Kubernetes权威指南(上)
Phineas
#云K8S
华为云:CCE
阿里云:ACK
腾讯云:TKE
#Kubernetes:自动化容器编排的开源平台,让部署容器化的应用简单并高效,核心特点是可以让容器按用户的期望状态运行。
- 核心组件
etcd:分布式键值存储系统
apiserver:资源操作的唯一入口
scheduler:资源的调度
controller-manager:管理控制器
kubelet:管理、维护容器生命周期
kube-proxy:服务发现和负载均衡
容器运行时:如Docker 负责本机的容器创建与管理。
- pod:K8S中原子调度单位,一个POD中含有多个容器,像豆荚中的一个个豆子。
网络通信方式:
同一主机内POD内部通信,共享同一个网络命名空间
不同主机内POD通过宿主机物理网卡通信
POD创建同时会创建一个Pause(infra)容器,用来共享网络、挂载卷
- 名称空间级别
工作负载型资源: Pod、Replicaset、Deployment、Job、Cronjob
服务发现及负载均衡型资源:Service(四层负载均衡)、Ingress(七层负载均衡)
配置与存储资源:Volume、CSI(容器存储接口)
特殊类型的存储卷:Configmap、Secret
集群级资源:Namespaces、Node、Role
元数据型资源:HPA、PodTemplate
- pod生命周期
init容器————> 初始化pod
探针----> 对容器定期判断 (返回码:为0正确;TCP检查:端口打开正确;HTTP状态码:200-400之间)
----> liveness (存活检测);readiness(就绪检测)
pod phase(阶段)----> pending(挂起);running(运行中);succeeded(成功);failed(失败);unknown(未知)
pod分类----> 自主式pod(没就没了);控制器管理的pod(始终维持pod副本数目)
- 控制器
Replicaset #确保容器副本数 (命令式编程--> create)(无状态服务)
Deployment #声明定义RS和POD,通过RS管理POD,可用来更新、回滚版本 (声明式编程--> apply)(无状态服务)(升级版的RC控制器)
Daemonset #确保全部(或一些)Node上运行一个Pod副本 (命令式编程)
Job #负责批处理任务(保证成功结束,不为0会重新执行)
Cronjob #管理基于时间的Job(定时运行,跟linux中crontable一样:分时日月周)
Statefulset #解决有状态服务
HPA #自动扩展
- Service (svc 四层负载均衡)
svc类型
Cluster IP #仅内部可访问的虚拟IP
NodePort #外部可访问
LoadBalancer #在NodePort基础上,借助云厂商创建一个外部负载均衡器并转发给NodePort
Externalname #将集群外部的服务引入集群内部
K8S集群中每个Node运行一个kube-proxy进程,负责为service实现了一种VIP形式
代理模式分类
Userspace
IPtables
LVS(IPVS) √
- Ingress 七层 API
client--> 访问域名--> nginx(ingress)——> SVC --> pod
- 存储
分类:
configmap(cm) #存储配置文件
secret #加密信息
volume #提供Pod共享存储卷
Persistent volume(PV) #持久卷
configmap创建
目录创建 --> 指定目录
文件创建 --> 指定文件
字面值创建 --> 命令行中创建
pod中使用cm
使用cm来替代环境变量
使用cm设置命令行参数
通过数据卷插件使用cm(将pod内数据卷挂载到外面)
configmap更新后滚动更新Pod(Env是容器启动时注入的所以不会更新),更新configmap目前并不会触发相关Pod的滚动更新,可通过修改pod annotations的方式强制触发滚动更新
secret
service account #K8S自动创建,用来访问K8S API
opaque #加密存储密码、密钥等
kubenetes.io/docker config json #存储私有docker registry 认证信息
volume
当容器重启时,容器中的文件将丢失,容器以干净的状态重新启动
emptyDir #pod分配给节点后,先创建emptyDir卷
hostpath #卷将主机节点的文件系统中的文件或目录挂载到集群中
pv、pvc
pv #管理员设置的存储
pvc #用户存储的请求(pvc是对pv的申请)
pv访问模式
RWO 单节点以读/写模式挂载
ROX 多节点以只读模式挂载
RWX 多节点以读/写模式挂载
回收策略
retain(保留) 手动回收
recycle(回收) 基本擦除
delete(删除)关联的基本资产将被删除
volume和Pv的区别
普通v和使用它的pod之间是一种静态绑定关系,在定义pod的文件里同时定义了它使用的v(v是pod的附属品),而pv是一个k8s资源对象,所以可以单独创建一个pv,它不和pod直接发成关系,而是通过pvc实现动态绑定
- 调度
scheduler 调度器:公平、资源高利用、效率、灵活
调度过程
预选(先):条件(按算法选出条件符合的)
优选(后):优先级
也可自定义调度器
节点亲和性 #关系为Node和Pod
软策略
硬策略
pod亲和性 #关系为Pod和Pod
软策略
硬策略
污点和容忍
节点亲和性是pod的一种属性,它使pod被吸引到一类特定的节点,污点则相反,它使节点能够排斥一类特定的Pod
节点和污点相互配合,可以避免Pod被分配到不合适的节点上
污点
使用kubectl taint命令可以给某个node节点设置污点,Node被设置上污点后就和Pod之间存在了一种相斥关系,可以让Node拒绝Pod的调度执行,甚至将Node已经存在的Pod驱逐出去
容忍
但我们可以在Pod上设置容忍,设置了容忍的Pod可容忍污点的存在
指定固定节点
通过节点名称或节点标签将Pod直接指定的Node上
- 集群安全
API server 是集群内部各个组件通信的中介,也是外部控制的入口,所以K8S的安全机制基本就是围绕保护API server来设计的,包括:认证、鉴权、准入控制三步来保证API server的安全
- helm 安装包管理工具
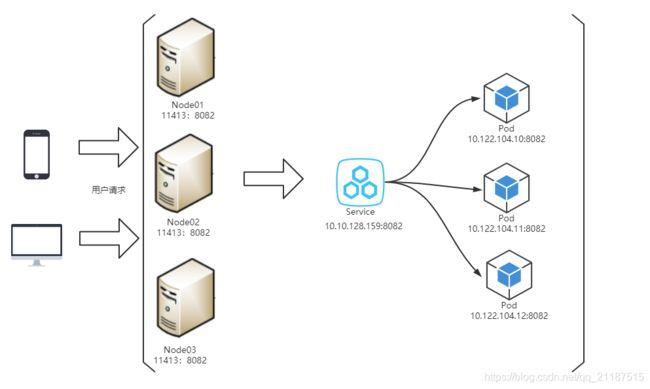
#服务访问之 IP & Port & Endpoint 辨析
`不同类型的IP
-Node IP:Node节点的IP地址。 节点物理网卡ip
-Pod IP:Pod的IP地址。 Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,同Service下的pod可以直接根据PodIP相互通信,不同Service下的pod在集群间pod通信要借助于 cluster ip,pod和集群外通信,要借助于node ip。
-Cluster IP:Service的IP地址。 属于Kubernetes集群内部的地址,无法在集群外部直接使用这个地址Service的IP地址,此为虚拟IP地址。外部网络无法ping通,只有kubernetes集群内部访问使用。通过命令 kubectl -n 命名空间 get Service 即可查询ClusterIP
Cluster IP是一个虚拟的IP,但更像是一个伪造的IP网络,原因有以下几点,仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配P地址,无法被ping,他没有一个“实体网络对象”来响应,只能结合Service Port组成一个具体的通信端口Endpoint,单独的Cluster IP不具备通信的基础,并且他们属于Kubernetes集群这样一个封闭的空间。在不同Service下的pod节点在集群间相互访问可以通过Cluster IP.
`不同类型的Port
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort // 有配置NodePort,外部流量可访问k8s中的服务
ports:
- port: 30080 // 服务访问端口,集群内部访问的端口
targetPort: 80 // pod控制器中定义的端口(应用访问的端口)
nodePort: 30001 // NodePort,外部客户端访问的端口
selector:
name: nginx-pod
-port
port是k8s集群内部访问service的端口(service暴露在Cluster IP上的端口),即通过clusterIP: port可以访问到某个service
-nodePort
nodePort是外部访问k8s集群中service的端口,通过nodeIP: nodePort可以从外部访问到某个service。
该端口号的范围是 kube-apiserver 的启动参数 –service-node-port-range指定的,在当前测试环境中其值是 30000-50000。表示只允许分配30000-50000之间的端口。比如外部用户要访问k8s集群中的一个Web应用,那么我们可以配置对应service的type=NodePort,nodePort=30001。其他用户就可以通过浏览器http://node:30001访问到该web服务。而数据库等服务可能不需要被外界访问,只需被内部服务访问即可,那么我们就不必设置service的NodePort
-TargetPort
targetPort 是pod的端口,从port和nodePort来的流量经过kube-proxy流入到后端pod的targetPort上,最后进入容器。
-containerPort
containerPort是pod内部容器的端口,targetPort映射到containerPort。
-hostPort
这是一种直接定义Pod网络的方式。hostPort是直接将容器的端口与所调度的节点上的端口路由,这样用户就可以通过宿主机的IP加上来访问Pod了
`Endpoint(Endpoint = Pod IP + Container Port)
创建Service的同时,会自动创建跟Service同名的Endpoints。
Endpoint 是k8s集群中一个资源对象,存储在etcd里面,用来记录一个service对应的所有pod的访问地址。service通过selector和pod建立关联。
Endpoint = Pod IP + Container Port
service配置selector endpoint controller 才会自动创建对应的endpoint 对象,否则是不会生产endpoint 对象
一个service由一组后端的pod组成,这些后端的pod通过service endpoint暴露出来,如果有一个新的pod创建创建出来,且pod的标签名称(label:pod)跟service里面的标签(label selector 的label)一致会自动加入到service的endpoints 里面,如果pod对象终止后,pod 会自动从edponts 中移除。在集群中任意节点 可以使用curl请求service <CLUSTER-IP>:<PORT>
-Endpoint Controller
Endpoint Controller是k8s集群控制器的其中一个组件,其功能如下:
负责生成和维护所有endpoint对象的控制器
负责监听service和对应pod的变化
监听到service被删除,则删除和该service同名的endpoint对象
监听到新的service被创建,则根据新建service信息获取相关pod列表,然后创建对应endpoint对象
监听到service被更新,则根据更新后的service信息获取相关pod列表,然后更新对应endpoint对象
监听到pod事件,则更新对应的service的endpoint对象,将podIp记录到endpoint中
定义 Endpoint
对于Service,我们还可以定义Endpoint,Endpoint 把Service和Pod动态地连接起来,Endpoint 的名称必须和服务的名称相匹配。
创建mysql-service.yaml
============================
apiVersion: v1
kind: Service
metadata:
name: mysql-production
spec:
ports:
- port: 3306
创建mysql-endpoints.yaml
============================
kind: Endpoints
apiVersion: v1
metadata:
name: mysql-production
namespace: default
subsets:
- addresses:
- ip: 192.168.1.25
ports:
- port: 3306
[root@k8s-master endpoint]# kubectl describe svc mysql-production
Name: mysql-production
Namespace: default
Labels: <none>
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP: 10.254.218.165
Port: <unset> 3306/TCP
Endpoints: 192.168.1.25:3306
Session Affinity: None
Events: <none>
-使用Endpoint引用外部服务
service 不仅可以代理pod, 还可以代理任意其它的后端(运行在k8s集群外部的服务,比如mysql mongodb)。如果需要从k8s里面链接外部服务(mysql),可定义同名的service和endpoint
在实际生成环境中,像mysql mongodb这种IO密集行应用,性能问题会显得非常突出,所以在实际应用中,一般不会把这种有状态的应用(mysql 等)放入k8s里面,而是使用单独的服务来部署,而像web这种无状态的应用更适合放在k8s里面 里面k8s的自动伸缩,和负载均衡,故障自动恢复 等强大功能
创建service (mongodb-service-exten)
=====================================
kind: Service
apiVersion: v1
metadata:
name: mongodb
namespace: name
spec:
ports:
- port: 30017
name: mongodb
targetPort: 30017
创建 endpoint(mongodb-endpoint)
==============================
kind: Endpoints
apiVersion: v1
metadata:
name: mongodb
namespace: tms-test
subsets:
- addresses:
- ip: xxx.xxx.xx.xxx
ports:
- port: 30017
name: mongod
可以看到service跟endpoint成功挂载一起了,表面外面服务成功挂载到k8s里面了,在应用中配置链接的地方使用mongodb://mongodb:30017 链接数据
#三种IP网络间的通信
service地址和pod地址在不同网段,service地址为虚拟地址,不配在pod上或主机上,外部访问时,先到Node节点网络,再转到service网络,最后代理给pod网络。
apiVersion: apps/v1 #API版本
kind: Deployment #副本控制器RC;想要创建的对象类别
metadata: #包含Pod的一些meta信息,比如名称、namespace、标签等信息。
labels: #标签
app: mysql
name: mysql
spec: #对象规约,指定资源内容(定义相关属性)
replicas: 3 #预期的副本数量
selector: #选择器
matchLabels: #匹配标签
app: mysql #对应上面的业务容器
template: #pod模板
metadata:
labels:
app: mysql
spec:
containers: #定义容器
- image: mysql:5.7 #使用镜像信息
name: mysql
ports:
- containerPort: 3306 #容器应用监听的端口号
env: #注入容器内的环境变量
- name: MYSQL_ROOT_PASSWORD
value: "123456"
Kubernetes
K8S将集群中的机器划分为一个Master和一些Node。在Master上运行着一些相关的进程:Kube-apiserver、kube-controller-manager和kube-scheduler,这些进程实现了整个集群的资源管理、pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,并且都是自动完成。Node作为集群中的工作节点,其上运行着真正的应用程序。在Node上,K8S管理的最小单元是Pod。在Node上运行着K8S的kubelet、kube-porxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启、销毁,以及实现软件模式的负载均衡。
----------------------------------------
Kubenetes命令
kubectl命令行的语法如下:
$ kubectl [command] [TYPE] [NAME] [flags]
含义如下:
1、command:子命令,用于操作资源对象,例如:create、get、deecribe、delete等
2、TYPE:资源对象类型,区分大小写,能以单数、复数或者简写形式表示。例如:kubectl get pod pod1
3、NAME:资源对象的名称,区分大小写。如不指定名称,系统则将返回属于TYPE的全部对象的列表
4、flags:kubectl子命令的可选参数,例如使用-s或--server设置API Server的URL地址,而不使用默认值
#查看所有子命令
$ kubectl --help
#查看子命令详细用法
$ kubectl cp --help
#列出kubectl可操作的资源对象
$ kubectl api-resources
#kubectl格式化输出
$ kubectl [command] [TYPE] [NAME] -o=<output_format>
例: -o json (以JSON格式显示结果)、 -o wide 输出额外信息 、 -o yaml 以YAML格式显示结果 、 自定义(下图)
#
kubectl格式化输出

#查看node
$ kubectl get node
#查看node详细信息(describe 显示详细信息)
$ kubectl describe node k8s-master
#创建pod
kubectl create命令可创建新资源。 因此,如果再次运行该命令,则会抛出错误,因为资源名称在名称空间中应该是唯一的。
$ kubectl create -f Pod-test.yaml
kubectl apply命令将配置应用于资源。 如果资源不在那里,那么它将被创建。 kubectl apply命令可以第二次运行(在只改动了yaml文件中的某些声明时,而不是全部改动,你可以使用kubectl apply)
$ kubectl apply -f mysql-deploy.yaml
#删除pod
$ kubectl delete -f Pod-test.yaml
#查看pod(-o wide显示更多信息)
$ kubectl get pods -o wide
#查看创建的deployment
$ kubectl get deploy
#查看pod创建时使用yaml文件内容
$ kubectl get pods mysql-596b96985c-p9fqf -n default -o yaml
#查看namespaces
$ kubectl get namespaces
#查看service
$ kubectl get svc mysql(svc name)
#查看可被访问的服务端点(Endpoint = Pod IP + Container Port)
$ kubectl get endpoints(简写ep也行)
#查看一个容器日志
$ kubectl logs myweb-5669769dbd-fvtxz(pod name)
#运行容器中的一个命令
$ kubectl exec myweb-5669769dbd-fvtxz(pod name) ls
#进入一个容器
$ kubectl exec -it mysql-596b96985c-p9fqf -- /bin/bash
#在线编辑运行中的资源对象
$ kubectl edit deploy nginx
#将pod的端口号映射到宿主机
$ kubectl port-forward --address 0.0.0.0 \
#在容器和Node之间复制文件
$ kubectl cp mysql-596b96985c-p9fqf:/etc/fatab /tmp
----------------------------------------
Kubenetes入门
《Kubernetes权威指南》第5版勘误:https://github.com/kubeguide/K8sDefinitiveGuide-V5-corrigendum
《Kubernetes权威指南》第5版源码:https://github.com/kubeguide/K8sDefinitiveGuide-V5-Sourcecode
应用类
Label与标签选择器(P23)
#label(标签)
常用示例:
版本标签、环境标签、架构标签、分区标签、质量管理标签
#selector(标签选择器)
分为:
基于等式的selector,例:name=wangwu:
基于集合的selector,例:name in (wangwu,lisi):
可以通过多个selector表达式的组合来实现复杂的条件选择,多个表达式之间用","进行分割,几个条件之间是"AND"的关系,例:name=wangwu,env!=lisi
Service的ClusterIP(P29)
#clusterIP
clusterIP地址仅用于K8S service这个对象,并由K8S管理和分配IP地址(来源于ClusterIP地址池),与Node和Master所在的物理网络完全无关。
#headless service
特殊的service--headless service,只要在service的定义中设置了clusterIP:None,就定义了一个headless service,它与普通的service的关键在于它没有clusterIP地址,如果解析headless service的DNS域名,则返回的是该service对应的全部Pod的Endpoint列表,意味着客户端是直接与后端Pod建立TCP/IP连接进行通信的,没有通过虚拟ClusterIP地址进行转发,因此通信性能最高,等同于“原生网络通信”。
Headless Service:该服务不会分配Cluster IP,也不通过kube-proxy做反向代理和负载均衡。而是通过DNS提供稳定的网络ID来访问,DNS会将headless service的后端直接解析为Pod IP列表。主要供StatefulSet使用。
#service 多端口
很多服务存在多个端口,k8s service 支持多个endpoint,在存在多个endpoint的情况下,要求每个endpoint都定义一个名称进行区分。
下面是tomcat多端口的service定义样例:
apiversion:v1
kind:Service
metadata:
name:tomcat-service
spec:
ports:
- port:8080
name:service-port
- port:8005
name:shutdown-port
selector:
tier:frontend
Service的外网访问服务(p32)
K8S的三种IP:(本文档前面有具体介绍)
Node Ip: 集群中每个节点的物理网卡的IP地址,是一个真实的物理网络;K8S集群外的节点访问K8S集群内的某个节点或TCP/IP服务时,都必须通过NodeIP通信。
Pod IP: 虚拟二层网络,K8S中一个Pod里的容器访问另一个Pod里的容器时,就是通过PodIP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量是通过Node IP所在的物理网卡流出的。
service IP: clusterIP 属于集群内IP, Nodeport解决集群外的应用访问集群内服务。
#同Service下的pod可以直接根据PodIP相互通信,不同Service下的pod在集群间pod通信要借助于 cluster ip,pod和集群外通信,要借助于node ip。
Nodeport的实现方式时,在K8S集群的每个Node上都为需要外部访问的Service开启一个对应的TCP监听端口,外部系统只需要访问任意一个Node的IP地址+NodePort端口号即可访问此服务,在任意Node上运行netstat命令,就可以看到有NodePort端口被监听。
有状态的应用集群(P35)
Deployment对象是用来实现无状态服务的多副本自动控制功能,那么有状态服务,如:zookeeper集群、Mysql高可用集群、Kafka集群等是怎么实现自动部署和管理的呢?
一开始是依赖`statefulset`解决的,但后来发现对于一些复杂的有状态的集群应用来说,`statefulset`还是不够用通用和强大,所以后面又出现了`K8S operator`。
IT世界里,有状态服务比作宠物,无状态服务比作牛羊;宠物需要去细心照料,无差别的牛羊则没有这样的待遇。
`总结一般有状态集群中有如下特性`:
·每个节点都有固定的身份ID,通过这个ID,集群中的成员可以相互发现并通信。
·集群的规模比较固定,集群规模不能随意改动。
·集群中每个节点都有状态,通常会持久化数据到永久存储中,每个节点在重启后都必须使用原有的持久化数据。
·集群中成员节点的启动顺序(以及关闭顺序)通常也是确定的。
·如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损。
#statefulset具有如下特性
·statefulset里的每个Pod都有稳定、唯一的网络标识,可以用来发现集群内的其他成员,假设statefulset的名称为kafka,那么第1个pod叫kafka-0,第2个叫kafka-1,以此类推。
·statefulset控制的Pod副本的启停顺序是受控的,操作第n个Pod时,前n-1个Pod已经是运行且准备好的状态。
·statefulset里的Pod采用稳定的持久化存储卷,通过PV或PVC来实现,删除Pod时默认不会删除与statefulseti相关度存储卷。
statefulset除了要和PV卷捆绑使用,以存储Pod的状态数据,还要与Headless service配合使用,即在每个statefulset定义中都要声明它属于哪个headless service。statefulset在headless service的基础上又为seatefulset控制的每个Pod实例都创建了一个DNS域名,域名格式:`$(podname).$(headless service name)` 例如:kafka-2.kafka
#operator
statefulset的建模能力有限,面对复杂的有状态集群时显得力不从心,所以就有了后来的K8S operator框架和众多的operator实现了。需要注意的是,K8S operator框架并不是面向普通用户的,而是`面向K8S平台开发者`的。平台开发者借助operator框架提供的API,可以方便的开发一个类似statefulset的控制器,更好的实现自动化部署和智能运维功能。
批处理应用(P37)
#job、cronjob
除了无状态服务、有状态服务,常见的还有批处理应用,特地是一个或多个进程处理一组数据(图像、文件、视频等),这组数据处理完成后,批处理任务自动结束。为了支持这类应用,K8S引入了新的资源对象——job。
job控制器提供了两个控制并发数的参数,`completions`和`parallelism`,`completions`表示需要运行任务数的总数,`parallelism`表示并发运行的个数。例如设置parallelism为1,则会依次运行任务,在前面的任务运行后再运行后面的任务。当Job所控制的Pod副本是短暂运行的,可以将其视为一组容器,其中的每个容器都仅运行一次。当Job控制的所有Pod副本都运行结束时,对应的Job也就结束了。Job生成的Pod副本是不能自动重启的,对应Pod副本的restartpolicy(重启策略)都被设置成为Never。
K8S还增加了cronjob,可以周期性的执行某个任务。
应用的配置问题(P37)
通过前面的学习,初步了解三种应用建模的资源对象,总结如下:
·无状态服务的建模:Deployment
·有状态服务的建模:Statefulset
·批处理应用的建模:Job
在进行应用建模时,应该如何解决应用需要在不同的环境中修改配置的问题呢?这就涉及到Configmap和secret两个对象。
configmap顾名思义,就是保存配置项(key=value)的一个map,是分布式系统中“配置中心”的独特实现之一。
#具体实现方式:(图1.13)
·用户将配置文件的内容保存到configmap中,文件名可作为key,value就是整个文件的内容,多个配置文件都可以放入同一configmap。
·在建模用户应用时,在Pod里将configmap定义为特殊的volume进行挂载。在Pod被调度到某个具体的Node上时,configmap里的配置文件会被自动还原到本地的目录下,然后映射到Pod里指定的配置目录下,这样用户的程序就可以无感知的读取配置了。
·在configmap的内容发生修改后,K8S会自动获取configmap的内容并在目标节点上更新对应的文件。
、
#secret
解决敏感信息的配置问题,比如数据库的用户名和密码、应用的数字证书、token、ssh秘钥等。对于这类敏感信息,我们可以创建一个secret对象,然后被Pod引用。
应用的运维问题(P39)
HPA,Pod的横向自动扩容,即自动控制Pod数量的增加或减少。
VPA,即垂直Pod自动扩缩容,它根据容器资源使用率自动推测并设置Pod合理的CPU和内存的需求指标,从而更加精确的调度Pod。
存储类
存储类的资源对象主要包括volume、persistent volume、PVC和StorageClass。
Volume(P40)
volume是Pod中能够被多个容器访问的共享目录。K8S中的volume被定义在Pod上,被一个Pod里的多个容器挂载到具体的文件目录下。
#常见类型:
1.emptyDir
一个emptydir是在Pod分配到Node时创建的。一些用途如下:
·临时空间,例如用于某些应用程序运行时所需的临时目录,且无需永久保留。
·长时间任务执行过程和中使用的临时目录。
·一个容器需要从另一个容器中获取数据的目录(多容器共享目录)。
在默认情况下,emptydir使用的是节点的存储介质。
2.hostPath
hostpath为在Pod上挂载宿主机上的文件或目录,通常可以用于以下几方面。
·在容器应用程序生成的日志文件需要永久保存时,可以使用宿主机的高速文件系统对其进行存储。
·需要访问宿主机上Docker引擎内部数据结构的容器应用时,可以通过定义hostpath为宿主机/var/lib/docker目录,使容器内部的应用可以直接访问Docker的文件系统。
3.公有云volume
如:谷歌公有云提供的GCEPersistentDisk、亚马逊公有云提供的AWS ESB等。
4.其他类型的Volume
·iscsi:将iSCSI存储设备上的目录挂载到Pod中。
·nfs:将NFS server上的目录挂载到Pod中。
·glusterfs:将开源GlusterFS网络文件系统的目录挂载到Pod中。
动态存储管理(P42)
volume属于静态管理的存储,即我们需要事先定义每个Volume,然后将其挂载到Pod中去,存在很多弊端。所以K8S后面就发展了存储动态化的新机制,来实现存储的自动化管理。相关的核心对象有三个:PV、storageclass、PVC。
`PV`表示由系统动态创建的一个存储卷,PV独立于Pod之外。
`storageclass`用来描述和定义某种存储系统的特征。storageclass有几个关键属性,其中`provisioner`代表了创建PV的第三方存储插件,`parameters`是创建PV时的必要参数,`reclaimPolicy`则表明了PV回收策略(回收策略包括删除或保留)。
`PVC`,表示应用需要申请的PV规格,其中重要的属性包括`accessModes(存储访问模式)`,`storageclassName(用哪种storageClass来实现动态创建)`及`resources(存储的具体规格)`。
#有了以storageClass与PVC为基础的动态PV管理机制,我们就很容易管理和使用Volume了,只需要在Pod里引用PVC即可达到目的。
安全类
从本质上来说,K8S可被看作是一个多用户共享资源的资源管理系统,这里的资源主要是各种K8S里的个资源对象。
#Role、ClusterRole
局限于某个命名空间的角色由`Role`对象定义,作用于整个K8S集群范围内的角色则通过`ClusterRole`对象定义。
----------------------------------------
Kubenetes安装配置指南
使用kubeadm工具快速安装K8S集群(P49)(略)
以二进制文件方式安装K8S安全高可用集群
在正式环境中应确保 Master 的高可用,并启用安全访问机制,至少包括以下几方面:
·Master的 kube-apiserver、kube-controller-manager和kube-scheduler 服务至少以3个节点的多实例方式部署
·Master启用基于CA认证的HTTPS安全机制
·etcd至少以3个节点的集群模式部署
·etcd集群启用基于CA认证的HTTPS安全机制
·Master启用RBAC模式授权
Master的高可用部署架构图如下:
使用HAProxy和Keeplived部署高可用负载均衡器:
#1、部署安全的etcd的高可用集群
`etcd`作为K8S集群的主数据库,在安全K8S各服务之前需要`首先安装和启动`。
#2、部署安全的K8S Mster 高可用集群
在K8S的Master节点上需要部署的服务包括 etcd、kube-apiserver、kube-controller-manager和kube-scheduler
#3、部署Node服务
在Node上需要部署Docker、kubelet、kube-proxy,在成功加入K8S集群后,还需要部署CNI网络插件、DNS插件等管理组件
kube-apiserver基于token的认证机制
K8S除了提供基于CA证书的认证方式,也提供了基于`HTTP Token`的简单认证方式。各客户端组件与API server之间的通信方式仍然采用HTTPS,但不采用CA数字认证。这种认证机制与CA证书相比,安全性很低,在生产环境`不建议使用`。
Kubenetes的版本升级
在K8S的版本升级之前,需要考虑不中断正在运行的业务容器的灰度升级方案。常见的做法是:先更新Master上的K8S服务的版本,再逐个或批量更新集群中的Node上的K8S服务的版本。更新Node上的K8S的服务步骤通常包括:先隔离一个或多个Node的业务流量,等待这些Node上运行的Pod将当前任务全部执行完成后,听到业务应用(Pod),在更新这些Node上的kubelet和kube-proxy版本,更新完成后重启业务应用(Pod),并将业务流量导入新启动的这些Node上,在隔离剩余的Node,逐步完成Node的版本升级,最终完成整个集群的K8S版本升级。
同时,应该考虑高版本呢的Master对低版本的Node的兼容性问题。高版本的Master通常可以管理低版本的Node,但版本差异不应过大,一面某些功能或API版本被弃用后,低版本的Node无法运行。
· 通过官网获取最新版本的二进制包Kubenetes.tar.gz,解压后提取服务的二进制文件。
· 更新Master的kube-apiserver、kube-controller-manager和kube-scheduler 服务的二进制文件和相关配置(在需要修改是更新)并重启服务。
· 逐个或批量隔离Node,等待其上运行的全部容器工作完成后停掉Pod,更新kubelet、kube-proxy服务文件和相关配置(在需要修改时更新)然后重启服务。
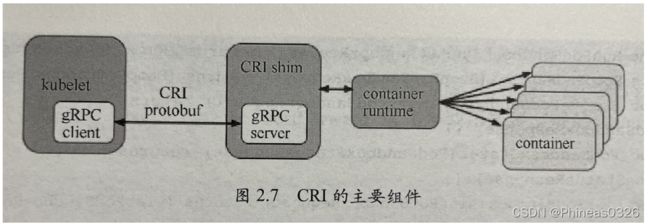
CRI(容器运行时接口)详解(P94)
归根结底,K8S Node(kubelet)的主要功能就是启动和停止容器的组件,我们称之为容器运行时,其中最知名的就是Docker了。为了更具扩展性,K8S从1.5版本开始就加入了容器运行时的插件API,即`CRI`
kubelet使用gRPC框架通过 UNIX Socket 与容器运行时(或CRI代理)进行通信。在这个过程中kubulet是客户端,CRI代理(shim)是服务端,如图2.7所示。
Protocol Buffers API 包含两个gRPC服务:ImageService和RuntimeService
·ImageService 提供了从仓库中拉取镜像、查看和移除镜像的功能
·RuntimeService 负责Pod和容器的生命周期管理,以及与容器的交互(exec/attach/port-forward)
#何为容器运行时
容器运行时顾名思义就是要掌控容器运行的整个生命周期,以 docker 为例,其作为一个整体的系统,主要提供的功能如下:
- 制定容器镜像格式
- 构建容器镜像 `docker build`
- 管理容器镜像 `docker images`
- 管理容器实例 `docker ps`
- 运行容器 `docker run`
- 实现容器镜像共享 `docker pull/push`
#RPC
RPC(Remote Procedure Call)远程过程调用,是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议,简单的理解是`一个节点请求另一个节点提供的服务`。RPC只是一套协议,基于这套协议规范来实现的框架都可以称为 RPC 框架,比较典型的有 Dubbo、Thrift 和 gRPC。
----------------------------------------
3.深入掌握POD(P113)
对Pod定义文件模板中个属性的详细说明(部分)
Pod可以由1个或多个容器组合而成,属于同一个Pod的多个容器应用之间互相访问时仅需通过localhost就可以通信。
3.3 静态Pod
#静态Pod
静态Pod是由kubelet进行管理的仅存在与特定的Node上的Pod。它们不能通过API server进行管理。
创建静态Pod有两种方式:配置文件方式和HTTP方式
1、配置文件方式
首先,需要设置kubelet的启动参数“--pod-manifest-path”(或者在kubelet配置文件中设置staticPodPath,这也是新版本推荐的设置方式,--pod-manifest-path参数将被逐渐弃用),指定kubelet需要监控的配置文件所在的目录,kubelet会定期扫描该目录,并根据该目录下的.yaml或.json文件进行创建。
假设配置目录为/etc/kubelet.d/,配置启动参数为--pod-manifest-path=/etc/kubelet.d/,然后重启ubelet服务。
删除该Pod时,只能到其所在Node上将其定义文件目录下删除。
2、HTTP方式
通过设置kubelet的启动参数“--manifest-url”,kubelet将会定期从改URL地址下载Pod的定义文件,并以.yaml或.json文件的格式进行解析,然后创建Pod。其实现方式与配置文件方式是一致的。
3.5 Pod的配置管理
#Pod的配置管理
#configmap
configmap供容器使用的典型用法如下:
1.生成容器内的环境变量
2.设置容器启动命令的启动参数(需设置为环境变量)
3.以volume的形式挂载为容器内部的文件或目录
configmap以一个或多个key:value的形式保存在K8S系统中供应用使用,既可以用于表示一个变量的值(例如 apploglevel=info),也可以用于表示一个完整配置文件的内容(例如server.xml=<?xml...>...)。
`创建configmap资源对象`
1.通过YAML文件方式创建
2.通过kubectl命令行方式创建
直接通过kubectl create configmap 也可以创建configmap,可以使用参数--from-file或--from-literal 指定内容,并且可以在一行命令中指定多个参数。
1)通过--from-file参数从文件进行创建,可以指定Key的名称,也可以在一个命令行中创建包含多个key的configmap,语法如下:
$ kubectl create configmap NAME --from-file=[key=]source --from-file=[key=]source
2)通过--from-file参数在目录下进行创建,该目录下的每个配置文件名都被设置key,文件的内容被设置为value,语法如下:
$ kubectl create configmap NAME --from-file=config-files-dir
3)使用--from-literal 时会从文本中进行创建,直接将指定的key#=value#创建为configmap的内容,语法如下:
$ kubectl create configmap NMAE --from-literal=key1=value1 --from-literal=key2=value2
举例如下:
#在POD中使用configmap
`通过环境变量方式使用configmap`
apiVersion: apps/v1
kind: Pod
metadata:
name: cm-test-pod
spec:
containers:
- name: cm-test
image: busybox
command: [ "/bin/sh", "-c", "env | grep APP" ]
#command就是将命令在创建的容器中执行,有这些命令去完成一些工作,command用法和dockerfile中的cmd差不多, command可以单独写,也可以分成command和参数args(sh -c 后面接的内容看成一个完整的shell脚本命令。)
env:
- name: APPLOGLEVEL #定义环境变量的名称
valueform: #key“apploglevel”对应的值
configMapKeyRef:
name: cm-appvars #环境变量的值取值cm-appvars:
key: apploglevel #key为apploglevel
K8S从1.6版本开始引入了一个新的字段envFrom,实现了在Pod环境中将configmap(也可用于secret资源对象)中所有定义的 key=value自动生成为环境变量:
apiVersion: apps/v1
kind: Pod
metadata:
name: cm-test-pod
spec:
containers:
- name: cm-test
image: busybox
command: [ "/bin/sh", "-c", "env" ]
envFrom:
- configMapRef
name:cm-appvars #根据cm-appvars中的key=value自动生成环境变量
`通过volumeMount使用configmap`
在pod “cm-test-app”的定义中,将configmap “cm-appconfigfiles”中的内容以文件的形式挂载到容器内部的/configfiles 目录下。Pod配置文件 cm-test-app.yaml的内容如下:
(configmap中定义了key-serverxml和key-loggingproperties)
apiVersion: v1
kind: Pod
metadata:
name: cm-test-app
spec:
containers:
- name: cm-test-app
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
volumeMounts:
- name: serverxml #引用volume的名称
mountPath: /configfiles #挂载到容器内的目录
volumes:
- name: serverxml #定义volume的名称
configMap:
name: cm-appconfigfiles #使用comfigmap “cm-appconfigfiles”
items: #假如不想以key名作为配置文件名可以引入items 字段,在其中逐个指定要用相对路径path替换的key:
- key: key-serverxml #key=key-serverxml
path: server.xml #value将server.xml 文件名进行挂载
- key: key-loggingproperties #key=key-loggingproperties
path: logging.properties #value将logging.properties 文件名进行挂载
`使用configmap的限制条件`
使用configamp的限制条件如下:
·configmap必须在Pod之前创建,Pod才能引用它。
·如果Pod使用envFrom 基于configmap定义环境,则无效的环境变量名称(例如名称以数字开头)将被忽略,并在事件中被记录为InvalidVariableNmaes。
·configmap 受命令空间限制,只有处于相同命名空间中的Pod才可以引用它。
·configmap无法用于静态Pod
3.6 在容器内获取POD信息(Downward API)
#在容器内获取POD信息(将 POD 的信息注入到容器内部):Downward API
我们知道,Pod的逻辑概念在容器之上,K8S在成功创建Pod后,会为Pod和容器设置一些额外信息,例如Pod级别的Pod名称、Pod IP、Node IP、label容器级别的限制资源等。在很多应用场景下,这些信息对容器内的应用来说都很有用,例如使用Pod名称作为日志记录的一个字段用于标识日志来源。为了在容器内获取Pod级别的这些信息,K8S提供了Downward API机制。
Downward API提供了两种方式用于将 POD 的信息注入到容器内部:
·环境变量:用于单个变量,可以将 POD 信息和容器信息直接注入容器内部。
·Volume挂载:将 POD 信息生成为文件,直接挂载到容器内部中去。

3.7 Pod生命周期和重启策略
# Pod生命周期和重启策略(RestartPolicy)
`Pod的状态`
Pending API Server已经创建该Pod,但在Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
Runnung Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
Succeeded Pod内所有容器均成功执行后退出,且不会再重启。
Failed Pod内所有容器均已退出,但至少有一个容器退出为失败状态。
Unknown 由于某种原因无法获取该Pod的状态,可能由于网络通信不畅导致。
`Pod的重启策略`
Always:当容器失效时,由kubelet自动重启该容器
OnFailure:当容器中止运行且退出码不为0时,由kubelet自动重启该容器
Never:不论容器运行状态如何,kubelet都不会重启该容器
`每种控制器对Pod重启策略要求如下`
·RC和DaemonSet:必须设置为Always,需要保证该容器持续运行
·Job:OnFailure或Never,确保容器执行完成后不再重启
·kubelet:在Pod失效时自动重启它,不论将RestartPolicy设置为什么值,也不会对Pod进行健康检查
3.8 Pod健康检查和服务可用性检查
# Pod健康检查和服务可用性检查
K8S对Pod的健康状态可以通过三类探针来检查:LivenessProbe、ReadinessProbe及StartupProbe,其中最主要的探针为LivenessProbe与ReadinessProbe,kubelet会定期执行这两类探针来诊断容器的健康状况。
(1)`LivenessProbe探针`:用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。
(2)`ReadinessProbe探针`:用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod才可以接收请求。对于被Service管理的 Pod,Service与Pod Endpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service 的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回 后端Endpoint列表。
(3)`StartupProbe探针`:某些应用会遇到启动比较慢的情况,此时ReadinessProbe就不适用了,因为这属于“有且仅有一次”的超长延时,可以通过StartupProbe探针解决该问题。
`以上探针均可配置以下三种实现方式`
·ExecAction:在容器内执行一个命令,如果该命令的返回码为0,则表明容器健康。
·TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康。
·HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTPGet方法,如果响应码大于200且小于400,则认为容器健康。
-----------------------------
例:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: gcr.io/google_containers/busybox
args:
- /bin/sh
- -c
- echo ok > /tmp/health; sleep 10; rm -rf /tmp/health; sleep 600 #pod创建运行后,文件10s后删除导致首次健康检查的时候没有探测到,容器会被杀掉并重启,如此往复。
livenessProbe:
exec:
command:
- cat
- /tmp/health
initialDelaySeconds: 15 #启动容器后进行首次健康检查的等待时间,单位为s。
timeoutSeconds: 1 #健康检查发送请求后等待响应的超时时间,单位为s。如果超时则kubelet会重启容器。
对于每种探测方式都需要设置initialDelaySeconds、timeoutSeconds 两个参数,含义如下:
initialDelaySeconds:启动容器后进行首次健康检查的等待时间,单位为s。
timeoutSeconds:健康检查发送请求后等待响应的超时时间,单位为s。如果超时则kubelet会重启容器。
------------------------------
`Pod Readiness Gates`
Kubernetes的ReadinessProbe机制可能无法满足某些复杂应用对容器内服务可用状态的判断。
所以Kubernetes从1.11版本开始,引入Pod Ready++特性对Readiness探测机制进行扩展,
在1.14版本时达到GA稳定版,称其为Pod Readiness Gates。
通过Pod Readiness Gates机制,用户可以将自定义的ReadinessProbe探测方式设置在Pod上,
辅助Kubernetes设置Pod何时达到服务可用状态(Ready)。
为了使自定义的ReadinessProbe生效,用户需要提供一个外部的控制器(Controller)来设置相应的Condition状态。
3.9 玩转Pod调度
#玩转Pod调度
最早期只有一个Pod副本控制器RC(ReplicationController)它的标签选择器只能选择一个标签,新一代的ReplicaSet增强了RC标签选择器的灵活性,拥有集合式的标签选择器,可以选择多个Pod标签。c
与RC不同,ReplicaSet被设计成能控制多个不同标签的Pod副本,比如,应用MyApp目前发布了v1与v2两个版本,用户希望MyApp的Pod的副本数保持为3个,可以同时包含v1和v2版本的Pod,就可以用ReplicaSet来实现这种控制,写法如下:
selector:
matchLabels:
version: v2
matchExpressions:
- {key: version,operator: In, values [v1,v2]}
#Deployment或RC:全自动调度
Deployment或RC的主要功能之一就是自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本数量。
下面是一个Deployment配置的例子:使用这个配置文件可以创建一个ReplicaSet,这个ReplicaSet会创建3个Nginx应用的Pod:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
#NodeSelector:定向调度
K8S Master上的Scheduler服务(kube-scheduler进程)负责实现Pod的调度,整个调度通过执行一系列的复杂的算法,最终为每个Pod都计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道Pod最终会被调度到哪个节点上。在实际情况下,也可能需要将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配,来达到上述目的。
(1) 首先通过kubectl label命令给目标Node打上一些标签:
kubectl label nodes -name> -key>=-value>
这里为k8s-node-1节点打上一个zone=north标签,表明它是一个“北方”的节点
$ kubectl label nodes k8s-node-1 zone=north
(2) 然后,在Pod的定义中加上nodeSelector的设置,以redis-master-controller.yaml为例:
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
nodeSelector: #这里
zone: north #这里
运行kubectl create -f 命令创建Pod,scheduler就会将Pod调度到拥有“zone=north”标签的Node上。如果有多个相同标签(例如zone=north),则scheduler会根据调度算法从这组Node中挑选一个可用的Node进行Pod调度。
#NodeAffinity:Node亲和性调度
NodeAffinity 意为 Node 亲和性的调度策略,是用于替换 NodeSelector 的全新调度策略。目前有两种节点亲和性表达。
·RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上(功能和nodeSelector很像,但是使用的是不同的语法),相当于硬限制。
·PreferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制。多个优先级规则可以设置权重(weight)值,以定义执行的先后顺序。
IgnoredDuringExecution 的意思是:如果一个Pod所在的阶段在Pod运行期间标签发生了改变,不再符合该Pod的节点亲和性需求,则系统将忽略Node上label的变化,该Pod还能继续在该节点上运行。
RequiredDuringSchedulingIgnoredDuringExecution:要求只运行在amd64的节点上
PreferredDuringSchedulingIgnoredDuringExecution:要求尽量运行在磁盘类型为ssd的节点上
代码如下:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #匹配表达式
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions: #匹配表达式
- key: disk-type
operator: In
values:
- ssd
containers:
- name: with-node-affinity
image: gcr.io/google_containers/pause:2.0
从上面的配置中可以看到In操作符,NodeAffinity 语法支持的操作符包括 In、NotIn、Exists、DoesNotExist、Gt、Lt。虽然没有节点排斥功能,但是NotIn和DoesNotExist就可以实现排斥的功能了。
#PodAffinity:Pod亲和与互斥调度原则
在实际的生产环境中有一类特殊的Pod调度需求:存在某些相互依赖、频繁调用的Pod,它们需要被尽可能地部署在同一个Node节点、机架、机房、网段或者区域(zone)内,这就是Pod之间的亲和性;反之,出于避免竞争或者容错的需求,我们也可能使某些Pod尽可能地远离某些特定的Pod,这就是Pod之间的反亲和性或者互斥性。
简单来说亲和性和反亲和性调度就是相关联的两种或多种Pod是否可以在同一个拓扑域中共存或者共斥。
什么是拓扑域?一个拓扑域由一些Node节点组成,这些Node节点通常有相同的地理空间坐标,例如在同一个机架、机房或地区,我们一般用region表示机架、机房等拓扑区域,用Zone表示地区这样跨度更大的拓扑区域。
为此,K8S内置了如下一些常用的默认拓扑域:
·kubernetes.io/hostname;
·topology.kubernetes.io/region;
·topology.kubernetes.io/zone;
具体做法就是通过在Pod的定义上增加topologyKey属性。和节点亲和相同,Pod亲和与互斥的条件设置也是requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution。Pod的亲和性被定义于PodSpec的affinity字段下的podAffinity子字段中。Pod间的互斥性则被定义于同一层次的podAntiAffinity子字段中。
参照目标Pod:首先创建一个名为pod-flag的Pod,带有标签 security=S1 和 app=nginx 。
apiVersion: v1
kind: Pod
metadata:
name: pod-flag
labels:
security: "S1"
app: "nginx"
spec:
containers:
- name: nginx
image: nginx
Pod的亲和性调度:这里定义的亲和标签是 “security:S1” 对应上面的 Pod “pod-flag” ,topologyKey 的值被设置为“kubernetes.io/hostname”
apiVersion: v1
kind: Pod
metadata:
name: pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: gcr.io/google_containers/pause:2.0
Pod的互斥性调度:我们不希望它与目标Pod运行在同一个Node上,这里要求新的Pod与 security=S1 的Pod为同一个 zone,但是不与 app=nginx 的Pod为同一个node。
apiVersion: v1
kind: Pod
metadata:
name: anti-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
containers:
- name: anti-affinity
image: gcr.io/google_containers/pause:2.0
与节点亲和性类似,Pod亲和性的操作符也包括 In、NotIn、Exists、DoesNotExist、Gt、Lt。
#Taints 和 Tolerations (污点和容忍)
前面介绍的 NodeAffinity 节点亲和性,使得Pod能够被调度到某些Node上运行。Taint 则恰好相反如果一个节点标记为 Taints ,除非 pod 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度 pod。简单的说,被标记为Taint的节点就是存在问题的节点,当并非故障节点,当仍需要将某些Pod调度到这些节点时,可以通过使用 Tolerations 属性来实现。
可以使用kubectl taint命令为Node设置taint信息:
$ kubectl taint nodes node1 key=value:NoSchedule
这设置为node1加上了一个Taint。该Taint的键为key,值为value,Taint的效果时NoSchedule。这意味着除非Pod声明可以容忍这个Taint,否则不会被调度到node1上。
然后,需要在 Pod 上声明 Tolerations。下面两个 Tolerations 都被设置为可以容忍(Tolerate)具有该 Taint 的 Node,使得Pod能够被调度到 node1 上。
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
或
tolerations:
- key: "key"
operator: "Exists"
effect: "NoSchedule"
Pod 的 Tolerations 声明中的 key 和 effect 需要和 Taint 的设置保持一致,并且满足一下条件之一。
· operator 的值是 Exists (无需指定 value)。
· operator 的值是 Equal 并且 value 相等。
另外有两个特例:
· 空的 key 配合 Exists 操作符能够匹配所有键和值。
· 空的 effect 匹配所有 effect。
effect:
NoSchedule:K8Snode添加这个effecf类型污点,新的不能容忍的pod不能再调度过来,但是老的运行在node上不受影响
NoExecute:K8Snode添加这个effecf类型污点,新的不能容忍的pod不能调度过来,老的pod也会被驱逐
PreferNoSchedule:pod会尝试将pod分配到该节点
一般来说,如果给Node 加上 effect=NoExecute 的 Taint ,那么在该Node上正在运行的所有无对应 Tolerations 的 Pod 都会被立刻驱逐,不过系统允许给具有NoExecute 效果的 Tolerations 加入一个可选大的 tolerationSeconds 字段,这个设置表明 Pod 可以在 Taint 添加到 Node之后 还能在这个 Node 上运行多久(单位为s)
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
tolerationSeconds: 3600
#Pod Priority Preemption:Pod 优先级调度
对于运行各种负载 (如 Service 、Job) 的中等规模或者大规模的集群来说,出于各种原因,我们需要尽可能提高集群的资源利用率。 而提高资源利用率的常规做法时采用优先级方案,即不同类型的负载对应不同的优级,同时允许集群中的所有负载所需的资源总量超过集群可提供的资源,在这种情况下,当发生资源不足的情况时,系统可以选择释放一些不重要的负载 (优先级最低的),保障最重要的负载能够获取足够的资源稳定运行。
如何声明一个负载相对其他负载“更重要”? 我们可以通过下列几个维度来定义:
· Priority:优先级
· Qos:服务质量等级
优先级抢占调度策略的和兴行为分别是驱逐(Eviction)与抢占(Preemtion),这两种行为的使用场景不同,效果相同。 Eviction 是 kubelet 进程的行为,即当一个Node 发生资源不足 (under resource pressure) 的情况时,该节点上的 kubelet 进程会执行驱逐动作,此时 Kubelet 会综合考虑 Pod 的优先级、资源申请量与实际使用量等信息来计算那些 Pod 需要驱逐; 当同样优先级的 Pod 需要被驱逐时,实际使用的资源量超过申请量最大倍数的高耗能 Pod 会被首先驱逐。对于 Qos 等级为 “Best Effort” 的 Pod 来说, 由于没有定义资源申请(CPU/Memory Request),所以他们实际使用的资源可能非常大。 Preemption 则是 Scheduler 执行的行为,当一个新的 Pod 因为资源无法满足而不能被调度时,Scheduler 可能 (有权决定)选择驱逐部分低优先级的 Pod 实例来满足此 Pod 的调度目标,这就是 Preemption 机制。
Pod 优先级调度实例如下:
首先,由集群管理员创建PriorityClasses,PriorityClass不属于任何命名空间:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
上述YAML文件定义了一个名为high-priority的优先级类别,优先级为100000,数字越大,优先级越高,超过一亿的数字被系统保留,用于指派给系统组件。
我们可以在任意Pod中引用上述Pod优先级类别:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
优先级抢占的调度方式可能会导致调度陷入“死循环”状态。
当Kubernetes集群配置了多个调度器(Scheduler)时,这一行为可能就会发生,比如下面这个例子:
Scheduler A为了调度一个(批)Pod,特地驱逐了一些Pod,因此在集群中有了空余的空间可以用来调度,此时Scheduler B恰好抢在Scheduler A之前调度了一个新的Pod,消耗了相应的资源,因此,当Scheduler A清理完资源后正式发起Pod的调度时,却发现资源不足,被目标节点的kubelet进程拒绝了调度请求!这种情况的确无解.
因此最好的做法是让多个Scheduler相互协作来共同实现一个目标。
最后要指出一点:使用优先级抢占的调度策略可能会导致某些Pod永远无法被成功调度。
优先级调度不但增加了系统的复杂性,还可能带来额外不稳定的因素。
一旦发生资源紧张的局面,首先要考虑的是集群扩容,如果无法扩容,则再考虑有监管的优先级调度特性,比如结合基于Namespace的资源配额限制来约束任意优先级抢占行为。
# DaemonSet: 在每个 Node 上都运行一个 Pod
用于管理在集群中的每个Node上运行一份Pod的副本示例 如图3.3
这种用法适合用于这种需求的应用:
· 运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph。
· 在每个 Node 上运行日志收集 daemon,例如filebeat、logstash。
· 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、collectd、Datadog 代理、Zabbix Agent。
DaemonSet 的 Pod 调度策略与 RC 类似,除了可以使用系统内置的算法在每个 Node 上进行调度,也可以在 Pod 的定义中使用 NodeSelector 或 NodeAffinity 来指定满足条件的 Node 范围进行调度。
下面的例子定义了为每个 Node 上都启动一个 fluentd 容器,配置文件 fluentd-ds.yaml 的内容如下,其中挂载了物理机的两个目录 “/var/log” 和 “/var/lib/docker/containers” :
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-cloud-logging
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
selector:
matchLabels:
k8s-app: fluentd-cloud-logging
template:
metadata:
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
containers:
- name: fluentd-cloud-logging
image: gcr.io/google_containers/fluentd-elasticsearch:1.17
resources:
limits:
cpu: 100m
memory: 200Mi
env:
- name: FLUENTD_ARGS
value: -q
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: false
- name: containers
mountPath: /var/lib/docker/containers
readOnly: false
volumes:
- name: containers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
# Job:批处理调度
批处理任务通常并行(或串行)启动多个计算进程去处理一批工作项(Work item),处理完成后,整个批处理任务结束。按照批处理任务实现方式的不同,批处理任务可以分为如图 3.4 所示的几种模式。
· Job Template Expansion模式:一个Job对象对应一个待处理的Work item,有几个Work item就产生几个独立的Job,通常适合Work item数量少、每个Work item要处理的数据量比较大的场景,比如有一个100GB的文件作为一个Work item,总共有10个文件需要处理。
· Queue with Pod Per Work Item模式:采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,在这种模式下,Job会启动N个Pod,每个Pod都对应一个Work item。
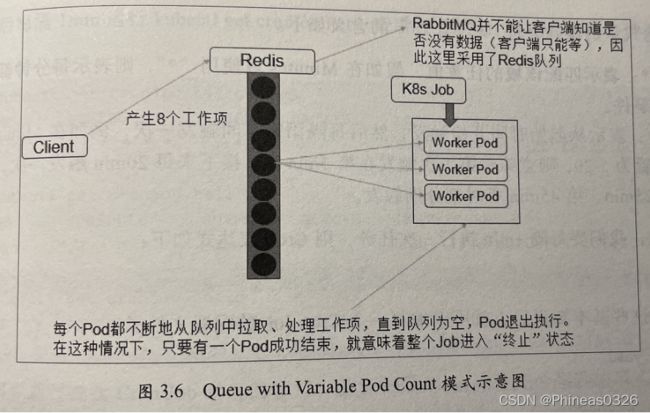
· Queue with Variable Pod Count模式:也是采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,但与上面的模式不同,Job启动的Pod数量是可变的。
还有一种被称为Single Job with Static Work Assignment的模式,也是一个Job产生多个Pod,但它采用程序静态方式分配任务项,而不是采用队列模式进行动态分配。
如表 3.4 所示是这几种模式的一个对比
考虑到批处理的并行问题,Kubernetes将Job分以下三种类型。
1.Non-parallel Jobs:通常一个Job只启动一个Pod,除非Pod异常,才会重启该Pod,一旦此Pod正常结束,Job将结束。
2.Parallel Jobs with a fixed completion count:并行Job会启动多个Pod,此时需要设定Job的.spec.completions参数为一个正数,当正常结束的Pod数量达至此参数设定的值后,Job结束。此外,Job的.spec.parallelism参数用来控制并行度,即同时启动几个Job来处理Work Item。
3.Parallel Jobs with a work queue:任务队列方式的并行Job需要一个独立的Queue,Work item都在一个Queue中存放,不能设置Job的.spec.completions参数,此时Job有以下特性。
·每个Pod都能独立判断和决定是否还有任务项需要处理。
·如果某个Pod正常结束,则Job不会再启动新的Pod。
·如果一个Pod成功结束,则此时应该不存在其他Pod还在工作的情况,它们应该都处于即将结束、退出的状态。
·如果所有Pod都结束了,且至少有一个Pod成功结束,则整个Job成功结束。
例:
首先是Job Template Expansion模式,由于在这种模式下每个Work item对应一个Job实例,所以这种模式首先定义一个Job模板,模板里的主要参数是Work item的标识,因为每个Job都处理不同的Work item。如下所示的Job模板(文件名为job.yaml.txt)中的$ITEM可以作为任务项的标识:
apiVersion: batch/v1
kind: Job
metadata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox
command: ["sh", "-c", "echo Processing item $ITEM && sleep 5"]
restartPolicy: Never
其次,我们看看Queue with Pod Per Work Item模式,在这种模式下需要一个任务队列存放Work item,比如RabbitMQ,客户端程序先把要处理的任务变成Work item放入任务队列,然后编写Worker程序、打包镜像并定义成为Job中的Work Pod。Worker程序的实现逻辑是从任务队列中拉取一个Work item并处理,在处理完成后即结束进程。并行度为2的Demo示意图如图 3.5 所示。
最后,我们看看Queue with Variable Pod Count模式,如图 3.6 所示。由于这种模式下,Worker程序需要知道队列中是否还有等待处理的Work item,如果有就取出来处理,否则就认为所有工作完成并结束进程,所以任务队列通常要采用Redis或者数据库来实现。

# Cronjob:定时任务
Cron job 的定时表达式,基本上照搬了 Linux Cron 的表达式,格式如下:
Minutes Hours DayofMonth Month DayofWeek
下面例子定义了一个名为 hello 的 Cron Job,任务每隔 1min 执行一次,运行的镜像是 busybox,运行的命令是 Shell 脚本,脚本运行时会在控制台输出当前时间和字符串“Hello from the Kubernetes cluster”。
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
当不需要某个 Cron Job 时,可以通过下面命令删除它:
$ kubectl delete cronjob hello
# 自定义调度器
1.新建Pod,nginx.yaml的内容如下(如果自定义的调度器还未在系统中部署,则默认的调度器会忽略这个Pod,这个Pod将会永远处于Pending状态。)
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
schedulerName: my-scheduler
containers:
- name: nginx
image: nginx:1.10
2.自定义调度器(百度例子)
调度器的主要作用就是把未分配node的pod,自动绑定一个node。下面是我们使用api完成手动绑定
export PODNAME=nginx
export NODENAME=k8s-worker2
curl --cacert /etc/kubernetes/pki/ca.crt \
--cert /etc/kubernetes/pki/apiserver-kubelet-client.crt \
--key /etc/kubernetes/pki/apiserver-kubelet-client.key \
--header "Content-Type:application/json" \
--request POST \
--data '{"apiVersion":"v1","kind":"Binding","metadata": {"name":"'$PODNAME'"},"target": {"apiVersion":"v1","kind": "Node", "name": "'$NODENAME'"}}' \
https://127.0.0.1:6443/api/v1/namespaces/default/pods/$PODNAME/binding/
#Pod 容灾调度
当我们的集群是为了容灾而建设的跨区域的多中心(多个zone)集群,既集群中的节点位于不同区域的机房时,比如北京、上海、广州、武汉,要求每个中心的应用相互容灾备份,又能同时提供服务,此时最好的调度策略就是将需要容灾的应用均匀调度到各个中心。
anti-affinity(pod 的互斥性)它虽然能够满足反亲和配置,但是没有办法控制 Pod 在 拓扑上分布的数量。
新版本中引入topologySpreadConstraints参数来将 Pod 均匀的调度到不同的 Zone。
例:我们的集群被划分为多个 Zone ,我们有一个应用(对应的 Pod 标签为 app=foo )需要在每个Zone均匀调度以实现容灾,则可以定义 YMAL 文件如下:
maxSkew #用于指定 Pod 在各个 Zone 上调度时能容忍的最大不均匀数:值越大,表示能接受的不均匀调度越大;值越小,表示各个 Zone 的 Pod 分布数量越均匀。
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
selector:
matchLabels:
app: foo
3.10 Init Container (初始化容器)
# Init Container (初始化容器)
在很多应用场景中,应用在启动之前都需要进行如下初始化操作。
· 等待其他关联组件正确运行(例如数据库或某个后台服务)
· 基于环境变量或配置模版生成配置文件
· 从远程数据库获取本地所需配置,或者将自身注册到某个中央数据库中
· 下载相关依赖包,或者对系统进行一些配置操作
Init container与应用容器本质上是一样的,但他们是仅运行一次就结束的任务,并且必须在成功执行完成后,系统才能继续执行下一个容器。
示例:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
initContainers:
- name: install
image: busybox
command:
- wget
- "-O"
- "/work-dir/index.html"
- http://kubernetes.io
volumeMounts:
- name: workdir
mountPath: "/work-dir"
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
volumes:
- name: workdir
emptyDir: {}
init container与应用容器的区别
· 运行方式不同,它们必须先于应用容器执行完成,当设置了多个init container时,将按顺序逐个运行,当所有init container都成功运行后,kubernetes才会初始化Pod的各种信息。
· 在init container的定义中也可以设置资源限制,volume的使用和安全策略,但与应用容器略有不同
· init container不能设置readinessProbe探针,因为必须在它们成功运行后才能继续运行Pod中定义的普通容器
· 在Pod重新启动时,init container将会重新运行
3.11 Pod 的升级和回滚
# Pod 的升级和回滚
当集群中的某个服务需要升级时,我们需要停止目前与该服务相关的所有Pod,然后下载新版本镜像并创建新的Pod。如果集群规模比较大,则这个工作变成了一个挑战,而且先全部停止然后逐步升级的方式会导致较长时间的服务不可用。Kubernetes提供了滚动升级功能来解决上述问题。
如果Pod是通过Deployment创建的,则用户可以在运行时修改Deployment的Pod定义(spec.template)或镜像名称,并应用到Deployment对象上,系统即可完成Deployment的 rollout 动作,rollout 被视为 Deployment 的自动更新或自动部署动作。如果在更新过程中发生了错误,则还可以通过回滚操作恢复Pod的版本。
# Deployment 的升级
以 Deployment nginx 为例:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
现在Pod镜像需要被更新为Nginx:1.9.1,我们可以通过kubectl set image命令为Deployment设置新的镜像名称:
$kubectl set image deployment/nginx-development nginx=nginx:1.9.1
另一种更新的方法是使用kubectl edit命令修改Deployment的配置,将spec.template.spec.containers[0].image从Nginx:1.7.9更改为Nginx:1.9.1:
$kubectl edit deployment/nginx-deployment
一旦镜像名(或Pod定义)发生了修改,则将触发系统完成Deployment所有运行Pod的滚动升级操作可以使用kubectl rollout status命令查看Deployment的更新过程:
$kubectl rollout status deployment/nginx-deployment
可以使用kubectl describe deployments/nginx-deployment命令仔细观察Deployment的更新过程。
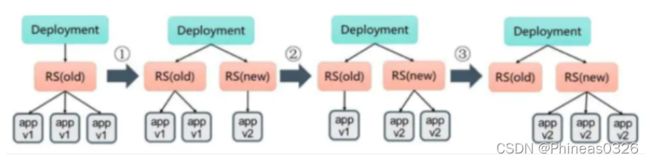
初始创建Deployment时,系统创建了一个ReplicaSet(nginx-deployment-5bf87f5f59),并按用户的需求创建了3个Pod副本。当更新Deployment时,系统创建了一个新的ReplicaSet(nginx-deployment-678645bf77),并将其副本数量扩展到1,然后将旧的ReplicaSet缩减为2。之后,系统继续按照相同的更新策略对新旧两个ReplicaSet进行逐个调整。最后,新的ReplicaSet运行了3个新版本Pod副本,旧的ReplicaSet副本数量则缩减为0。如图所示。
在整个升级的过程中,系统会保证至少有两个Pod可用,并且最多同时运行4个Pod,这是Deployment通过复杂的算法完成的。Deployment需要确保在整个更新过程中只有一定数量的Pod可能处于不可用状态。在默认情况下,Deployment确保可用的Pod总数至少为所需的副本数量(DESIRED)减1,也就是最多1个不可用(maxUnavailable=1)。Deployment还需要确保在整个更新过程中Pod的总数量不会超过所需的副本数量太多。在默认情况下,Deployment确保Pod的总数最多比所需的Pod数多1个,也就是最多1个浪涌值(maxSurge=1)。Kubernetes从1.6版本开始,maxUnavailable和maxSurge的默认值将从1、1更新为所需副本数量的25%、25%。
这样,在升级过程中,Deployment就能够保证服务不中断,并且副本数量始终维持为用户指定的数量(DESIRED)。
在Deployment的定义中,可以通过spec.strategy指定Pod更新的策略,目前支持两种策略:Recreate(重建)和RollingUpdate(滚动更新),默认值为RollingUpdate。在前面的例子中使用的就是RollingUpdate策略。
· Recreate:设置spec.strategy.type=Recreate,表示Deployment在更新Pod时,会先杀掉所有正在运行的Pod,然后创建新的Pod。
· RollingUpdate:设置spec.strategy.type=RollingUpdate,表示Deployment会以滚动更新的方式来逐个更新Pod。同时,可以通过设置spec.strategy.rollingUpdate下的两个参数(maxUnavailable和maxSurge)来控制滚动更新的过程。
下面对滚动更新时两个主要参数的说明如下。
· spec.strategy.rollingUpdate.maxUnavailable:用于指定Deployment在更新过程中不可用状态的Pod数量的上限。该maxUnavailable的数值可以是绝对值(例如5)或Pod期望的副本数的百分比(例如10%),如果被设置为百分比,那么系统会先以向下取整的方式计算出绝对值(整数)。而当另一个参数maxSurge被设置为0时,maxUnavailable则必须被设置为绝对数值大于0(从Kubernetes 1.6开始,maxUnavailable的默认值从1改为25%)。举例来说,当maxUnavailable被设置为30%时,旧的ReplicaSet可以在滚动更新开始时立即将副本数缩小到所需副本总数的70%。一旦新的Pod创建并准备好,旧的ReplicaSet会进一步缩容,新的ReplicaSet又继续扩容,整个过程中系统在任意时刻都可以确保可用状态的Pod总数至少占Pod期望副本总数的70%。
· spec.strategy.rollingUpdate.maxSurge:用于指定在Deployment更新Pod的过程中Pod总数超过Pod期望副本数部分的最大值。该maxSurge的数值可以是绝对值(例如5)或Pod期望副本数的百分比(例如10%)。如果设置为百分比,那么系统会先按照向上取整的方式计算出绝对数值(整数)。从Kubernetes 1.6开始,maxSurge的默认值从1改为25%。举例来说,当maxSurge的值被设置为30%时,新的ReplicaSet可以在滚动更新开始时立即进行副本数扩容,只需要保证新旧ReplicaSet的Pod副本数之和不超过期望副本数的130%即可。一旦旧的Pod被杀掉,新的ReplicaSet就会进一步扩容。在整个过程中系统在任意时刻都能确保新旧ReplicaSet的Pod副本总数之和不超过所需副本数的130%。
这里需要注意多重更新(Rollover)的情况。如果Deployment的上一次更新正在进行,此时用户再次发起Deployment的更新操作,那么Deployment会为每一次更新都创建一个ReplicaSet,而每次在新的ReplicaSet创建成功后,会逐个增加Pod副本数,同时将之前正在扩容的ReplicaSet停止扩容(更新),并将其加入旧版本ReplicaSet列表中,然后开始缩容至0的操作。
例如,假设我们创建一个Deployment,这个Deployment开始创建5个Nginx:1.7.9的Pod副本,在这个创建Pod动作尚未完成时,我们又将Deployment进行更新,在副本数不变的情况下将Pod模板中的镜像修改为Nginx:1.9.1,又假设此时Deployment已经创建了3个Nginx:1.7.9的Pod副本,则Deployment会立即杀掉已创建的3个Nginx:1.7.9 Pod,并开始创建Nginx:1.9.1 Pod。Deployment不会在等待Nginx:1.7.9的Pod创建到5个之后再进行更新操作。
还需要注意更新Deployment的标签选择器(Label Selector)的情况。通常来说,不鼓励更新Deployment的标签选择器,因为这样会导致Deployment选择的Pod列表发生变化,也可能与其他控制器产生冲突。如果一定要更新标签选择器,那么请务必谨慎,确保不会出现其他问题。关于Deployment标签选择器的更新的注意事项如下。
(1)添加选择器标签时,必须同步修改Deployment配置的Pod的标签,为Pod添加新的标签,否则Deployment的更新会报验证错误而失败:
添加标签选择器是无法向后兼容的,这意味着新的标签选择器不会匹配和使用旧选择器创建的ReplicaSets和Pod,因此添加选择器将会导致所有旧版本的ReplicaSets和由旧ReplicaSets创建的Pod处于孤立状态(不会被系统自动删除,也不受新的ReplicaSet控制)。
(2)更新标签选择器,即更改选择器中标签的键或者值,也会产生与添加选择器标签类似的效果。
(3)删除标签选择器,即从Deployment的标签选择器中删除一个或者多个标签,该Deployment的ReplicaSet和Pod不会受到任何影响。但需要注意的是,被删除的标签仍会存在于现有的Pod和ReplicaSets上。
# Deployment 的回滚
如果在 Deployment 升级过程中出现意外,比如写错镜像的名称,新的镜像还没被放入镜像仓库里、新镜像的配置文件发生不兼容改变、新镜像的启动参数不对,以及以为更复杂的依赖关系而导致升级失败等,就需要回退到之前的旧版本,这时就可以用到 Deployment 的回滚功能了。
假设在更新Deployment镜像时,将容器镜像名误设置成Nginx:1.91(一个不存在的镜像):
$kubectl set image deployment/nginx-deployment nginx=nginx:1.91
则这时Deployment的部署过程会卡住:
为了解决这个问题,我们需要回滚到之前稳定版本的 Deployment 。
首先,用 kubectl rollout history 命令检查这个 Deployment 部署到历史记录:
------
[root@k8s-master01 pod]# kubectl rollout history deployment/nginx-deployment
deployment.apps/nginx-deployment
REVISION CHANGE-CAUSE
5 >
6 >
------
在默认情况下,所有 Deployment 的发布历史记录都被保留在系统中,以便于我们随时进行回滚(可以配置历史记录数量)。注意,在创建Deployment时使用--record参数(例:kubectl create -f nginx-deployment.yaml --record),就可以在 CHANGE-CAUSE 列看到每个版本使用的命令了。
如果需要查看特定版本的详细信息,则可以加上--revision=>参数:
$kubectl rollout history deployment/nginx-deployment --revision=5
现在我们决定撤销本次发布并回滚到上一个部署版本:
$kubectl rollout undo deployment/nginx-deployment
也可以使用 --to--revision 参数指定回滚到的部署版本号:
$kubectl rollout undo deployment/nginx-deployment --to-revision=6
# 暂停和恢复 Deployment 的部署操作
对于一次复杂的Deployment配置修改,为了避免频繁触发Deployment的更新操作,可以先暂停Deployment的更新操作,然后进行配置修改,再恢复Deployment,一次性触发完整的更新操作,就可以避免不必要的Deployment更新操作了
以之前创建的Nginx为例:
通过kubectl rollout pause命令暂停deployment的更新操作 #暂停
$kubectl rollout pause deployment/nginx-deployment
之后修改Deployment的镜像信息:
$kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
查看Deployment的历史记录,并发现没有触发新的Deployment部署操作
$kubectl rollout history deployment/nginx-deployment
在暂停Deployment部署之后,可以根据需要进行任意次数的配置更新。例如,再次更新容器的资源限制:
$kubectl set resources deployment nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi
最后,恢复这个Deployment的部署操作: #恢复
$kubectl rollout resume deploy nginx-deployment
注意,在恢复暂停的Deployment之前,无法回滚该Deployment。
# 其他管理对象的更新策略
Kubernetes从1.6版本开始,对DaemonSet和StatefulSet的更新策略也引入类似于Deployment的滚动升级,通过不同的策略自动完成应用的版本升级。
1.DaemonSet的更新策略
目前DaemonSet的升级策略包括两种:OnDelete和RollingUpdate。
(1)OnDelete:DaemonSet的默认升级策略,与1.5及以前版本的Kubernetes保持一致。当使用OnDelete作为升级策略时,在创建好新的DaemonSet配置之后,新的Pod并不会被自动创建,直到用户户手动删除旧版本的Pod,才触发新建操作。
(2)RollingUpdate:从Kubernetes 1.6版本开始引入。当使用RollingUpdate作为升级策略对DaemonSet进行更新时,旧版本的Pod将被自动杀掉,然后自动创建新版本的DaemonSet Pod。整个过程与普通Deployment的滚动升级一样是可控的。不过有两点不同于普通Pod的滚动升级:一是目前Kubernetes还不支持查看和管理DaemonSet的更新历史记录;二是DaemonSet的回滚(Rollback)并不能如同Deployment一样直接通过kubectl rollback命令来实现,必须通过再次提交旧版本配置的方式实现。
2.StatefulSet的更新策略
Kubernetes从1.6版本开始,针对StatefulSet的更新策略逐渐向Deployment和DaemonSet的更新策略看齐,也将实现RollingUpdate、Paritioned和OnDelete这几种策略,以保证StatefulSet中各Pod有序地、逐个地更新,并且能够保留更新历史,也能回滚到某个历史版本。
3.12 Pod 的扩缩容
实际生产系统, 会遇到某个服务需要扩容的场景,也可能会遇到由于资源紧张或者工作负载降低而需要减少服务实例数量的场景。此时可以利用Deployment/RC的Scale机制来完成这些工作。
Kubernetes对Pod的扩缩容操作提供了手动和自动两种模式,手动模式通过执行kubectl scale命令或通过RESTful API对一个Deployment/RC进行Pod副本数量的设置,即可一键完成。自动模式则需要用户根据某个性能指标或者自定义业务指标,并指定Pod副本数量的范围,系统将自动在这个范围内根据性能指标的变化进行调整。
# 手动扩缩容机制
以Deployment nginx为例:
(nginx-deployment.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
通过kubectl scale命令可以将Pod副本数量从初始的3个更新为5个:
$kubectl scale deployment/nginx-deployment --replicas 5
将--replicas设置为比当前Pod副本数量更小的数字,系统将会“杀掉”一些运行中的Pod,以实现应用集群缩容:
$kubectl scale deployment/nginx-deployment --replicas 1
# 自动扩缩容机制
Kubernetes从1.1版本开始,新增了名为Horizontal Pod Autoscaler(HPA)的控制器,用于实现基于CPU使用率进行自动Pod扩缩容的功能。HPA控制器基于Master的kube-controller-manager服务启动参数--horizontal-pod-autoscaler-sync-period定义的探测周期(默认值为15s),周期性地监测目标Pod的资源性能指标,并与HPA资源对象中的扩缩容条件进行对比,在满足条件时对Pod副本数量进行调整。
---------
HPA的工作原理
Kubernetes中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。HPA控制器通过Metrics Server的API(Heapster的API或聚合API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标Pod副本数量。当目标Pod副本数量与当前副本数量不同时,HPA控制器就向Pod的副本控制器(Deployment、RC或ReplicaSet)发起scale操作,调整Pod的副本数量,完成扩缩容操作。如图3.12。
---------
指标的类型
Master的kube-controller-manager服务持续监测目标Pod的某种性能指标,以计算是否需要调整副本数量。目前Kubernetes支持的指标类型如下。
· Pod资源使用率:Pod级别的性能指标,通常是一个比率值,例如CPU使用率。
· Pod自定义指标:Pod级别的性能指标,通常是一个数值,例如接收的请求数量。
· Object自定义指标或外部自定义指标:通常是一个数值,需要容器应用以某种方式提供,例如通过HTTP URL“/metrics”提供,或者使用外部服务提供的指标采集URL。
---------
HorizontalPodAutoscaler配置详解
Kubernetes将HorizontalPodAutoscaler资源对象提供给用户来定义扩缩容的规则。HorizontalPodAutoscaler资源对象处于Kubernetes的API组“autoscaling”中,目前包括v1和v2两个版本其中autoscaling/v1仅支持基于CPU使用率的自动扩缩容,autoscaling/v2则用于支持基于任意指标的自动扩缩容配置,包括基于资源使用率、Pod指标、其他指标等类型的指标数据,当前版本为autoscaling/v2beta2。
下面对HorizontalPodAutoscaler的配置和用法进行说明。
(1)基于autoscaling/v1版本的HorizontalPodAutoscaler配置,仅可以设置CPU使用率:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
主要参数如下
· scaleTargetRef:目标作用对象,可以是Deployment、ReplicationController或ReplicaSet。
· targetCPUUtilizationPercentage:期望每个Pod的CPU使用率都为50%,该使用率基于Pod设置的CPU Request值进行计算,例如该值为200m,那么系统将维持Pod的实际CPU使用值为100m。
· minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个Pod的CPU使用率为50%。
为了使用autoscaling/v1版本的HorizontalPodAutoscaler,需要预先安装Heapster组件或Metrics Server,用于采集Pod的CPU使用率。
(2)基于autoscaling/v2beta2的HorizontalPodAutoscaler配置:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
主要参数如下。
· scaleTargetRef:目标作用对象,可以是Deployment、ReplicationController或ReplicaSet。
· minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个Pod的CPU使用率为50%。
· metrics:目标指标值。在metrics中通过参数type定义指标的类型;通过参数target定义相应的指标目标值,系统将在指标数据达到目标值时(考虑容忍度的区间,见前面算法部分的说明)触发扩缩容操作。
可以将metrics中的type(指标类型)设置为以下三种,可以设置一个或多个组合,如下所述。
(1)Resource:基于资源的指标值,可以设置的资源为CPU和内存。
(2)Pods:基于Pod的指标,系统将对全部Pod副本的指标值进行平均值计算。
(3)Object:基于某种资源对象(如Ingress)的指标或应用系统的任意自定义指标。
Resource类型的指标可以设置CPU和内存。
对于CPU使用率,在target参数中设置averageUtilization定义目标平均CPU使用率。对于内存资源,在target参数中设置AverageValue定义目标平均内存使用值。
指标数据可以通过API“metrics.k8s.io”进行查询,要求预先启动Metrics Server服务。
Pods类型和Object类型都属于自定义指标类型,指标的数据通常需要搭建自定义Metrics Server和监控工具进行采集和处理。指标数据可以通过API“custom.metrics.k8s.io”进行查询,要求预先启动自定义Metrics Server服务。
类型为Pods的指标数据来源于Pod对象本身,其target指标类型只能使用AverageValue,示例如下:
metrics:
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
其中,设置Pod的指标名为packets-per-second,在目标指标平均值为1000时触发扩缩容操作。
--------
基于自定义指标的 HPA 实践
基于自定义指标进行自动扩缩容时,需要预先部署自定义Metrics Server,目前可以使用基于Prometheus、Microsoft Azure、Datadog Cluster等系统的Adapter实现自定义Metrics Server,未来还将提供基于Google Stackdriver的实现自定义Metrics Server。
基于Prometheus的HPA架构如图 3.13 所示
关键组件包括如下:
· Prometheus:定期采集各Pod的性能指标数据。
· Custom Metrics Server:自定义Metrics Server,用Prometheus Adapter进行具体实现。它从Prometheus服务采集性能指标数据,通过Kubernetes的Metrics Aggregation层将自定义指标API注册到Master的API Server中,以/apis/custom.metrics.k8s.io路径提供指标数据。
· Metrics Aggregation层将自定义指标API注册到Master的API Server中,以/apis/custom.metrics.k8s.io路径提供指标数据。
HPA Controller:Kubernetes的HPA控制器,基于用户定义的HorizontalPodAutoscaler进行自动扩缩容操作。
3.13 使用 StatefulSet 搭建 MongoDB 集群
本节以MongoDB为例,使用StatefulSet完成MongoDB集群的创建,为每个MongoDB实例在共享存储中(这里采用GlusterFS)都申请一片存储空间,以实现一个无单点故障、高可用、可动态扩展的MongoDB集群。
部署架构如图3.14所示。
#前提条件
在创建StatefulSet之前,需要确保在Kubernetes集群中管理员已经创建好共享存储,并能够与StorageClass对接,以实现动态存储供应的模式。
本节的示例将使用GlusterFS作为共享存储(GlusterFS的部署方法参见8.3节的说明)。
#部署StatefulSet
为了完成MongoDB集群的搭建,需要创建如下三个资源对象。
· 一个StorageClass,用于StatefulSet自动为各个应用Pod申请PVC。
· 一个Headless Service,用于维护MongoDB集群的状态。
· 一个StatefulSet。
首先,创建一个StorageClass对象。
storageclass-fast.yaml文件的内容如下:
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/glusterfs
parameters:
resturl: "http://"
执行kubectl create命令创建该StorageClass:
$kubectl create -f storageclass-fast.yaml
接下来,创建对应的Headless Service。
mongo-sidecar作为MongoDB集群的管理者,将使用此Headless Service来维护各个MongoDB实例之间的集群关系,以及集群规模变化时的自动更新。
mongo-headless-service.yaml文件的内容如下:
---
apiVersion: v1
kind: Service
metadata:
name: mongo
labels:
name: mongo
spec:
ports:
- port: 27017
targetPort: 27017
clusterIP: None
selector:
role: mongo
使用kubectl create命令创建该StorageClass:
$kubectl create -f mongo-headless-service.yaml
最后,创建MongoDB StatefulSet。
statefulset-mongo.yaml文件的内容如下:
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: mongo
spec:
serviceName: "mongo"
replicas: 3
template:
metadata:
labels:
role: mongo
environment: test
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mongo
image: mongo
command:
- mongod
- "--replSet"
- rs0
- "--smallfiles"
- "--noprealloc"
ports:
- containerPort: 27017
volumeMounts:
- name: mongo-persistent-storage
mountPath: /data/db
- name: mongo-sidecar
image: cvallance/mongo-k8s-sidecar
env:
- name: MONGO_SIDECAR_POD_LABELS
value: "role=mongo,environment=test"
- name: KUBERNETES_MONGO_SERVICE_NAME
value: "mongo"
volumeClaimTemplates:
- metadata:
name: mongo-persistent-storage
annotations:
volume.beta.kubernetes.io/storage-class: "fast"
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 100Gi
其中的主要配置说明如下。
(1)在该StatefulSet的定义中包括两个容器:mongo和mongo-sidecar。mongo是主服务程序,mongo-sidecar是将多个mongo实例进行集群设置的工具。mongo-sidecar中的环境变量如下。
· MONGO_SIDECAR_POD_LABELS:设置为mongo容器的标签,用于sidecar查询它所要管理的MongoDB集群实例。
· KUBERNETES_MONGO_SERVICE_NAME:它的值为mongo,表示sidecar将使用mongo这个服务名来完成MongoDB集群的设置。
(2)replicas=3表示这个MongoDB集群由3个mongo实例组成。
(3)volumeClaimTemplates是StatefulSet最重要的存储设置。在annotations段设置volume.beta.kubernetes.io/storage-class="fast"表示使用名为fast的StorageClass自动为每个mongo Pod实例分配后端存储。resources.requests.storage=100Gi表示为每个mongo实例都分配100GiB的磁盘空间。
使用kubectl create命令创建这个StatefulSet:
$kubectl create -f statefulset-mongo.yaml
4.深入掌握 Service
Service是kubernetes最核心的概念,通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求进行负载分发到后端的各个容器应用上。
4.1 Service 定义详解
Service 用于为一组提供服务的 Pod 抽象一个稳定的网络访问地址,是 K8S 实现微服务的核心概念。通过 Service 的定义设置的访问地址是 DNS 域名格式的服务名称,对于客户端应用来说,网络访问方式并没有改变(DNS 域名的作用等价于主机名、互联网域名或IP地址)。 Service 还提供了负载均衡器功能,将客户端请求负载分发到后端提供具体服务的各个 Pod 上。
Service 的 YAML 格式的定义文件的完整内容如下:
apiVersion: v1 // Required
kind: Service // Required
matadata: // Required
name: string // Required
namespace: string // Required
labels: #自定义标签属性列表
- name: string
annotations: #自定义注解属性列表
- name: string
spec: // Required #详细描述
selector: [] // Required
type: string // Required #Service类型
clusterIP: string #虚拟服务的IP地址
sessionAffinity: string
ports: #Service端口列表
- name: string #端口名称
protocol: string #端口协议
port: int #服务监听的端口号
targetPort: int #需要转发到后端Pod的端口号
nodePort: int
status:
loadBalancer: #外部负载均衡器
ingress:
ip: string #外部负载均衡器IP
hostname: string
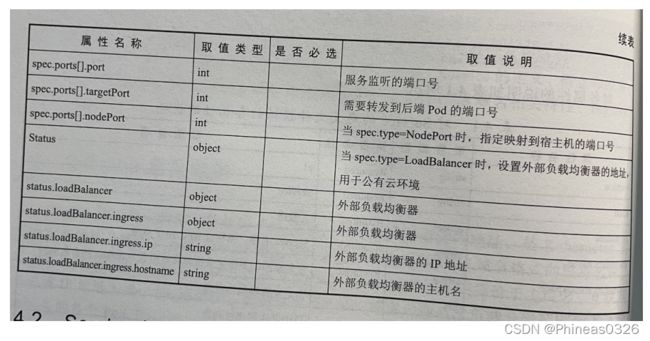
对各属性的说明如表 4.1 所示。
4.2 Service 的概念和原理
Service 主要用于提供网络服务,通过 Service 的定义,能够为客户端应用提供稳定的访问地址(域名或IP地址)和负载均衡功能,已经屏蔽后端 Endpoint 的变化,是K8S实现微服务的核心资源。
# Service 的概念
在应用 Service 概念之前,我们先看看如何访问一个多副本的应用容器组提供的服务。
如下所示为一个提供 Web 服务的 Pod 集合,由两个 Tomcat 容器副本组成,每个容器提供的服务端口号都为 8080:
webapp-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
spec:
replicas: 2
selector:
matchLabels:
app: webapp
template:
metadata:
labels:
app: webapp
spec:
containers:
- name: webapp
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
创建该 Deployment:
$kubectl create -f webapp-deployment.yaml
查看每个Pod的IP的地址:
$kubectl get pods -l app=webapp -o wide
客户端应用可以直接通过这两个 Pod 的 IP 地址和端口号 8080 访问 Web 服务:
例:查到的IP为 10.0.95.22
$ curl 10.0.95.22:8080
但是,提供服务的容器应用通常是分布式的,通过多个 Pod 副本共同提供服务。而 Pod 副本的数量也可能在运行的过程中动态改变(例如执行了水平扩缩容),另外,单个Pod 的 IP 也可能发生了变化(例如发生了故障恢复)。
对于客户端应用来说,要实现动态感知服务后端实例的变化,以及将请求发送到多个后端实例的负载均衡机制,都会大大增加客户端系统实现的复杂度。 K8S 的 Service 就是用于解决这些问题的核心组件。通过 Service 的定义,可以对客户端应用屏蔽后端 Pod 实例数量及 Pod IP 地址的变化,通过负载均衡策略实现请求到后端 Pod 的实例转发,为客户端应用提供一个稳定的服务访问入口地址。Service 实现的是微服务架构中的几个核心功能:全自动的服务注册、服务发现、服务负载均衡等。
以前面创建的 webapp 应用为例,为了让客户端应用访问到两个 Tomcat Pod 实例,需要创建一个 Service 来提供服务。 K8S 提供了一种快速的方法,即通过 kubectl expose 命令来创建 Service:
$kubectl expose deployment webapp
查看新创建的 Service ,可以看到系统为它分配了一个虚拟 IP 地址(ClusterIP地址),Service 的端口号则从 Pod 中的 containerPort 复制而来:
$kubectl get svc
除了使用 kubectl expose 命令创建 Service,更便于管理的方式是通过 YAML 文件来创建 Service ,代码如下:
webapp-service.yaml
---
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- protocol: TCP
port: 8080
targetPort: 8080
selector:
app: webapp
---
Service 定义中的关键字段是 ports 和 selector 。
本例中的 ports 定义部分指定了 Service 本身的端口号为 8080 ,targetPort 则用来指定后端 Pod 的容器端口号,selector 定义部分设置的是后端 Pod 所拥有的 label:app=webapp。
---
在提供服务的 Pod 副本集运行过程中,如果 Pod 列表发生了变化,则 K8S 的 Service 控制器会持续监控后端 Pod 列表的变化,实时更新 Service 对应的后端 Pod 列表。
一个 Service 对应的“后端”由 Pod 的 IP 和容器端口号组成,即一个完整的 “IP:Port” 访问地址,这在 K8S 系统中叫做 Endpoint 。通过查看 Service 详细信息,可以看到其后端 Endpoint 列表:
$kubectl describe svc webapp
实际上,K8S 自动创建了与 Service 关联的 Endpoint 资源对象,这可以通过查询 Endpoint 对象进行查看。
$kubectl get endpoints
# Service 的负载均衡机制
当一个 Service 对象在 K8S 集群中被定义出来时,集群内的客户端应用就可以通过服务 IP 访问到具体的 Pod 容器提供的服务了。从服务 IP 到后端 Pod 的负载均衡机制,则是由每个 Node 上的 kube-proxy 负责实现的。本节对 kube-proxy 的代理模式、会话保持机制和基于拓扑感知的服务路由机制(EndpointSlices)进行说明。
1、kube-proxy 的代理模式
目前 kube-proxy 提供了以下代理模式(通过启动参数 --proxy-mode 设置)。
· userspace 模式:用户空间模式,效率最低,不再推荐使用
· iptables 模式:kube-proxy 通过设置 Linux Kernel 的 iptables 规则,实现从 Service 到后端 EndPoint 列表的负载分发规则。(要保证Endpoint状态正常)
· ipvs 模式:kube-proxy 通过设置 Linux Kernel 的 netlink 接口设置 IPVS 规则。(要求 Linux Kernel 启动 IPVS 模块)(同时,IPVS支持多种负载侧率:RR(轮训)、LC(最小连接)、DH(目的地址哈希)、SED(最短期望延时))
· kernelspace 模式: Windows Service 上的代理模式。
2、会话保持机制
Service 支持通过设置 sessionAffinity 实现基于客户端 IP 的会话保持机制,即首次将某个客户端来源 IP 发起的请求转发到后端的某个 Pod 上,之后从相同的客户端 IP 发起的请求都将被转发到相同的后端 Pod 上,配置参数为 service.spec.sessionAffinity,例如:
---
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
sessionAffinity: ClientIP
ports:
- protocol: TCP
port: 8080
targetPort: 8080
selector:
app: webapp
同时,用户可以设置会话保持的最长时间,在此时间之后重置客户端来源 IP 的保持规则,配置参数为 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds。 例如下面的服务将会话保持时间设置为 10800s(3h):
webapp-service.yaml
---
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800
ports:
- protocol: TCP
port: 8080
targetPort: 8080
selector:
app: webapp
# Service 的多端口设置
一个容器应用可以提供多个端口的服务,在 Service 的定义中也可以相应地设置多个端口号。
在下面的例子中,Service 设置了两个端口号来分别提供不同的服务,如 Web 服务和 management 服务(下面为每个端口号都进行了命名,以便区分):
---
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- port: 8080
targetPort: 8080
name: web
- port: 8005
targetPort: 8005
name: management
selector:
app: webapp
另一个例子是同一个端口号使用的协议不同,如 TCP 和 UDP ,也需要设置为多个端口号来提供不同的服务:
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "KubeDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 169.169.0.100
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
# 将外部服务定义为 Service
普通的 Service 通过 Label Selector 对后端 Endpoint 列表进行了一次抽象,如果后端的 Endpoint 不是有 Pod 副本集提供的,则 Service 还可以抽象定义任意其他服务,将一个 K8S 集群外部的已知服务定义为 K8S 内的一个 Service ,供集群内的其他应用访问,常见的应用场景包括:
· 已部署的一个集群外服务,例如数据库服务、缓存服务等;
· 其他 K8S 集群的某个服务;
· 迁移过程中对某个服务进行 K8S 内的服务名访问机制的验证。
对于这种应用场景,用户在创建 Service 资源对象时不设置 Label Selector(后端 Pod 也不存在),同时在定义一个与 Service 关联的 Endpoint 资源对象,在 Endpoint 中设置外部服务的 IP 地址和端口号,例如:
---
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
---
kind: Endpoints
apiVersion: v1
metadata:
name: my-service
subsets:
- addresses:
- IP: 1.2.3.4
ports:
- port: 80
如图 4.1 所示,访问没有标签选择器的 Service 和带有标签选择器的 Service 一样,请求将被路由到由用户自定义的后端 Endpoint 上。
# 将 Service 暴露到集群外部
K8S 为 Service 创建的 ClusterIP 地址是对后端 Pod 列表的一层抽象,对于集群外部来说并没有意义,但有许多 Service 是需要对集群外部提供服务的,K8S 提供了多种机制将 Service 暴露出去,供集群外部的客户端访问。这可以通过 Service 资源对象的类型字段 “type” 进行设置。
目前 Service 的类型如下:
· ClusterIP: Kubernetes 默认会自动设置 Service 的虚拟 IP 地址,仅可供集群内部的客户端应用访问。也可以手动设置一个 ClusterIP 地址,需要保证该 IP 地址 kubernetes 集群设置的 ClusterIP 范围内,并没有被其它 Service 使用。
· NodePort:将 Service 的端口映射到每个 Node 的一个端口号上,这样集群中的任意 Node 都可以作为 Service 的访问入口地址,即 NodeIP:NodePort
· LoadBalancer:将 Service 映射到一个已经存在的负载均衡器的 IP 地址上,通常在公有云使用
· ExternalName:将 Service 映射为一个外部域名地址,通常在 ExternalName 字段设置
1.NodePort 类型
下面的列子设置 Service 的类型为 NodePort ,并设置具体的 NodePort 端口号为 8081:
---
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
type: NodePort
ports:
- port: 8080 #Service所需的虚拟端口号
targetPort: 8080 #指定后端Pod的端口号
nodePort: 8081 #映射到Node的端口号
selector:
app: webapp
在默认情况下,Node的kube-proxy会在全部网卡(0.0.0.0)上绑定NodePort端口。
在很多数据中心环境,一台主机会配置多块网卡,作用各不相同(例如存在业务网卡和管理网卡等)。在Kubenetes1.10版本开始,kube-proxy可以通过设置特定的IP地址将NodePort绑定到特定的网卡上,而无需绑定在全部网卡上,其设置方式为为配置启动参数“--nodeport-address”,指定需要绑定的网卡IP地址,多个地址之间使用逗号隔开。
例如:仅在10.0.0.0/8和192.168.0/24对应的网卡上绑定NodePort端口号,其他IP地址不会绑定
--nodeport-addresses=10.0.0.0/8,192.168.18.0/24
如果用户在Service定义中不设置具体的nodePort端口号,Kubernetes会自动分配一个Nodeport范围内可用的端口号。
2.LoadBalancer 类型
通常在公有云环境中设置Service为“LoadBalancer”,可以将Service映射到公有云提供的某个负载局衡器的IP地址上,客户端通过负载均衡器的IP地址和端口号就可以访问到具体的服务,无须再通过kube-proxy提供的负载均衡器机制进行流量转发。公有云提供的LoadBalancer可以直接将流量转发到后端Pod上,而负载均衡分发机制依赖于公有云服务上具体实现。
下面的列子设置 Service 的类型为 LoadBalancer:
---
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: LoadBalancer
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
在服务创建之后,云服务商会在Service的定义中补充LoadBalancer的IP地址(status字段)
status:
loadBalancer:
ingress:
- ip: 192.0.2.128
3.ExternalName 类型
ExternalName 类型的服务用于将集群外的服务定义为 kubernetes 的集群 Service,并且通过 externalName 自动指定外部服务的地址,可以使用域名或 IP 格式。集群内的客户端应用通过访问这个 Service 就能访问外部服务了。这种类型的 Service 没有后端 Pod,无需 LabelSelector。
例如:
---
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
设置服务名字为 my-service ,所在的命名空间为 prod ,客户端访问服务地址 my-service.prod.svc.cluster.local 时,系统将自动指向外部域名my.databases.example.com 。还可以通过Ingress将服务暴露到集群外部。
# Service 支持的网络协议
目前 Service 支持的网络协议如下:
· TCP: Service 的默认网络协议,可用于所有类型的 Service。
· UDP: 可用于大多数类型的 Service,LoadBalancer 类型取决于云服务商对 UDP 的支持。
· HTTP: 取决于云厂商是否支持 HTTP 和实现机制。
· PROXY: 取决于云厂商是否支持 HTTP 和实现机制。
· SCTP: 从 K8S 1.12 版本引入,到 1.19 版本时达到 Beta 阶段,默认启用。
K8S 从 1.17 版本开始,可以为 Service 和 Endpoint 资源对象设置一个新的字段 “AppProtocol” ,用于标识后端服务在某个端口上提供的应用层协议类型,例如 HTTP、HTTPS、SSL、DNS等,该特性在 K8S 1.19 版本时达到 Beta 阶段,计划与 K8S 1.20 版本时达到 GA 阶段。要使用 AppProtocol,需要设置 kube-apiserver 的启动参数 --feature-gates=ServiceAppProtocol=true 进行开启,然后再 Service 或 Endpoint 的定义中设置 AppProtocol 字段指定应用层协议的类型,例如:
---
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- port: 8080
targetPort: 8080
AppProtocol: HTTP
selector:
app: webapp
# K8S 的服务发现机制
服务发现机制指客户端应用在一个 K8S 集群中如何获取后端服务的访问地址。K8S 提供了两种机制供客户端应用以固定的方式获取后端服务的访问地址:环境变量方式和 DNS 方式。
1.环境变量方式
在一个 Pod 运行起来的时候,系统会自动为其容器运行环境注入所有集群中有效 Service 的信息。Service 的相关信息包括服务 IP 、服务端口号、各端口号相关的协议等,通过 {SVCNAME}_SERVICE_HOST 和 {SVCNAME}_SERVICE_PORT 格式进行设置。其中,SVCNAME 的命名规则为:将 Service 的 name 字符串转换为全大写字母,将中横线 “-” 替换为下划线 “_”。
以 webapp 服务为例:
---
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- protocol: TCP
port: 8080
targetPort: 8080
selector:
app: webapp
在一个新创建的 Pod (客户端应用)中,可以看到系统自动设置的环境变量如下:(Linux env 命令)
WEBAPP_SERVICE_HOST=10.0.0.11
WEBAPP_SERVICE_PORT=8080
WEBAPP_PORT=tcp://10.0.0.11:8080
WEBAPP_PORT_8080_TCP=tcp://10.0.0.11:8080
WEBAPP_PORT_8080_TCP_PROTO=tcp
WEBAPP_PORT_8080_TCP_PORT=8080
WEBAPP_PORT_8080_TCP_ADDR=10.0.0.11
然后客户端应用能够根据Service相关环境变量的命名规则,从环境变量中获取需要访问目标服务的地址,例如:
curl http://${WEBAPP_SERVICE_HOST}:${WEBAPP_SERVICE_PORT}
2.DNS 方式
Service 在 Kubernetes 系统中遵循 DNS 命名规范,Service 的 DNS 域名表示方法为 >.>.svc.>,其中servicename 为服务的名称,namespace 为其所在的 namespace 名称,clusterdomain 为 Kubernetes 集群设置的域名后缀 (例如cluster.local)
对于客户端应用来说, DNS 的域名格式的 Service 名称提供的是稳定的、不变的访问地址,可以简化客户端应用的配置,是 Kubernetes 中推荐使用的方式。
当 Service 以 DNS 域名形式进行访问是,需要在 Kubernetes 集群中存在一个 DNS 服务器来完成域名到 ClusterIP 地址的解析工作,目前有 CoreDNS 作为Kubernetes 集群中的默认 DNS 服务器提供域名解析服务。
另外,Service 定义中的端口号如果设置了名称( name ),则端口号也会拥有一个 DNS 域名,在 DNS 服务器中以 SRV 记录的格式保存:_>._>.>.>.svc.>,其值为端口号的数值。
以 webapp 服务为例,将其端口号命名为 “http”:
---
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
ports:
- protocol: TCP
port: 8080 #Service所需的虚拟端口号
targetPort: 8080 #指定后端Pod的端口号
name: http
selector:
app: webapp
解析名为“http”端口号的DNS SRV记录“_http_._tcp.webpp.default.svc.cluster.local”,可以查询到端口号为8080
# Headless Service 的概念和应用
在某些应用场景中,客户端不需要通过Kubernetes内置的Service实现负载均衡功能,或者需要自行完成对服务后端各个实例的服务发现机制,或者需要自行实现负载均衡功能,可以通过创建特殊的名为“Headless”的服务实现。
Headless Service的概念是这种服务没有入口访问地址(无ClusterIP地址),kube-proxy不会为其创建负载转发规则,而服务名(DNS域名)的解析机制取决于该Headless Service是否设置了Label Selector。
1. Headless Service设置Label Selector
如果Headless Service设置了Label Selector,Kubernetes则将根据Label Selector查询后端Pod列表,自动创建Endpoint列表,将服务名(DNS域名)的解析机制配置为:当客户端访问该服务名时,得到是全部Endpoint列表(而不是一个确定的IP地址)。
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
clusterIP: None
selector:
app: nginx
2. Headless Service未设置Label Selector
如果Headless Service没有设置Label Selector,则Kubernetes不会自动创建对应的Endpoint列表。DNS系统会根据下列条件设置DNS记录:
· 如果Service类型为ExternalName,则对服务名访问将直接被DNS系统转为Service设置的外部(externalName);
· 如果系统中存在与Service同名的Endpoint定义,则服务名将被解析为Endpoint定义中的列表,适用于非ExternnalName类型的Service

# 端点分片与服务拓扑
Service的后端是一组Endpoint列表, 为客户端端应用提供了极大的便利。但是随着集群规模的扩大以及Service数量的增加,尤其是Service后端Endpoint数量的增加,kube-proxy需要维护的负载分发规则(例如iptables规则或ipvs)数量也会急剧增加,导致后续对Service后端Endpoint的增加、删除等更新操作成本急剧上升。例如:在kubernetes集群中有10000个Endpoint运行大约5000个Node上,则对单个Pod更新需要约5GB的数据传输,这不进对集群内的网络带宽浪费巨大,而对Master的冲击非常大,会影响Kubernetes整体的性能,在Deployment不断进行滚动升级情况下由于突出。
1. 端点分片
Kubernetes1.6开始引入端点分片(Endpoint Slices)机制,引入新的EndpointSlice资源对象和一个新的EndpointSlice控制器。EndpointSlice通过对Endpoint分配管理来实现降低Master和各个Node之间的网络传输数量及提高整体性能目标。对与Deployment的滚动升级,可以实现更新部分Node上的Endpoint信息,Master和Node之间的数据传输减少了100倍左右,很大程度上提高了管理效率。
EndpointSlice根据Endpoint所在的Node的拓扑信息进行分配管理,实例如图 4.2 所示。
默认情况下,在EndpointSlice控制器创建的EndpointSlice中最多包含100个Endpoint,如需修改可以通过kube-controller-manager服务启动参数--max-endpoints-per-slice设置,但是上限不能超过1000。
2. 服务拓扑
服务拓扑机制从Kubernetes1.17版本开始引入,目标是实现基于Node拓扑的流量路由,例如将发送到某个服务的流量优先路由到与客户端相同Node的Endpoint上,或者路由到与客户端相同的Zone的那些Node的Endpoint上。
在默认情况下,发送到一个Service的流量会被均匀的转发到每个后端Endpoint上,但无法根据复杂的拓扑信息设置复杂的路由策略。服务拓扑机制的引入就是为了实现基于Node拓扑的服务器路由,允许Service创建者根据来源Node和目标Node的标签来定义流量路由策略。
通过对来源(Source) Node和目标(destination)Node标签的匹配,用户可以根据业务需求对Node进行分组,设置有意义的的指标值来标识“较近”或者“较远”的属性。例如:对于公有云环境,通常有区域(Zone或Region)的划分,云平台倾向于把服务的流量限制在同一个区域内,这通常是因为跨区域网络流量会收取额外的费用。另外一个例子,把流量路由到由DaemonSet管理的当前Node的Pod上。又如希望把流量保持在相同机架的Node上,已获得更低的网络延时。
服务拓扑机制需要通过设置kube-apiserver和kube-proxy服务启动参数--feature-gates="ServiceTopology=true,EndpointSilce=true"进行启用(需要同时启动EndpointSlice功能),然后可以在Service对象上通过定义topologyKeys字段来控制到Service的流量路由了。
topologyKeys字段设置的是一组Node标签列表,按顺序匹配Node完成流量的路由转发,流量会被转发到标签匹配成功的Node上。如果按第1个标签找不到匹配的Node,就尝试匹配第2个标签,以此类推。如果全部的标签都没有匹配到Node,则请求会被拒绝,就像Service没有后端Endpoint一样。
将topologyKey配置为“*”标识任意拓扑,它只能作为配置列表中的最后一个才能有效。如果不设置topologyKeys字段,或者将其值设置为空,相当于没有启动服务拓扑功能。
对于要使用服务拓扑的集群,管理员需要为Node设置相应的拓扑标签,包括 kubernetes.io/hostname、kubernetes.io/zone和kubernetes.io/region。
4.3 DNS 服务搭建和配置指南
作为服务发现机制的基本功能,在集群内需要能够通过服务名对服务进行访问,这就需要一个集群范围内的 DNS 服务来完成从服务到 ClusterIP 地址的解析。k8s DNS服务的发展经历了三个阶段:SkyDNS、KubeDNS和CoreDNS,其架构由复杂向简单演变,如下图:
部署略。。。
4.4 DNS 本地缓存
由于在Kubernetes中配置的DNS服务是一个名为“kube-dns”的Service,所以容器应用都通过ClusterIP地址(例如:169.168.0.100)去执行服务名的DNS域名解析。这对于大规模的集群会存在两个问题:
(1)集群DNS服务压力增大(可以通过自动扩容缓解)
(2)由于DNS服务的IP地址是Service的ClusterIP地址,所以会通过kube-proxy设置的iptables规则进行转发,可能导致域名解析性能很差,原因是Netfilter在做DNAT转换时会引起conntrack冲突,从而导致DNS查询产生5s延迟。
为了解决这两个问题,Kubernetes引入了Node本地DNS缓存来提高整个集群的DNS域名解析性能,在1.18时达到Stable阶段,使用Node本地DNS缓存的好处:
· 在没有本地DNS缓存时,集群DNS服务的Pod很可能在其他节点上,跨主机访问会增加网络延时,使用Node本地缓存DNS缓存可显著减少跨主机查询的网络延时;
· 跳过IPtables DNAT和连接跟踪将有助于减少conntrack竞争,并避免UDP DNS记录填满conntrack表
· 本地缓存到集群DNS服务的连接协议可升级为TCP。TCP conntrack条目将在连接关闭时被删除;默认使用UDP时,contrack条目只能等到超时时间过后才被删除,操作系统的默认超时时间为30s
· 将DNS查询从UDP升级为TCP,将减少由于丢弃的UDP数据包和DNS超时时间而导致尾部延迟(tail latency),UDP超时时间可能会长达30s(3次重试,每次10s)
· 提供Node级别DNS解析请求度量(Metrics)和可见性(visibility)
· 可以重新启用负缓存功能,减少对集群DNS服务重新梳理
Node本地DNS缓存(NodeLocal DNSCahe)的,客户端Pod首先会通过本地DNS缓存进行域名解析,当缓存中不存在域名时,会将请求转发到集群DNS服务进行解析。如图 4.6。
下面对如何部署 Node 本地 DNS 缓存工具进行说明:
配置文件 nodelocaldns.yaml 内容如下,主要包括 ServiceAccount、Daemonset、ConfigMap 和 Service 几个资源对象。
Service Account 的定义如下:
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: node-local-dns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
Service 的定义如下:
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns-upstream
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "KubeDNSUpstream"
spec:
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
selector:
k8s-app: kube-dns
ConfigMap 的定义如下:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: node-local-dns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
Corefile: |
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10
forward . 169.169.0.100 {
force_tcp
}
prometheus :9253
health 169.254.20.10:8081
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 169.169.0.100 {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 169.169.0.100 {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . 169.169.0.100 {
force_tcp
}
prometheus :9253
}
DaemonSet 的定义如下:
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-local-dns
namespace: kube-system
labels:
k8s-app: node-local-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
updateStrategy:
rollingUpdate:
maxUnavailable: 10%
selector:
matchLabels:
k8s-app: node-local-dns
template:
metadata:
labels:
k8s-app: node-local-dns
annotations:
prometheus.io/port: "9253"
prometheus.io/scrape: "true"
spec:
priorityClassName: system-node-critical
serviceAccountName: node-local-dns
hostNetwork: true
dnsPolicy: Default # Don't use cluster DNS.
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
- effect: "NoExecute"
operator: "Exists"
- effect: "NoSchedule"
operator: "Exists"
containers:
- name: node-cache
image: k8s.gcr.io/k8s-dns-node-cache:1.15.13
resources:
requests:
cpu: 25m
memory: 5Mi
args: [ "-localip", "169.254.20.10", "-conf", "/etc/Corefile", "-upstreamsvc", "kube-dns-upstream" ]
securityContext:
privileged: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9253
name: metrics
protocol: TCP
livenessProbe:
httpGet:
host: 169.254.20.10
path: /health
port: 8081
initialDelaySeconds: 60
timeoutSeconds: 5
volumeMounts:
- mountPath: /run/xtables.lock
name: xtables-lock
readOnly: false
- name: config-volume
mountPath: /etc/coredns
- name: kube-dns-config
mountPath: /etc/kube-dns
volumes:
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
- name: kube-dns-config
configMap:
name: coredns
optional: true
- name: config-volume
configMap:
name: node-local-dns
items:
- key: Corefile
path: Corefile.base
4.5 Pod 的 DNS 域名相关特性
Pod作为集群中提供具体服务的实体,也可以像Service一样设置DNS域名。另外,系统为客户端应用Pod提供需要使用的DNS策略提供多种选择。
# Pod的DNS域名
对Pod来说,Kubernetes会为其设置一个-ip>.>.pod.-domain>格式的DNS域名,其中Pod IP部分需要用"-"替换"."符号,例如:
系统为webapp-p598v这个pod设置的DNS域名为10-244-2-3.default.pod.cluster.local
[root@master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 3 2d17h 10.244.1.3 node3 > >
webapp-p598v 1/1 Running 0 3d3h 10.244.2.3 node4 > >
webapp-wj5q7 1/1 Running 0 3d3h 10.244.3.2 node2 > >
[root@master ~]# kubectl exec -it webapp-wj5q7 bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@webapp-wj5q7:/usr/local/tomcat# ping 10-244-2-3.default.pod.cluster.local
PING 10-244-2-3.default.pod.cluster.local (10.244.2.3) 56(84) bytes of data.
64 bytes from 10-244-2-3.webapp.default.svc.cluster.local (10.244.2.3): icmp_seq=1 ttl=62 time=2.11 ms
64 bytes from 10-244-2-3.webapp.default.svc.cluster.local (10.244.2.3): icmp_seq=2 ttl=62 time=0.889 ms
^C
--- 10-244-2-3.default.pod.cluster.local ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 2ms
rtt min/avg/max/mdev = 0.889/1.500/2.111/0.611 ms
root@webapp-wj5q7:/usr/local/tomcat#
---
对于Depoyment或Daemonset类型创建的Pod,Kubernetes会为每个Pod有以其IP地址和控制器名称设置一个DNS域名,格式-ip>.-name>.>.svc.-doamin>,其中Pod IP地址段字符串需要用“-”替代“.”符号,例如:
Pod地址为10.244.3.2,由ReplicationController部署名字为webapp,系统为这个Pod分配一个DNS域名为10-244-3-2.webapp.default.svc.cluster.local
[root@master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 4 2d17h 10.244.1.3 node3 > >
webapp-p598v 1/1 Running 0 3d4h 10.244.2.3 node4 > >
webapp-wj5q7 1/1 Running 0 3d4h 10.244.3.2 node2 > >
[root@master ~]# kubectl exec -it webapp-p598v bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@webapp-p598v:/usr/local/tomcat# ping 10-244-3-2.webapp.default.svc.cluster.local
PING 10-244-3-2.webapp.default.svc.cluster.local (10.244.3.2) 56(84) bytes of data.
64 bytes from 10-244-3-2.webapp.default.svc.cluster.local (10.244.3.2): icmp_seq=1 ttl=62 time=0.580 ms
64 bytes from 10-244-3-2.webapp.default.svc.cluster.local (10.244.3.2): icmp_seq=2 ttl=62 time=1.37 ms
^C
--- 10-244-3-2.webapp.default.svc.cluster.local ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 3ms
rtt min/avg/max/mdev = 0.580/0.975/1.371/0.396 ms
# 为Pod自定义 hostname 和 subdomain
在默认情况下,Pod的名称将被系统设置为容器环境内的主机名称(hostname),但通过副本控制器创建的名称会有一段随机的后缀名,无法固定,此时可以通过在Pod yaml配置文件中设置hostname字段定义容器环境的主机名。同时可以设置subdomain字段定义容器环境的子域名。
---
apiVersion: v1
kind: Pod
metadata:
name: my-webapp
labels:
app: my-webapp
spec:
hostname: my-webapp #主机名
subdomain: mysubdomain #子域名
containers:
- name: my-webapp
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
创建这个 Pod
[root@master ~]# kubectl get pod my-webapp
NAME READY STATUS RESTARTS AGE
my-webapp 1/1 Running 0 33s
[root@master ~]#
查看 Pod 的 IP 地址
root@master ~]# kubectl get pod my-webapp -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-webapp 1/1 Running 0 73s 10.244.3.5 node2 > >
在Pod创建成功之后,Kubernetes系统为其设置的DNS域名为"my-webapp.mysubdomain.default.svc.cluster.local"
kubectl exec -it my-webapp bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@my-webapp:/usr/local/tomcat# cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.244.3.5 my-webapp.mysubdomain.default.svc.cluster.local my-webapp
为了使集群内其它应用能够访问Pod的DNS域名,还需要部署一个Headless Service,其服务名称为Pod的子域名(subdomain),这样系统就会在DNS服务器中自动创建相应的DNS记录。
---
apiVersion: v1
kind: Service
metadata:
name: mysubdomain
spec:
selector:
app: my-webapp
clusterIP: None
ports:
- port: 8080
在其它应用Pod中输入 curl >.mysubdomian.defalut.svc.cluster.local:8080可以访问
# Pod中的DNS策略
Kubernetes可以在Pod级别通过dnsPolicy字段设置DNS策略,目前支持的DNS策略如下:
· Default:继承Pod所在宿主机的域名解析设置
· ClusterFirst:优先使用Kubernetes环境的DNS服务(如果CoreDNS提供的域名解析服务),将无法解析的域名转发到系统配置的上游DNS服务器
· ClusterFirstWithHostNet:适用于以hostNetwork模式运行的Pod。
· Node:忽略Kubernetes的DNS配置,需要手工通过dnsConfig自定义DNS配置
---
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
# Pod 中的自定义 DNS 配置
在默认情况下,系统会自动为Pod配置好域名服务其等DNS参数,Kubernetes也提供Pod定义中由用户自定义DNS相关配置的方法。可以通过在Pod定义中设置dnsConfig自动进行DNS相关配置。该字段是可选字段,在dnsPolicy为任意策略时都可以设置,但是当dnsPolicy="None"时必须设置。
自定义DNS可以设置内容:
· nameservers:用于域名解析的DNS服务器列表,最多可以设置3个。当Pod的dnsPolicy="None"时,该nameservers列表必须包含至少一个IP地址。配置的 · nameserver列表会与系统自动设置的nameserver进行合并和去重
· searches:用于域名搜索的DNS域名后缀,最多设置6个,也会与系统设置的合并和去重
· options:配置其它DNS参数,例如,timeout等等
---
apiVersion: v1
kind: Pod
metadata:
name: custom-dns
spec:
containers:
- name: custom-dns
image: tomcat
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
dnsPolicy: "None"
dnsConfig:
nameservers:
- 8.8.8.8
searches:
- ns1.svc.cluster-domain.example
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0
在Pod成功创建后,容器内的配置文件/etc/resolv.conf的内容将被系统设置如下:
root@custom-dns:/etc# cat resolv.conf
nameserver 8.8.8.8
search ns1.svc.cluster-domain.example my.dns.search.suffix
options ndots:2 edns0