在 8 月 13 日的 TDengine 开发者大会上,TDengine 存储引擎架构师程洪泽带来题为《TDengine 的存储引擎升级之路——从 1.0 到 3.0》的主题演讲,详细阐述了 TDengine 3.0 存储引擎的技术优化与升级。本文根据此演讲整理而成。
点击【这里】查看完整演讲视频

相比前两个版本,3.0 的存储引擎更注重各种场景下的存储和查询效率,不仅要对管理节点进一步“减负”,提供高效合理的更新、删除功能,支持数据备份、流式处理等功能,还要考虑到数据维度膨胀下的高效处理、多表场景下的开机启动速度、合理高效且准确地使用系统资源等需求。
TDengine 3.0 存储引擎的更新可以分为三大块,首先是 TQ,基于 WAL 的消息队列;其次是 META,基于 TDB 的元数据存储引擎;第三是 TSDB(Time Series Database),用来存储时序数据的类 LSM 存储引擎(TSDB SE)。
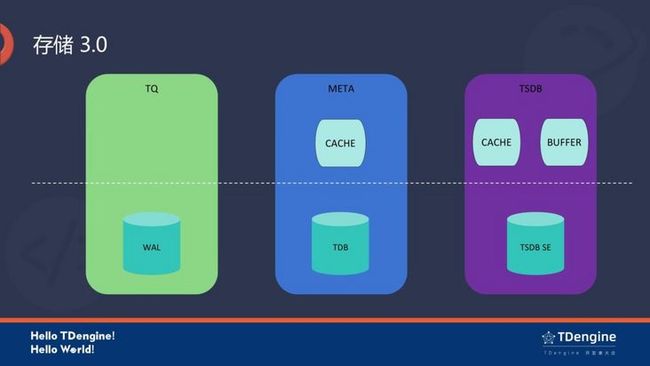
消息队列存储引擎
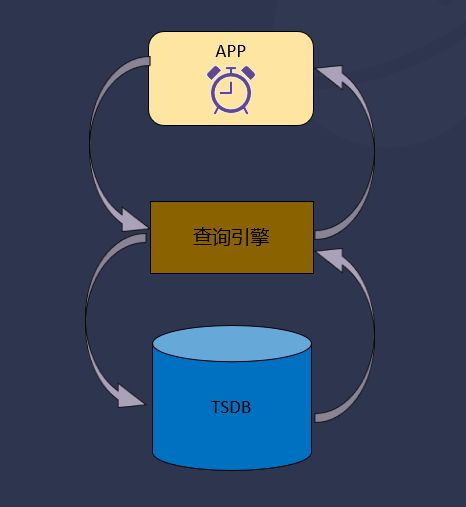
在 1.0 和 2.0 时我们提供了一个基于 TSDB 存储的连续查询功能,当时的想法是用它来代替流式处理。工作流程可以概括为:App 定时发查询任务下去,查询引擎执行查询,TSDB 返回结果给查询引擎,查询引擎再把结果返回给 App。
这一功能的优点是可以复用查询引擎,简单易开发,但缺点也很明显,不仅会出现计算实时性差、查询压力大导致算力浪费的情况,更重要的是乱序问题无法处理。数据在进入 TSDB 之后都会按照时间戳进行排序,一个乱序的数据进来后插到前面,TSDB 是无法推出这条数据的,这就会导致乱序问题的出现;另外由于查询引擎是复用的,TSDB 的查询引擎也不会对新的乱序数据进行处理、对结果进行更改校验。
从这一技术背景出发,TDengine 3.0 中需要设计一个存储引擎来支持消息队列和流式计算。这个存储引擎能告诉我们什么样的数据是增量数据,这样一来,流式计算只需处理增量数据就好了,其他的数据就不用管了。
此外这个存储引擎需要构建在一个 Pipe 之上,保证数据进入和出去的前后顺序一致。在设计时,我们发现 TDengine 的 WAL 其实就是一个天然的 Pipe。于是我们在 WAL 之上加了一层索引,并进行大量的适配开发,实现了 TQ 存储引擎。
如果大家深入研究过 TDengine 的模型,就会发现它的架构模型和 Kafka 的很多设计都是相对应的,超级表和 Kafka 的 Topic 相似、Vnode 跟 Kafka 中的 Partition 也很接近,子表的表名跟 Kafka 中的 Event Key 对应,因此这个架构设计天然地就带有消息队列的特点,从这点出发,TDengine 3.0 想要实现一个消息队列是非常容易的。
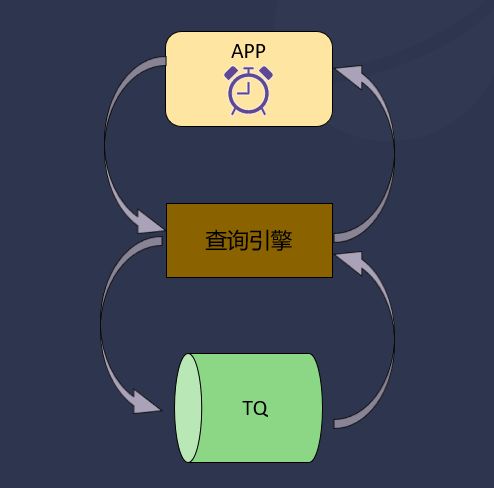
基于 TQ 存储引擎,在实际操作时,查询引擎只会处理增量数据,将计算结果修正后返回给 App,而不会再进行全量数据的再查询。它带来的优点是实时性非常高,因为能对增量数据进行明确地区分,乱序数据也得以高效处理,同时还节省了更多的计算资源,将计算结果修正。
元数据存储引擎
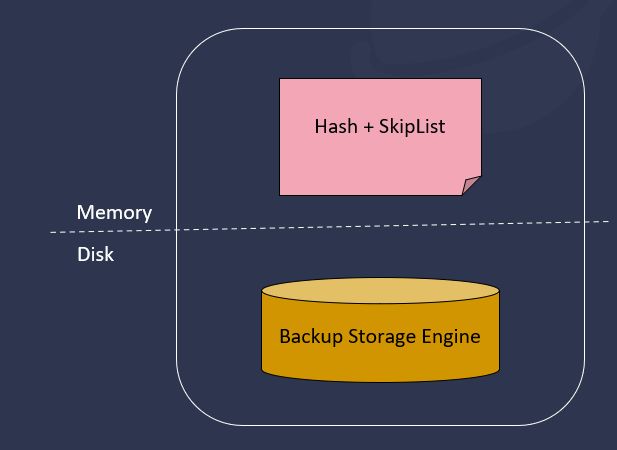
在元数据存储这块,此前的 1.0 和 2.0 采取的都是比较简单的存储机制,即全内存存储,数据在内存中以 hash 表的方式存储,并辅以跳表索引,这个 hash 表中有一个 Backup Storage Engine,它可以保证数据的持久化。该方式的优点是全内存、效率高,但缺点也很明显,当启动时,这部分数据就会全部加载到内存之中,不仅内存占用无法精准控制,还会导致开机启动时间长。
为了解决这些问题,在 3.0 中我们研发了 TDB(一个 B+ 树格式的的存储引擎),来存储元数据及元数据索引。TDB 的 B+ 树存储适合元数据读多写少的场景,能够支持百亿时间线的存储,避免了元数据全内存存储以及长时间的加载,同时解决了在有限内存下,表数量膨胀的问题。对于 TDB 是如何实现的,大家如果感兴趣,可以去 GitHub(https://github.com/taosdata/T...)上看一下源代码。
TDB 的优点是内存可以精确控制,开机启动速度快,在有限内存下也可以存储海量的元数据,此外如果 TDB 外加 Cache 辅助的话,在一定程度上可以提供接近全内存 hash 表的查询速度。
时序数据存储引擎
时序数据的更新和删除
在 2.0 中,更新删除功能是在引擎开发玩后补充开发的一个功能,因此 2.0 的更新和删除功能相对简单,但功能较弱。2.0 的更新是基于一个分布在横轴上的时间戳,更新数据的操作就是在后面追加相同时间戳的数据,简单来讲就是用乱序数据的方法来处理更新,然后查询引擎把这些乱序数据进行合并,就得到了更新后的结果。删除的实现更加简单,近似于物理删除,要删除的数据会在内存、硬盘上被直接“干掉”,效率相对较低。
TDengine 3.0 完全抛弃了 2.0 的更新删除机制,在设计层面考虑了更新和删除的实现,引入了版本号,把时序数据变成了二维图形上的点,每个写入请求都带有一个版本号,版本号按照写入请求处理顺序递增。
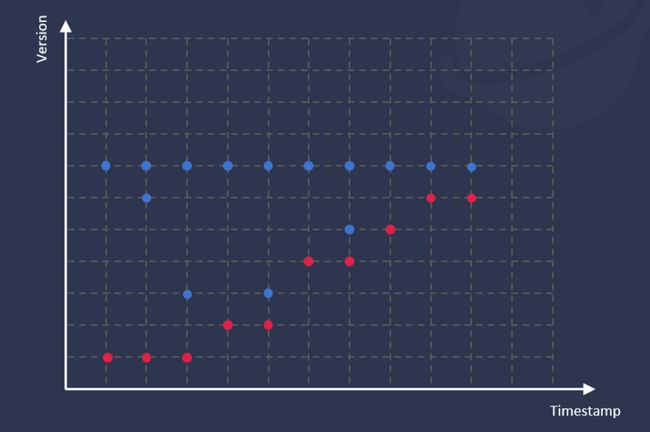
那 3.0 具体是如何做更新的?如上图所示,这些蓝色的点是你要更新的数据,数据的版本号肯定比要更新的旧数据版本号大,所以我们就引入了版本号机制。当时间戳相同时,版本号大的数据将更新版本号小的数据,因为版本号大的数据是后写入的数据,相对较“新”。
以前每张表中的数据,不论在内存里还是在硬盘中,都是按照时间戳进行排序的,但在引入了版本号之后排序规则也进行了修改。首先还是按时间戳进行排序,在时间戳相同的情况下要按照版本号进行排序,在这样的排序流程下,我们就可以把数据更新用一个近乎于追加的方式处理,查询引擎负责将最后的数据合并整理后得到最终结果。
在 3.0 中,时序数据的删除机制也完全重做。相比 2.0,3.0 支持的过滤条件也明显增加,比如 where tag、where timestamp 等等。那具体底层是如何实现的呢?首先还是基于版本号机制。

对于删除操作来说,我们需要记录开始和结束的时间区间,以及删除请求的版本号,如上图所示,一个删除请求对应二维图上的一个紫色矩形,这个矩形内部的所有点都被删除了。在 3.0 中,时序数据删除时会追加一条(st, et, version)的记录元组,在查询时,查询引擎会将写入的数据和删除记录元组进行最终的合并,并得到删除后的最终结果。
采用这种机制,删除功能对于写操作变得相对简单了,但是对于查询而言,则变得更加复杂了。查询在合并数据时,要判断记录是不是被删除了,即检查记录是不是在所有的删除区间(矩形)里面,这是相当耗时的。
TDengine 3.0 采用 Skyline 算法来提高有删除数据下的查询速度。这一算法的本质是构造一个点数据,用来代替所有的删除区间,如上图中的两个矩形删除区域可以用三个点来表示。原来对于每条记录都要检查是否被删除的算法,现在变成了一个单向扫描过滤的操作,从而大大提高查询速度。
多表场景下的存储优化
在时序数据场景下,海量数据代表的也有可能是海量的表。在有些业务场景下表数量非常之多,但采集的数据却很少,比如有一千万张表,但每天每张表采集数据只有两条,这种场景对于 2.0 的存储结构并不是很友好。
在 TDengine 2.0 中,一张表会落在硬盘上,一个数据块里面只有一张表的数据;如果有一千万张表,每张表两条数据,那一个数据块就只有两条记录,压缩都没法压缩,而且这种情况下压缩的话还会导致数据的膨胀。
TDengine 的超级表下面所有子表都共享同一个 schema,这样的话在 last 文件里我们就可以将同一个超级表下不同子表的数据合并成一个数据块——原来一个表里只有两条记录,但如果能把一百张表的两条记录合并成一个数据块,那就有两百条记录。但是这可能需要读一百次表,如果我们就想读一次那要怎么操作呢?
为了解决这个问题,3.0 在数据块中又加了一个属性,那就是表的 UID。在 3.0 的 last 文件中,数据块中的数据会按照 UID、Timestamp、Version 排序,即先比较 UID、UID 相同的情况下比较时间戳,时间戳相同的情况下比较版本号,这样的话就可以更有效地处理多表低频的场景了。

结语
TDengine 是一个开源产品,3.0 的代码也已经开放在了 GitHub 上,非常希望大家能够积极地参与进来,去下载和体验。也欢迎大家加入 TDengine 的生态交流群,和我们以及 TDengine 的关注者和支持者一起交流和探讨。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。