用户行为分析模型实践--漏斗分析模型
在《用户行为分析模型实践——路径分析模型
》中,讲述了基于平台化查询中查询时间短、需要可视化的要求,并结合现有的存储计算资源以及具体需求,我们在实现中将路径数据进行枚举后分为两次进行合并。
本次本文详细介绍漏斗模型的概念及基本原理,并阐述了其在平台内部的具体实现。针对实际使用过程的问题,探索基于 ClickHouse漏斗模型实践方案。
一、背景需求
漏斗分析是衡量转化效果、进行转化分析的重要工具,是一种常见的流程式的数据分析方法。它能够帮助你清晰地了解转化情况,从多角度剖析对比,定位流失原因,提升转化表现。他主要立足于三大需求场景:
-
定位用户流失具体原因。
-
检测某个专题活动效果。
-
针对不同版本,转化率情况对比。
二、概述
2.1 概念介绍
漏斗模型主要用于分析一个多步骤过程中每一步的转化与流失情况。其中有几个概念要了解:
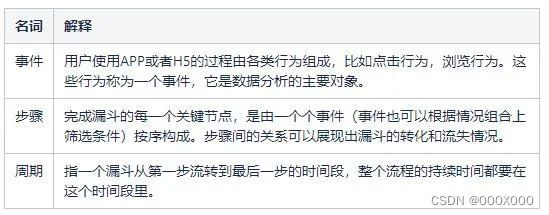
其中漏斗模型分为两种:无序漏斗和有序漏斗。
定义如下:
无序漏斗:在漏斗的周期内,不限定漏斗多个步骤之间事件发生的顺序。
【计算规则】:假设一个漏斗中包含了 A、B、C 3个步骤,A步骤发生的时间可以在B步骤之前,也可以在B的后面。用户的行为顺序为A、B、C的组合都算成功的漏斗转化。即使漏斗步骤之间穿插一些其他事件步骤,依然视作该用户完成一次成功的漏斗转化。
有序漏斗:在漏斗的周期内,严格限定漏斗每个步骤之间的发生顺序。
【计算规则】:假设一个漏斗中包含了 A、B、C 3个步骤,A步骤发生的时间必须在B步骤之前,用户的行为顺序必须为A->B->C 。
和无序漏斗一样,漏斗步骤之间穿插一些其他事件步骤,依然视作该用户完成一次成功的漏斗转化。
三、 用漏斗进行的数据分析
了解了上面的关于漏斗模型的基本概念,我们看一下如何创建一个漏斗。
3.1 选一个漏斗类型
漏斗模型的类型一般分为有序漏斗和无序漏斗,它们的概念已在2.1做了详细的介绍。我们这里以无序漏斗为例,创建漏斗模型。
3.2 添加漏斗步骤
漏斗步骤就是漏斗分析的核心部分,步骤间统计数据的对比,就是我们分析步骤间数据的转化和流失的关键指标。
比如我们以一个“下载应用领红包”的活动为例。预设的用户的行为路径是:用户首先进入【红包首页】,发现最新的红包活动“下载应用,领取红包”,点击进入【红包活动页】,根据提示跳转到【应用下载页】,选择自己感兴趣的应用下载,完成后,进入【提现页面】领取活动奖励。从上面描述的场景中,我们可以提取出以下关键的四步。
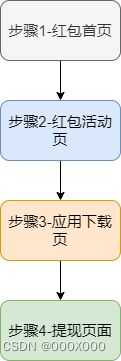
图3.1 “下载应用领红包”活动步骤
3.3 确定漏斗的时间区间和周期
这里多了一个时间区间的概念,与前文介绍的周期容易混淆。一般来说,此类数据的数仓表是按照时间分区的。所以选择时间区间,本质就是选择要计算的数据范围。
周期是指一个漏斗从第一步流转到最后一步的时间限制,即是用来界定怎样才是一个完整的漏斗。在本例中,我们按照天为周期进行处理,选择时间区间为“2021-05-27”、“2021-05-28”、“2021-05-29”。
3.4 漏斗数据的展示
依据我们设计的漏斗模型(具体模型设计,下文会提及),可以计算出下表的数据:
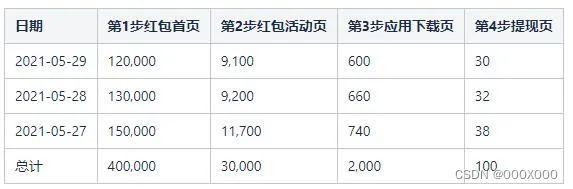
表3.1 “下载应用领红包”活动分步数据
以表3.1中2021-05-27日的数据为例,触达第一步“红包首页”的用户数量为150,000,在同一天内同时触发第一步“红包首页”和第二步“红包活动页”的人数为11,700。其他数据的含义以此类推。
将表3.1中的数据每步按照日期加起来,就得到2021-05-27至2021-05-29日数据的漏斗图(图3.2)。
从中可以直观的反应出用户在“红包首页”、“红包活动页”、“应用下载页”、“提现页”四步中每一步的人数和转化率。
比如,触达“红包首页”页面的人数为400,000,经过”红包首页“,触达”红包活动页“页面的人数为30,000。则这两个阶段的转化率为:30,000÷400,000=7.5%。
通过对各个阶段人数和转化率的比对,就能比较直观的发现我们这个 “下载应用领红包”的活动用户流失的环节所在,并以此排查原因和优化各个环节。
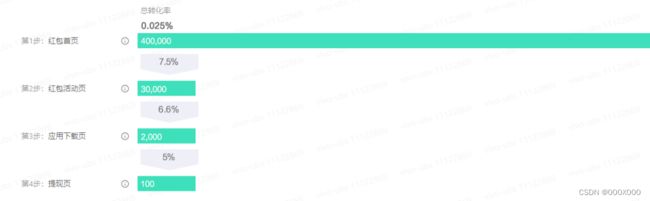
图 3.2 “下载应用领红包”活动漏斗图
四、整体功能设计及漏斗分析模型的实现
4.1 功能整体架构设计
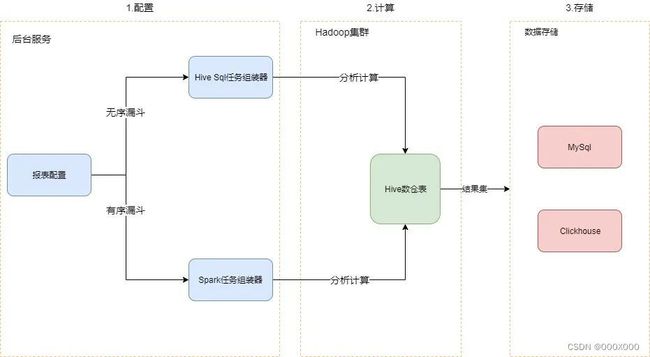
图 4.1 漏斗分析整体架构设计
整体工程主要分为配置、计算、存储三阶段。
(1)配置
此阶段主要是工程端的后台服务实现。用户在前端按照自身需求设置漏斗类型、漏斗步骤、筛选条件、时间区间和周期等配置。后台服务收到配置请求后,依据漏斗类型选择不同任务组装器进行任务的组装。
其中,漏斗类型是无序漏斗使用的Hive SQL 任务组装器,而更加复杂的有序漏斗可以使用 Spark任务组装器。组装后生成的任务包含了漏斗模型的计算逻辑,比如 Hive SQL或者 Spark 任务。
(2)计算
平台根据接收到的任务的类型,选择Hive或者 Spark引擎进行分析计算。计算结果同步到 MySQL 或者ClickHouse集群。
(3)存储
结果集持久化到数据库中,可通过后台服务展示给用户。
4.2 无序漏斗实现逻辑
无序漏斗并不限制其多个步骤之间的发生顺序,只要在限定的周期内完成即可。
在模型的设计上,采用的思想是:
在一个周期内,按照步骤顺序依次计算漏斗每一步骤的人数,并且下一层的计算的人群范围要等于上一次计算完成的人群范围,通过每一步的人群范围可以计算出想要的指标,比如每步的人数(uv)或者访问量(pv)。
如图4.2 所示。其中,圈选的人群为每一步的触达的人数,计算的结果集就是基于此人群得到计算结果。步骤1的圈选人群会作为步骤2漏斗计算的一个筛选条件,参与后续计算。依次类推完成漏斗的每一步计算。最终汇集每一步的计算结果集形成类似于表3.1 的结果数据。
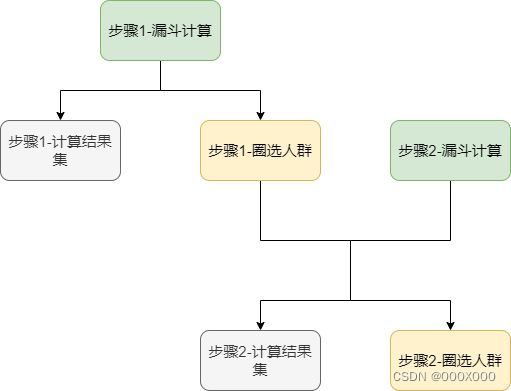
图4.2 无序漏斗计算逻辑
4.3 有序漏斗实现逻辑
有序漏斗顾名思义,将严格漏斗每步之间的顺序。整个实现逻辑可分为以下几步:
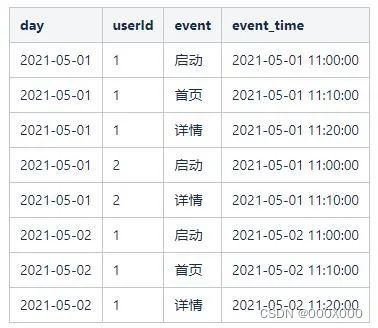
(1)获取规定时间区间内的数据集。
为了方便讲解,示例数据如下图所示,其中,day为数据上报的时间,userId为用户唯一标识,event为事件,event_time为事件发生时间。
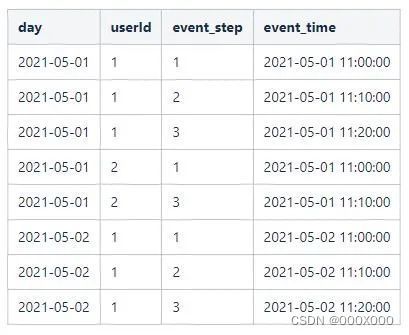
(2)按照漏斗步骤计算每行数据处于的漏斗步骤。
假设需要统计分析的漏斗步骤为:“启动”->“首页”->“详情”。‘“启动”标记为1,“首页”标记为2,“详情”标记为3,记录在event_step字段上。
(3)对上述数据进行处理,得到每个用户在当天有序的事件上报列表。
将上述数据按照day,userId分组,按event_time顺序,分别求取event_step和event_time的有序集合,并根据event_step获取漏斗触达的最大深度,记为level,如下:
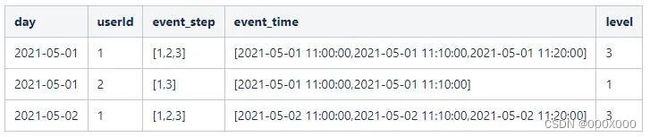
(4)计算每一步漏斗的人数。
按照day与level分组计算每一步漏斗的人数,也是是每个level的uv。
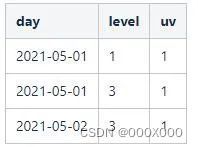
需要注意的是,因为计算的是每一步漏斗的人数,所以步骤与步骤之间人数是没有交集的,但事实上,根据有序漏斗的计算逻辑,触达漏斗后面的步骤,一会触达其前面的漏斗步骤。
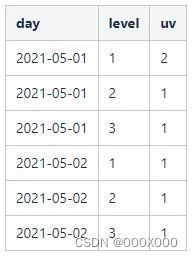
所以,前面的步骤一定要加上其后所有步骤的的人数,才是该步真正的人数。如上面的例子,对于2021-05-01的数据,level=1的uv为1,level=2的uv为0,level=3的uv为1,所以level=1实际总人数为三步人数之和,也就是2。依次类推,由此可以得到所有步骤真正的总人数。
4.4 存在的问题与下一步优化的方向
问题:现阶段用户通过自定义的配置,生成相应的Spark或者Hive任务计算出模型的结果并生成报表,进而展示给用户。这样的流程在提供给用户灵活的配置和个性化的查询的同时,兼顾了节约存储资源。美中不足的是报表的生成过程,依然需要耗费一定的时间成本,尤其是有序漏斗采用了Spark计算,对于队列资源也会产生较大的消耗。这点在用户短时间创建大量的分析报表时,体现的尤为明显。
优化方向:将一定时期内的相关的数仓数据同步到ClickHouse,依托ClickHouse强大的即时计算和分析能力,为用户提供所查即所得的使用体验。用户可以根据自身业务需求选择即时查询或者离线报表。例如,比如需要大量组合各类条件进行对比分析的可以选择即时模块。需要长期观察的报表可以选择离线的例行报表。这样就达到的存储和查询效率的平衡。
下面,就对漏斗模型在ClickHouse上的应用做一些探索。
五、基于 ClickHouse 的漏斗分析模型
5.1 主要函数介绍
(1)windowFunnel(window, [mode, [mode, ... ]])(timestamp, cond1, cond2, ..., condN)
-
定义:
在所定义的滑动窗口内,依次检索事件链条。函数在这个事件连上触及的事件的最大数量。
-
补充:
① 该函数检索到事件在窗口内的第一个事件,则将事件计数器设置为1,此时就是滑动窗口的启动时刻。
② 如果来自链的事件在窗口内顺序发生,则计数器递增,如果事件序列终端,则计数器不会增加。
③ 如果数据在不同的完成点具有多个事件链,则该函数将仅输出最长链的大小。
-
参数:
①【timestamp】 :表中代表时间的列。函数会按照这个时间排序
② 【cond】:事件链的约束条件
③【window】:滑动窗口的长度,表示首尾两个事件条件的间隙。单位依据timestamp的参数而定。即:timestamp of cond1 <= timestamp of cond2 <= ... <= timestamp of condN <= timestamp of cond1 + window
④ 【mode】:可选的一些配置:
【strict】: 事件链中,如果有事件是不唯一的,则重复的事件的将被排除,同时函数停止计算。
【strict_orde】:事件链中的事件,要严格保证先后次序。
【strict_increase】:事件链的中事件,其事件戳要保持完全递增。
(2)arrayWithConstant(length,param)
-
定义:
生成一个指定长度的数组
-
参数:
① length:数组长度
② param:填充字段
-
例:SQL:
select arrayWithConstant(3,1);Result:
arrayWithConstant(3, 1)
[1,1,1] (3)arrayEnumerate(arr)
-
定义:返回数组下标
-
参数:arr:数组
-
例:SQL:
select arrayEnumerate([11,22,33]);Result:
arrayEnumerate([11, 22, 33])
[1,2,3] (4)groupArray(x)
-
定义:创建数组
-
例:SQL:
select groupArray(1);Result:
groupArray(1)
[1] (5)arrayCount([func,] arr1)
-
定义:返回数组中符合函数func的元素的数量
-
参数:
① func:lambda表达式
② arr1:数组
-
例:SQL:
select arrayCount(x-> x!=1,[11,22,33]);Result:
arrayCount(lambda(tuple(x), notEquals(x, 1)), [11, 22, 33])
3 (6)hasAll(set, subset)
-
定义:检查一个数组是否是另一个数组的子集,如果是就返回1
-
参数:
① set:具有一组元素的任何类型的数组。
② subset:任何类型的数组,其元素应该被测试为set的子集。
-
例:SQL:
select hasAll([11,22,33], [11]);Result:
hasAll([11, 22, 33], [11])
1 5.2 模型构建过程
5.2.1 数据准备
为了更加清晰的讲解整个过程,我们举一个例子演示一下整个过程。
首先构建一个ClickHouse表funnel_test,包含用户唯一标识userId,事件名称event,事件发生日期day。
建表语句如下:
create table funnel_test(userId String,event String,day DateTime)engine = MergeTree PARTITION BY userIdORDER BY xxHash32(userId);
插入测试数据:
insert into funnel_test values(1,'启动','2021-05-01 11:00:00');insert into funnel_test values(1,'首页','2021-05-01 11:10:00');insert into funnel_test values(1,'详情','2021-05-01 11:20:00');insert into funnel_test values(1,'浏览','2021-05-01 11:30:00');insert into funnel_test values(1,'下载','2021-05-01 11:40:00');insert into funnel_test values(2,'启动','2021-05-02 11:00:00');insert into funnel_test values(2,'首页','2021-05-02 11:10:00');insert into funnel_test values(2,'浏览','2021-05-02 11:20:00');insert into funnel_test values(2,'下载','2021-05-02 11:30:00');insert into funnel_test values(3,'启动','2021-05-01 11:00:00');insert into funnel_test values(3,'首页','2021-05-02 11:00:00');insert into funnel_test values(3,'详情','2021-05-03 11:00:00');insert into funnel_test values(3,'下载','2021-05-04 11:00:00');insert into funnel_test values(4,'启动','2021-05-03 11:00:00');insert into funnel_test values(4,'首页','2021-05-03 11:01:00');insert into funnel_test values(4,'首页','2021-05-03 11:02:00');insert into funnel_test values(4,'详情','2021-05-03 11:03:00');insert into funnel_test values(4,'详情','2021-05-03 11:04:00');insert into funnel_test values(4,'下载','2021-05-03 11:05:00');
如果数据表如下:
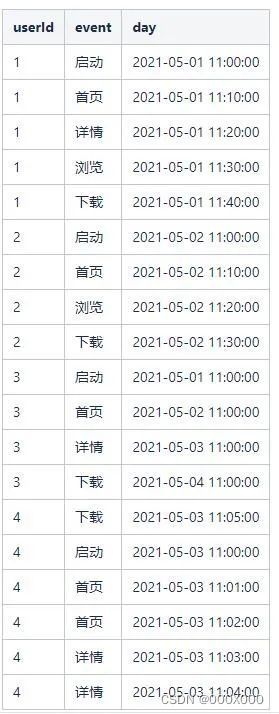
表 5.1 漏斗模型测试数据
5.2.2 有序漏斗计算
假定,漏斗的步骤为:启动->首页->详情->下载
(1)使用ClickHouse的漏斗构建函数windowFunnel()查询
SELECT userId,windowFunnel(86400)(day,event = '启动',event = '首页',event = '详情',event = '下载') AS levelFROM (SELECT day, event, userIdFROM funnel_testWHERE toDate(day) >= '2021-05-01'and toDate(day) <= '2021-05-06')GROUP BY userIdorder by userId;
从上述SQL中,设置了漏斗周期为86400秒(1天),这个周期的单位是依据timestamp决定的。整个漏斗分为了4步骤:启动、首页、详情、下载。时间区间为“2021-05-01”到“2021-05-06”之间。执行后,得到如下结果:
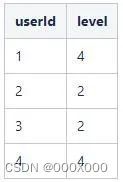
从结果中,可以看到各个userId在规定周期内,触达的最大的漏斗层级,也就是执行了漏斗步骤了几步。例如,userId=1,在一天内,按序访问了启动->首页->详情->下载这四步,得到最大层级就是4。当然,我们也可以漏斗函数配置为”strict_order“模式,他将严格保证先后次序,还是userId为1的情况,在”2021-05-01“这一天,”详情“与”下载“间多了个”浏览“的动作,所以此刻,userId=1可触达的层级就是3,因为,在”strict_order“下,”详情“阻断了整个事件链路。
(2)获取每个用户在每个层级的明细数据
通过上一步我们计算出了每个用户在设定的周期内触达的最大的层级。下面接着要计算每个用户在每个层级的明细数据,计算逻辑如下:
SELECT userId,arrayWithConstant(level, 1) levels,arrayJoin(arrayEnumerate(levels)) level_indexFROM (SELECT userId,windowFunnel(86400)(day,event = '启动',event = '首页',event = '详情',event = '下载') AS levelFROM (SELECT day, event, userIdFROM funnel_testWHERE toDate(day) >= '2021-05-01'and toDate(day) <= '2021-05-06')GROUP BY userId);
将这个最大的层级转化为相应大小的数组,从中得到数组下标集合,然后将这个下标的集合按其中元素展开为多行。这样就得到每个用户在每个层级上明细数据。
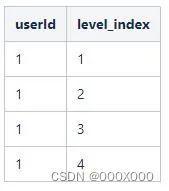
例如userId=1的最大层级为4,通过arryWithConstant函数生成数组[1,1,1,1],然后取这个数组下标得到新的数组[1,2,3,4],这些下标其实对应着漏斗的“启动”,“首页”,“详情”,“下载”这四个层级。
将下标数组通过arrayJoin函数展开,得到userId=1的各层明细数据:
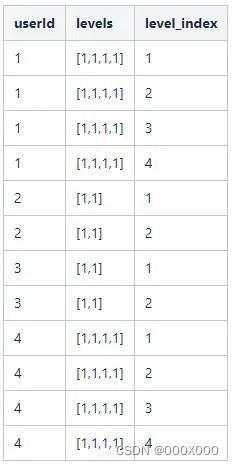
全部userId的执行结果如下:
(3) 计算漏斗各层的用户数
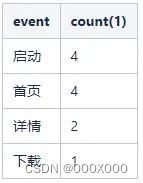
将上面步骤得到的明细数据按照漏斗层级分组聚合,就得到了每个层级的用户数。总体逻辑如下:
SELECT transform(level_index,[1,2,3,4],['启动','首页','详情','下载'],'其他') as event,count(1)FROM (SELECT userId,arrayWithConstant(level, 1) levels,arrayJoin(arrayEnumerate(levels)) level_indexFROM (SELECT userId,windowFunnel(86400)(day,event = '启动',event = '首页',event = '详情',event = '下载') AS levelFROM (SELECT day, event, userIdFROM funnel_testWHERE toDate(day) >= '2021-05-01'and toDate(day) <= '2021-05-06')GROUP BY userId))group by level_indexORDER BY level_index;
结果为:
5.2.3 无序漏斗计算
假定,漏斗的步骤为:启动->首页
(1)确定计算的数据范围
SELECT toDate(day),event,userIdFROM funnel_testWHERE toDate(day) >= '2021-05-01'and toDate(day) <= '2021-05-06';
结果如下:
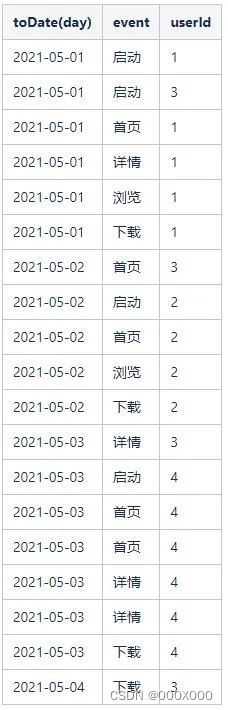
(2)计算每个userId的访问量(pv)和访问用户数(uv)。
先按照时间与userId分组,通过groupArray函数获取事件(event)的集合。
pv计算:
【漏斗第一层级】:直接查询事件集合中,漏斗第一步事件的总数。
【漏斗第二层级】:在第一层级事件存在的情况下,查询第二层级的数量。后面的层级以此类推。
uv计算:
【漏斗第一层级】:如果事件集合中,包含第一步事件,则记为1,表示存在。
【漏斗第二层级】:事件集合中,同时包含第一与第二层级事件,则记为1。后面的层级依此类推。
select day,userId,groupArray(event) as events,arrayCount(x-> x = '启动', events) as level1_pv,if(has(events, '启动'), arrayCount(x-> x = '首页', events), 0) as level2_pv,hasAll(events, ['启动']) as level1_uv,hasAll(events, ['启动','首页']) as level2_uvfrom (SELECT toDate(day) as day,event,userIdFROM funnel_testWHERE toDate(day) >= '2021-05-01'and toDate(day) <= '2021-05-06')group by day, userId;
得到结果:
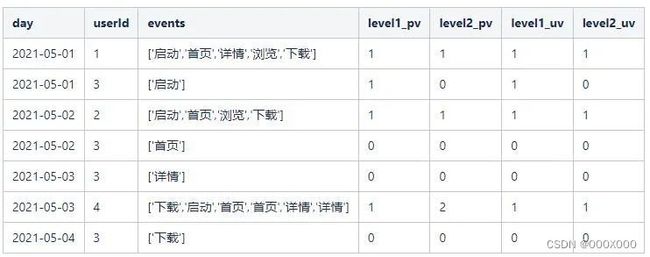
(3)按天统计
按天统计,计算出每天的用户数及每个层级的pv,uv。
SELECT day AS day,sum(level1_pv) AS sum_level1_pv,sum(level2_pv) AS sum_level2_pv,sum(level1_uv) as sum_level1_uv,sum(level2_uv) as sum_level2_uvfrom (select day,userId,groupArray(event) as events,arrayCount(x-> x = '启动', events) as level1_pv,if(has(events, '启动'), arrayCount(x-> x = '首页', events), 0) as level2_pv,hasAll(events, ['启动']) as level1_uv,hasAll(events, ['启动','首页']) as level2_uvfrom (SELECT toDate(day) as day,event,userIdFROM funnel_testWHERE toDate(day) >= '2021-05-01'and toDate(day) <= '2021-05-06')group by day, userId)group by dayorder by day;
计算结果如下:
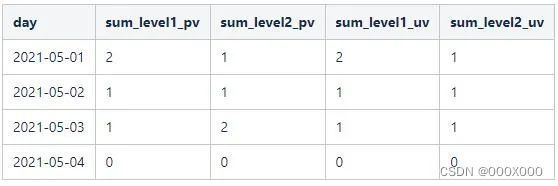
六、写在最后
漏斗分析是数据分析中的一个重要的分析手段,通过它获取的各个环节的访问量、转化率、流失率等数据,为我们评估业务流程的合理性,提升用户体验,加强用户的留存率都起到了重要作用。
本文简述了现有基于 Hive/Spark 的漏斗模型的实现逻辑,此种方式在允许用户高度自定义查询的同时,节约了存储资源。但是会消耗一定的时间成本和队列资源。
为了优化此类问题,本文讨论了基于 ClickHouse 的漏斗模型实现,在模型的计算速率取得了较为理想的效果。ClickHouse 虽然拥有种类繁多的函数支持计算分析,但是在缺少便捷的自定义函数功能,在某些细分场景下并不十分贴合业务,这一点也是未来可以加强和突破的方向。