ClickHouse单机和集群安装及图形化工具Tabix
ClickHouse单机安装部署
测试环境:centos7,单节点
1.检查SSE 4.2 指令集
ClickHouse 目前通过 SSE 4.2 指令集实现向量化的执行引擎来加速查询,向量化执行可以简单的看作一项消除程序中循环的优化,为了实现向量化需要利用 CPU 的 SIMD (Single Instruction Multiple Data)指令,通过单条指令可以实现操作多条数据。在现代计算机中是通过数据并行来提高性能,其原理就是在 CPU 寄存器层面实现数据的并行操作。
下面是检查当前CPU是否支持SSE 4.2的命令:
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
返回SSE 4.2 supported表示支持,如果不支持,可以下载源码进行安装,这里暂不讨论。
![]()
2. 使用yum方式安装RPM包
普通用户需要有sudo权限
sudo yum install yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
如果您想使用最新的版本,请用testing替代stable(只推荐用于测试环境)。prestable有时也可用。
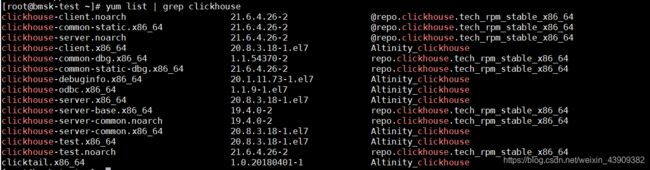
2.1 查看安装包
yum list | grep clickhouse
2.2 运行命令安装
sudo yum install clickhouse-server clickhouse-client
2.3 启动服务端
systemctl start clickhouse-server
2.4 查看服务状态
systemctl status clickhouse-server
如果服务没有启动,可以试试重启虚拟机,我当时就是这样的,汗…
3.启动客户端
clickhouse-client

退出客户端: q;

多行输入:clickhouse-client -m,这样后面写sql可以多行输入,不然就只能写在一行。
其它操作可以查看:clickhouse官方中文文档
ClickHouse集群安装部署
测试环境:centos7,三节点
1. 集群部署
ClickHouse的集群安装就是在每台机器上安装ClickHouse的服务端以及客户端,所以先在每台机器上重复上面的单机安装步骤。
2. 修改config.xml
vi /etc/clickhouse-server/config.xml
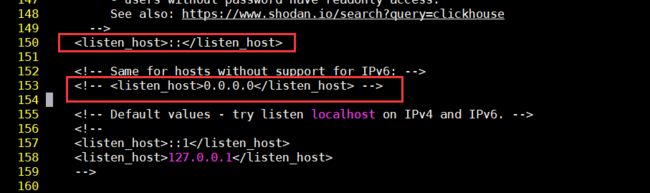
如果支持IPv4和ipv6,把
如果不支持IPv6,则将
添加后面需要创建的metrika.xml文件的路径以及remote_servers和zookeeper的配置:
<include_from>/etc/clickhouse-server/metrika.xml</include_from>
<remote_servers incl="clickhouse_remote_servers" optional="true" />
<zookeeper incl="zookeeper-servers" optional="true" />
3.添加集群配置文件metrika.xml
<yandex>
<!-- /etc/clickhouse-server/config.xml 中配置的remote_servers的incl属性值,需要在config.xml中指定,默认为remote_servers-->
<remote_servers>
<clickhouse_cluster> <!-- 自定义的集群名 -->
<!-- 数据分片1 -->
<shard>
<weight>1</weight> <!-- 写入数据时的分片权重。默认值:1-->
<!-- 是否仅将数据写入其中一个副本。 默认值:false(将数据写入所有副本)-->
<internal_replication>true</internal_replication>
<!-- 分片1的副本,只设置一个,就是它本身 -->
<replica>
<host>192.168.x.xxx</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.x.xxx</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.x.xxx</host>
<port>9000</port>
</replica>
</shard>
</clickhouse_cluster><!-- 自定义的集群名 -->
</remote_servers>
<!-- 本节点副本名称 -->
<macros>
<replica>192.168.x.xxx</replica>
</macros>
<!-- 监听网络-->
<networks>
<ip>::/0</ip>
</networks>
<!-- /etc/clickhouse-server/config.xml 中配置的zookeeper的incl属性值,需要在config.xml中指定,默认为zookeeper-->
<!--zookeeper相关配置-->
<zookeeper-servers>
<!-- index是连接zookeeper的顺序,zookeeper中节点的index顺序需要与主机名或者ip匹配,不一定一一对应,可以去查看一下你部署的zookeeper主机映射,保证节点映射匹配-->
<node index="1">
<host>192.168.x.xxx</host>
<port>2181</port>
</node>
<node index="2">
<host>192.168.x.xxx</host>
<port>2181</port>
</node>
<node index="3">
<host>192.168.x.xxx</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
4. 分发修改
将配置文件分发到其他的ClickHouse节点上,并修改
<macros>
<replica>192.168.x.xxx</replica>
</macros>
为自己的主机映射名。
5. 启动集群
clickhouse-client -m
ClickHouse可视化界面
这里演示ClickHouse Web 界面 Tabix.
主要功能:
- 浏览器直接连接 ClickHouse,不需要安装其他软件。
- 高亮语法的编辑器。
- 自动命令补全。
- 查询命令执行的图形分析工具。
- 配色方案选项。
Tabix官方文档提供了5种安装方式:Tabix官方文档
我这里使用了Embedded方式,这种方式使用的clickhouse内置的服务,直接打开/etc/clickhouse-server/config.xml中http_server_default_response标签和listen_host的注释就行
<http_server_default_response><![CDATA[<html ng-app="SMI2"><head><base href="http://ui.tabix.io/"></head><body><div ui-view="" class="content-ui"></div><script src="http ://loader.tabix.io/master.js"></script></body></html>]]></http_server_default_response>
<listen_host>::</listen_host>
修改完后重启clickhouse:systemctl restart clickhouse-service
访问方式:
http://ip:8123

使用默认的用户名default,密码不填,直接为空,点击SIGN IN即可

后面的玩法等研究熟了再更新。