Python有关Unicode UTF-8 GBK编码问题详解
Python有关Unicode UTF-8 GBK编码问题详解
1.统一码(Unicode)
Unicode也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。对于世界上所有的语言文字再unicode中都可以查看到。【汉】字的编码解释官网https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=6C49
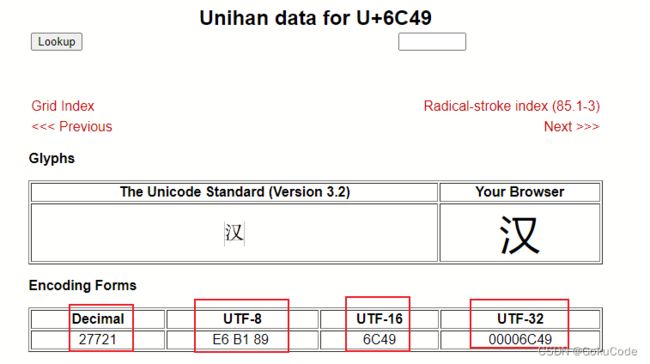
unicode编码就是为了统一世界上的编码,有一个统一的规范。但是它还存在一些问题。
Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题
- 第一个:如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
- 第二个:我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
- 出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。
- unicode在很长一段时间内无法推广,直到互联网的出现。
2.UTF-8编码
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
-
对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
-
对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------±--------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Python代码举例:
a = '\u6c49' # 汉的unicode编码
print(a)
a = '汉'
print("汉字utf8格式:",a.encode('utf8'))
print('汉字unicode格式:',a.encode('unicode_escape'))
print('汉字gbk格式:',a.encode('gbk'))
print('汉字gb2312格式:',a.encode('gb2312'))
# 输出结果
汉
汉字utf8格式: b'\xe6\xb1\x89'
汉字unicode格式: b'\\u6c49'
汉字gbk格式: b'\xba\xba'
汉字gb2312格式: b'\xba\xba'
可以看到以上结果,汉字的汉通过print打印时用的是unicode编码,存储时使用utf8,也即是我们保存文件时常用的编码
with open('xxx.txt','w',encoding='utf-8') as f:
f.write(xxx)
打开的时候也要指定文件编码
with open(file_path, encoding='utf-8') as f:
f.read()
当使用gbk编码保存的文件使用utf8打开时会报错,使用gbk打开即可
with open(r'gbk.txt','r',encoding='utf8') as f:
print(f.read())
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte
总结
- UNICODE是一个符号集合,对全世界的语言都对应一个符号编码
- UTF-8是UNICODE在计算机中存储时的具体体现,是存储方案
- UTF-16同理
- UTF-32同理
- GB 2312 或 GB 2312-80 是一个简体中文字符集的中国国家标准,全称为《信息交换用汉字编码字符集·基本集》,又稱為GB0,由中国国家标准总局发布,1981年5月1日实施。
- GBK: 汉字国标扩展码,基本上采用了原来GB2312-80所有的汉字及码位,并涵盖了原Unicode中所有的汉字20902,总共收录了883个符号, 21003个汉字及提供了1894个造字码位。
参考链接