Transformer原理解析
Transformer
RNN的提供了一种对带有时序依赖关系的数据更好的建模方式,常用的seq2seq结构使RNN可以输入输出的维度不一样,解决了某一些文本问题(如翻译),带有Attention的seq2seq结构使decoder部分不再完全依赖中间的语义向量Context,还结合了所有encoder中隐藏层的状态,使各种文本任务的精度得到了很大的提升。而带Attention的seq2seq结构存在无法并行的问题,因为RNN的结构要求输入需要一个接一个。Transformer结构就是为了解决无法并行的问题而产生的,使用Attention的结构完全代替了RNN部分,并且效果达到更优。
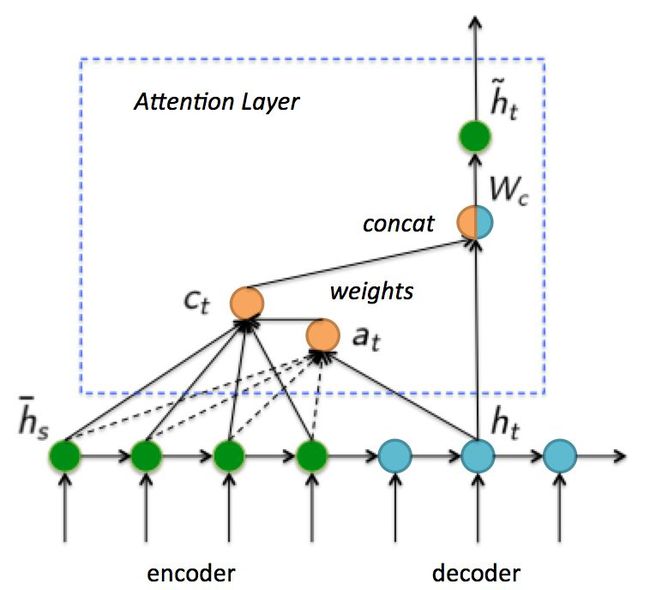
带Attention的RNN
- 首先,计算Decoder的t时刻隐藏层状态 h t h_t ht对Encoder每一个隐藏层状态 h s ‾ \overline{h_s} hs的得分,然后进行softmax得到权重 a t ( s ) a_t(s) at(s)。
- 其次,利用权重计算所有隐藏层状态 h s ‾ \overline{h_s} hs加权之和 c t c_t ct。
- 最后,将加权和与隐藏层状态拼接在一起经过一次线性变换和激活函数得到 h t ~ \widetilde{h_t} ht ,再经过一次线性变换得到输出。
Transformer
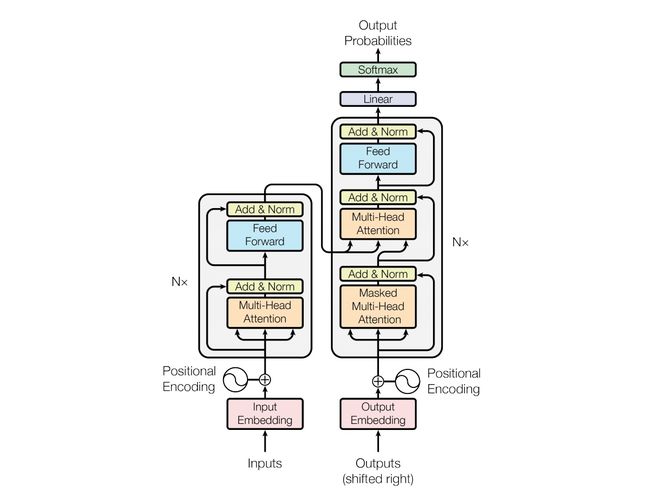
transformer同样包括encoder和decoder两个部分,输入的文本序列先经过embedding,在加上位置编码后输入到encoder部分中,输出的隐向量与输入的维度完全相同。在decoder层输入的是encoder的隐向量和标签embedding向量经过right shift之后的向量,因为在训练阶段要用ground truth。最后decoder输出的向量经过线性层和softmax得到分类结果。整个模型不需要串行输入所以是可以并行训练的,但测试阶段没有ground truth,所以decoder部分要得到一个词的结果之后再输入到decoder中去的一个一个词生成。
位置编码
Transformer抛弃了RNN,而提出了用位置编码来将相对位置信息加到输入当中。位置编码可以通过学习得到位置的embedding,也可以直接计算不同频率的sine和cosine函数,两种方法的效果是很接近的。下面介绍函数直接计算的方法。
P E ( p o s , 2 i ) = s i n ( p o s / 100 0 2 i / d m o d e l ) PE_{(pos,2i)} = sin(pos/1000^{2i/d_{model}}) PE(pos,2i)=sin(pos/10002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 100 0 2 i / d m o d e l ) PE_{(pos,2i+1)} = cos(pos/1000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/10002i/dmodel)
pos代表文本在句子中的位置,2i代表embedding中索引,当索引是偶数的时候用第一个公式,当索引是奇数的时候用第二个公式。通过这种方法得到的位置编码的优势是,每两个位置处的编码只与两个pos的差k有关,缺点是无法辨别谁在前谁在后。
Encoder
encoder包括N(=6)个encoder layer,每个layer都包含Multi-Head Attention层、Add&Norm层、Feed Forward层和Add&Norm层。Add就是常用的残差连接,Norm使用的是LayerNorm,前馈网络层就是linear+activation+dropout+linear组成的,整体架构如下。
src = positional_encoding(src, src.shape[-1])#位置编码
src2 = self.self_attn(src, src, src, src_mask, src_key_padding_mask)#multi-Head Attention
src = src + self.dropout1(src2) #残差连接
src = self.norm1(src)#Layer Norm
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))#前馈网络层
src = src + self.dropout(src2)#残差连接
src = self.norm2(src)#layer Norm
Multi-Head Attention
多头注意力网络是Encoder中的重点。Multi-Head就是指通过head个不同的线性变换对q,k,v(embedding向量)进行投影,最后将不同的attention结果拼接起来。
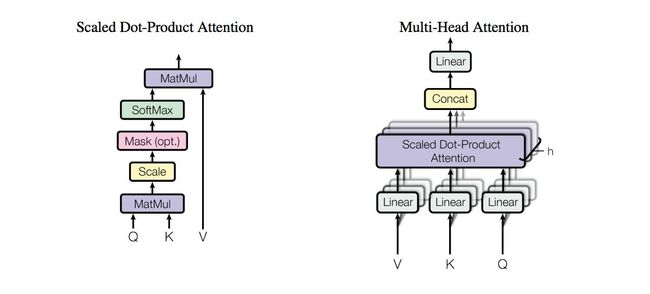
为了计算更快的具体操作是先用一个更大的线性变换(比如,原来每个线性变换是(emb_dim*head_dim),现在是(emb_dim *(head_dim *k)),然后再通过resize,变成(emb_dim *head_dim),这样在attention计算中将h次矩阵计算变成了一次。例如(seq,batch,emb_dim)的数据,先转变成(seq,batch *head,head_dim),再更换维度(batch *head,seq,head_dim),进行attention的计算,之后再更换维度(seq,batch *head,head_dim),resize变回(seq,batch,emb_dim),所以要保证head的数目可以被embedding_dim整除。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k V ) Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}}V) Attention(Q,K,V)=softmax(dkQKTV)
在自注意力中输入的q,k,v都是一样的,但是线性变换矩阵不一样,所以Q,K,V也不一样了。
Decoder
Decoder和Encoder的结构差不多,但是其还有两个attention部分,它们是不一样的,第一个attention是使用含有mask矩阵的self-attention,第二个attention不是self-attention,因为它的K、V是来自encoder的输出,而Q是上一位置decoder的输出词的embedding向量。Decoder的输出是对应i位置的输出词的概率分布。
这里要注意一下,训练和预测是不一样的。在训练时,解码是一次全部decode出来,用上一步的ground truth来预测(mask矩阵也会改动,让解码时看不到未来的token;而预测时,因为没有ground truth了,需要一个个预测。