HRNet论文笔记及代码详解
《Deep High-Resolution Representation Learning for Visual Recognition》
- 0. 前置知识
-
- 1)图像语义信息理解
- 2)特征金字塔网络(Feature Pyramid Networks,FPN)
- 3)图像插值算法
- 4)Bottleneck 与 Basicblock
- 1. 摘要(Abstract)
- 2. 动机(Motivation)
- 3. 网络结构(Network Architecture)
-
- 1)多分辨率平行支流架构设计( Parallel Multi-Resolution Convolution)
- 2)融合模块(FuseLayer)
- 3)过渡层(TransitionLayer)
- 4)表征头设计(Representation Head)
- 5)源码解析
- 参考目录
paper: Arxiv 、CVPR2019、TPAMI2020
code: 项目主页、Human-Pose-Estimation、Face-Alignment、Image-Classification、Semantic-Segmentation、Object-Detection
Author: 中科大、微软亚研院
0. 前置知识
1)图像语义信息理解
在计算机视觉领域中,一张图像的语义信息通俗的理解就是该图像中包含的人类能定义的一些特征,比如该图像的纹理,颜色,以及图像中目标的眼睛、鼻子、类别、性别,和这张图片想要表达的意思是什么等等。另外,语义信息也有高低之分,更强的语义信息即包含了图片中更多的语义,有人按照其强度的大小将其分为视觉层、对象层和概念层[1]。
- 视觉层指一张图片中包含的底层语义特征,包含轮廓、边缘、颜色、纹理和形状等特征。如果使用CNN对图像的语义特征进行提取,从CNN各层输出的角度来看的话,底层语义特征就是靠近输入的 (浅层)卷积层提取的feature map 。这类特征分辨率较高,包含更多的位置、细节信息,但是由于经过的卷积较少,提取的feature map中语义信息较少,噪声较多。
- 对象层即中间层,通常包含了属性特征等,就是某一对象在某一时刻的状态;
- 概念层即图片中的高层语义特征, 是图像表达出的最接近人类理解的东西。高层语义特征即靠近输出的 (深层)卷积层提取的feature map 。由于随着卷积层的不断增加,feature map映射到原图中的感受野逐渐增大,提取的特征越来越抽象,因此这类特征包含的语义信息更加丰富,分辨率较低,但同时对局部的位置、细节信息感受相对也就更差。
有一个更加通俗的例子,假如一张图上有沙子,蓝天,海水等,视觉层是一块块的区分,对象层是沙子、蓝天和海水这些,概念层就是海滩,这是这张图表现出的语义。
总的来讲,底层语义特征和高层语义特征各有各的用处。比如在关键点检测、目标检测、分割等对位置信息较敏感的视觉任务中,底层语义特征更为重要;在物体分类、人脸识别、情绪识别等对位置信息不敏感但需要较大的感受野和更抽象特征的任务中,高层语义特征更为重要。
2)特征金字塔网络(Feature Pyramid Networks,FPN)
FPN主要是为了在增加极小计算量的情况下,处理好目标检测中多尺度变化的问题(尤其是对于小目标检测)。为了进行目标检测,很多网络都是利用多层卷积+下采样操作来提取图片中的强语义信息[2],然后利用单个高层特征进行检测。但是这样有一个缺陷,即小物体本身具有的像素信息较少,在下采样中极易丢失,并且高层特征的位置信息也很少。针对这个问题,经典的方法有以下几种:
- 基于图像金字塔的特征金字塔。 先构造图像金字塔,然后将这些图像输入至神经网络中提取特征,然后在每一个feature map上做预测,最后综合所有预测计算结果。这种优点是能够产生多尺度的强语义的特征表示,但缺点也很明显,推理速度慢,占用内存巨大等。

- 利用单个高层特征做预测。这种方法常见于目前的目标检测网络中,比如Faster R-CNN中,使用神经网络最后一层的feature map来进行预测。这种高层特征具有强语义信息,但是相应的位置信息是很少的。

- 特征金字塔。使用不同层级的特征(feature map)进行预测,然后对所有的预测进行融合,比如SSD中采用的就是这种多尺度融合的方法。但是这种方法的缺陷就是底层特征图的语义信息不强,并且分辨率也不够高。比如在SSD中为了避免使用低层特征图,是从网络的高层开始构建金字塔(例如,VGG网络的Conv4之后,再添加几个新的卷积层),因此,SSD并没有使用具有高分辨的底层特征图,即没有充分利用到低层特征图中的空间信息(这些信息对小物体的检测十分重要)。

针对以上问题,文章《Feature Pyramid Networks for Object Detection》提出了FPN网络,使得能够在增加较少计算量的前提下,融合低分辨率(空间信息少)但语义信息较强的特征图和高分辨率(空间信息丰富)但语义信息较弱的特征图。FPN的思想就是把高层的特征传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。网络结构示意图如下,输入一张图片,首先经历左边的resnet结构(自底向上)不断提取特征,然后针对最高层的特征,再经历右边结构(自顶向下)传下来,每向下传一层就是经历一次上采样来增大一次分辨率。在向下传递的过程中还有一个横向连接操作,即使左侧与上采样后分辨率相同的特征图进行一次1x1卷积来对齐通道数,再将二者相加在一起(融合),这时就得到了下一层的结果。横向连接的目的主要是为了融合进低层特征中的定位细节信息。最后对右边结构中的每一层特征图做预测,然后融合预测的结果,即得到最终输出。

3)图像插值算法
插值 (Interpolation),通常指内插,既是离散数学名词,也是图像处理术语(图像插值也可称为上采样(upsampling)),二者的联系十分密切。作为图像放缩 (Scale) 的方法,常见的插值方法有:最近邻插值 (Nearest Neighbour Interpolation)、线性插值(Linear Interpolation)、双线性插值 (Bilinear Interpolation)、双三次插值 (Bicubic interpolation) 等乃至更高阶插值。插值的本质是利用已知数据估计未知位置数值,类似于拟合问题,二者均为函数逼近或数值逼近的重要组成部分。但不同之处在于,对于给定的函数,插值要求离散点“坐落在”函数曲线上从而满足约束;而拟合则希望离散点尽可能地“逼近”函数曲线。
推荐一篇博客:https://www.codenong.com/cs105796249/
上采样的目的是为了放大图像,除了内插值的方法外,也可以通过反卷积(通过转置卷积核的方法来实现卷积的逆过程)、反池化(在池化过程,比如max-pooling时,要记录下每个元素对应kernel中的坐标。反池化时即将每一个元素根据坐标填写,其余位置补0.)的方法实现。
4)Bottleneck 与 Basicblock
Bottleneck最先出现于2014年的GooggleNet中,它的主要目的是进行特征的降维,从而减少计算量。为什么称之为Bottleneck(瓶颈层),有种解释是它长得像一个瓶颈,示意图如下。

Bottleneck本质上是一种将信息压缩再放大的神经网络结构,直观讲就是将输入降维之后再升维。为什么要这样做呢?主要有两点原因。
- 为了进行信息的损失。可能有人会疑惑,难道对于模型而言不是信息越多越好吗,但其实答案并不是的。在AI领域中,输入至网络的是一张图像或一段音频,它们本质上都是信号,为了能够保证包含所需信息,在采样时的范围都会很广。比如图像有三个通道,但人脸识别只需一个通道,声音包括高中低频,但支部宝声纹支付只需要高频,其他剩余的信息在这些任务中都属于是噪声(但如果换种任务的话,比如说饮料种类识别,剩余的两个通道(剩余信息)就又变得有用了,不再属于噪声)。因此一张图片中包含的信息多种多样,对我们任务有用的只占部分,也就是说数据中有用的信息只占少数,绝大多数都属于是冗余的噪声,无用信息的损失是必要的。因此通过Bottelneck这种降维之后再升维的网络,可以对实现对无用的信息进行损失。
- 为了精简网络规模,减少参数量。经典的案例就是ResNet50、ResNet101、ResNet152这些深层网络中使用的Bottleneck结构。它相较于ResNet-34中的Basicblock模块,最核心的就是使用了1×1卷积层。如输入通道数为256,1×1卷积层会将通道数先降为64,经过3×3卷积层后,再将通道数升为256。1×1卷积层的优势是在更深的网络中,用较小的参数量处理通道数很大的输入。
Basicblock一般指的是ResNet中的Basicblock模块。下图左边是Basicblock模块,右边是Bottleneck模块。Basicblock包含了两个3 x 3卷积层和一个残差连接,这种模块在ResNet18, ResNet34中被使用,但是当网络的层数变得更深时,其参数量变得很大,对算力的要求变得较高,也就促使了Bottleneck的出现,被应用于ResNet50、ResNet101、ResNet152这些深层网络中。

1. 摘要(Abstract)
高分辨率表征对于像人体姿态估计、语义分割、目标检测等对位置信息敏感的视觉任务极其重要。现有的SOTA框架(比如ResNet、VGGNet)首先通过串联的高分辨率卷积至低分辨率卷积子网络将输入的图像编码为低分辨率表征,然后从已编码的低分辨率表征中回复高分辨率表征。与此相反,本文提出的High-Resolution Network (HRNet), 在整个过程中都保持高分辨率的表征。它有两个重要特点:1)并行连接高低分辨率的卷积流分支;2)不断进行不同分支间的信息交互。通过这两个特点,HRNet同时达到了强语义信息和精准位置信息的目的。本文也展示了HRNet在人体姿态估计、语义分割、目标检测等多种任务中具有强大的优势。
2. 动机(Motivation)
深度卷积神经网络(DCNNs)之所以在众多计算机视觉任务中取得卓越效果,是因为它能学习到相较于传统手工特征更加丰富的表征。最近的分类网络像AlexNet、VGGNet、GoogleNet、ResNet、DenseNet等都遵循了LeNet-5的设计准则,就是如下图(a)所示,逐渐减小特征图的空间大小,将卷积层从高分辨率到低分辨率串联起来,然后产生低分辨率的表征(通过下采样得到)进一步用于分类。

下图是依赖于高到低、低到高分辨率的几个代表性的姿态估计网络。(a)Hourglass;(b)Cascaded pyramid networks; © SimpleBaseline; (d) Combination with dilated convolutions; 在Hourglass、级联金字塔网络中,高到低与低到高过程中同样分辨率的层进行跳跃连接,目的是融合低级和高级的特征。在级联金字塔网络中,通过卷积操作来融合低级和高级特征。

对位置敏感的视觉任务,如语义分割、人体姿态估计和目标检测等,高分辨率表征是重要的。先前的SOTA方法采用的是高分辨率恢复方法来获取高分辨率表征,即像上图(b)所示从分类网络中的低分辨率表征中提高表征的分辨率(一般使用上采样),比如Seg-Net,DeconvNet,U-Net,SimpleBaseline和encoder-decoder等。也有一些网络(DeepLab,PSPNet)使用膨胀卷积来去除一些下采样层从而得到中等分辨率的表征。
本文提出了一个名为HRNet的架构,它能够在整个过程中保持高分辨率的表征。该网络从一个高分辨率的卷积流开始,逐步逐个添加高到低分辨率的卷积流,并且并行连接这些多分辨率的卷积流。最终的网络包含n个阶段,第n个阶段包含n个卷积流,也就对应了n个类别的分辨率。然后作者在这些并行流之间不断地交互信息来进行分辨率融合的操作。
因此HRNet学习到的高分辨率特征不仅具有强语义还具有精准的空间信息。作者称这来自于两个方面:1)HRNet的方法是将高分辨率与低分辨率卷积流并行连接,而不是像以往一样串联连接。因此能够保持高分辨率,而不是从低分辨率中恢复高分辨率,从而使学习到的表征在空间上更精确。2)现今大多数融合策略来聚合高分辨率的低级、高级表征是通过对低分辨率表征进行上采样得到的。但相反,HRNet是在每个阶段都进行高低分辨率融合来互相增强高分辨率、低分辨率的表征。因此在每个阶段的高、低分辨率表征都是具有强语义的。
- 对于作者的这两点贡献,最有新意的是第一点,就是将不同分辨率的卷积流并行化,然后不同分辨率分支的表征进行信息交互,从而达到了从头到尾都是具有强语义的高分辨率表征。第二点信息交互其实很多网络都已实现过。
本文共推出了两个版本的网络:HRNet-V1、HRNet-V2。HRNet-V1只将高分辨率卷积流计算的高分辨率表征输出,在COCO人体姿态估计任务上的表现优于HRNet-V2。HRNet-V2将所有从高到底分辨率分支计算的表征结合之后作为输出,在语义分割任务上优于HRNet-V1。此外,作者还从HRNet-V2的高分辨率表征中构建了一个多级别表征,应将它应用于SOTA目标检测框架(Faster R-CNN, Cascade R-CNN, FCOS, CenterNet等)、SOTA联合目标检测和实例分割框架(Mask R-CNN, Cascade Mask R-CNN, Hybride Task Cascade等)。最后结果显示该方法提高了检测性能,特别是对小物体的性能显著提高。
3. 网络结构(Network Architecture)
1)多分辨率平行支流架构设计( Parallel Multi-Resolution Convolution)
下图是HRNet的整体架构,水平和垂直方向分别代表了网络的深度和feature map的尺度。整个网络由四个阶段的子网络组成,每个阶段都比上一个阶段新增一条支流,新增的支流比上层的支流分辨率减半,但通道数增加一倍。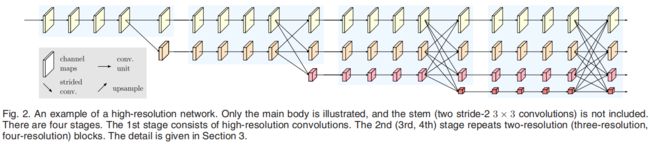
在第一个阶段只有一条卷积流,分辨率为最高,进入下一阶段后新增一条更低分辨率支流,并将他们平行化。下图是架构示意图,第一个下标表示第几阶段,第二个阶段表示第几种分辨率,第r种分辨率的大小是1/2(r-1)倍的初始分辨率。

在项目主页作者给出的预训练模型中的有两种:HRNet-W32和HRNet-W48。32和48表示最高分辨率的这条支流在最后三个阶段的通道数分别是32和48。其他三条平行支流的通道数分别是(64,128,256)和(96,192,384)。每新增一条平行直流,分辨率减半,通道数增加一倍。
2)融合模块(FuseLayer)
融合模块的目的是每个阶段的每条支流的输出都能从其他并行支流的输出中接收信息。以3个表征的融合模块为例,如下图所示,输入是三个表征:
![]()
输出也是3个表征:
![]()
r是第i个表征,i表示输入,o表示输出。每个输出的表征都是3个输入表征经过变换后再相加起来的结果,计算公式为
![]()
其中f_xr(·)是转换函数,第一个下标x对应第x个输入,第二个下标r对应第r个输出。当x=r时,也就是下图中黑色框的情况 ,对表征不做任何转换,f_xr( R)=R。当x

代码如下
def _make_fuse_layers(self):
fuse_layers = []
for post_index, out_channel in enumerate(self.out_channels[:len(self.in_channels)]):
fuse_layer = []
for pre_index, in_channel in enumerate(self.in_channels):
if pre_index > post_index:
fuse_layer.append(nn.Sequential(
nn.Conv2d(in_channel, out_channel, 1, 1, 0, bias=False),
nn.BatchNorm2d(out_channel, momentum=0.1),
nn.Upsample(scale_factor=2**(pre_index-post_index), mode='nearest')))
elif pre_index < post_index:
conv3x3s = []
for cur_index in range(post_index - pre_index):
out_channels_conv3x3 = out_channel if cur_index == post_index - pre_index - 1 else in_channel
conv3x3 = nn.Sequential(
nn.Conv2d(in_channel, out_channels_conv3x3, 3, 2, 1, bias=False),
nn.BatchNorm2d(out_channels_conv3x3, momentum=0.1)
)
if cur_index < post_index - pre_index - 1:
conv3x3.add_module('relu_{}'.format(cur_index), nn.ReLU(False))
conv3x3s.append(conv3x3)
fuse_layer.append(nn.Sequential(*conv3x3s))
else:
fuse_layer.append(None)
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
def forward(self, x):
x_fuse = []
for post_index in range(len(self.fuse_layers)):
y = 0
for pre_index in range(len(self.fuse_layers)):
if post_index == pre_index:
y += x[pre_index]
else:
y += self.fuse_layers[post_index][pre_index](x[pre_index])
x_fuse.append(self.relu(y))
3)过渡层(TransitionLayer)
TransitionLayer是通过一个步长为2的3x3卷积层(两倍下采样)来生成一个分辨率减半的feature map,以当作下个阶段新增加支流的输出,在源码中它的位置位于fuselayer之后。并且不同于原文中将上个阶段所有支流的输出进行下采样之后相加,源码中只对上个阶段最低分辨率支流的输出进行下采样,得到feature map。源码如下。
def _make_transition_layer(
self, num_channels_pre_layer, num_channels_cur_layer):
# 以self.transition1为例,num_channels_pre_layer=[256], num_channels_cur_layer=[18,36]
num_branches_cur = len(num_channels_cur_layer) # 过渡后阶段包含的branch数
num_branches_pre = len(num_channels_pre_layer) # 过渡前阶段包含的branch数
transition_layers = []
for i in range(num_branches_cur): # 对后一个阶段每一个branch进行遍历
if i < num_branches_pre: # 后一阶段branch索引小于前一阶段branch索引时
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
# 过渡后该branch通道与过渡前该branch通道不一致时,
# 则增加一个卷积层将通道数从256降维至18,同时stride=1不改变尺寸。
transition_layers.append(nn.Sequential(
nn.Conv2d(num_channels_pre_layer[i],
num_channels_cur_layer[i],
3,
1,
1,
bias=False),
BatchNorm2d(
num_channels_cur_layer[i], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)))
else:
transition_layers.append(None)
else: # 后一阶段branch索引大于等于前一阶段branch索引时
conv3x3s = []
for j in range(i + 1 - num_branches_pre):
inchannels = num_channels_pre_layer[-1]
# 当两者是一个branch时,输出与输入维度相同,都为前一个阶段的最后branch输出的维度
# 否则输出维度为后一阶段当前branch的维度
outchannels = num_channels_cur_layer[i] \
if j == i - num_branches_pre else inchannels
# 步长为2,下采样,尺寸缩小两倍
conv3x3s.append(nn.Sequential(
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False),
BatchNorm2d(outchannels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)))
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
def forward(self, x):
x_trans = []
for branch_index, transition_layer in enumerate(self.transition_layers):
if branch_index < len(self.transition_layers) - 1:
if transition_layer:
x_trans.append(transition_layer(x[branch_index]))
else:
x_trans.append(x[branch_index])
else:
x_trans.append(transition_layer(x[-1]))
4)表征头设计(Representation Head)
在TPAMI2020版本的文章中,作者在原有的基础上进行了改进,加上初始版本,共有三种表征头以用于不同的任务。可视化图如下所示。V1版本的输出只来自于最高分辨率卷积流的输出,适用于人体姿态估计任务。V2版本的输出, 首先将3个低分辨率支流的输出通过双线性插值放大到最大分辨率的尺度,注意此时没有使用卷积层,因此各个表征的通道数不变,然后将他们拼接在一起之后,再经过一个1x1的卷积层混合四种表征,然后输出,这个版本 适用于语义分割任务。V2p版本的输出是对V2输出的改进,它对V2的输出进行了多层降采样来构建多级别的输出,这个版本的输出适用于目标检测任务。

5)源码解析
对于输入的一张图片,在网络的头部首先是一个stem net,用于将输入的image(尺寸为256)简要处理成尺寸为C(64)特征图,在此之后的四个阶段,每个阶段的最高分辨率branch都保持C尺寸。第一个阶段的网络包含了四个残差单元,每个单元用的是Bottelneck。第2-4个阶段的子网络分别用了1,4,3个模块化的HR模块,在2-4阶段的每一个模块化的HR模块均由4个Basicblock构成。这个HR模块是源码中的核心代码,相当于是一个已经模块化好的类,重复调用即可用于搭建第2-4阶段的子网络。
Bottelneck和Basicblock代码如下,跟Resnet中的代码一样。
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
以用于人脸关键点检测的HRNet版本为例,核心代码如下。
class HighResolutionNet(nn.Module):
def __init__(self, config, **kwargs):
self.inplanes = 64
extra = config.MODEL.EXTRA
super(HighResolutionNet, self).__init__()
# stem net 在网络的头部,用于将输入的image(尺寸为256)简要处理成尺寸为C(64)特征图。
# 在此之后的四个阶段,每个阶段的最高分辨率branch都保持C尺寸。
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn1 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn2 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.sf = nn.Softmax(dim=1)
self.layer1 = self._make_layer(Bottleneck, 64, 64, 4) # 使用Bottleneck搭建第一阶段
self.stage2_cfg = extra['STAGE2']
num_channels = self.stage2_cfg['NUM_CHANNELS'] # [18,36]
block = blocks_dict[self.stage2_cfg['BLOCK']] # "BASIC" , 此时使用BasicBlock模块搭建剩余3个阶段
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))] # Basicblock.expansion = 1
self.transition1 = self._make_transition_layer(
[256], num_channels)
self.stage2, pre_stage_channels = self._make_stage(
self.stage2_cfg, num_channels)
self.stage3_cfg = extra['STAGE3']
num_channels = self.stage3_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage3_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition2 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage3, pre_stage_channels = self._make_stage(
self.stage3_cfg, num_channels)
self.stage4_cfg = extra['STAGE4']
num_channels = self.stage4_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage4_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition3 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage4, pre_stage_channels = self._make_stage(
self.stage4_cfg, num_channels, multi_scale_output=True)
final_inp_channels = sum(pre_stage_channels)
self.head = nn.Sequential(
nn.Conv2d(
in_channels=final_inp_channels,
out_channels=final_inp_channels,
kernel_size=1,
stride=1,
padding=1 if extra.FINAL_CONV_KERNEL == 3 else 0),
BatchNorm2d(final_inp_channels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True),
nn.Conv2d(
in_channels=final_inp_channels,
out_channels=config.MODEL.NUM_JOINTS,
kernel_size=extra.FINAL_CONV_KERNEL,
stride=1,
padding=1 if extra.FINAL_CONV_KERNEL == 3 else 0)
)
def _make_transition_layer(
self, num_channels_pre_layer, num_channels_cur_layer):
# 以self.transition1为例,num_channels_pre_layer=[256], num_channels_cur_layer=[18,36]
num_branches_cur = len(num_channels_cur_layer) # 过渡后阶段包含的branch数
num_branches_pre = len(num_channels_pre_layer) # 过渡前阶段包含的branch数
transition_layers = []
for i in range(num_branches_cur): # 对后一个阶段每一个branch进行遍历
if i < num_branches_pre: # 后一阶段branch索引小于前一阶段branch索引时
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
# 过渡后该branch通道与过渡前该branch通道不一致时,
# 则增加一个卷积层将通道数从256降维至18,同时stride=1不改变尺寸。
transition_layers.append(nn.Sequential(
nn.Conv2d(num_channels_pre_layer[i],
num_channels_cur_layer[i],
3,
1,
1,
bias=False),
BatchNorm2d(
num_channels_cur_layer[i], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)))
else:
transition_layers.append(None)
else: # 后一阶段branch索引大于等于前一阶段branch索引时
conv3x3s = []
for j in range(i + 1 - num_branches_pre):
inchannels = num_channels_pre_layer[-1]
# 当两者是一个branch时,输出与输入维度相同,都为前一个阶段的最后branch输出的维度
# 否则输出维度为后一阶段当前branch的维度
outchannels = num_channels_cur_layer[i] \
if j == i - num_branches_pre else inchannels
# 步长为2,下采样,尺寸缩小两倍
conv3x3s.append(nn.Sequential(
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False),
BatchNorm2d(outchannels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)))
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
def _make_layer(self, block, inplanes, planes, blocks, stride=1):
# 该函数也是ResNet中对bottleneck模块使用的代码
# inplanes是输入特征图的维度,输出特征图的维度是planes * block.expansion
# block.expansion是bottleneck的类属性,此处定义为4,表示通过卷积层扩展特征维度的倍数。
# 当输入输出的维度不一致时,shortcut存在,也就是downsample,内部的操作是一个卷积层加一个BN,目的是增加特征维度以用于残差连接
downsample = None
if stride != 1 or inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(inplanes, planes, stride, downsample)) # 第一个unit输入输出维度不同(输入64维,输出256维),有shotcut
inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(inplanes, planes)) # 第2-4个unit输入输出维度相同(输入256维,输出256维),无shotcut
return nn.Sequential(*layers)
def _make_stage(self, layer_config, num_inchannels,
multi_scale_output=True):
# num_modules表示该阶段使用了多少个模块化的HR模块,第2,3,4阶段的num_modules分别是1,4,3
# 第2,3,4阶段的每一个模块化的HR模块均有4个Basicblock构成
num_modules = layer_config['NUM_MODULES']
num_branches = layer_config['NUM_BRANCHES']
num_blocks = layer_config['NUM_BLOCKS']
num_channels = layer_config['NUM_CHANNELS']
block = blocks_dict[layer_config['BLOCK']]
fuse_method = layer_config['FUSE_METHOD']
modules = []
for i in range(num_modules):
# multi_scale_output is only used last module
if not multi_scale_output and i == num_modules - 1:
reset_multi_scale_output = False
else:
reset_multi_scale_output = True
modules.append(
HighResolutionModule(num_branches,
block,
num_blocks,
num_inchannels,
num_channels,
fuse_method,
reset_multi_scale_output)
)
num_inchannels = modules[-1].get_num_inchannels() # 该阶段最后一个module各支流的输入的通道数
return nn.Sequential(*modules), num_inchannels
def forward(self, x):
# h, w = x.size(2), x.size(3)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x) # (bs, 64, 64, 64)
x = self.layer1(x) # (bs, 64, 64, 256)
x_list = []
for i in range(self.stage2_cfg['NUM_BRANCHES']): self.stage2_cfg['NUM_BRANCHES']==2
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x))
else:
x_list.append(x)
y_list = self.stage2(x_list)
x_list = []
for i in range(self.stage3_cfg['NUM_BRANCHES']):
if self.transition2[i] is not None:
x_list.append(self.transition2[i](y_list[-1]))
else:
x_list.append(y_list[i])
y_list = self.stage3(x_list)
x_list = []
for i in range(self.stage4_cfg['NUM_BRANCHES']):
if self.transition3[i] is not None:
x_list.append(self.transition3[i](y_list[-1]))
else:
x_list.append(y_list[i])
x = self.stage4(x_list)
# Head Part
height, width = x[0].size(2), x[0].size(3)
# 线性插值之后再拼接在一起,完成强语义且高分辨率的特征提取。
x1 = F.interpolate(x[1], size=(height, width), mode='bilinear', align_corners=False)
x2 = F.interpolate(x[2], size=(height, width), mode='bilinear', align_corners=False)
x3 = F.interpolate(x[3], size=(height, width), mode='bilinear', align_corners=False)
x = torch.cat([x[0], x1, x2, x3], 1)
x = self.head(x) # 检测头
return x
参考目录
[1] https://blog.csdn.net/qq_30121457/article/details/108918519
[2] https://zhuanlan.zhihu.com/p/397293649