本文首发于微信公众号“Shopee技术团队”
摘要
传统的客户端监控分析场景中,采用按照具体的 URL 进行统计分析的方法,在面对一个应用可能会访问成千上万条 URL 时,结果就差强人意,不能明显地标识出应用访问的哪些 URL 存在潜在问题。
MDAP 平台在进行客户端监控分析时,通过使用概率统计和机器学习的方案,将若干条相似的 URL 归一化成同一条规则模型,然后基于该规则模型进行相关统计分析,从而提高了基于 URL 的客户端监控分析的可用性及准确性,进而提高了 MDAP 用户对自己应用质量的监控分析。
这是 MDAP 系列的第二篇文章,前文回顾:《MDAP:可观测性数据分析平台设计与实践》
1. 引言
URL 作为客户端监控分析的一个重要元素,传统的基于 URL 的统计分析方式直接使用原始 URL 值进行统计分析,比如:
SELECT `url`, count(1) as `cnt`
FROM `web_analysis_tab`
WHERE `app_name` = 'app_1'
GROUP BY `url`;使用上述查询语句进行统计分析的结果是非常糟糕的,主要表现在以下几个方面:
- 应用开发者无法快速地、准确地通过分析结果定位、发现潜在的应用问题、风险;
- 统计结果过于分散,用户可能会失去查看统计分析结果的兴趣;
- 平台处理过滤离散数据的统计分析,可能存在较大的系统开销,包括:查询效率、网络传输、页面展示等。
比如,假设 app_1 访问过 1,000,000 个不同值的 URL,而其 URL 规则模型不足 100 个。

初版的 MDAP(Multi-Dimension Analysis Platform,多维度分析平台)用户和开发者同样面对此类问题的困扰。为了更好地服务 MDAP 用户,协助 MDAP 用户快速、有效地分析自己的应用质量。MDAP 平台基于概率统计理论和机器学习技术,根据应用上报的 URL,自动学习出相应的 URL 模型,利用衍生字段 url_pattern 而非原始 url 进行统计分析,从而大幅度减少了基于 URL 统计分析过于散列的情况,使得统计分析结果更加收敛,进而更方便用户使用 MDAP 对自己的应用质量进行分析查看。
本文剩余部分的结构安排如下:在第 2 节中,结合具体例子讲解 MDAP 对解决 URL 归一化问题的思考。第 3 节,介绍 MDAP 是如何对 URL 进行归一化处理的总体框架,并在第 4 节中进行详细的算法描述。优化效果的测试与评估在第 5 节中进行阐述。最后,在第 6 节中,进行总结并对未来进行展望。
2. 问题思考
本章节将解释这项工作的详细动机和思考。针对三种不同方案进行分析,阐述配置/上传 URL 模型规则的不可行性;通过一个具体的例子,展示自底向上的成对策略如何工作以及何时失败;并解释模式树为何有效。
2.1 用户配置方案
配置/上传 URL 模型规则
为了将 URL 转换成对应的 URL 模型规则,最先考虑的方案是在平台中,允许用户配置/上传应用相关的 URL 模型规则,但随即我们发现该方案存在几点问题:
- 繁琐的用户配置。MDAP 平台的宗旨是为了协助平台用户监控、统计、分析自己的应用质量。为了进行 URL 模型匹配而需要平台用户配置/上传 URL 模型规则,无疑增加了平台用户的负担。同时,平台用户极有可能遗忘进行新的 URL 模型规则变更,从而严重影响 URL 模型匹配效果,进而回退到传统的基于 URL 统计分析模型。
差异化的 URL 模型规则。不同语言、框架的 URL 路由规则差异大,巨大的风格差异不利于平台进行 URL 规则模型的统一管理,比如下面三种获取某一具体用户详情信息的 URL 模型规则:
- golang/gin:
GET http://example.com/users/:user_name; - golang/grpc-gateway:
GET http://example.com/{name=users/*},遵守 Google API 设计规范; - java/spring:
GET http://example.com/users/{user_name}。
- golang/gin:
- 数据巨大的外部 URL。根据 MDAP 平台统计分析,单应用访问非本应用服务的外部 URL 地址数量平均占比约为 10%-30%。这些外部 URL 多为 Google、Facebook 等网站的路由地址,使用 MDAP 平台的用户在开发自己应用的时候,并不完全了解外部 URL 的模型规则,因此无法在 MDAP 平台进行相关的配置。
综上所述,基于用户自主配置 URL 模型规则的方案是不可行的。因此,MDAP 平台需要基于应用上报的 URL 自动学习对应的 URL 规则模型。
2.2 机器学习方案
2.2.1 URL 协议语法介绍
为了帮助读者更好地理解后续算法设计以及 MDAP 思考解决问题的思路,本文需要对 URL 的语法结构进行简单介绍,如下图所示:

根据上图所示,我们可以将 URL 分解为一些通用的 URL 组件:schema、authority、path、query 及 fragment,其通过 :、/、? 及 # 进行分割。例如,URL http://example.com/books/search?name=go&isbn=1234 可以分解成如下几部分组件:
schema: http
authority: example.com
path: {"path0": "books", "path1": "search"}
query: {"name": "go", "isbn": "1234"}在稍后的算法设计中,本文重点关注 path 和 query 两部分数据,将上述 URL 转换成 Tuple(authority, Array[Tuple(K, V)])的结构,具体如下:
(
"example.com",
[
("path0", "books"),
("path1", "search"),
("name", "go"),
("isbn", "1234")
]
)2.2.2 自底向上结对策略思考

如上图所示,其中存在 8 条不同的 URL,MDAP 采用 2.2.1 将每条 URL 转换成 KV 结构,比如:U1 -> {"K1": "a", "K2": "b", "K3": "y", "K4": "c", "K5": "*"}。使用自底向上策略生成 URL 规则模型的方式,可以清楚地看到 K3 和 K5 应该被归一化为 *。其归一化过程如下:
- U5 + U6 -> P1:
({"K1": "a", "K2": "b", "K3": "y", "K4": "c", "K5": "*"}) - U7 + U8 -> P2:
({"K1": "a", "K2": "b", "K3": "z", "K4": "c", "K5": "*"}) - P1 + P2 -> P3:
({"K1": "a", "K2": "b", "K3": "*", "K4": "c", "K5": "*"})
上述步骤首先基于 U5、U6 和 U7、 U8 分别生成 P1 和 P2,然后基于 P1、P2 生成理想的 URL 模型规则 P3。但如果 U6 不存在的话,就会导致 P1 无法生成,进一步 P3 也无法生成。此外,在上述示例中 U1 - U4 同样不适合用来结对生成规则模型。
2.2.3 URL 模式树
相对于自底向上策略,模式树可以充分利用整个训练集的统计信息。这样,学习过程变得更加可靠和稳健,不再受到随机噪声的影响。对于 2.2.2 中的示例,即使某些 URL 不存在,仍然可以通过考虑所有其他 URL(包括 U1 ∼ U4)。
其次,使用模式树,可以通过直接基于树节点总结规则来显着提高学习效率。例如,不再需要 P1 和 P2,可以根据上述模式直接生成 P3。详细的算法描述将在第 4 节中进行阐述。
3. 框架总览
本章节将阐述 MDAP 进行 URL 模型规则学习和匹配的方法和架构。
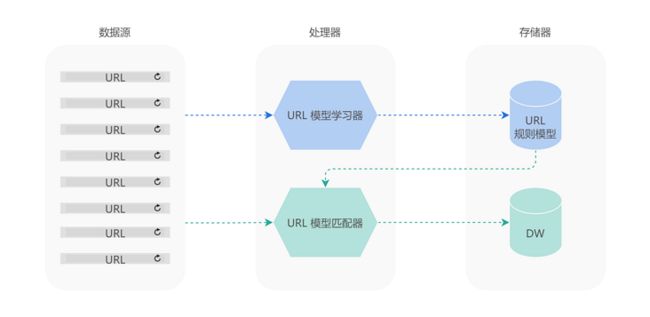
如上图所示:
- 首先,MDAP 使用 URL 模型学习器,基于应用上报的 URL 数据,自动学习出 URL 规则模型,并将其进行存储;
- 然后,在 URL 模型匹配器中,MDAP 将 URL 规则模型作用于应用上报的 URL 数据,生成元组
Tuple(url, url_pattern)后,将其存入数据仓库之中。
考虑到各应用上报到 MDAP 的 URL 数据量巨大,MDAP 平台使用 Flink 进行 URL 模型规则学习,具体如下:
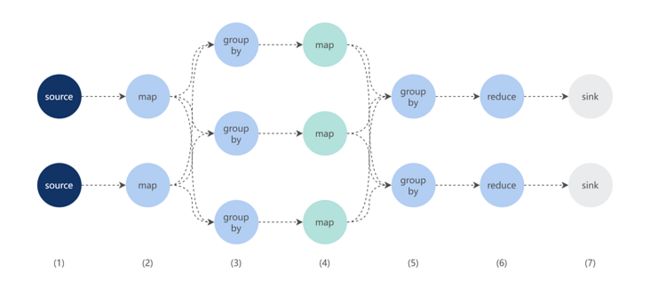
- 从数据源中读取 URL 数据;
- 按照 2.2.1 将各 URL 转化成
Tuple(authority, Array[Tuple(K, V)])的结构; - 按照
authority + salt将步骤 2 生成的结果分组,其中authority定义参考 2.2.1,salt用来解决大数据计算时的数据倾斜问题,可根据实际情况选择不同的数据作为salt,比如:length(Array[Tuple(K, V)]); - 对同一分组下的 URL,使用模式树算法生成 URL 规则模型;
- 再按照
authority将步骤 4 生成的结果分组; - 合并相同
authority下的模型; - 保存 URL 规则模型。
关于 URL 模型匹配器,MDAP 使用了 Trie 的衍生变种结构,来提升 URL 模型匹配的效率,在本文中不再赘述,感兴趣的读者可以去了解学习 Trie 这种数据结构。
4. 算法描述
本章节将阐述如何基于模式树生成 URL 规则模型,重点阐述基于熵进行节点分裂及基于高斯分布、马尔可夫链进行显著值、离散值区分。
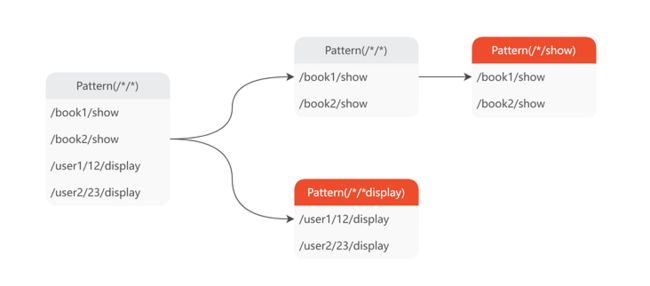
如上图所示,生成 URL 规则模型的算法包括以下 6 步:
- 初始化模式树根节点,其包含全部 URL;
- 找出值元素最适合分裂的 URL 键(
path_index或query_key); - 区分出第 2 步找出的 URL 键对应的显著值(Salient Value)和离散值(Trivial Value);
- 将显著值保留,并将离散值归一化为
*,并基于显著值和*分裂模式树; - 重复 2-4 步,直至所有的 URL 键都已处理;
- 遍历模式树的叶子节点,收集各 URL 节点的模型规则。
在本算法中,最关键的两个步骤为第 2 步和第 3 步。
4.1 找出值元素最适合分裂的 URL 键
信息熵的概念用来解决如何找出最适合分裂的 URL 键。根据值越随机的 URL 键,其熵越大。尽可能聚合键值变化少的部分,把变化多的部分后置计算或进行通配处理,因此,需要找到可以最小化熵的 URL 键。计算 URL 键对应的熵的公式如下:

其中,V 为该 URL 键对应的值元素的个数,N 为全部元素出现的总次数,vi 为第 i 个元素出现的频次。
根据上述公式,查找出熵最小的 URL 键,并结合 4.2 区分出显著值和离散值,即可进行模型树节点分裂。
4.2 区分显著值和离散值
4.2.1 基于高斯分布区分显著值和离散值
根据对 MDAP 收集的 URL 历史数据的分析结果,假设 URL 中每个键对应的值列表服从高斯分布:
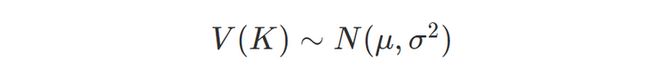
因此,将熵最小的键的值按照其频次进行倒序排序,并对计算相邻的两个值之间的频次下降速度,以下降速度最大的两个节点为界,即可区分出显著值和离散值,其中分界点之左为显著值,之右为离散值,比如:
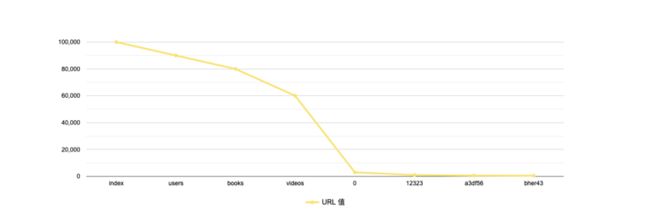
在上图中,频次速度下降最大两个节点为 videos 和 0,因此,显著值包括:
["index", "users", "books", "videos"]离散值包括:
["0", "12323", "a3df56", "bher43"]4.2.2 基于马尔可夫链和密度函数进行剪枝
虽然按照 4.2.1 可以区分显著值和离散值,但其效果并非总是有效,比如:

在上图中,如 URL 键对应的值服从蓝色线条的高斯分布,则通过 4.2.1 可区分出显著值和离散值;但如果 URL 键对应的值服从橙色线条甚至是比橙色线条更扁平的高斯分布,则极容易将离散值误判为显著值,因此需要辅助算法进行剪枝操作。
根据 MDAP 平台对 URL 数据的分析,发现离散的 URL 符合以下几个特征:
- 数字,比如:
/users/123中的123; - 哈希值,比如:
/files/12af8712中的12af8712; - base64,比如:
/something/aGVsbG8K中的aGVsbG8K等其他非人类语言。
满足以上特征的(除数字外)字符串统称为乱语(Gibberish)。为了对乱语和数字类型的 URL 键值进行剪枝,MDAP 引入马尔可夫链和密度函数进行乱语、数字识别,但由于缩略词(Abbreviate)不属于人类标准的语言,有极大概率被误判成乱语,因此需要配置缩略词表进行先验判断。具体算法步骤如下:
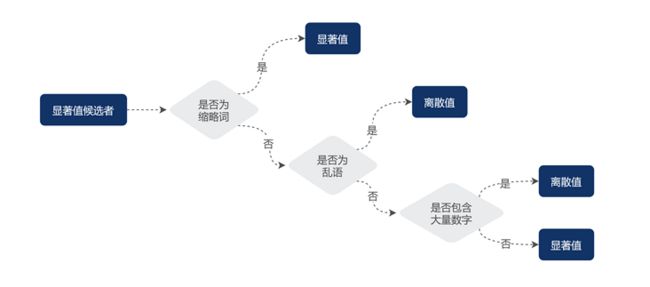
- 判断给定字符串是否在缩略词表,如果是,保留其为显著值并结束,否则继续后续步骤;
- 判断给定字符串是否为乱语,如果是,将其归为离散值并结束,否则继续后续步骤;
- 判断给定字符串是否含有大量数字,如果是,将其归为离散值,否则保留其为显著值。
基于马尔可夫链进行乱语判别
马尔可夫链在 NLP(自然语言处理)中广泛使用,MDAP 平台使用马尔可夫链的方式比较简单,通过 2-gram 的方式进行字符串分词,从而计算连续字符串出现的概率,比如:

使用马尔可夫链,将大文本作为训练集,生成相应的概率矩阵:

然后,将该矩阵作用于好文本和坏文本,计算出判断字符串是否为乱语的阈值:
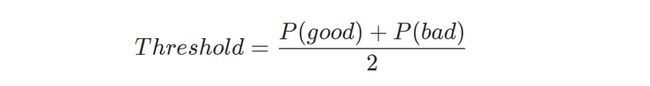
最后,通过下面的公式判断给定的字符串是否为乱语:
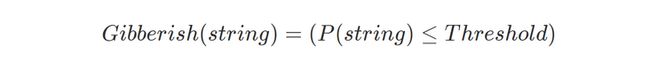
基于密度函数进行数字含量判别
考虑到主要版本号之类的字符串,比如 v1,需要保留为显著值,而像用户 ID 之类的字符串,比如 1234,需要被归类成离散值,因此需要采用如下的公式,进行字符串数组含量判断。
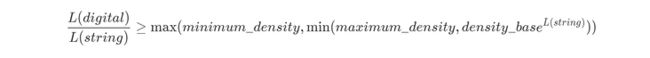
5. 算法优化测试与效果展示
本章节将展示使用模式树生成 URL 规则模型的去重效果、URL 匹配度,并展示在 MDAP 平台中的实际效果。
5.1 算法优化测试
5.1.1 压缩率测试
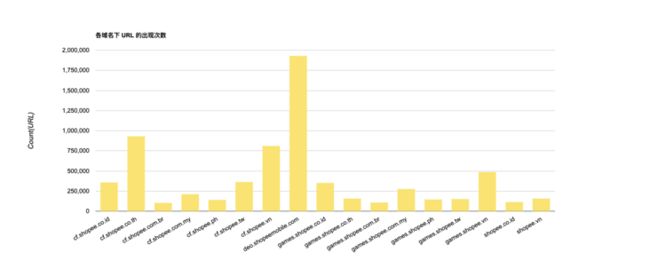
首先,MDAP 收集一部分来自生产环境的数据作为训练集来生成 URL 规则模型,其中各域名包含 100,000 - 2,000,000 原始 URL 数据,具体如下图所示:
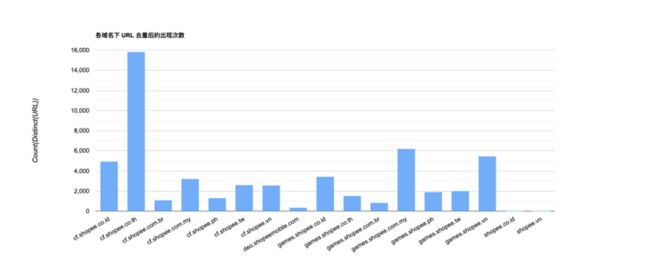
然后,将原始 URL 进行 distinct 去重后得到 10 - 16,000 条 URL,具体如下图所示:
最后,将原始 URL 经过第 4 节的算法处理后,生成的 URL 规则模型条数为 1 - 85 条,具体如下图所示:

通过对比去重 URL 和 URL 规则模型的统计效果图,可以明显发现,通过模式树生成的 URL 模型规则的数量远小于简单 distinct 去重的结果。
5.1.2 匹配度测试
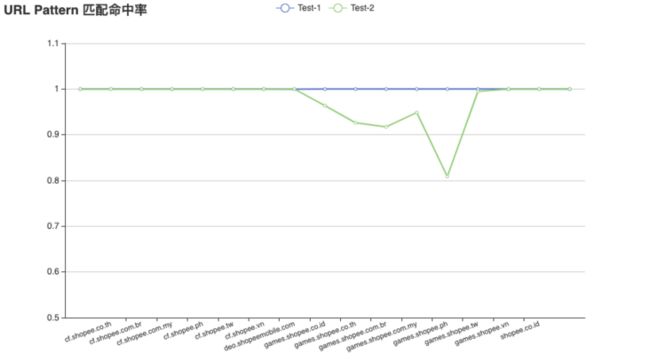
将 5.1.1 生成的 URL 规则模型在两个不同的测试集之间进行验证,其中测试集 1(Test-1)为与训练集同日但不同时间段的数据,测试集 2(Test-2)为距离测试集 1 一周之后的数据。如上图所示,测试集 1 的数据匹配规则模型的命中率很高(大于等于 99.99%),测试集 2 的命中率相对较差(80.89% - 100%)。
5.1.3 测试结论
通过 5.1.1 和 5.1.2 的测试结果,可以得出以下结论:
- 基于模式树生成的 URL 规则模型进行统计分析,可以极大地统计分析结果的收敛度;
- URL 与模型规则的匹配度随训练时间与匹配时间的范围变化而变化,相差时间越近,匹配度越好。
5.2 效果展示
MDAP 平台目前使用 T + 1 的方式进行 URL 规则模型匹配,基于平台数据监测统计结果,模型规则的平均匹配失败率约为 0.3%。
使用模型下规则基于 URL 统计分析的页面展示效果如下,其中第一张图为基于 distinct 去重后的 URL 进行统计分析(约 8110 条),第二张图为基于 URL 规则模型进行统计分析(约 60 条)。
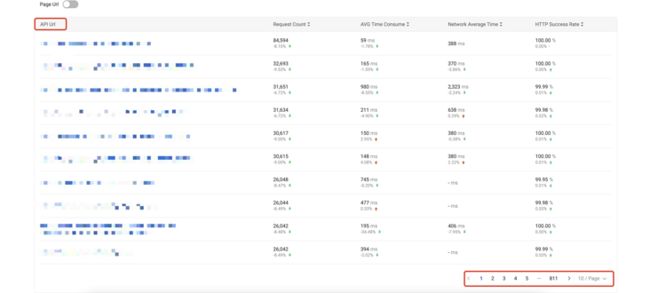

6. 总结与展望
MDAP 平台基于模型树构建实现了 URL 归一化处理,并基于归一化的结果提高了基于 URL 进行统计分析的能力和准确性。
但目前仍然存在一定缺陷,主要包括两方面:
- 规则学习周期相对较长,对于准实时数据处理能力较差;
- 模型迭代功能尚未完善,存在一定缺陷。
因此,后续 MDAP 平台将在此两方面进行进一步优化,从而提高 MDAP 在基于 URL 进行统计分析时的数据质量。
参考资料
- A pattern tree-based approach to learning URL normalization rules
- https://github.com/rrenaud/Gibberish-Detector
- https://en.wikipedia.org/wiki/URL
本文作者
Daniel,后端工程师,来自 Shopee Engineering Infrastructure 团队。