计算机视觉中的经典骨干网络总结
特征提取是计算机视觉任务的基础,良好的特征提取网络可以明显的提升算法的性能表现。在计算机视觉任务中,对图像进行特征提取的网络被称作为骨干网络(Backbone),可以说是下游任务的主心骨了。下面总结近年来研究者们提出的经典的骨干网络。主要从CNN、Transformer、轻量化这三个方面来写。
目录
- 一、基于CNN的BackBone
-
- 1.1 AlexNet
-
- 1.1.1 整体结构
- 1.1.2 激活函数
- 1.1.3 归一化
- 1.1.4 池化
- 1.1.5 避免过拟合
- 1.2 VGG
-
- 1.2.1 小卷积核
- 1.2.2 最大池化
- 1.2.3 归一化
- 1.2.3 Dropout
- 1.3 GoogLeNet
-
- 1.3.1 Inception
- 1.3.2 降低参数
- 1.3.3 GoogLeNet
- 1.3.4 避免梯度消失
- 1.3.5 代码
- 1.4 ResNet
-
- 1.4.1 恒等映射
- 1.4.2 残差连接
- 1.4.3 网络结构
- 1.4.4 梯度回传
- 1.4.5 代码
- 1.5 ResNet改进
-
- 1.5.1 ResNeXt
- 1.5.2 ResNeSt
- 二、基于Transformer的Backbone
-
- 2.1 Transformer
-
- 2.2.1 编码器(Encoder)
- 2.2.2 解码器(Decoder)
- 2.2.3 分析部分
- 2.2 Vision Transformer
-
- 2.2.1 先前的研究如何处理的
- 2.2.2 Vision Transformer
- 2.2.3 位置编码
- 2.2.4 class token
- 2.2.5 对比模型
- 2.3 Swin Transformer
-
- 2.3.1 Swin Transformer整体结构
- 2.3.2 Window Attention与Shifted Window Attention
- 2.3.3 几种变体及实验
- 2.4 Deformable Attention Transformer
-
- 2.4.1 DAT
- 2.4.2 网络结构
- 2.4.3 实验部分
- 三、轻量化网络模型
-
- 3.1 DenseNet
-
- 3.1.1 整体结构
- 3.1.2 Bottleneck层
- 3.1.3 过渡层(Transition Layer)
- 3.1.4 网络结构
- 3.1.5 优缺点
- 3.2 MobileNet
-
- 3.2.1 深度可分离卷积(Depthwise Separable Convolution)
- 3.2.2 计算量与参数量对比
- 3.2.3 性能对比
- 3.3 MobileNet-V2
-
- 3.3.1 Linear Bottleneck
- 3.3.2 Inverted residuals
- 3.3.3 网络模型
- 3.4 ShuffleNet
-
- 3.4.1 模块介绍
- 3.4.2 Shuffle
- 3.4.3 网络模型
- 3.5 其他
- 后记
一、基于CNN的BackBone
1.1 AlexNet
《ImageNet Classification with Deep Convolutional Neural Networks》
把时间拉回到十年前,在图像分类任务上AlexNet拿到了当时ImageNet图像分类的第一名,使用的是卷积神经网络的方法。对于细节内容就不展开那么多了,下面主要从骨干网络、激活函数、归一化、池化、避免过拟合这几个方面进行介绍。
1.1.1 整体结构
整体结构主要由五个卷积层、三个全连接层构成,中间穿插着最大池化、ReLU、Dropout,如下图所示。

从这个图来看,其实很难看懂,分了上下两个通路,主要的原因在于GPU的显存不够。为了节省显存,前两层独立开,在第三层进行特征交互(也就是把两个通路的特征在通道维度拼接),在倒数第二、第三层全连接也是把特征进行拼接,最后经过softmax进行分类。这个图比较乱,直接看看源码部分(这个pytorch实现里面没有LocalResponseNorm,为了分析论文把加上了,另外仅考虑单个通路,毕竟现在的显存都上来了)。
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000, dropout: float = 0.5) -> None:
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),# pytorch源码没有此行
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),# pytorch源码没有此行
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
1.1.2 激活函数
激活函数论文里面采用的是ReLU,给出一段话说ReLU的训练速度快(相比sigmoid和tanh),但是也没有分析原因。现在已经是十年后了,就当回事后诸葛亮吧!ReLU主要有以下几个优点:
①在大于0 部分,梯度是1(当梯度大于1时,倒数连乘梯度爆炸;倒数小于1倒数连乘梯度消失);
②计算简单。
当然,能够加速模型收敛的应该主要在于①,因为对比的sigmoid与tanh的梯度都是小于等于1的。现在已经出来了很多变体,这里不做分析,遇到一个讨论一个。
1.1.3 归一化
归一化的公式是:
b x , y i = a x , y i / ( k + α Σ j = m a x ( 0 , i − n / 2 ) m i n ( N − 1 , i + n / 2 ) ( a x , y j ) 2 ) β b^i_{x,y}=a^i_{x,y}/(k+αΣ^{min(N-1,i+n/2)}_{j=max(0,i-n/2)}(a^j_{x,y})^2)^β bx,yi=ax,yi/(k+αΣj=max(0,i−n/2)min(N−1,i+n/2)(ax,yj)2)β
其中 x x x, y y y表示特征图的坐标, i i i表示所在通道数, n 、 k 、 α 、 β n、k、α、β n、k、α、β都是超参数。从这个公式可以很简单的理解,某个特征值归一化时,由当前位的特征值及相同位置上通道维度上前后共 n − 1 n-1 n−1个邻居决定(加上自己,那就是n个,如果靠近通道前或者后,那就最多至于 n / + 1 n/+1 n/+1个值了)。
1.1.4 池化
论文里面说池化的时候,采用重叠池化效果更好。所谓重叠池化,就是池化操作的步长比核的尺寸小。一般来说,用池化比较多的地方就是下采样、保证输出维度统一。这里将池化操作的步长减少,也就意味着有更多的信息能够保留下来,所以感觉这里的能够有效的原因是不是在于保留了更多的信息呢?
1.1.5 避免过拟合
在避免过拟合方面,主要通过两种方式实现的。
- 数据增强
(1)图像级别数据增强,将图像进行水平翻转,然后随机取224×224的切片。
(2)对于每个通道的的图像,计算特征值和特征向量,对每个通道进行权重加强(这里没有仔细研究)。 - Dropout
使用Dropout避免过拟合,就是在训练时随机对一部分神经元进行抑制,即置0;测试时对所有神经元输出的结果乘以平均权重。(之前是说法是,通过这样好像是同时训练了多个模型,那么输出的结果就是多模型的集成结果;但是最近的一些研究,说是类似于正则化的效果)
1.2 VGG
《Very deep convolutional networks for large-scale image recognition》
说起VGG,想起来VGG应该是我用的第一个骨干网络,第二个是GoogLeNet,下一节说。VGG是在AlexNet之后提出的,相比AlexNet而言加深了网络的深度(所以论文题目的very deep),下面来看下网络的结构。
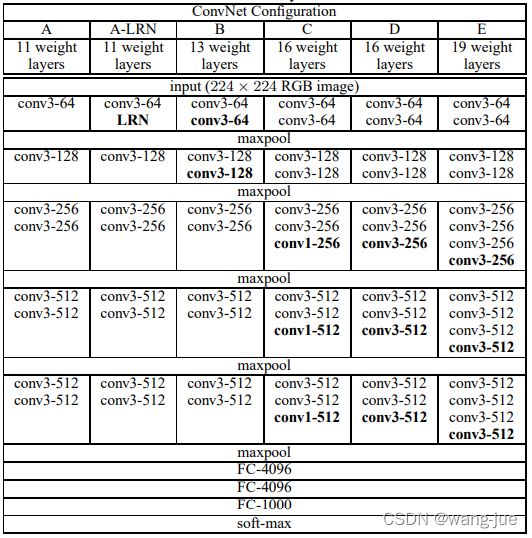
我们常说的VGG16(13层conv+3层FC)和VGG19(16层conv+3层FC)是指表中的D、E两个模型。
1.2.1 小卷积核
VGG的模型里面全部采用3×3的小卷积核(先忽略1×1的),小卷积核主要的优点在于
多层小卷积核可以实现更大的感受野,并且降低参数量。比如两层3×3的卷积层,可以实现5×5的感受野;3层3×3的卷积核可以获得7×7的感受野,同时参数量降低很多。
5 × 5 > 2 × 3 × 3 ; 7 × 7 > 3 × 3 × 3 5×5>2×3×3;7×7>3×3×3 5×5>2×3×3;7×7>3×3×3
所有的卷积后面都接ReLU,即 c o n v − > r e l u − > c o n v − > r e l u conv->relu->conv->relu conv−>relu−>conv−>relu
1.2.2 最大池化
这里采用的最大池化与AlexNet不一样,步长与池化核大小一样,目的在于进行特征降维(缩小尺度)。
1.2.3 归一化
VGG论文里面提到LRN(AlexNet里面提出的)效果不好,并且增加内存,所以没有采用。在pytorch中torchvision里面有两种版本。一种是无归一化的,另一种是加入了BN(BatchNorm2d)。加入BN之后变成了
c o n v − > b n − > r e l u − > c o n v − > b n − > r e l u conv->bn->relu->conv->bn->relu conv−>bn−>relu−>conv−>bn−>relu
1.2.3 Dropout
在VGG后面接三层FC,前两层FC都是4096维度接ReLU,最后一层是1000维度,接Softmax用于分类。对前两层用dropout,0.5概率置0。
1.3 GoogLeNet
《Going Deeper With Convolutions》
从论文名字就可以看出来前期骨干网络发展的研究方向,deep(AlexNet)、very deep(VGG)、going deeper(GoogLeNet)都是想让网络更深。让网络性能更好主要从两方面增大模型的参数量:(1)让网络更深;(2)让网络更宽。但是网络参数更多的话面临两个问题:(1)容易导致过拟合;(2)计算量太大,效率低。因此,需要构建稀疏的参数模型来替代参数量多的模型。比如,用卷积代替全连接,用较少的卷积等。
1.3.1 Inception
然后给出了所提出的Inception模块,如下图所示:

- 模块分析
从这个图里面来看,一个模块里面三个卷积分别是1×1、3×3、5×5(可以学习到"稀疏程度"不同的特征,1×1不稀疏、3×3与5×5稀疏?);一个最大池化3×3;最后将特征在通道维度进行拼接。 - 模块解读
不同尺度卷积核感受野不同(学习到的特征稀疏度不同?其实可以理解为大卷积核关注全局特征,小卷积核关注局部特征);而最大池化具有平移不变性;将不同尺度的特征进行拼接实现特征融合。
1.3.2 降低参数
为了减少参数量,对上面这个模块进行修改,也就是从通道维度对特征进行缩减。如下图:
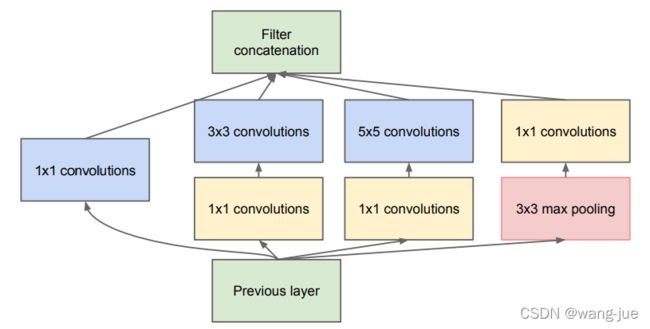
由于3×3、5×5的参数量较大,而卷积核通道数和输入特征的通道数相同。如果想减少计算量,可以通过1×1卷积的方式减少通道数。(注意到为什么这里池化后面接1×1卷积,而不是在池化前面接1×1卷积呢?)
1.3.3 GoogLeNet
后面基于inception模块构建了GoogLeNet,共有22层卷积层+7层池化。
1.3.4 避免梯度消失
前几天深层网络都面临梯度消失的问题,没有解决。这里通过引用两个辅助的分类层,即在特征中间计算分类分类,最终两个辅助的分类损失与最终的损失按照0.3、0.3、1.0的权重进行优化。这就相当于我怕你中间迷路了,我中间站在几个路口给你指引一下(感觉有点这个意思,哈哈!)。
1.3.5 代码
GoogLeNet的源码比较容易理解,可见这里。后面又出现了inception的几种改进版本,这里就不一一介绍了。
1.4 ResNet
ResNet是何凯明大神在《Deep Residual Learning for Image Recognition》论文中提出的。现在已经成为广泛使用的骨干网络之一。这里主要提出了残差连接结构避免了深层网络梯度消失及梯度爆炸的问题,使得更深的网络成为可能。
1.4.1 恒等映射
在神经网络模型中,更深的网络参数更多,可以实现更复杂的关系映射。但是实验的时候发现,更深的网络出现性能“退化”的情况。所谓的“退化”就是把网络加深之后性能变差了,这种变差不是指过拟合或者欠拟合,而是训练误差变高了,也就是网络的映射能力降低了。
换种角度思考,如果加深的网络不进行任何学习,直接输入等于输出,性能也不会降低。从这种情况来看,神经网络由于加入了激活函数等非线性结构,难以完成恒等映射。恒等映射是什么?就是输入和输出一样。
1.4.2 残差连接
在网络学习的时候,之前的设计都是一层接一层的,上一层的输出作为下一层的输入,这样就难以解决恒等映射的问题。因此,提出残差连接结构,如下图所示。

从这个图来看,有两个优点:
(1)完成恒等映射。浅层特征可以直接的传递到深层特征中。
(2)梯度回传。深层的梯度可以通过残差的结构直接传递到浅层的网络中。
1.4.3 网络结构
基于上面的分析提出残差连接结构,构建了不同的网络,有18、34、50、101、152等。
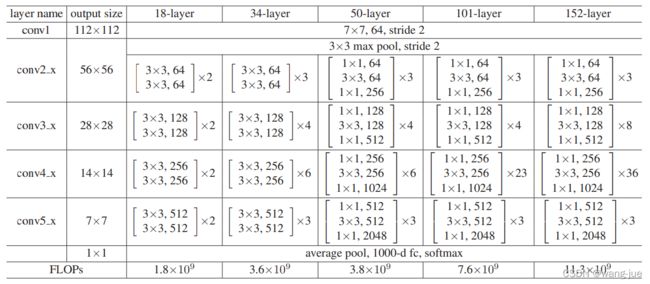
从表格里面可以看到,18和34的结构相似,在50层之后的结构换了。下面这个图给出了两种结构的的表示,可以看到前面都是3×3的结构,后面经过1×1的卷积进行通道变换,使得模型的参数量变化不大。因此可以用于更深的网络之中,而避免导致过多的参数及计算量。

1.4.4 梯度回传
神经网络模型都是一层连接一层的,可以表示为:
H ( x ) = F ( G ( x ) ) H(x)=F(G(x)) H(x)=F(G(x))
那么在求导的时候,利用链式求导法则有:
∂ H ( x ) / x = ∂ F ( G ( x ) ) / G ( x ) ⋅ ∂ G ( x ) / x \partial H(x)/x=\partial F(G(x))/G(x)·\partial G(x)/x ∂H(x)/x=∂F(G(x))/G(x)⋅∂G(x)/x
由于网络的梯度比较小(正态分布),那么通过连乘之后梯度会越变越小,容易出现梯度消失。残差连接结构的梯度由于由相加的一项构成,可以直接将浅层的梯度沿袭过来。对于:
H ( x ) = F ( G ( x ) ) + G ( x ) H(x)=F(G(x))+G(x) H(x)=F(G(x))+G(x)
求导:
∂ H ( x ) / x = ∂ F ( G ( x ) ) / G ( x ) ⋅ ∂ G ( x ) / x + ∂ G ( x ) / x \partial H(x)/x=\partial F(G(x))/G(x)·\partial G(x)/x+\partial G(x)/x ∂H(x)/x=∂F(G(x))/G(x)⋅∂G(x)/x+∂G(x)/x
通过梯度回传分析,可以发现即使网络很深时,也能够使得网络模型收敛较快。
1.4.5 代码
ResNet中的残差连接代码实现很简单,直接可以通过相加来实现。整个网络的代码可见在这里(ResNet代码)
1.5 ResNet改进
由于ResNet具有出色的性能表现,从2016年到现在已经五六年了,仍然是目前最广泛使用的骨干网络。接着出现了一些基于ResNet改进的网络,比如ResNeXt、ResNeSt等。下面就介绍一下这两个网络是如何基于ResNet进行改进的。
1.5.1 ResNeXt
ResNeXt来源于《Aggregated Residual Transformations for Deep Neural Networks》主要提出的了 cardinality(翻译成基?下面都写作基了)的概念,在“宽度”方面进行探索(与GoogLeNet有相似的地方)。所谓 基是什么意思呢?见下图:

如图左边是ResNet中的拓扑结构;右边是ResNeXt的拓扑结构,图中表示基为32。那么从这个图也就容易理解了,所谓的基就是“多分支的卷积”(说的可能不那么专业,表达出这个意思),并且每个基的结构相同。好看的小朋友也许已经发现了,其实这个和分组卷积很像,然后作者也进行了解释,其实就是分组卷积。

上面的三个图是等价的,只不过是换了不同的实现方式,本质没有区别(代码的实现就直接用分组卷积实现的)。那么,这么的目的是什么呢?作者做了对比实验,ResNet从深度、宽度上在图像分类方面都具有一定的性能提升,但是性能提升不大。但是ResNeXt从基的角度进行扩充(ResNet可以看作是基为1),对于性能提升明显。可以看这个对比实验结果。
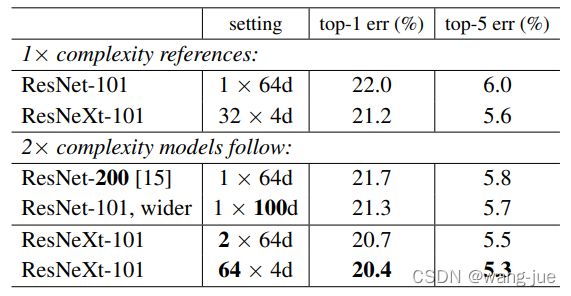
从实验的基的数量来看,基的数量越多(分组),性能提升越大。但是考虑到计算的代价,分组过多会降低计算速度(虽然参数不变,但是分组卷积本身会带来额外的开销)。

代码在此
那么有个问题,为什么ResNeXt采用分组卷积时性能更好呢?有两种说法:
(1)多个卷积核关注的不同,使得特征学习的更加互补,或者从不同的梯度方向进行优化(感觉不是很直观)。
(2)普通卷积每个卷积核的输入都是相同的,导致卷积核参数优化相似(容易过拟合?);而分组卷积在每个分组内进行优化,卷积参数之间的耦合性更低,相似性也更低一些,使得参数优化不一致(更好的避免过拟合?)。可以看下大佬对卷积核相似性进行可视化的分析。
1.5.2 ResNeSt
ResNeSt来源于《ResNeSt: Split-Attention Networks》,与SE-Net、SK-Net有一定的相似之处,这里我只介绍ResNeSt。
ResNeXt建立了分组的思想,而ResNeSt在分组的同时加入了Attention(注意力)的思想,也就是先分(split)再注意力(attention)。下面直接看结构图:
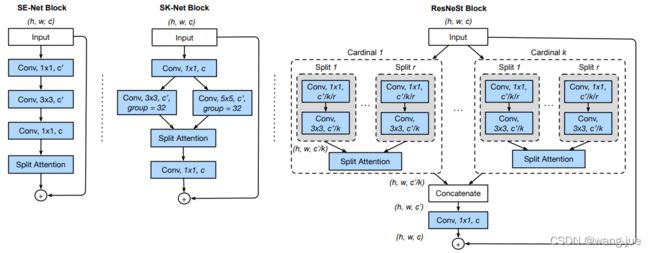
右边这个图,总体来看就是先进行分组卷积,然后在每个组内进行split-attention,接着将各组内得到的结果进行concat,然后通过1×1卷积获得通道相同的特征,最后再进行残差连接。
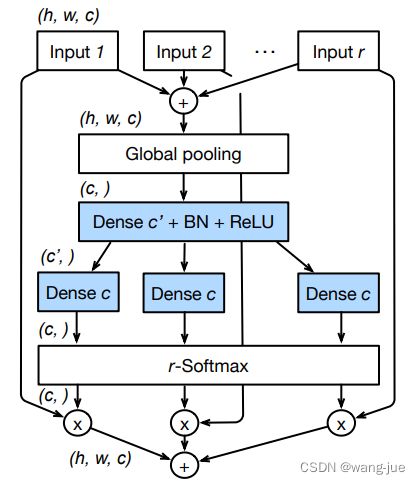
在每个基内进行split-attention,通过全局池化、全连接(使用1×1卷积降低参数量)然后通过softmax获得不同通道的权重,最终再将权重乘以各分组内的特征上,然后相加。ResNeSt的性能较好,在分类、检测、分割等任务上都达到了SOTA水平。
二、基于Transformer的Backbone
视觉Transformer最近这两年比较火,由于Transformer完全采用局部、或者全局注意力的方式,在依赖图像整体的任务中表现较好,比如去遮挡、图像裁剪打乱等任务中具有比较好的任务,而这些任务中卷积的方法性能表现一般。
2.1 Transformer
Transformer来源于论文《Attention Is All You Need》,这篇论文里面提出在序列转换模型中(如机器翻译中,由一种语言序列翻译成另一种语言序列)通常采用RNN、LSTM、GRU等网络结构,但是这些结构存在一定的缺陷:
- 计算为序列形式,如当前值依赖上一个值,导致计算时难以并行;
- 难以建立特别长的依赖关系(语言中的上下文逻辑,如果离得比较远就够不着了;如果想要建立长时间的依赖关系需要占用的内存就很大了)。
于是,提出Transformer结构,由编码器和解码器构成,看下面这个图:
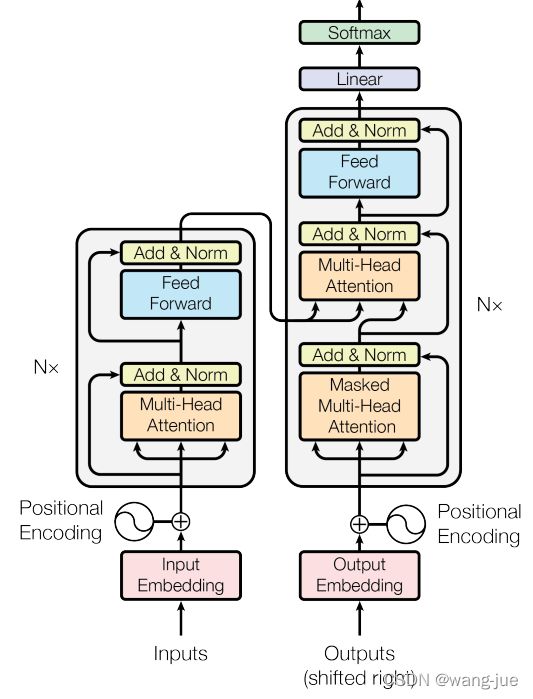
2.2.1 编码器(Encoder)
(1)位置编码
在编码器输入之后,经过embedding,然后加上位置编码,然后输入到N个模块的结构中。
位置编码加入了位置信息,比如翻译中不同的词的位置不同表达的含义不同,而位置编码通过sin和cos实现的。
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}}) \\ PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
(2)Mutil-Head Attention
Mutil-Head Attention是一个多头的注意力模型,单个的注意力模型是由query、key、value进行attention得到的。下图是Scaled Dot-Product Attention与Mutil-Head Attention。
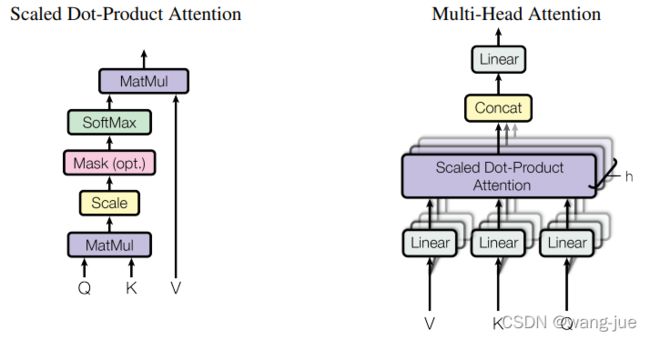
Scaled Dot-Product Attention就是单个的attention结构,计算方式即:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac {QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
公式中 d k \sqrt{d_k} dk的目的是为了进行归一化的,当向量很长时,值的差异会很大,再经过softmax之后会出现大量接近于0,而少量接近于1,这样会使得梯度变小,于是除以一个常数避免这种情况(论文也说了,当维度较小时影响不大)。通过这个模块可以构建向量的不同位置之间的联系,相比RNN(序列一层层往后传递)、CNN(堆叠多层卷积层,可以实现更大的感受野)而言可以一步实现不同位置信息之间的依赖关系学习。
但是,单个这样的attention结构是没有参数的,于是构建了如右图中的Mutil-Head Attention结构,通过对Q、K、V经过线性层的方式进行参数学习。用h个头的方式有点类似于CNN中多个通道的感觉,增强线性映射的能力。
(3)Layer Norm
在CNN中我们经常使用的Batch Norm,但是在序列转译模型中,由于输入的序列或者句子长度不一,因此采用Layer Norm进行归一化。即在每个向量内部进行均值方差计算,然后乘以λ、γ进行缩放。
(4)Feed Forward
Feed Forward函数用于增强映射能力,前面经过Attention之后获得了不同位置之间的权重关系。那么,再经过Feed Forward之后实现更复杂的语义映射。如果没有这个的话,只能表征不同权重下的Value。
2.2.2 解码器(Decoder)
(1)整体结构
解码器整体和编码器结构相似,区别在于加入了Masked Mutil-Head Attention。在每个模块中首先通过Masked Mutil-Head Attention获得Query,然后与Encoder输出的Key、Value共同输入到Mutil-Head Attention中去。
(2)Masked Mutil-Head Attention
注意这里与Mutil-Head Attention的区别在于前面加了一个Masked,这里把未出现的词掩盖住。Encoder的输出并不是直接作为Decoder的输入。比如,在训练的时候,Encoder输入“我爱学习” ,分词之后获得 我 / 爱 / 学习 这几个词的向量输入到Encoder中,而对应的输出应该是 I love learning。于是进行以下操作(为简单表述直接用单词表示,在实际操作中均通过Embedding进行向量化):
①Decoder 输入:‘bos’ (目标序列开始的token,可以理解为起始符) 对应输出:i 计算分类损失
②Decoder 输入:‘bos’ ‘i’ 对应输出:love 计算分类损失
③Decoder 输入:‘bos’ ‘i’ ‘love’ 对应输出:learning 计算分类损失
④Decoder 输入:‘bos’ ‘i’ ‘love’ ‘leanrning’ 对应输出:’/s’(终止符) 计算分类损失
因此Masked的目的就是在于把后面未出现的内容掩盖住,因为在序列转译任务中是看不到后面的东西的。同时,在测试的时候,只能一个个单词的输出结果。
2.2.3 分析部分
这里需要说下不同模块的对比分析部分,在表1中,对比了不同的操作层的复杂度、序列计算次数、传播到最大长度需要的次数。可以看到不同的操作层的复杂度差别不大;在序列计算次数中循环神经网络需要计算n次才能将整个序列计算完成,并且传播到所有元素中也需要n次,而卷积操作通过多层迭代的方式扩大感受野,因此是log的复杂度。

实验后面涉及到调参、消融实验等这里就不一一介绍了,感兴趣的可以看下论文。关于Transformer的讲解可以看下李沐老师的论文精度Transformer。
2.2 Vision Transformer
vision transformer来源于《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》ICLR2021这篇论文,算是比较早的将Transformer用到计算机视觉领域的。我们知道Transformer提出之后在NLP领域应用获得比较好的结果,可见Transformer比较好的处理序列结构,比如文本、语音等。那么将其应用于视觉领域该怎么做?会怎样呢?既然Transformer用于处理序列化模型的,那么就将图像编码成序列化的形式,如果直接把一个图像的所有的像素全部作为序列输入到模型中,维度太高了,那么该如何处理呢?
2.2.1 先前的研究如何处理的
(1)用特征图作为Transformer的输入
比如图像经过resnet网络之后,下采样16倍,那边再将这个特征图作为输入,维度会减少很多
(2)类似卷积的方式
在图像的每个局部区域做Transformer处理,避免所有像素之间一起做导致维度过高。
引言里面提到了卷积具有两个优点(归纳偏置),因此在较小的数据集上效果好:
(1)locality,可以理解为局部领域,图像中相近的像素具有一定的相关性;
(2)平移等变性,卷积平移时结果不变。
2.2.2 Vision Transformer
与上一节不同,这篇论文提出采用pathch的方式,用于减少参数也就是论文题目一个图像可以等价于16×16的单词。如下图所示为将图像进行裁剪成网格形式,每个patch作为一个序列作为网络模型的输入。
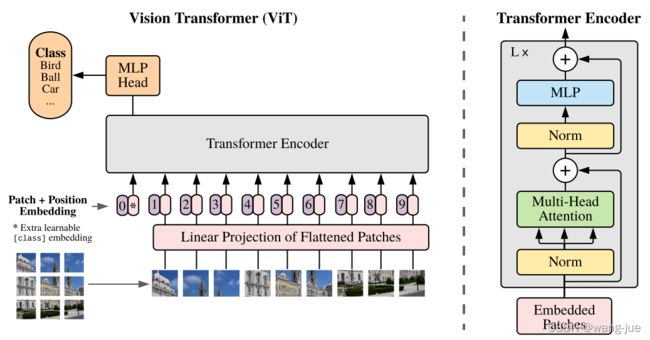
总的来介绍,图像经过patch划分之后,给每个patch一个位置编码,然后经过线性层(Liner Projection of flattened)投射之后输入到Transformer Encoder中,而最终的输出通过第一个extra learnable的输出进行分类预测。下面按照前向推理的流程进行介绍。
(1)图像为224×224×3的尺度,划分为16×16之后,每个token(即patch)为196=(224×224)/(16×16),每个token的维度为768=16×16×3;
(2)经过Liner Projection进行投射之后,维度为768×768,也就是不改变输入维度。即输入为196×768,经过768×786的矩阵,输出仍然是196×768;
(3)位置编码(1D或者2D的)也是768维度,进行逐元素相加,加上第一个cls token,因此输入为197×768维度;
(4)经过Layer之后维度不变,再经过MutilHead Attention之后(MutilHead分组之后再concat)维度仍然不变,最后再经过MLP进行维度转换,最后维度仍然不变,输出仍然是197×768,重复L遍,最后经过MLP Head进行分类。
2.2.3 位置编码
在NLP中位置编码为1D,那么在图像里面,为了更好的表示位置信息,应该引入2D的编码(横纵坐标)。实验对比发现如果不用位置编码效果较差,如果用了位置编码:1D、2D、相对位置编码(比如距离当前位置的)的实验效果差不多。(论文中给出的解释是,图像分成patch之后,感知位置信息还是比较容易的,如果没有位置信息全局一起感知就比较难,引入位置信息之后有利于学习很多)论文附录D.4
如果训练的模型,用于处理不同尺度的图像该怎么处理呢?论文给出的方法是对位置编码进行线性插值(效果不是特别好)。
2.2.4 class token
这里采用BERT里面同样的方式,第一个为cls token,最后输出的197×768作为图像的特征,然后再进行分类。实验也对比了如果采用cls token进行分类和所有token输出的特征进行分类(每个token进行池化,然后进行维度拼接),发现性能差别不大,为了保证完全遵循Transformer的架构,这里全部采用cls token。论文附录D.3
2.2.5 对比模型
这里对比了三种模型,一种是ResNet完全卷积模型,一种是Transformer完全的注意力模型,一种是混合模型(先通过ResNet提取出特征然后经过Transformer,Hybrid模型)。实验结果显示(论文Fig.3):
(1)在较小的数据集上(ImageNet-1k)上,卷积模型要;
(2)在中等的数据集上(ImageNet-21),效果差不多;
(3)在更大的数据集上(JFT-300M)Transformer的效果更好。
参考大神解读,强烈建议自己去学习一下。
2.3 Swin Transformer
Swin Transformer来源于论文《Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows》是ICCV2021的best paper。在摘要中提到图像相比文本而言具有更高的分辨率,其实也就是图像的像素使得信息多,VIT模型在处理时会有指数的空间复杂度。本文提出一种层次结构的Transformer,并且性能高效且相对于图像的尺度而言只有线性的空间复杂度(Transformer的网络对于图像、文本的线性增长特征而言一般都是指数级的复杂度)。思想就是,划分局部窗口进行内部Attention(类似于卷积的思想)。论文代码
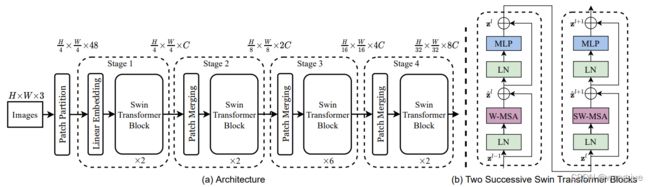
2.3.1 Swin Transformer整体结构
如下图所示,整体结构与ResNet系列类似,具有四个阶段,每个阶段分别进行4×、8×、16×、32×倍下采样,这样来看就可以直接使用FPN进行多尺度的检测,在目标检测、语义分割等任务中具有较强的拓展性。
下面按照前向传播的方式进行介绍。
(1)输入图像经过Patch Partition之后划分成4×4的patch,那么每个的维度就变成了[H/4,W/4,4×4×3],然后经过Linear Embeding层变成[H/4,W/4,C]通道,对于Swin T通道的维度为96。注意这里Patch Partition与Linear Embedding层代码里面直接通过4×4的卷积,步长为4实现。
(2)在每个Swin Transformer里面进行patch划分,然后分别进行W-MSA与SW-MSA处理(这里都是成对出现),并且通道维度不变下面介绍;
(3)后面的2、3、4阶段的模块结构类似,先经过Patch Merging维度处理,即尺度减半、通道×4倍,为了与ResNet中尺度减半、通道×2倍,这里增加了全连接层进行维度减半;
(4)在每个阶段分别进行4×、8×、16×、32×尺度下采样,通道维度为C、2C、4C、8C,然后可以用FPN进行多尺度的检测。
2.3.2 Window Attention与Shifted Window Attention
在每个Swin Transformer Block里面都分别进行win与swin的注意力,分别如下图的Layer1与Layer1+1。
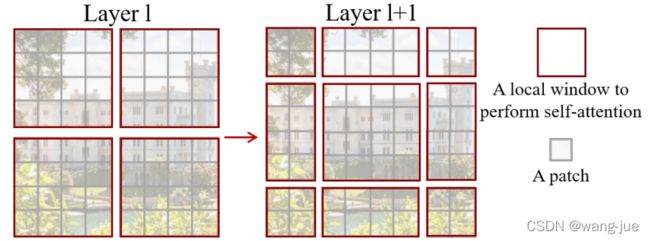
由图可见win Attention内维度相同,可以直接进行并行计算;但是swin Attention维度不同在计算时效率较低。这里作者提出masked MSA进行替代计算,如下图:
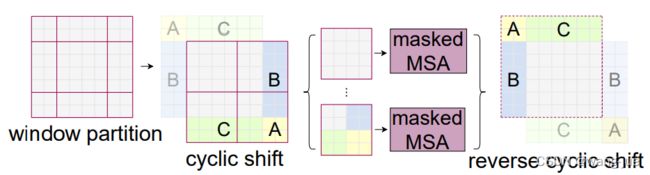
当进行Sift Win操作时,通过上下、左右的转换,将9个大小不一的窗口转换成4个尺度相同的窗口,然后进行attention计算,最后经过masked MSA进行处理,最后再把特征转换回去。关于masked MSA在github上面有不少人给出图示,我这里引用一个github讨论,下图是作者给出的示意图,并给出代码。
2.3.3 几种变体及实验
类似ResNet,给出Swin-T、Swin-S、Swin-B、Swin-L变体,参数的区别主要就是通道、第三阶段数量。实验在分类、检测、分割上面都具有较强的性能。
2.4 Deformable Attention Transformer
论文《Vision Transformer with Deformable Attention》。前面两篇论文都是用Transformer去解决计算机视觉的问题,从VIT到Swin Transformer可以看到的是把全局的attention转化为局部的attention,为了实现不同区域的交互引入shift window。由于shift window采用移动窗口的方式使得不同的窗口之间达到交互的目的,而DAT中引入可变卷积的思想,通过卷积学习特征的偏置进行特征重组,实现自由attention。
2.4.1 DAT
整体结构如下所示:
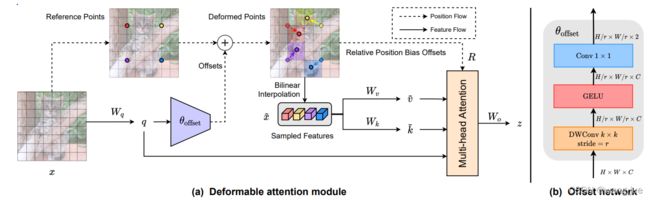
(1)首先在特征图上预设很多采样点,然后由query预测采样点的特征位置偏移;通过双线性插值算法对采样点进行修正,获得采样点的特征,最后将采样特征输入到Mutil-Head中去;
(2)关于采样点:采样点为原图/特征中按照间距进行采样,代码中设置间隔为1,也就是所有的点都采样(如果设置参数大于1,则采样点数量小于特征图尺度,可以用于加速运算),如图中采样点间隔设置为4;
(3)可变形特征这里实现和可变卷积一样,双线性插值算法可见这个博客。
(4)offset network由depthwise Convolution、GELU、1×1卷积构成,输出为尺度相同,通道为2的位置偏差,即x、y两个方向的。
2.4.2 网络结构
整体的网络结构与Swin Transformer完全一致,并且前两个阶段也是一样的,只对后两个阶段采用的DAT结构,原因应该是在于计算复杂度过高。因为引入了DAT之后,虽然参数量增加的貌似只有offset network,但是在特征重组时采用双线性插值操作,会极大的降低运行速度。
2.4.3 实验部分
实验部分看起来还是比较亮眼的,在分类、检测、分割上面都能有明显的提点0.5-2
三、轻量化网络模型
为提取更加准确的图像语义特征,骨干网络都是从深度、宽度两方面发展的。随着深度和宽度的增加,网络的参数和计算量逐渐增大,导致运算速度变得越来越慢,因此需要做好速度和精度的权衡。在这一方面,有一些经典的论文从轻量化网络模型方法进行研究,下面介绍一些。
3.1 DenseNet
DenseNet来源于《Densely Connected Convolutional Networks》论文。这篇论文提出新的骨干网络的,对每一层的特征通过密集连接的方式,让后面的层重复利用。这里简单对比一下不同网络的梯度回传过程:
AlexNet、VGG:这些都是按照层次结构依次回传;
GoogLeNet:不同尺度的卷积核,感受野不同,但是依然是依次回传的;
ResNet:引入残差结构,由于Skip连接的存在,可以直接将深层的梯度传递到浅层中,避免梯度消失的同时,直接实现恒等映射;
DenseNet:密集连接,深层中的梯度可以直接回传到前面的所有层中,网络参数重用率更高。
3.1.1 整体结构
整体结构如下图所示,网络结构为BN-ReLU-Conv的形式,每一层的输入为之前所有的特征在通道维度拼接的结果;输出为k个通道的特征,然后与之前的输入进行concat,其中k表示growth rate。
第一层输入为k0通道,输出为k个通道;
第二层输入为k0+k个通道,输出为k个通道;
第L层输入为k0+(L-1)×k,输出为k个通道。

3.1.2 Bottleneck层
由于每一层都会输出k个通道的特征,在深层网络中通道的数量会呈现线性增长,这里引入bottleneck的思想进行降维,即通过BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3),减少参数并且提升速度。这里论文中取名为DenseNet-B。
3.1.3 过渡层(Transition Layer)
在之前的网络中,随着深度的增加特征的尺度变小、通道数变多,通过1×1卷积-2×2均值池化进行尺度减半。其中1×1卷积的目的是减少通道数(随着网络层数的增加,特征的通道数越来越多,导致计算较慢)。这里论文取名为DenseNet-BC。
3.1.4 网络结构
论文给出几种不同的网络,分别是DenseNet-121(k=32)、DenseNet-169(k=32)、DenseNet-201(k=32)、DenseNet-161(k=48)。从实验结果来看,随着网络层数的增加,性能会变好;随着k的增大,性能也会变好(其实也就是网络的参数变多了)。性能方面,在分类任务中准确率相似的情况下,DenseNet相比ResNet而言,参数量小一倍。
3.1.5 优缺点
DenseNet参数量少,性能也挺好,为什么没有成为像ResNet一样广泛用于检测、分割等任务中呢?这里猜测一样主要的原因在于显存,DenseNet由于重复利用之前的特征,会导致显存占用过高。
3.2 MobileNet
MobileNet来源于论文《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》标准卷积对输入的所有通道都进行处理,因此参数量巨大。MobileNet采用深度可分离卷积和1×1卷积进行轻量化,降低参数量并且很好的保证了模型的性能。
3.2.1 深度可分离卷积(Depthwise Separable Convolution)
(1)标准卷积
对于输入特征D1×D1×M的特征而言,D1为输入图像的长宽,M为输入通道;输出为D2×D2×N,其中N表示输出的通道;则标准卷积的参数量、计算量分别为: 参 数 量 : d 1 × d 1 × M × N , 计 算 量 : D 1 × D 1 × M × N × D 2 × D 2 参数量:d1×d1×M×N,计算量:D1×D1×M×N×D2×D2 参数量:d1×d1×M×N,计算量:D1×D1×M×N×D2×D2其中d1表示卷积核大小。
(2)Depthwise Convolution
深度卷积就是每一个通道对应一个单通道的二维卷积核,参数量为: 参 数 量 : d 1 × d 1 × M , 计 算 量 : D 1 × D 1 × M × D 2 × D 2 参数量:d1×d1×M,计算量:D1×D1×M×D2×D2 参数量:d1×d1×M,计算量:D1×D1×M×D2×D2由于输入每个通道都对应一个1维度的卷积核,因此参数量和计算量相比普通卷积而言减少了N倍。
(3)Pointwise Convolution
点卷积也就是1×1卷积,由于深度卷积无法对通道进行改变,因此可以通过1×1卷积进行通道维度缩放。参数量和计算量分别为 参 数 量 : M × N , 计 算 量 M × N × D 2 × D 2 参数量:M×N,计算量M×N×D2×D2 参数量:M×N,计算量M×N×D2×D2

3.2.2 计算量与参数量对比
MobileNet就是通过深度卷积和1×1卷积实现和普通卷积相同维度特征的输入输出,但是参数量和计算量减少很多。
(1)计算量对比,深度可分离卷积比普通卷积
( D 1 × D 1 × M × D 2 × D 2 + M × N × D 2 × D 2 ) / ( D 1 × D 1 × M × N × D 2 × D 2 ) = 1 / N + 1 / ( D 1 × D 1 ) (D1×D1×M×D2×D2+M×N×D2×D2)/(D1×D1×M×N×D2×D2)\\ =1/N+1/(D1×D1) (D1×D1×M×D2×D2+M×N×D2×D2)/(D1×D1×M×N×D2×D2)=1/N+1/(D1×D1)
(2)参数量对比,深度可分离卷积比普通卷积
( d 1 × d 1 × M + M × N ) / ( d 1 × d 1 × M × N ) = 1 / N + 1 / ( d 1 + d 1 ) (d1×d1×M+M×N)/(d1×d1×M×N)=1/N+1/(d1+d1) (d1×d1×M+M×N)/(d1×d1×M×N)=1/N+1/(d1+d1)
3.2.3 性能对比
在分类任务中,MobileNet-224可以在较少的参数和计算量的情况下,达到GoogLeNet与VGG16的性能。
3.3 MobileNet-V2
在MobileNet的基础上,提出了MobileNet-V2,论文《MobileNetV2: Inverted Residuals and Linear Bottlenecks》,MoblieNet-v2相比MoblieNet而言主要有三点区别。
3.3.1 Linear Bottleneck
这里论文提到了兴趣流形(mainfold of interest)的概念,就是在神经网络中高维的特征可以映射到低维的特征中,这种流形也就保存了下来(这里其实我也没有搞懂是什么意思,感觉像是低维的特征中包含了高维特征中重要的信息)。但是,经过ReLU之后,由于只保留了大于0的特征,使得部分特征被抑制了,导致这种“流形”坍塌了,不利于特征的表达。这里我理解的(不知道对不对):
(1)在普通的网络模型中,由于通道数量较多,ReLU丢失一部分之后问题还不大,重要的信息仍然能够保留下来;
(2)在轻量化的模型中使用ReLU之后,抑制的部分参数无法学习,而轻量化的模型参数本来就少,这样就不利于特征提取。
为避免这个问题,采用线性的方式进行ReLU用来保留更多的信息,实际操作也就是使用了1×1的卷积。注意,这里并不是将每个Bottleneck后面的ReLU用线性操作代替,每个Bottleneck里面仍然有激活函数的,采用的是ReLU6(ReLU6也就是限制最大输出为6,为了保证在低精度数据下的稳定)。
3.3.2 Inverted residuals
网络结构的设计引入了残差连接,并且是两头窄中间胖的类型。如果一直都是低通道的,模型的性能不好(特征经过激活函数会抑制掉一部分,并且模型参数量较少难以完成复杂的映射),因此在每个模块内部先通过1×1的卷积提升维度,后面再进行降维。如下图所示,对比普通的残差模块与倒残差模块,可见区别主要在于倒残差模块的内部通道数增加,具有大的特征存储能力。论文中说中间层通道5-10倍效果接近。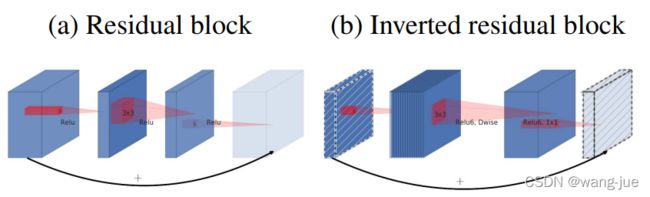
3.3.3 网络模型
网络模型如下所示,其中t表示Inverted residuals中输入到中间层的通道倍数;c表示输出通道数;n表示模块重复次数;s表示模块中的第一层步长数(步长为2时,尺度缩小一倍)。
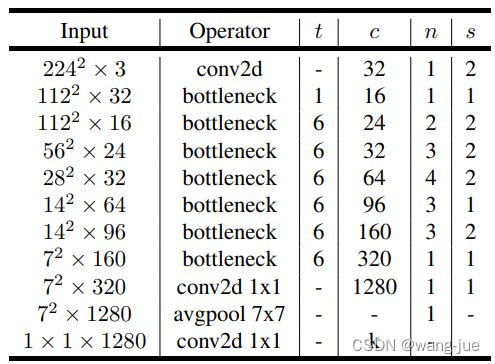
这里贴一个大佬的分析,醍醐灌顶。
3.4 ShuffleNet
ShuffleNet沿用了残差连接的结构,采用分组卷积并对通道进行重组实现不同分组之间的特征交互。
3.4.1 模块介绍
ShuffleNet的每个模块都是由下图中(b)、(c)进行组合得到(输入层、输出层除外)。
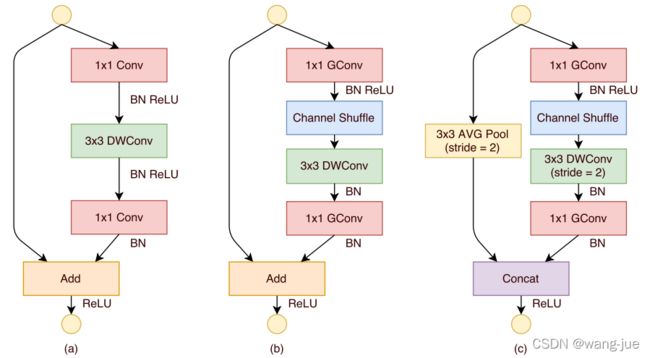
(a)表示基础的残差连接结构,通过1×1卷积、深度卷积、再经过1×1卷积维度变换,最后通过残差连接实现特征融合;
(b)中将所有的卷积都通过分组卷积实现,在3×3的分组卷积中对通道进行重组,实现不同分组之间的交互;
(c)在进行尺度缩放时,增大卷积的步长使得特征尺度减半,为保证前后的特征尺度一致,对输入特征进行平均池化,然后以concat连接的方式进行融合,沿用了之前的尺度减半维度加倍的思想。
3.4.2 Shuffle
由于分组卷积固定的在每个分组内进行特征提取及参数更新,不同分组之间没有交互,这里在分组卷积的同时通过打乱通道之间的顺序,实现不同通道之间的交互,增加特征之间的耦合性。
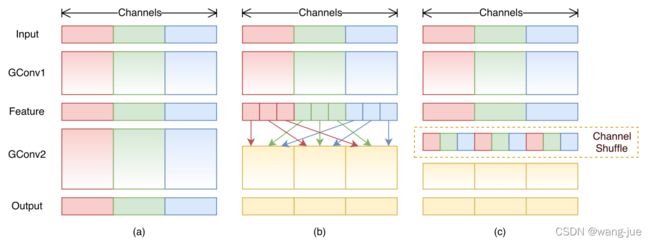
图中(a)表示分组卷积,(b)、(c)表示打乱分组之间的过程,比如将通道分为三个组,每个组打乱时将其他分组的特征选择一个形成新的组,然后再进行分组卷积。
3.4.3 网络模型
网络按照分组的不同,参数量和速度均不同,具体参数如下所示:

论文中不同的参数对应的有不同的性能表现,这里就不贴了。说下缺点吧,由于打乱通道影响了内存的连续性,导致速度实际上没有特别的快。
3.5 其他
其他的论文如EfficientNet、RegNet等也都是很好的论文,另外轻量化模型方面在模型量化、模型减枝能还有很多优秀的工作没有介绍,后面等看到了就再做补充。
后记
这篇博客是交完盲审论文开始写的,后面经历了论文的一些工作、寒假、答辩等事情,在此期间断断续续的把这些经典的论文整理好。介绍的内容比较浅显,尤其感谢所提到的所有论文的作者以及大佬们的解读,若有错误还请在评论区批评指正。谢谢!
未完待续