YOLOv5-水印检测
简介:
YOLOv5在YOLOv4算法的基础上做了进一步的改进,检测性能得到进一步的提升。虽然YOLOv5算法并没有与YOLOv4算法进行性能比较与分析,但是YOLOv5在COCO数据集上面的测试效果还是挺不错的。
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
1>输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
2> 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
3> Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
4> Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
网络结构:
改编自知乎大佬的一张图:
Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的3种(Yolov5m、Yolov5l、Yolov5x)都是在此基础上不断加深,不断加宽。
在这里插入图片描述
参数:
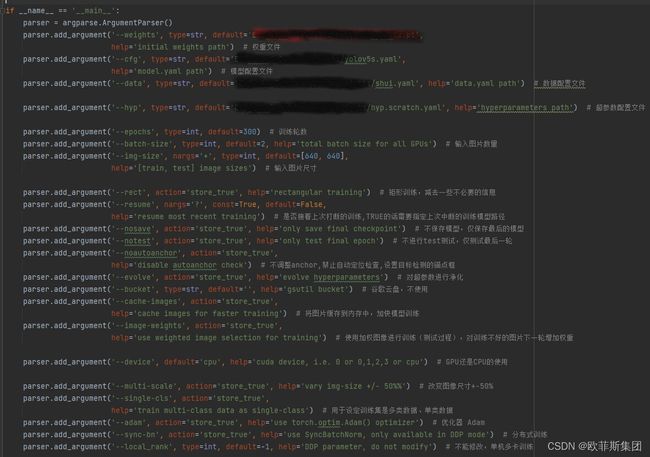
train.py
(训练文件)

**cfg:**网络结构参数配置文件(锚点、骨干网络、头网络)
**data:**数据位置的配置文件
**hyp:**超参数配置文件(学习率、损失增益等)
**epochs:**训练轮数
**batch-size:**图片输入数量
img-size:输入图片大小,放缩图片
rect:矩形训练,减去一些不必要的信息
resume:是否接着上次打断的训练,TRUE的话需要指定上次中断的训练模型路径
nosave:不保存模型,仅保存最后的模型
notest:不进行test测试,仅测试最后一轮
noautoanchor:不调整anchor,禁止自动定位检查,设置目标检测的锚点框
evolve:对超参数进行净化
bucket:谷歌云盘,不使用
cache-images:将图片缓存到内存中,加快模型训练
image-weights:使用加权图像进行训练(测试过程),对训练不好的图片下一轮增加权重
device:GPU还是CPU的使用
multi-scale:改变图像尺寸
single-cls:用于设定训练集是多类数据、单类数据
adam:优化器
sync-bn: 分布式训练
local_rank:不能修改,单机多卡训练
workers:最大工作训练核心、线程 网上建议设置0
project:模型保存位置,没有会自动生成
entity:wandb库,可以看训练过程,一般不用(需要自己注册账号)
name:模型保存的文件夹,多次运行:exp1,exp2…
exist-ok:预测结果保存位置,覆盖上次结果不新建结果文件
quad:用于训练集图像大于–img-size设置的640图片,训练效果更好,小于的效果差一些
linear-lr:学习速率调整,默认FALSE 通过余弦函数降低学习率
label-smoothing:防止过拟合,对标签进行平滑处理,防止分类算法中产生过拟合
upload_dataset:wandb库的
bbox_interval:wandb库的
save_period:用于记录训练日志
yolov5s.yaml
(进行和你选择的结构参数配置文件)

nc:分类的类别
depth_multiple和width_multiple:根据选择的配置文件不同而不一样
voc.yaml
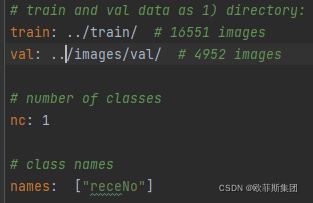
train和val指定训练数据的位置,还可以设置test
nc:分类的类别
names:每个类别的名字
detect.py
(预测文件)
source:预测数据路径
weights:训练好的best.pt文件路径
conf-thres:置信度阈值
iou-thres:交并比阈值
conf-thres和iou-thres确定返回的预测框
test.py
(测试文件)

save-txt:返回检测框TXT文件
save-hybrid:标签和预测结果保存TXT文件
save-conf:检测到的坐标返回TXT文件
其余参数大致和train相同
数据标注

使用标注精灵:新建一个项目,选择位置标注和自定义标注类别,导入数据,选择矩形框标注,导出数据为XML文件。
格式转化
voc2yolov5.py
classes:类别名称
TRAIN_RATIO:按比例划分train和val
convert_annotation函数:读取xml文件,写入TXT文件,确定标注好的XML文件和查找位置相同

os.getcwd() 绝对路径
创建放图片、labe、train、val等文件夹
过程:
先进行数据的格式转化,然后train的参数修改,最后修改对应的配置文件,运行train进行模型训练。
预测、测试同理
先进性格式转换voc2yolov5.py:
修改以下对应位置:
classes = ["XMH"] #类别名称,对应需要的类别
TRAIN_RATIO = 80 #训练验证集按80%20%分
def convert_annotation(image_id):
in_file = open('../%s.xml' % image_id,encoding="utf-8") #对应XML文件路径
out_file = open('../%s.txt' % image_id, 'w',encoding="utf-8") #对应保存转换后txt文件路径
convert_annotation函数下获取XML标注信息,所以循环里面需要和XML对应
wd获取的相对路径
train.py文件
weights: 修改下载的权重文件路径
cfg: 修改网络结构参数配置文件路径
data: 修改数据配置文件路径(修改对应配置文件信息)
hyp: 修改超参数配置文件路径(可以学习率、损失增益等,看情况)
epochs: 修改训练轮数(根据自己需求)
batch-size: 修改图片输入数量(按自己电脑内存大小修改输入批次大小)
img-size:修改输入图片大小,放缩图片(一般640)
resume: 修改路径(上一次没有训练完的权重文件路径)
project,name:保存文件路径
workers:建议为0
device:选用CPU或者GPU(0,1,2…)
detect.py文件
weights、img-size、device、project、name同上
source:修改数据路径(测试、预测数据)
conf-thres:置信度(建议0.6)
iou-thres:交并比(建议0.5)
save-txt:保存坐标信息,增加路径
找到utils下面的plots.py文件中的plot_one_box函数:
打印坐标信息:
def plot_one_box(x, img, color=None, label=None, line_thickness=3):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
print("左上点的坐标为:(" + str(c1[0]) + "," + str(c1[1]) + "),右下点的坐标为(" + str(c2[0]) + "," + str(c2[1]) + ")")
或者修改detect.py:
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
label = f'{names[int(cls)]} :{conf:.2f}'
x1 = int(xyxy[0].item())
y1 = int(xyxy[1].item())
x2 = int(xyxy[2].item())
y2 = int(xyxy[3].item())
lab.append(label)
loc.append([x1, y1, x2, y2])
print('bounding box is:', x1, y1, x2, y2) # 打印坐标
print(lab)
print(loc)
a = (x1, y1, x2, y2)
with open(txt_path + '.txt', 'a') as f:
# f.write(('%g ' * len(line)).rstrip() % line + '\n')
f.write(str(a) + '\n')
f.write(str(label))
保存TXT文件,a是坐标信息(可以直接写入(x1,y1,x2,y2))
label获取的是标签信息
test.py大致和train.py相同
结果:
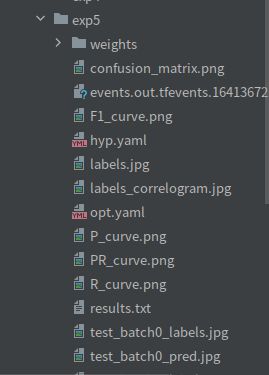
配置文件指定路径下生成结果,模型权重文件防在weights下面,存在best和last(最好的和最好的),参数文件
检测结果:

开始运行: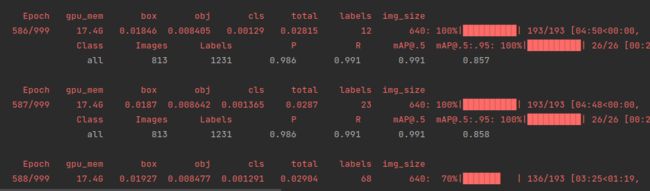
报错:
wandb:报错说没有账号等,可以直接关闭
找到utils下的wandb_loggig下面的wandb_utils添加:
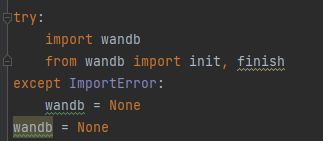
安装pycocotools报错:
按要求,在官网下载对应的VISUAL
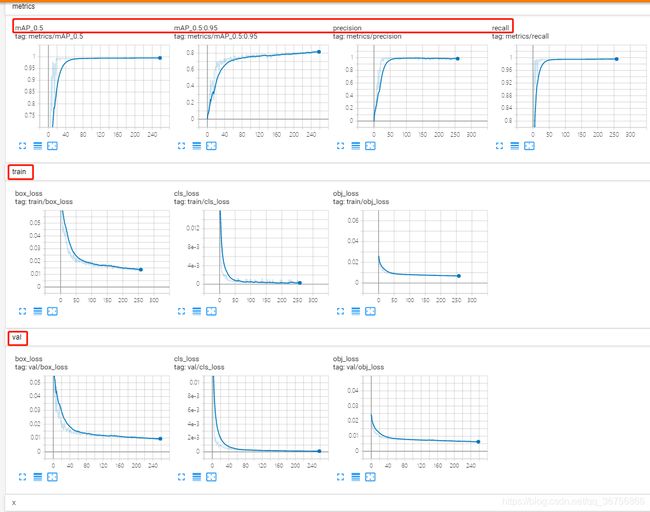
利用tensorboard可视化训练过程,训练开始会在yolov5目录生成一个runs文件夹,利用tensorboard打开即可查看训练日志:
tensorboard --logdir=runs
注意:数据转化的时候一定要把数据类别名称加上。
环境:
