C#集合
StringBuilder竟然是基于链表而不是数组的集合,它不是2被的增加容量,而是新增一个StringBuilder节点,容量为int num = Math.Max(minBlockCharCount, Math.Min(this.Length, 8000));minBlockCharCount:填满上个节点后剩余的字符个数;this.Length:上两个节点的容量之和新增的数据往里面填,基本上每个节点的最大容量就是8000个字符,满了之后再新增节点,不会拷贝以前的数据。StringBuilder有一个名为m_ChunkPrevious的字段,指向上一个节点。不知道这是新的实现方式还是以前就是这样实现的,
对于一直往里面Append数据效率的确是快了,不会拷贝以前的数据,其他的操作实现起来就麻烦一点,至于效率估计会有点影响。这样的实现方式对于添加大量的字符串效率会有很大的提高,如果是用一个连续的数组存放字符串的话,在复制数据的时候性能会有点影响。
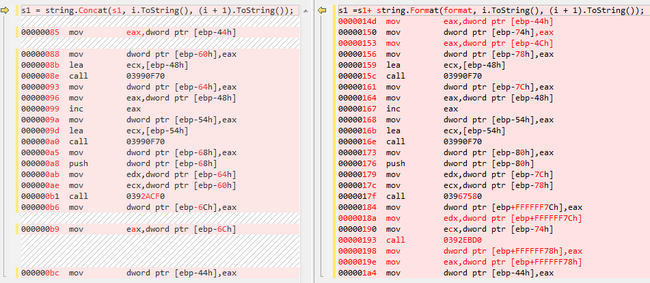
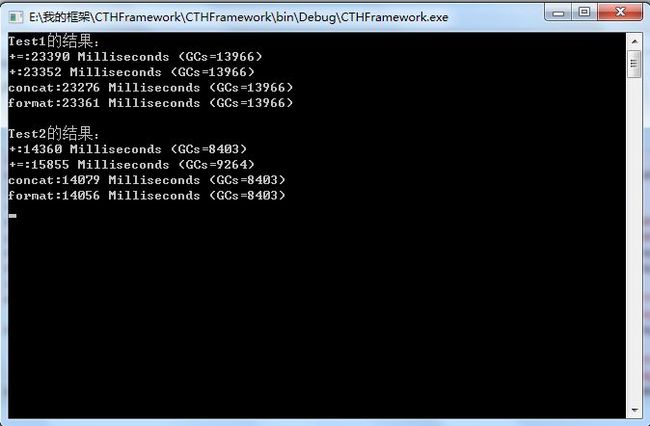
String关于字符串,我想大家最喜欢比较+、+=、String.Format、String.Concat随的性能好,如果只是一条或是少量顺序语句,说谁的性能好没有任何意义,根本体现不出谁的性能好,要比性能就得大量的数据测试,在循环次数相同的情况下,他们几个的性能真的差不多,如果非要比速度的话,”+”>“+=“>“ConCat”>“Format”并不是大家常说的+=的性能比+好(不一定总是这个结果)。其实要提高性能就得减少循环的次数,在以同样的方式减少循环的次数的情况下,性能提高了,基本上是性能跟循环的次数成反比,性能差不多。我们来看看他们的汇编代码就知道了,从图中我们看出+与+=执行的指令条数是一样的,ConCat比Format少了几个移动指针的指令,其他的指令个数都是一样的,当然他们的垃圾回收次数也就是一样的。总之少量字符串用他们哪一个都无所谓,毕竟不涉及性能问题,我喜欢用Format,因为它让代码更好理解,看着舒服些,大量字符串就必须得用StringBuilder。
测试代码:
static void Test1() { int timer = 100000; using (new OperationTimer("+=")) { string s1 = string.Empty; for (int i = 0; i < timer; i++) { s1 += i.ToString(); } } using (new OperationTimer("+")) { string s1 = string.Empty; for (int i = 0; i < timer; i++) { s1 = s1 + i.ToString(); } } using (new OperationTimer("concat")) { string s1 = string.Empty; for (int i = 0; i < timer; i++) { s1 = string.Concat(s1, i.ToString()); } } using (new OperationTimer("format")) { string format = "{0}"; string s1 = string.Empty; for (int i = 0; i < timer; i++) { s1 = s1 + string.Format(format, i.ToString()); } } } static void Test2() { int timer = 110000; using (new OperationTimer("+")) { string s1 = string.Empty; for (int i = 0; i < timer; i+=2) { s1 = s1 + i.ToString()+(i+1).ToString(); } } using (new OperationTimer("+=")) { string s1 = string.Empty; for (int i = 0; i < timer; i += 2) { s1 += "i" + i.ToString() + (i + 1).ToString(); } } using (new OperationTimer("concat")) { string s1 = string.Empty; for (int i = 0; i < timer; i += 2) { s1 = string.Concat(s1, i.ToString(), (i + 1).ToString()); } } using (new OperationTimer("format")) { string format = "{0}{1}"; string s1 = string.Empty; for (int i = 0; i < timer; i += 2) { s1 = s1 + string.Format(format, i.ToString(), (i + 1).ToString()); } } }
汇编代码如下:

测试结果:
ArrayList你可以抛弃它了,用List吧,向ArrayList中添加值类型数据的数据性能没有List的好,引用类型性能差不多。值类型ArrayList会出现装箱和拆箱,性能差点,而引用类型大家调用的都是指针,List就别认为自己长得帅了,List会为每种值类型都会产生一套代码,而引用类型是同一套代码。其实以前我也不知道为什么会是这样,在我看了C++的模版后我就明白了,模版的参数可以是任何类型,为每种类型产生一套代码,但是C++有模版半特化功能,就是将模版的参数加一个约束,这种模版的参数必须是指针类型,有了这两个模版,值类型的就会调用第一个模版,生成一套代码,因为每种值类型所占用的字节不是都一样,指针类型的就会调用特化的模版,因为每种指针占用的都是4个字节,所以根本不需要为每种类型都生成一套代码。代码的膨胀问题就是这样解决的。List容量基本上是2倍2倍的扩增,然后将以前的数据复制过来,值类型直接复制数据,引用类型直接复制对象的引用,如果对象被修改了,List中的引用也就被修改了,当然引用类型都是这样的。
Hashtable也是过时了,被Dictionary取代了,非泛型的集合肯定是会被泛型的取代的。他们的实现原理我想应该是差不多的,对于哈希字典,我认为了解他是怎么散列的就行,每种集合的提共的方法其实都是都差不多,只是最主要的算法不同而已。Object有个GetHashCode()方法,这个方法能为每个对象生成一个不同的长度为10的整数,然后将这个数散列到一个数组中,数组是按照质数的顺序扩展的,也就是说,数组的长度都是质数,这主要是为了均匀的散列。如果向Dictionary中添加两个相同的Key,也就是散列到同一个位置就会跑出异常, HashSet也是基于散列的,当有多个对象散列到同一个地方的时候,它不会跑出异常,而是直接返回。排除一个数组或是多个数组中的重复数据用HashSet是个不错的选择。
Stack栈很简单,以2倍的方式扩容,进栈的相当于填充数组,从0~N-1,出栈的时候将最后加入栈中的元素清掉,也就是后进先出。
Queue队列也很简单,默认以2被的方式扩容,扩容的倍数可以自定义,进队列的时候相当于填充数组,从0~N-1,出队列就是返回一个索引所知的元素,每有一个元素出队列,这个索引就增1,出队列的元素清除,元素占用的位置保留,即数组的大小不变,只是你访问不了。
SortDictionary是基于红黑树的,这个红黑树还有点难理解,还在学习中,就不多说了。那就是查找速度快,时间复杂度为O(logN),在添加元素的时候会经常调整树的结构。
作者:陈太汉
博客:http://www.cnblogs.com/hlxs/