【Pytorch】Tensorboard用法:标量曲线图、直方图、模型结构图
Pytorch官方文档:https://pytorch.org/docs/stable/tensorboard.html
Tensorflow的官方文档:https://www.tensorflow.org/tensorboard
在机器学习中,我们一般需要记录模型训练的评估指标、参数等等。TensorBoard就是一个功能极为强大的机器学习实时检测并可视化的工具。它可以实时跟踪并可视化loss、acc等标量,可以使用直方图、分布图来展示权重和梯度分布的变化,也可以展示出模型的架构图,还可以将将嵌入向量投影到较低维度的空间从而可视化等等。
起源
TensorBoard最早是TensorFlow 的可视化工具包。早期PyTorch是不支持Tensorboard的,于是lanpa大佬就开发了一个完全支持PyTorch的Tensorboard工具包TensorboardX。后来在PyTorch 1.1.0版本,官方与TensoBoard合作加入了对Tensorboard的支持接口torch.utils.tensorboard,而且使用方法和TensorboardX基本一致。相比Visdom,Tensorboard功能强大,用户多。
安装&导入
安装
pip install tensorboard
导入
from torch.utils.tensorboard import SummaryWriter
使用方法
【SCALARS】记录标量信息
只要是标量信息,都可以使用SCALARS来记录,比如:loss、accuracy、mse、F-score、动态学习率、dropout的保留率、隐藏层中的参数信息(如:最值、均值、方差等等)等。
使用方法:
将下面的关键代码插入到你的机器学习代码中相应的位置即可。
# strat training
writer = SummaryWriter(log_dir='./log/') # 【关键代码1】
for epoch in range(10):
train_loss = train_one_epoch(epoch)
val_loss, rmse = eval_model(epoch)
writer.add_scalar(tag='TrainLoss', scalar_value=train_loss, global_step=epoch) # 【关键代码2】
writer.add_scalars(main_tag='Metrics', tag_scalar_dict={'ValLoss':val_loss,
'RMSE': rmse}, global_step=epoch) # 【关键代码3】
writer.close() # 【关键代码4】
代码说明:
- 【关键代码1】初始化一个writer,
log_dir是日志文件的保存目录,默认是./runs/。- 【关键代码2】记录这一刻的train_loss标量值,
tag是数据标识符,scalar_value是要记录的标量值,global_step是第几步。- 【关键代码3】和代码3功能一样,不过它可以同时记录多个标量值。
main_tag是父标签,tag_scalar_dict是个字典{子标签: 要记录的标量值},global_step是第几步。- 【关键代码4】关闭writer。也可以使用
with SummaryWriter(log_dir='./log/') as writer:类似python的文件操作。
运行你的机器学习代码之后,在当前目录下shift+鼠标右键打开命令行输入下面的命令并回车(./log/是你在代码里写的日志保存的目录):
tensorboard --logdir ./log/
打开浏览器,输入命令行中提示的地址(http://localhost:6006/),回车,效果图如下:
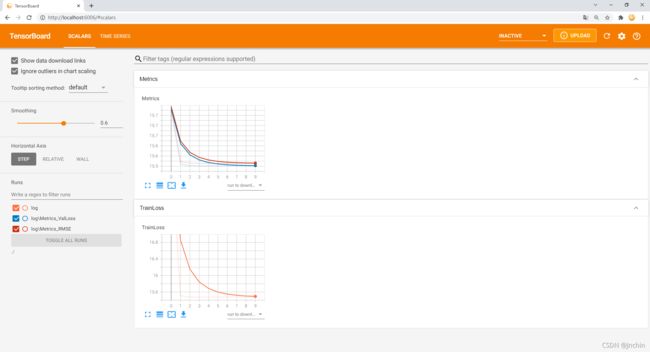
使用右上角刷新功能可以实时查看训练情况。
子图分组
当记录了很多标量值信息后,会出现图像大量堆叠导致UI 混乱不美观。可以使用分组功能,使用方式也非常简单,只需要将参数tag或者main_tag分层命名即可,代码如下:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
with SummaryWriter() as writer:
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
效果图:

至此,对于一些简单的机器学习任务,这些工具就已经够用了。下面开始进阶操作。
【HISTOGRAM】记录分布的信息
histogram(直方图)就是用于显示 Tensor 的分布是如何随时间变化而变化。通过显示大量不同时间点的直方图来可视化 tensor 的变化。一般用来记录Tensor的分布变化情况(如:梯度、权重、神经元输出等),比如查看神经元输出激活之前的分布和激活之后的分布变化。
使用方法:
# strat training
writer = SummaryWriter(log_dir='./log')
for epoch in range(100):
train_loss = train_one_epoch(epoch)
val_loss, rmse = eval_model(epoch)
# 【关键代码】
for name, param in model.named_parameters():
writer.add_histogram(tag=name+'_grad', values=param.grad, global_step=epoch)
writer.add_histogram(tag=name+'_data', values=param.data, global_step=epoch)
writer.close()
代码说明:
add_histogram的用法和上面的一样,tag是数据标识符,values是要记录的数据,global_step是第几步。- 注意:
values传入的是多维数组(Tensor或者array)而不是标量,如果传入的是高维数组,会将其先扁平到一维,再分桶统计成直方图。统计方法与numpy.histogram类似。
执行上述代码后–>命令行tensorboard --logdir ./log/–>浏览器http://localhost:6006/–>点开【HISTOGRAMS】选项卡,效果如下:
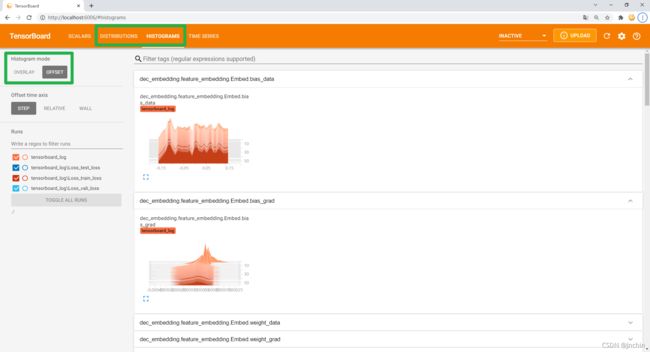
可以看到相比之前多了两个选项卡【HISTOGRAMS】和【DISTRIBUTIONS】,其实这两个都是用来查看histogram统计结果的,只不过前者以直方形式显示统计结果, 后者提供更为抽象的统计信息。
在选项卡【HISTOGRAMS】中提供了两种显示模式:OVERLAY和OFFSET(左上角),可以看到在不同视角下的直方图分布情况。
下面解读一下两种图的含义:
【HISTOGRAMS】
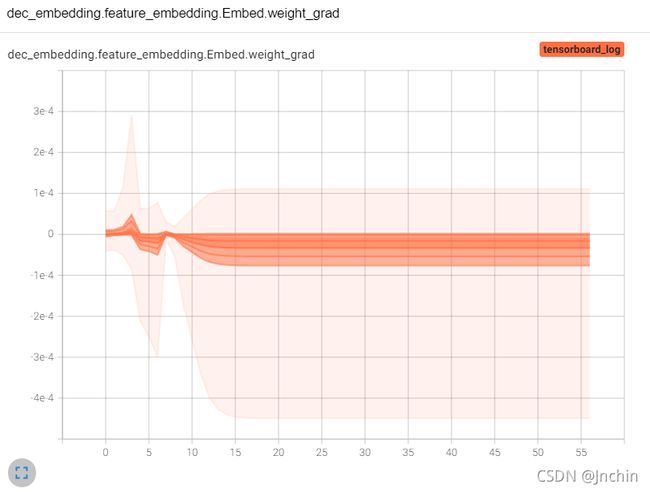
在选项卡【HISTOGRAMS】中点开名为dec_embedding.feature_embedding.Embed.weight的图像窗口后,如下所示:

可以看到这张图是展示了该网络层的梯度分布图像。梯度就是个向量,可以看成数组,在统计时会把所有的梯度扁平成一个一维数组,然后用直方图统计起来。
-
横轴表示这些梯度中元素值的分布范围,纵轴表示第几轮。
-
当把鼠标放在图上时,会出现的一条黑线和数字点,如上图这个黑线就表示第30轮的时候统计的直方图,这个黑色数字点表示第30轮时有922个梯度元素值等于0.0000175。
从上图可以得以下信息:
1、大约在第15轮之后,梯度中元素值的分布就不再改变了,且都集中在0附近。
2、结合【SCALARS】中loss曲线一直保持不变,说明模型可能遇到了训练瓶颈或者鞍点,或者是网络退化?
3、如有错误或者补充,望指出。
【DISTRIBUTIONS】
【DISTRIBUTIONS】的图和【HISTOGRAMS】图显示的数据源都是相同的,只是用不同的方式对相同的内容进行展示而已。
在选项卡【DISTRIBUTIONS】中点开名为dec_embedding.feature_embedding.Embed.weight的图像窗口后,如下图:
-
横坐标表示第几轮,纵坐标表示梯度中元素值的分布范围。
-
不同的颜色表示梯度中元素值在某个区域值出现的频次,颜色越深表示出现的频次越多。
从上图可以看出以下信息:
1、总体来看,梯度中元素值在0附近颜色普遍最深,也就是说在0附近这个区域权重值的取值频次最高。
2、在第15轮之后,梯度值出现频次不再改变且总体出现频次范围变大了,说明很有可能梯度的方向一直在来回改变,梯度的元素值不变,我觉得可能是小幅度的梯度震荡。
3、如有错误或者补充,望指出。
【GRAPHS】记录模型架构
【GRAPHS】可以记录模型结构,可视化网络结构及训练流程。
使用方法:
# 写个模型
class MyModel(nn.Module):
def __init__(self, i_f=2, o_f=1):
super(MyModel, self).__init__()
self.linear1 = nn.Linear(i_f, 4)
self.linear2 = nn.Linear(4, o_f)
def forward(self, x):
x = self.linear1(x)
x = nn.functional.relu(x)
x = self.linear2(x)
return x
model = MyModel()
# 【关键代码】
writer = SummaryWriter(log_dir='./log')
fake_input = torch.randn(16,2)
writer.add_graph(model=model, input_to_model=fake_input)
writer.close()
代码说明:
- 直接将
add_graph代码插入到模型实例化后面即可,不过要注意的是,在这之前需要自行创建一个假的输入数据。- 参数
model就是你的实例化好的模型,参数input_to_model就是输入到模型的数据。
效果图如下:
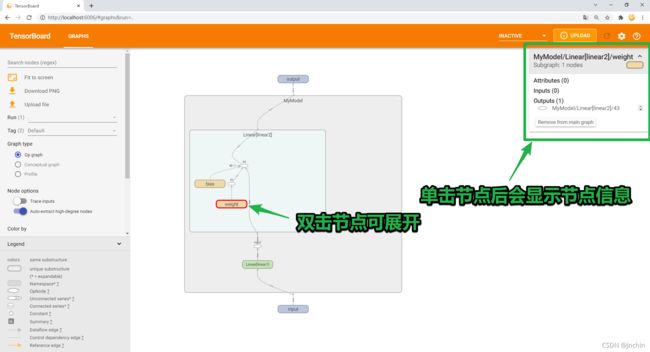
【其他功能】我暂时用不到,以后用到再补充
常见的有:
add_image # 添加图像数据
add_images # 添加多个图像数据
add_figure # 将 matplotlib 图形渲染为图像并将其添加到摘要中。需要matplotlib包。
add_video # 添加视频数据
add_audio # 添加音频数据
add_text # 添加文本书数据
add_embedding # 添加嵌入投影仪数据。
add_pr_curve # 添加精确召回曲线。
add_custom_scalars # 通过在“标量”中收集图表标签来创建特殊图表。注意,此函数只能为每个 SummaryWriter() 对象调用一次,不能在循环里用。
add_hparams # 添加一组要在 TensorBoard 中进行比较的超参数。
add_mesh # 向 TensorBoard 添加网格或 3D 点云。
具体使用详情看官方文档。