整数,再和该主题的分区总数区域得到分区号。
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
//1.4: 校验序列化后的记录是否超过限制大小
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
// 时间戳,默认是 KafkaProducer 初始化时间
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
// 初始化回调和响应的拦截器对象
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
//1.5: 把消息添加到记录累加器中
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
// 当 batch 满了,或者创建了新的 batch 后,唤醒 Sender 线程
this.sender.wakeup();
}
return result.future;
1.1:元数据调用
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) throws InterruptedException {
//
metadata.add(topic);
Cluster cluster = metadata.fetch();
Integer partitionsCount = cluster.partitionCountForTopic(topic);
如果缓存中的数据满足条件,直接返回缓存中的元数据
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long begin = time.milliseconds();
long remainingWaitMs = maxWaitMs;
long elapsed;
//否则进行元数据更新。
do {
log.trace("Requesting metadata update for topic {}.", topic);
metadata.add(topic);
int version = metadata.requestUpdate();
//喊醒线程获取更新元数据
sender.wakeup();
try {
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMs
throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms.");
}
return new ClusterAndWaitTime(cluster, elapsed);
}
produce包含三大模块
ProducerSendThread:客户端的message缓存。
当缓存的消息量(batch.num.messages设定)到达或者到达一定时间(queue.enqueue.timeout.ms设置)没有获取到消息调用DefaultEventHandler进行发送。
producepool:缓存和broker的通信,获取同topic的元数据和客户端连接。ProducerSendThread将消息发送给不同客户端,降低io
DefaultEventHandler:发送消息的具体逻辑。具体逻辑DefaultEventHandler.handle
ProducerSendThread----------------》DefaultEventHandler-----------------》
1.3.1:produce的三大模块分析模块
1:代码实现类:Producer
class Producer[K,V](val config: ProducerConfig,
private val eventHandler: EventHandler[K,V]) extends Logging {
private val hasShutdown = new AtomicBoolean(false)
private val queue = new LinkedBlockingQueue[KeyedMessage[K,V]](config.queueBufferingMaxMessages)
private var sync: Boolean = true
private var producerSendThread: ProducerSendThread[K,V] = null
private val lock = new Object()
config.producerType match {
case "sync" =>
case "async" =>
sync = false
//模块1:ProducerSendThread
producerSendThread = new ProducerSendThread[K,V]("ProducerSendThread-" + config.clientId,
queue,eventHandler, config.queueBufferingMaxMs,
config.batchNumMessages, config.clientId)
producerSendThread.start()
}
// this是 scala的构造函数
def this(config: ProducerConfig) =
this(config,
// 模块2:DefaultEventHandler
new DefaultEventHandler[K,V](config,
Utils.createObject[Partitioner](config.partitionerClass, config.props),
Utils.createObject[Encoder[V]](config.serializerClass, config.props),
Utils.createObject[Encoder[K]](config.keySerializerClass, config.props),
//模块3
new ProducerPool(config)
))
}
1:ProducerSendThread模块
核心代码,主要通过重写run方法,processEvents // 处理核心代码
private def processEvents() {
var lastSend = SystemTime.milliseconds
var events = new ArrayBuffer[KeyedMessage[K,V]]
var full: Boolean = false
// 从队列持续获取消息。超时时间=
// Stream.continually:为scala的无限流使用
Stream.continually(queue.poll(scala.math.max(0, (lastSend + queueTime) - SystemTime.milliseconds), TimeUnit.MILLISECONDS))
.takeWhile(item => if(item != null) item ne shutdownCommand else true).foreach {
currentQueueItem =>
val elapsed = (SystemTime.milliseconds - lastSend)
// 检查是否达到了队列时间。当上面的轮询方法在超时和之后,就会currentQueueItem 返回一个null
val expired = currentQueueItem == null
// 计算累计的消息数
if(currentQueueItem != null) {
trace("Dequeued item for topic %s, partition key: %s, data: %s"
.format(currentQueueItem.topic, currentQueueItem.key, currentQueueItem.message))
events += currentQueueItem
}
// 检查批大小是否达到,在 前面配置的
full = events.size >= batchSize
if(full || expired) {
if(expired)
debug(elapsed + " ms elapsed. Queue time reached. Sending..")
if(full)
debug("Batch full. Sending..")
调用模块2--------- // 如果队列时间已达到或批处理大小已达到,则将其分派给事件处理程序:DefaultEventHandler
tryToHandle(events)
lastSend = SystemTime.milliseconds
//清空消息
events = new ArrayBuffer[KeyedMessage[K,V]]
}
}
// 发送最后一批事件
tryToHandle(events)
if(queue.size > 0)
throw new IllegalQueueStateException("Invalid queue state! After queue shutdown, %d remaining items in the queue"
.format(queue.size))
}
2:DefaultEventHandler
def handle(events: Seq[KeyedMessage[K,V]]) {
val serializedData = serialize(events)//序列化消息
serializedData.foreach {
keyed =>
val dataSize = keyed.message.payloadSize
producerTopicStats.getProducerTopicStats(keyed.topic).byteRate.mark(dataSize)
producerTopicStats.getProducerAllTopicsStats.byteRate.mark(dataSize)
}
var outstandingProduceRequests = serializedData
var remainingRetries = config.messageSendMaxRetries + 1 //获取失败重试次数
val correlationIdStart = correlationId.get() //获取发送消息的批次id,id一样认为是同批
debug("Handling %d events".format(events.size))
while (remainingRetries > 0 && outstandingProduceRequests.nonEmpty) {//消息不是空且还有重试次数
topicMetadataToRefresh ++= outstandingProduceRequests.map(_.topic) //消息的topic集合
if (topicMetadataRefreshInterval >= 0 &&
Time.SYSTEM.milliseconds - lastTopicMetadataRefreshTime > topicMetadataRefreshInterval) {//判断topic的分区数是否改变,改变更新元数据
CoreUtils.swallow(brokerPartitionInfo.updateInfo(topicMetadataToRefresh.toSet, correlationId.getAndIncrement), this, Level.ERROR)
sendPartitionPerTopicCache.clear()
topicMetadataToRefresh.clear
lastTopicMetadataRefreshTime = Time.SYSTEM.milliseconds
}
outstandingProduceRequests = dispatchSerializedData(outstandingProduceRequests) //进行消息发送,返回失败消息进行重试
if (outstandingProduceRequests.nonEmpty) {
info("Back off for %d ms before retrying send. Remaining retries = %d".format(config.retryBackoffMs, remainingRetries-1))
// 在尝试另一个发送操作之前,请退出并更新主题元数据缓存
Thread.sleep(config.retryBackoffMs)
// 获取未完成的生产请求的主题并刷新这些请求的元数据
CoreUtils.swallow(brokerPartitionInfo.updateInfo(outstandingProduceRequests.map(_.topic).toSet, correlationId.getAndIncrement), this, Level.ERROR)
sendPartitionPerTopicCache.clear()
remainingRetries -= 1
producerStats.resendRate.mark()
}
}
if(outstandingProduceRequests.nonEmpty) { //失败重试
producerStats.failedSendRate.mark()
val correlationIdEnd = correlationId.get()
error("Failed to send requests for topics %s with correlation ids in [%d,%d]"
.format(outstandingProduceRequests.map(_.topic).toSet.mkString(","),
correlationIdStart, correlationIdEnd-1))
throw new FailedToSendMessageException("Failed to send messages after " + config.messageSendMaxRetries + " tries.", null)
}
}
1.4:生产者发送模式
发送模式分为同步模式和异步模式,配置项:producer.type=sync/async
同步模式:消息立刻发给broker,增加请求次数和网络io
异步模式:消息进行缓存队列,到时间或者缓存大小再发送,可以提升发送速度,减少网络io。
1.4.1:同步模式:sync
流程分析
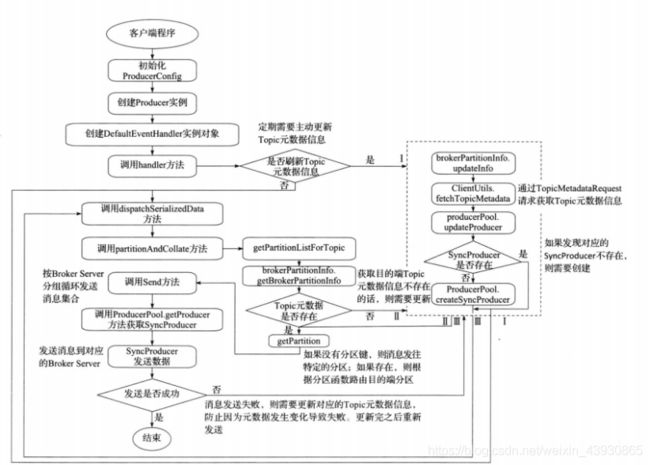
1.4.2:异步模式:async

2:消费者
消费者分为高级和简单两种消费者
高级:消费者组形式消费,更加简单高效
2.1:shell消费
可以使用消费者组命令查看,监控工具也可以使用
./kafka-consumer-groups.sh --zookeeper hdp01:2181,hdp02:2181,hdp03:2181 --list
/kafka-consumer-groups.sh --zookeeper hdp01:2181,hdp02:2181,hdp03:2181 --group cons --describe

2.2:高级消费者代码示例
1个Consumer和多个线程消费模型,保证只有一个线程操作KafkaConsumer,其它线程消费ConsumerRecord列表

public class consumer {
private final ConsumerConnector consumer;
priate final String topic="spark01";
public consumer(){
Properties props = new Properties();
//zookeeper 配置,通过zk 可以负载均衡的获取broker
props.put("group.id", "cons");
props.put("enable.auto.commit", "true");
props.put("zookeeper.connect","hdp01:2181,hdp02:2181,hdp03:2181");
props.put("auto.commit.interval.ms", "1000");
props.put("partition.assignment.strategy", "Range");
props.put("auto.offset.reset", "smallest");
// props.put("zookeeper.connect","hdp01:2181,hdp02:2181,hdp03:2181");
/**序列化器接口的键*/
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
/**值。*/
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("serializer.class", "kafka.serializer.StringEncoder");
//构建consumer connection 对象
consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(props));
}
public void consume(){
//指定需要订阅的topic
Map topicCountMap = new HashMap();
//value值建议和partititon个数一样。指定featch消息的线程数,从而实现多线程获取消息,若此处value!=1,但是没有多线程featch,会造成正常运行但是消费不到消息的现象。具体看源码分析,会并行获取分区的消息
topicCountMap.put(topic, new Integer(numThreads));
//指定key的编码格式
Decoder keyDecoder = new kafka.serializer.StringDecoder(new VerifiableProperties());
//指定value的编码格式
Decoder valueDecoder = new kafka.serializer.StringDecoder(new VerifiableProperties());
//获取topic 和 接受到的stream 集合,针对每一个消费者线程创建一个BlockingQueue队列,队列中存储的
//是FetchedDataChunk数据块,每一个数据块中包括多条记录。
Map>> map = consumer.createMessageStreams(topicCountMap, keyDecoder, valueDecoder);
//根据指定的topic 获取 stream 集合
List> kafkaStreams = map.get(topic);
//创建多线程消费者kafkaStream,线程数和topicCountMap 中的value值必须保持一致。若value为1,则没有必要运行线程池创建多线程
ExecutorService executor = Executors.newFixedThreadPool(numThreads);
//因为是多个 message组成 message set , 所以要对stream 进行拆解遍历
for(final KafkaStream kafkaStream : kafkaStreams){
//是否需要多线程根据topicCountMap 中的value值是否>1
executor.submit(new Runnable() {
@Override
public void run() {
//拆解每个的 stream,一般根据消费获取某几个分区的数据。
ConsumerIterator iterator = kafkaStream.iterator();
while (iterator.hasNext()) {
//messageAndMetadata 包括了 message , topic , partition等metadata信息
MessageAndMetadata messageAndMetadata = iterator.next();
System.out.println("message : " + messageAndMetadata.message() + " partition : " + messageAndMetadata.partition());
//偏移量管理:提交由此连接器连接的所有代理分区的偏移量。
consumer.commitOffsets();
}
}
});
}
}
public static void main(String[] args) {
new consumer().consume();
}
}
2.1关闭自动提交
props.put(“enable.auto.commit”, “false”);
可以看到偏移量没有提交

2.2开启自动提交
props.put(“enable.auto.commit”, “true”);
2.3:消费者源码详解
源码位置:org/apache/kafka/clients/consumer/KafkaConsumer.java
类下主要方法介绍
- 1:subscribe订阅topic
- 2:poll拉取消息
- 3:commitSync:向kafka集群提交消费偏移量
- 4:commitAsync:异步提交偏移量,可以执行回调函数
- 5:position:获取分区的偏移量
2.3.1:消费者流程
KafkaConsumer.subscribe()进行订阅topic
1:获取topic元数据以及partition的leader,只有leader负责读写功能
2:获取响应partition的消费偏移量,不管是偏移量如何存储
3:向broker发送消费请求
4:提交偏移量

2.3.2:源码解读
KafkaStream一个迭代器,它会阻塞,直到可以从提供的队列中读取一个值
消费者consumer.createMessageStreams的实现是kafka.javaapi.consumer.ZookeeperConsumerConnector,其只是一个包装类,真正实现kafka.consumer.ZookeeperConsumerConnector
1:createMessageStreams
def createMessageStreams[K,V](
topicCountMap: java.util.Map[String,java.lang.Integer],
keyDecoder: Decoder[K],
valueDecoder: Decoder[V])
: java.util.Map[String,java.util.List[KafkaStream[K,V]]] = {
if (messageStreamCreated.getAndSet(true))
throw new MessageStreamsExistException(this.getClass.getSimpleName +
" can create message streams at most once",null)
val scalaTopicCountMap: Map[String, Int] = {
import JavaConversions._
Map.empty[String, Int] ++ (topicCountMap.asInstanceOf[java.util.Map[String, Int]]: mutable.Map[String, Int])
}
//调用真正的实现类:kafka.consumer.ZookeeperConsumerConnector
val scalaReturn = underlying.consume(scalaTopicCountMap, keyDecoder, valueDecoder)
val ret = new java.util.HashMap[String,java.util.List[KafkaStream[K,V]]]
for ((topic, streams) <- scalaReturn) {
var javaStreamList = new java.util.ArrayList[KafkaStream[K,V]]
for (stream <- streams)
javaStreamList.add(stream)
ret.put(topic, javaStreamList)
}
ret
}
2:kafka.consumer.ZookeeperConsumerConnector
def consume[K, V](topicCountMap: scala.collection.Map[String,Int], keyDecoder: Decoder[K], valueDecoder: Decoder[V])
: Map[String,List[KafkaStream[K,V]]] = {
debug("entering consume ")
if (topicCountMap == null)
throw new RuntimeException("topicCountMap is null")
val topicCount = TopicCount.constructTopicCount(consumerIdString, topicCountMap)
val topicThreadIds = topicCount.getConsumerThreadIdsPerTopic
// make a list of (queue,stream) pairs, one pair for each threadId
val queuesAndStreams = topicThreadIds.values.map(threadIdSet =>
threadIdSet.map(_ => {
val queue = new LinkedBlockingQueue[FetchedDataChunk](config.queuedMaxMessages)
val stream = new KafkaStream[K,V](
queue, config.consumerTimeoutMs, keyDecoder, valueDecoder, config.clientId)
(queue, stream)
})
).flatten.toList
val dirs = new ZKGroupDirs(config.groupId)
registerConsumerInZK(dirs, consumerIdString, topicCount)
reinitializeConsumer(topicCount, queuesAndStreams)
loadBalancerListener.kafkaMessageAndMetadataStreams.asInstanceOf[Map[String, List[KafkaStream[K,V]]]]
}
如何实现主要包括以下四大问题:
1:consumerThread和partition如何分配?
topicCountMap 的value值去创建消费者线程。那消费者线程和partition如何分配,
kafka提供了两种partition分配算法,也就是range(范围),roundrobin(轮询)
3:生产和消费的速度
3.1:生产者速度
生产的消息要发送到服务器,分区数会影响性能,但是测试发现50-100间的分区数是最好的,更高的分区数并不会再提升。
记录一次问题:同步模式0.8版本发送时遇到突然提高数据量导致的sockettimeout超时问题:各种排查网络io,cpu,内存无果,最终替换0.11版本的api提升了同步生产瓶颈,没有超时问题
3.2:消费速度:
以单台服务器吞吐量300M为例,则无论分区再多,上线也是吞吐量,也就是说所有的消费者共同分摊吞吐量:例如3个分区,则每个分区100M。所有增加服务器会提升集群性能,增加消费者个数会提升性能。