基于深度学习的小目标检测方法的调查和性能评估
A survey and performance evaluation of deep learning methods for small object detection
此文为翻译论文,原文地址:
https://www.sciencedirect.com/science/article/abs/pii/S0957417421000439
原文
摘要:在计算机视觉领域,随着深度卷积神经网络(CNN)的迅速发展,目标检测技术取得了重大进展。本文综述了近年来发展起来的用于小目标检测的深度学习方法。我们总结了小目标检测的挑战和解决方案,并介绍了主要的深度学习技术,包括融合特征图、添加上下文信息、平衡前景-背景示例以及创建足够的正面示例。我们讨论了四个研究领域的相关技术,包括通用目标检测、人脸检测、航空图像中的目标检测和分割。此外,本文基于三个大型小对象基准数据集,比较了几种主要的小对象检测深度学习方法,包括YOLOv3、快速R-CNN和SSD的性能。我们的实验结果表明,虽然这些深度学习方法对小目标的检测精度较低,小于0.4,但速度较快的R-CNN表现最好,而YOLOv3则紧随其后.
1、引言
目标检测是计算机视觉的基本任务之一。通常,目标检测和识别包括两个步骤:首先,定位每个目标的潜在位置;然后,将目标划分为不同的类别。在深度学习方法兴起之前,目标检测方法依赖于人工设计的特征和基于人类理解目标的方式设计的分类器。近年来,由于深度学习,特别是深度卷积神经网络(CNN)的成功,目标检测领域有了长足的发展。目标检测已广泛应用于许多应用,如自动驾驶、视觉搜索、虚拟现实(VR)和增强现实(AR)等。尽管在许多应用中已经实现了对图像中的中大型目标的精确检测,但对小目标的准确检测,例如航空图像中的20x20像素鸭子,仍然具有挑战性。由于难以区分的特征、低分辨率、复杂的背景、有限的信息背景等原因,小目标很难检测。这是一个活跃的研究领域,近年来发展了许多深度学习技术,并取得了很好的结果。一些工作表明了组合不同特征层的重要性,而另一些工作表明上下文信息非常有用.此外,提高分类准确度的技术,如处理不平衡的分类示例和不足训练的技术,也取得了良好的效果。
1.1本文主要内容
本文主要研究用于检测图像中小目标的深度学习技术。我们对相关的目标检测和实例分割方法进行了全面的回顾。我们确定并分析了主要挑战,总结了提高小物体检测性能的策略。首先,我们讨论了四个方面的挑战:1)基本CNN中各个层生成的特征不包含用于小目标检测的足够信息;
2) 小目标检测缺乏背景信息;
3) 前场和背景训练样本的不平衡使得分类困难;
4)针对小对象的正面训练示例不足。
然后,我们从
1)组合多个特征映射,
2)添加上下文信息,
3)平衡类示例,
4)创建足够数量的正面示例
四个角度总结了现有的小目标技术。我们介绍了四个不同研究领域的相关技术,包括通用目标检测、人脸检测、航空图像中的目标检测和实例分割.最后,报告了我们的实验结果,比较了几种最先进的深度学习方法在以小目标为中心的基准数据集上的性能。本文的主要贡献如下:
1)全面回顾了关于小目标检测的最新深度学习技术
2)从四个具体方面确定小目标检测面临的挑战,总结深度学习方法的主要组成部分,并从四个方面对现有方法进行分类
3)分析并连接四个研究领域的相关技术,包括通用目标检测、人脸检测、航空图像中的目标检测和分割
4)在三个小目标基准数据集上对一些最先进的深度学习方法进行实证性能评估。
1.2 与以往综述论文的比较
(Zou, Shi, Guo, & Ye, 2019)的综述涵盖了过去20年中的目标检测方法,包括传统检测方法和深度学习方法。本文主要研究在过去5年中发展起来的用于小目标检测的深度学习方法.(Zou等人,2019年)综述了通用目标检测的深度学习方法,而本文包括在四个研究领域开发的方法,包括通用目标检测、人脸检测、航空图像中的目标检测和分割.(Leevy、Khoshgoftaar、Bauder和Seliya,2018年;Oksuz、Cam、Kalkan和Akbas,2019)专注于克服类不平衡问题的方法.(Zhao,Zheng,Xu和Wu,2019)回顾了几个目标检测任务中的几种最先进的深度学习框架,并分析了不同的方法和一般目标检测的实验结果.(刘等人,2020年;Jiao等人,2019)回顾了用于目标检测的深度学习方法和技术。然而,他们没有提供这些深度学习方法的实验分析.(Wu,Sahoo和Hoi,2020)回顾了目标检测组件、模型和学习策略。尽管这些作品提供了一个全面的回顾,他们的重点是一般大小的目标,而不是小目标.
最近,关于小目标检测也有一些综述。Nguyen、Do、Ngo和Le(2020年)对小目标的现有目标检测方法进行了回顾,并重点对四种模型进行了性能评估。相比之下,本文提出了一个更为深入和全面的综述和不同的角度的挑战。此外,我们总结了现有深度学习方法的主要组成部分,将现有的检测方法分为四个方面,从目标检测的四个不同应用领域连接和分析了当前的深度学习方法,并评估了三个模型在三个不同数据集上的性能。Tong、Wu和Zhou(2020)主要从五个方面回顾了现有的改进小目标检测的方法,并在两个数据集上分析了实验结果。相比之下,本文不仅总结了不同方面的现有方法,还识别和分析了四个具体方面的关键挑战,连接和分析了几个相关研究领域的解决方案,并给出了不同数据集的实证结果。
综上所述,本文在几个方面与以往的综述文章有所不同。首先,我们的回顾侧重于小目标。其次,我们的综述包括主要检测组件和最先进的目标检测框架的概述。第三,分析了小目标检测面临的挑战,总结了提高小目标检测精度的主要技术。此外,我们还分析和连接了四个小目标检测应用领域的技术,这些领域涵盖了广泛的小目标检测任务。最后,我们在小目标基准数据集上对三种有代表性的深度学习框架进行了实际比较.
论文的其余部分组织如下。第2节概述了图像中目标检测的深度学习方法和主要组件.第3节介绍了主要的深度学习方法以及用于小目标检测的框架。第4节确定了小目标检测的挑战和解决方案,以及在四个相关研究领域开发的主要技术。第5节介绍了几种主要的小目标检测深度学习方法在三个小目标基准数据集上的实验结果。最后,第六部分讨论了未来的研究方向。
2.基于图像的目标检测深度学习方法综述
2.1问题定义
图像目标检测的目标是检测图像中预定义类对象的实例,并在每个对象周围绘制一个紧密的边界框。更具体地说,目标检测包括两个任务:目标定位和分类,即查找目标在图像中的位置并确定每个对象所属的预定义类别。
2.2. 深度学习方法的主要组成部分
在本节中,我们总结了基于图像的目标检测的深度学习方法的主要组成部分,包括主干网络、区域候选、锚框、目标分类、边界盒回归、损失函数和非极大抑制。
2.2.1.主干网络
基于深度神经网络的目标检测器中的主干网络用于从输入图像中提取高级特征。最常用的主干网络源自深度神经网络图像分类器,该分类器在大规模图像分类数据集上表现良好,如ImageNet分类数据集(Huang、Liu、Van Der Maaten和Weinberger,2017;Szegedy等人,2015年;塞格迪、范霍克、伊夫、斯伦斯和沃伊纳,2016年;Newell,Yang和Deng,2016;何,张,任,孙,2016;Howard等人,2017年;Simonyan&Zisserman,2014年)。通常,最后的分类层从这些图像分类器中移除,其余层用作主干网络。在主干网的基础上,增加检测层,形成完整的目标检测器。主干网的主要设计目标是高检测精度和计算效率。下面是一些流行的主干网。
VGGNets(Simonyan&Zisserman,2014)在卷积层中使用大小为3×3像素的小过滤器,然后使用2×2最大池。VGG16有13个卷积层,而VGG19有16个卷积层。VGG在2014年赢得了ImageNet挑战赛,仍然是使用最广泛的网络之一
残余网络,或Resnet(He等人,2016),其中提出了残余块,通过直接从每个模块的输入添加跳过连接,克服反向传播中的梯度消失问题,使训练非常深入的网络成为可能。剩余网络有几种变体。最常用的版本是ResNet50和ResNet101。ResNet比VGGNet深得多。ResNet赢得了ImageNet 2015分类任务.
Inception networks(Szegedy等人,2015年、2016年)在不增加计算复杂性的情况下增加了网络的深度和宽度。初始模块由1x1、3x3和5x5过滤器大小的卷积层和最大池层组成,这些层彼此平行堆叠。在一层中可以同时提取多个尺度的特征。初始网络比VGGNet快得多.
DenseNet(Huang et al.,2017),其中每一层都与前庄园中的所有其他层紧密相连,因此后一层的所有层都使用较低层特征。DenseNet可以缓解消失梯度问题。
已经开发了许多技术来改进主干网。例如,沙漏网络被设计用于捕捉多尺度特征,并被广泛用于姿态估计和目标检测(Newell等人,2016)。一个简单的沙漏模块由卷积层和最大池层组成,用于以低分辨率提取特征。在几个池层之后,网络使用上采样层和来自所有不同大小缩放图像的组合特征。最后,应用两个1x1卷积层生成最终预测。堆叠的多个沙漏模块遵循自下而上和自上而下的方法,跨越不同大小的缩放图像。对于嵌入式设备上的深度学习模型,(Howard等人,2017年)提出了一种可以在移动设备上运行的轻量级网络。它用深度卷积和1x1点卷积代替了标准卷积层,与其他深度神经网络相比,大大减少了计算量。PvaNet(Kim等人,2016年)利用CReLU、初始模块和多尺度输出设计了轻薄的特征提取。
2.2.2区域候选
生成区域候选的主要方法包括约束参数最小割(CPMC)、多尺度组合分组、选择性搜索和区域建议网络(RPN)。CPMC(Carreira和Sminchisescu,2011)将学习一个模型来对细分市场进行排名。具体来说,从片段中提取大量特征,如图特征、区域特征和格式塔特征。这些片段根据它们与地面真相的相似性进行排序。因此,排序问题被建模为一个回归问题,以预测与地面真相的相似性。该模型在具有不同程度背景偏差的图像上进行训练。然后最大化分段之间的重叠分数。多尺度组合分组(Pont Tuset、Arbeĺaez、Barron、Marques和Malik,2016)提出了一种考虑多尺度信息的分层分割方法。基于子采样和超采样构造图像金字塔。单尺度分割应用于每个图像分辨率。在重新缩放和对齐后,将不同的分割贴图组合起来。多尺度区域的组合将进一步一起处理。选择性搜索(Uijlings、Van De Sande、Gevers和Smelders,2013)是一种广泛用于目标检测的基于分割的方法。它按层次对候选区域进行分组,并生成包含类别独立对象的信息位置。然而,它不是基于神经网络的,不能使用数据集进行训练,而且速度很慢。RPN(Ren、He、Girshick和Sun,2015)是第一个基于CNN的网络,可以与其他检测网络一起训练。它同时预测目标区域和目标分类置信度得分。RPN的输入为图像,其输出包含具有对象分数的感兴趣区域(ROI)。具体来说,它使用小型网络作为卷积层上的滑动窗口。每个滑动窗口对应于输入图像中的一个区域,并且可以被视为具有不同比例的区域建议。将特征分为两个预测层:分类层和盒回归层。分类层执行二进制分类以预测区域是否包含任何对象。
2.2.3锚
锚,也称为锚框,(Ren等人,2015)首次提出。锚是一组预定义的边界框,具有各种比例和比率,放置在特征图上。特征图上不同位置的锚点被投影回输入图像,以与真实边界框匹配。每个特征图的步幅由H/H和W/W计算,其中H和W分别是输入图像的高度和宽度,H和W分别是特征图的高度和宽度。锚框的比例和比率通常是预定义的,以最大限度地匹配真实边界框。一些研究人员使用训练数据集无监督聚类方法来计算尺度和比率.在训练期间,锚与地面真相边界框通过IoU(联合交集)分数匹配。通常,对于每个边界框,得分最高的锚或其与地面真相边界框的IoU高于阈值的锚被标记为正面示例。这些主播,其IoU分数与地面真相框低于一个阈值,被标记为负面的例子。利用正反两个例子训练分类器进行目标分类。仅对正例进行进一步回归,以确定对象的位置。(Wang,Chen,Yang,Loy,&Lin,2019)提出了一种新的锚sheme,称为引导锚定,通过使用语义特征动态引导锚定生成。更具体地说,锚在预测概率高于某个阈值的特征地图上生成.
2.2.4目标分类
分类的目标是预测图像中目标的类别,即预测给定感兴趣区域(RoI)不同类别标签的概率。由于定位问题是通过边界框回归处理的,因此对象分类组件类似于应用于每个RoI的标准分类问题,而不是整个图像。目标分类和边界框回归任务共享同一主干网络,以产生良好的结果.
2.2.5边界框回归
边界框回归是学习将预先设定的边界框映射到相应的地面真值边界框的变换。它要么应用于两级对象检测器的第一阶段中使用的方案,要么用于细化估计的边界框以使其更精确。在(Girshick、Donahue、Darrell和Malik,2014)中,对具有CNN特征的线性回归模型进行了训练,以更好地定位边界框。它有四个变换参数用于中心(x和y坐标)以及区域的宽度和高度。对于区域方案(P)和地面实况(G),四个参数的计算如下:

各种边界盒回归损失函数已经提出了。在(He,Zhu,Wang,Savvides&Zhang,2019)中,基于预测边界盒分布和地面真值分布的Kullback-Leibler散度,提出了KL损失(Kull-back-Leibler)。在(Lee,Kwak和Cho,2018)中,提出了一种边界盒回归神经网络,分别使用卷积层、完全连接层和ROI对齐层进行训练,以最小化IoU损失。(Yu,Jiang,Wang,Cao和Huang,2016)提出了边界盒回归的IoU损失,并将所有边界盒变量一起回归。IoU损失对尺度不变量不敏感(Rezatofighi et al.,2019),发现IoU与最小化ln范数损失函数没有很强的关系。因此,GIoU建议通过不仅考虑重叠区域,而且关注非重叠区域来解决此问题。(Zheng等人,2020年)提出了DIoU损耗,以解决早期工作中的缓慢收敛问题。此外,通过考虑重叠面积、中心点距离以及纵横比,进一步提出了CIoU.
2.2.6损失函数
在目标检测中,多任务损失函数已经广泛应用于同时最小化对象分类和边界框回归的错误。对于分类,softmax loss已用于计算前景背景类。对于回归损失,SmoothL1(定义如下)已被广泛使用。仅对预测为前景类的边界框(即对象)计算此损失。
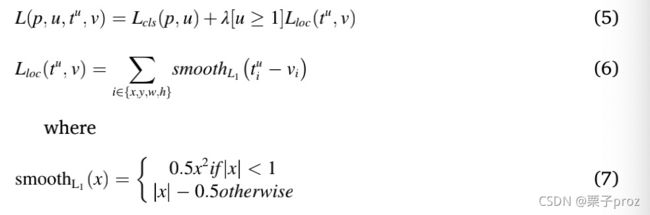
p分布在所有类别.由softmax层计算.
这句话被改写如下:然而,由于大多数输入图像中缺少前景对象,因此很难在训练阶段捕获前景对象的有效模式和信息。为了克服这一挑战,提出了另一种多任务丢失函数用于目标检测,以提高性能。(林,戈亚尔,吉尔希克,何和多尔́ar,2017)。在(Lin,Goyal,et al.,2017)中,提出了聚焦损失,通过降低简单示例的权重来解决前景和背景示例之间的不平衡问题。

其中y是标签,p是模型的估计概率。γ是聚焦参数,它减少了小样本的权重,α是控制前景和背景示例的平衡。
2.2.7非极大抑制
NMS作为推理阶段的后处理步骤,用于删除同一对象的冗余重叠检测结果。贪婪方法是首先根据分数对所有检测框进行排序,然后贪婪地选择分数最高的检测框,如果它们与所选框显著重叠,即它们在联合(IoU)分数上的交集高于设计阈值,则抑制其他区域。NMS通常独立地应用于每个对象类。在(Rothe、Guillaumin和Van Gool,2014)中,通过将问题视为消息传递聚类问题并从训练数据中学习阈值参数(而不是预定义阈值),找到了改进的解决方案。最近,(Bodla、Singh、Chellappa和Davis,2017年)和(Hosang、Benenson和Schiele,2017年)提出了采用软阈值的方法来提高性能。在标准NMS中,较低分数区域与较高分数区域显著重叠的区域将被丢弃。然而,在软NMS中(Bodla等人,2017年),较低分数区域保留在结果中。(Hosang等人,2017)提出了一个CNN网络,通过使用相邻区域的检测结果来更新一个区域的检测结果来执行NMS.
3基于深度学习的目标检测方法
3.1基于锚的深度学习方法
基于锚的目标检测深度学习方法可分为两大类:两级目标检测器和一级目标检测器。两级物体探测器,如更快的R-CNN(Ren等人,2015年),将检测问题分为两个阶段:区域建议阶段和检测阶段。区域建议阶段的目标是生成对象可能存在的区域。它输出区域位置以及对象分数0或1,以指示是否存在对象。在检测阶段,候选区域建议被划分为不同的类别。此阶段输出类别概率和(可选)细化区域位置。两级探测器实现了最先进的性能;然而他们的跑步速度通常很慢。单级目标探测器,如YOLO(Redmon、Divvala、Gir-shick和Farhadi,2016)和SSD(Liu等人,2016),在一个深度神经网络中执行区域建议和检测。初始区域是具有各种比例和比率的预定义锚,在图像上密集平铺。从最初的锚点,探测器找到那些可能包含物体的锚点。与两级检测器相比,一级检测器通常要快得多,但获得的精度较低。以前的一些工作经验评估了一些单级探测器和两级探测器的性能(Soviany&Ionescu,2018a,2018b)。它比较了一些两级检测器和一级检测器之间的检测精度和时间,并得出结论,平均而言,一级检测器比两级检测器的检测速度快,而两级检测器往往比一级检测器更准确。(Soviany&Ionescu,2018b)建议将图像分为易分类和难分类,并在不同的计算机上训练不同的模型,以实现更快的速度和更高的精度.
3.2 两阶段检测代表
R-CNN(Girshick et al.,2014)是将深度CNN分类结果从ImageNet传输到目标检测的第一项工作。R-CNN采用了分离区域提议和目标分类两阶段方法。每个区域建议都被扭曲并输入到深度CNN中,并提取4096维特征向量。在培训期间,首先仅使用图像级别标签在ImageNet数据集上对网络进行预培训。R-CNN在目标检测方面取得了突破,并将VOC 2012数据集的检测精度提高了30%以上。这项工作成功地证明了与人类设计的特征相比,经过训练的CNN特征具有优越性。然而,CNN特征提取被独立地应用于每个区域建议,这使得网络非常缓慢。Fast R-CNN(Girshick,2015)通过解决两个主要问题改进了R-CNN。首先,在两个不同阶段分别对R-CNN进行分类和包围盒回归的训练。
Fast R-CNN将分类和回归训练结合起来。它有两个输出层:一个用于分类分数,另一个用于边界框位置偏移,表示为四个值,即边界框中心点的×、y坐标以及边界框的宽度和高度。提出了一种新的多任务同时训练损失函数。其次,将R-CNN中的特征提取应用于每个区域方案,这既耗时又费时。快速R-CNN通过对整个图像只计算一次卷积特征映射来提高效率。感兴趣区域(RoI)池层旨在为不同大小的区域方案提取固定大小的特征。它将特征映射划分为固定大小的子窗口,并最大化每个子窗口以形成固定大小的特征。尽管快速R-CNN比R-CNN快得多,但它仍然基于传统的区域建议方法,这非常耗时。
Faster R-CNN(Ren等人,2015年)通过使用称为区域建议网络(RPN)的卷积神经网络取代传统的区域建议阶段,进一步提高了快速R-CNN的检测速度。RPN同时预测目标区域和目标置信度得分。该设计的主要优点是RPN与目标检测网络共享相同的卷积层,从而缩短了检测时间.与图像金字塔方法相比,不同的锚定尺寸捕获了多尺度表示,使得计算重量较轻.在第二阶段,对RPN的输出进行进一步分类和定位,以生成最终的检测结果。更快的R-CNN可以进行端到端的训练,整个网络是高效的。
Mask R-CNN(He、Gkioxari、Dolĺar和Girshick,2017)被提议作为更快R-CNN的扩展,并在像素级实例分割上进行额外预测。Mask R-CNN使用速度更快的R-CNN两级管道,具有相同的第一级网络。在第二阶段,它增加了一个额外的输出,为每个区域建议添加了一个二进制掩码,并保留了原始分类和边界框回归。在用于训练的损失函数中,它以二进制交叉熵损失的形式为掩模预测增加了一个额外的项。Mask R-CNN的主要贡献之一是RoI对齐层,该层用于修复RoI池层中的失调问题。其想法是去除RoI边界的量化,而是计算实际值。双线性插值用于计算每个采样点上的真实特征值。从采样点取结果的平均值或最大值。Mask R-CNN实现了最先进的实例级分割。
特征金字塔网络(FPN;Lin,Dolĺar,et al.,2017)专注于解决以下问题:较低级别的特征地图包含更多的空间信息,但语义信息较少,而深层神经网络的后几层包含更多的高级语义信息,但空间信息较少。FPN利用CNN网络的层次结构,通过横向连接实现了自下而上和自上而下的路径。在自底向上的部分中,输入图像通过CNN,并使用池层缩小特征地图的大小。在自上而下的部分中,特征映射被上采样回与自下而上部分相同的大小。此外,横向连接将相同尺寸的自底向上路径和自顶向下路径中的特征映射与元素添加相融合。FPN生成的集成特征映射显著提高了检测精度,尤其是对于小目标.
3.3一阶段检测器
YOLO(Redmon等人,2016年)专注于提高目标探测器的速度。该算法将目标检测问题作为回归问题处理,去除了两级检测器中的区域建议阶段。它将输入图像分成7*7个单元,每个单元用于预测对象的中心落入单元中,而不是为对象区域使用预定义的定位点。每个单元预测边界框位置、每个边界框的分数和类概率。网络实现为卷积层,然后是完全连接的层。误差损失平方和用于最小化定位和分类误差。YOLO是一种实时目标探测器,具有每秒45帧的探测速度,与其他探测器相比速度非常快。然而,类别概率仅在每个单元内预测。它不能很好地处理部分位于一个单元中的对象,不能处理广泛分布的地面真值对象,并且难以精确预测边界盒的比例和比例,从而导致定位精度较低。
YOLOv2(Redmon&Farhadi,2017)提出了对YOLO的几项改进。为了提高召回率,它去除了完全连接的层,并采用锚盒的概念来预测边界盒。采用无监督学习方法直接从训练数据生成包围盒尺度和比例。它不只是预测每个单元的一个类概率,而是预测每个边界框的对象性和类,从而提高了检测部分覆盖对象的性能。对于边界框回归,它预测相对于单元格左上角位置的位置,从而使预测边界介于0和1之间。其他建议的技术包括批量标准化、高分辨率分类和多尺度训练。所有这些技术都极大地提高了检测准确度,同时保持了较快的速度。
YOLOv3(Redmon&Farhadi,2018)提出了比YOLOv2更多的改进。对于分类预测,使用二元交叉墒损失函数代替so ftmax 损失.在一个边界框中处理多个类的情况。它采用多尺度框架和特征pyra-mid对3个不同尺度的目标进行预测。为了提高速度和精度,特别是在小目标检测方面,提出了一种新的带ResNet模块的主干网.
SSD(Liu等人,2016年)是一种单激发检测器,没有区域建议阶段,如图1所示。与仅使用最后一层进行检测的更快的R-CNN不同,SSD使用多层执行检测以更好地捕获多尺度对象。由于锚定被应用于多个特征地图,SSD在层之间设计了各种锚定比例范围。下层的尺度较小,高层的尺度较大。这种设计可以处理范围广泛的对象,从而提高召回率。与YOLO使用完全连接层进行目标检测不同,SSD使用完全卷积层预测置信度得分和定位偏移。通过一些额外的数据扩充和硬负挖掘技术,SSD在几个基准数据集上实现了最先进的性能。然而,SSD在小对象上表现不佳,这是因为它的层很浅,没有深层语义信息。
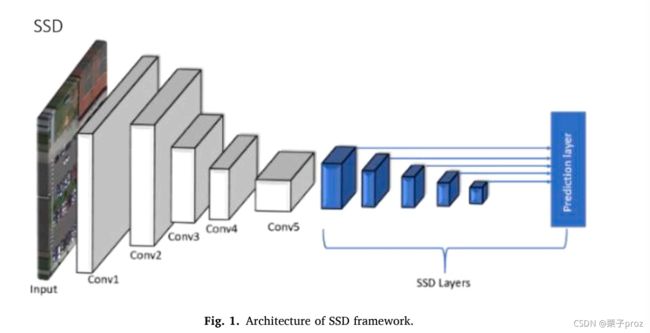
DSSD(Fu、Liu、Ranga、Tyagi和Berg,2017)通过使用更大的网络改进了SSD。他们的实验结果表明,深度强大的主干网ResNet-101的性能优于VGG网络。引入了反褶积模块以添加更多上下文信息。更重要的是,反褶积层可以在训练期间进行训练,从而使DSSD更加灵活并获得更好的性能。为了提高锚定尺度和锚定比率的准确性,采用K-均值聚类对训练盒进行分组,并以平方根盒面积作为距离度量。DSSD提高了SSD的精度,尤其是对于小型对象。
RetinaNet(Lin,Goyal,et al.,2017)被提议作为一个单级目标探测器,以减少与现有两级探测器的检测精度差距,同时保持快速检测时间。这项工作发现,一级检测器和两级检测器之间的准确度差距主要是由于在培训中使用的正面示例和负面示例以及简单示例和困难示例的数量非常不平衡。大量简单的例子支配了损失函数,这导致了退化模型。通过引入一种新的损失函数,称为焦点损失函数,自适应地减少简单示例的权重,解决了这一问题.
4小目标检测挑战和解决方案
在本节中,我们将确定将深度神经网络应用于小对象检测的四个主要挑战,并讨论现有的解决方案。
4.1. 小目标检测的挑战在本节中,我们总结了小目标检测的四大挑战。
4.1.1.1挑战1:单个特征层不包含用于小对象检测的足够信息。
深度CNN体系结构通过池和子采样操作提供层次特征图,从而产生包含不同空间分辨率的不同层特征图。众所周知,在早期的图层特征图中,特征图具有更高的分辨率,并且表示更小的接收场。同时,它们不包含对目标检测很重要的高级语义信息。另一方面,后一层特征地图包含更强的语义信息,这对于识别和分类对象(包括不同的对象姿势或照明)至关重要。尽管更高级别的特征映射对于识别大对象很有用,但它们可能不足以检测小对象。在深度CNN架构中进行多次下采样后,后一种特征地图会丢失空间信息。尺寸为32x32像素的小对象在早期(或较浅的)特征贴图中清晰可见,而不是在深层特征图.因此,单独的低级特征或高级特征不足以检测小目标。
解决方案:结合浅层和深层的特征。为了更好地检测小对象,几种基于深度CNN的方法将低级特征图和高级特征图结合在一起,以获得必要的空间和语义信息。有两种主要的特征地图融合方法:
1)自底向上方案该方案被纳入标准的前馈CNN ar体系结构中。从早期图层到后期图层,要素贴图在池操作后会收缩。最终的检测层直接组合了几个自底向上的特征映射。
2) 自顶向下模式该模式可被视为一种注意机制,propa将高级语义信息返回到低级特征映射。它通常使用卷积-反卷积或编码器-解码器网络,在解码器中进行上采样操作,以扩大特征地图的空间分辨率。此外,跳过范例或横向连接通常用于连接较低层与较高层特征地图,同时绕过中间层。检测层使用融合后的特征映射。组合特征映射的典型操作包括求和、生成、连接和全局池化.
4.1.2.挑战2:小目标的有限上下文信息
通常,小对象的分辨率较低,因此很难识别低分辨率对象。由于小对象本身包含的信息有限,因此上下文信息在小对象检测中起着关键作用(Torralba、Murphy、Freeman和Rubin,2003;Oliva和Torralba,2007;Divvala、Hoiem、Hays、Efros和Hebert,2009;Palmer,1975)。上下文信息已用于从“全局”图像级别到“局部”图像级别的对象识别。全局图像级别考虑来自整个图像的图像统计信息,而局部图像级别考虑来自对象相邻区域的上下文信息。上下文特征可分为三种类型(Divvala等人,2009年):
1) 局部像素上下文:对象周围的面片或像素,如边缘、颜色、纹理等。可以通过增加对象检测网络中检测窗口的大小来捕获局部像素上下文。
2) 语义上下文:在某些周围场景(如事件、活动或场景类别)中识别对象的概率。
3) 空间上下文:图像中其他对象的空间位置,例如,在某些位置找到物体关于其他物体的可能性.例如,在人脸检测系统中,受试者的肩膀和脖子总是靠近他们的脸。
解决方案:在检测网络中加入上下文信息。局部像素上下文通常通过放大过滤器大小来添加,以捕获对象周围的额外信息。语义上下文通常是通过从图像中提取更深层次的特征来添加的,例如在反卷积层或递归神经网络(RNN)中.
4.1.3.挑战3:小物体的分类不平衡
类不平衡是指类之间的数据分布不均匀。有两种类型的阶级失衡。一个是前景和背景示例的不平衡。在目标检测中,通过对整个图像进行密集扫描,使用区域前向网络生成包含目标的候选区域。锚定是在整个输入图像上密集平铺的预定义矩形框。锚定的比例和比率是根据训练数据集中目标对象的大小预定义的。为了检测小对象,与检测大对象相比,每幅图像生成的锚定数量有所增加。只有在联合体(IoU)上与地面真值边界框具有高交点的锚点被标记为正面示例。由于大多数锚与地面真相边界框的重叠程度较低或没有重叠,因此它们被视为负面示例。当密集生成的锚与图像中位置稀疏的真实对象匹配时,正面示例只占很小的一部分,导致高等级不平衡,例如等级比从100:1到1000:1。基于锚的目标检测方法有几个缺点。首先,由于基础真值边界框的稀疏性以及基础真值和锚之间的IoU匹配策略,负面示例高度支配正面示例,这导致模型偏向负面类。第二,密集滑动窗口策略具有较高的时间复杂度(O(h2w2)),其中h是锚的高度,w是锚的宽度,这使得训练速度较慢。
解决方案:在培训中平衡正面和负面的例子。主要有两种策略:1)基于数据的策略和2)基于损失函数的策略。基于数据的策略是改变前景和背景示例编号,使正面和负面类的示例具有大致相同的权重。硬采样和软采样是两种常用的方法。硬采样选择样本子集,而软采样为示例指定不同的权重。例如,随机抽样通常用于随机选择符合一定比例的样本。另一种抽样策略是对损失较大的硬示例进行更多抽样。例如,可以先训练机器学习模型,然后将误报视为硬示例,这些示例在第二轮训练中权重很大。最近提出的(OHEM)方法(Shrivastava、Gupta和Girshick,2016)对计算出的感兴趣区域(RoI)执行一次正向传递,并计算所有RoI的损失。然后,根据损失函数值对示例进行排序,并选择损失最大的示例用于下一轮训练,因为当前训练的网络模型对其表现最差。(Pang,Chen,et al.,2019)还提出了一种IoU平衡抽样技术,以便从困难案例中抽取更多训练样本。在软抽样方面,(曹,陈,罗和林,2020)提出了一种基于样本重要性选择样本的技术,其中正面样本的重要性通过其IoU分数和基本真相边界框来衡量,通过考虑局部区域和全局区域的性质,计算了反例的重要性。基于损失函数的策略将重新加权损失函数中不平衡类的示例,以平衡前景和背景示例。例如,AP损耗(Chen等人,2019年)使用平均精度损耗来重新计算示例的重量。Loss博士(钱、陈、李和金,2019)根据前景示例的分布对背景示例的分布重新加权.
4.1.4.挑战4:小目标的正样本不足
大多数用于目标检测的深层神经网络模型都是使用不同尺度的目标进行训练的。它们通常在大型对象上表现良好,但在小型对象上表现较差。原因可能包括生成的小规模锚箱数量不足,无法匹配小对象,以及无法成功匹配地面真相的示例数量不足。锚是深度神经网络中某些中间层的特征映射中的区域,这些区域将被投影回原始图像。很难为小对象生成锚。此外,锚需要与地面真相边界框相匹配。下面是一种广泛使用的匹配方法。如果锚相对于地面真实边界框具有较高的IoU分数,例如大于0.9,则将其标记为正面示例。此外,对于每个地面真相框,具有最高IoU分数的锚也被标记为一个积极的例子。因此,小物体通常很少有锚与地面真值结合盒匹配,即很少有正面例子。
解决方案:使用可以为小对象生成更多锚并将更多锚与小对象匹配的方法。现有技术包括:1)多尺度机构。由小型、中型和大型对象的独立分支组成的多尺度体系结构可以生成不同尺度的锚。2) 匹配策略。自适应设置锚定比例和比率,以帮助更多锚定匹配小对象的地面真实情况。3) 增加小物体的正面例子。在区域建议阶段,通过允许锚相互重叠来生成更多锚。
4.2在通用目标检测研究中发展的用于小目标检测的深度学习技术
在这一部分中,我们总结了在一般目标检测研究中开发的对小目标检测有效的深度学习技术。
4.2.1.1技术1:改进小物体的特征图
低层次特征对定位很重要,而高层次特征对分类很重要。在多个深度神经网络的检测层使用低层和高层特征映射的组合,提高了小目标检测的结果。使用自下而上的方式,一组网络架构合并了不同层的功能图(Fu等人,2017;Lin,Milan,Shen和Reid,2017;Kong等人,2017)。孔、孙、谭、刘和黄(2018)提出了一种非线性特征映射变换通过同时考虑全球和本地信息。非线性变换的参数是可学习的,并可在不同层之间共享。将变换应用于不同层中的特征地图,每个变换层生成检测结果。(Yang,Liu,Yan和Li,2019)在“编码器-解码器”体系结构中使用了反褶积层,此外还结合了卷积层和反褶积层的特征图。(Bell,Law rence,Zitnick,Bala&Girshick,2016)使用跳过连接直接将低级特征映射添加到高级特征映射。特征来自具有不同感受野(conv3、conv4和conv5)的卷积层。这些特征被标准化并连接到检测模块中。(Zagoruyko等人,2016年)在标准化后还连接了不同层(conv3、conv4、conv5)的特征。在(Cao等人,2018年)中,大量实验结果表明,结合低水平和高水平特征可以提高小对象的检测精度。(Jeong,Park和Kwak,2017)通过同时执行合并和反褶积来连接特征,其中合并减少了低级别特征地图的大小,以将其与高级别特征地图相结合,反褶积增加了高级别特征地图,以将其与低级别特征地图相结合。(Yu等人,2018)通过使用迭代深度聚合(IDA)和高级深度聚合(HDA)融合语义和空间信息。IDA非线性地提供两种类型的特征,而HDA将几个CNN特征合并到一个树状结构中。(Zhang,Qiao,et al.,2018)使用额外的分段模块添加更多语义信息。(Li&Zhou,2017)融合了来自多个较低层的特征,其中低层特征图通过最大池进行下采样,高层特征图通过双线性插值调整大小。类似地,(孔、姚、陈和孙,2016)在低层特征上应用了最大池,在高层特征上应用了反褶积运算。然后将这些特征映射连接在一起,形成所谓的超特征映射.
一些网络架构使用自顶向下和自底向上连接来组合功能。((Shrivastava、Sukthankar、Malik和Gupta,2016)添加了自顶向下的模块以及横向连接。自顶向下的模块可以生成具有更多语义和上下文信息的功能。横向连接可以通过传输较低级别的功能来丰富自顶向下的功能。(Kong等人,2017)使用反向连接将高级语义信息从后面的网络层添加回前面的层。(Ghiasi,Lin和Le,2019)提出了一种搜索方法来自动搜索良好的特征金字塔结构,这可能会取代手动设计。递归神经网络(RNN)担任控制器,将任意两个输入功能与求和或池运算合并。(庞、王、安沃、汗和邵,2019)在两个层次上应用了特征金字塔融合机制。对于全局信息,它构建了一个图像金字塔,并将来自图像金字塔四个层次的特征与标准SSD框架中的原始特征相结合。对于局部空间信息,将来自前一层和当前层的特征融合在一起.
4.2.2 技巧2:合并小对象的上下文信息
小对象的上下文信息可以分为局部联系和语义上下文信息。通过更大的边界框和建议框,可以在深层神经网络中包含更多的局部上下文信息。(Cai,Fan,Feris&Vasconcelos,2016)添加了额外的局部上下文,边界框是对象区域的1.5倍,这有助于包含更多小对象的周围环境。额外的上下文信息与检测层的对象特征相结合。(Zagoruyko等人,2016年)通过增加区域提案箱的大小,采用四种比例(1倍、1.5倍、2倍和4倍)来整合当地背景信息。来自四个区域的输出在输入检测层和分类层之前与ROI池合并并连接.
为了包含更多语义上下文信息,(Fu等人,2017年)使用了带有“跳过连接”的反卷积层,在小目标检测得到更好的结果.反卷积层被设计为比卷积层浅得多,并使用元素乘积,而不是简单地将反卷积层叠加在卷积层之上。类似地,(Cai等人,2016年)也使用反卷积层来提高特征图的分辨率。(Bell等人,2016年)使用四个递归神经网络(RNNs)捕获输入图像的全局信息。RNN在对象周围添加语义上下文信息,1x1卷积将所有信息组合在一起。此外,(Zhang、Wen、Bian、Lei和Li,2018)将更高级别的功能地图传递给了更低级别的功能.
4.2.3技巧3:纠正小对象的前景和背景类不平衡
改善前景和背景类不平衡的技术可分为两部分,即基于数据的方法和基于损失函数的方法。在基于数据的方法中,(Cai等人,2016年)使用自举抽样(bootstrap sampling)解决了阶级不平衡问题,该抽样基于负面例子的损失值进行抽样。(Zhang,Wen,et al.,2018)使用两步回归方法平衡前景和背景测试样本。一些简单的负片被去掉,使正片和负片的比率大约相等。(Kong等人,2017年)在过滤出没有对象的边界框之前实现了对象性。在基于损失函数的方法中,(Galleguillos&Belongie,2010)使用了一个损失函数,该函数赋予了硬负面示例更大的权重。
4.2.4技巧4:增加小目标的训练样本
已经开发了许多技术来增加小对象的训练示例数量。它们包括用于多尺度学习、尺度变换和锚箱自适应匹配的神经网络体系结构。已经设计了几种用于多尺度学习的神经网络结构,即针对不同大小的对象训练检测器网络,以解决分类器训练中小对象示例不足的问题。(Singh、Najibi和Davis,2018)展示了一种训练方案的有效性,该方案使用不同比例和姿势的物体,由于训练示例的数量和种类增加,提高了对小物体的检测性能。对小目标进行上采样,并将其送入卷积网络进行检测。在训练过程中,只有特征映射包含一定范围内的目标对象的图层才会被激活,这样小对象的训练效果与中、大对象的训练效果一样好。(Najibi、Singh和Davis,2019b)提出了一个多尺度网络来预测最可能包含小对象的区域,并放弃了不可能包含小对象的区域。该网络首先预测小对象的二值分割图,目的是获得大的小对象召回率。训练中只使用可能包含小物体的区域。(Yang,Choi和Lin,2016)提出了一种称为比例相关池(scale dependent pooling)的技术,用于根据对象比例为对象分配适当的特征贴图。这种方法基于这样一种想法,即小对象在较低级别的特征图中主要具有强激活。该方法将小对象的早期特征贴图与大对象的后期特征贴图合并在一起。其他几项工作在不同的卷积层之后增加了预测和检测层,即使用不同的特征图进行预测,并扩大了区域大小以包含更多的本地上下文信息(Cai等人,2016;Li&Zhou,2017;Chen,Liu,Tuzel,&Xiao,2016)。尺度变换是用于增加小对象训练示例数量的另一种技术(Kim、Kang和Kim,2018)。将不同尺度的对象映射到单个尺度不变空间,以增加示例数量。从原始输入图像的不同尺度学习映射,得到归一化的面片。因此,可以在训练中使用包含所有比例对象的图像。(Singh&Davis,2018a)提出了一种称为图像金字塔尺度标准化(SNIP)的新型训练方案,该方案可以最小化训练过程中的尺度变化.
代替预定义的锚框,机器学习已用于寻找锚框的完美比例和比率,并执行锚箱的自适应匹配(Redmon&Farhadi,2017)。例如,可以根据其比例将地面真实值边界框分组为簇,然后将锚定框与相似比例的地面真实值边界框匹配。
4.3. 人脸检测研究中发展起来的小目标检测技术
人脸检测得到了广泛的研究并取得了巨大的成功。人脸具有不同的面部特征,即鼻子、眼睛、嘴巴及其相对位置,这使得人脸检测不同于一般的对象检测。但是,当面部尺寸非常小(例如小于16x16像素)且特征无法区分时,这仍然是一个挑战。许多小人脸检测技术已经被开发出来。最先进的算法如表1所示。

4.3.1.技术1:改进小脸特征图组合
多个特征图的技术之一是用于集成低层、中层和高层特征的跳过连接。(Tian等人,2018)提出了一种迭代特征图生成方案,该方案生成了六种不同尺度的特征,并将主干网络中的所有特征图反馈到网络的开头,以提取更多的小对象语义信息。(Samangouei、Chellappa、Najibi和Davis,2018)将组合的较低层和较高层特征提供给基于ROI的块规范化层。(Tian等人,2018)使用跳过连接合并了四个特征图,以生成四个新的特征图进行检测。具体而言,输入特征通过元素乘法与下一级特征融合。此外,将融合后的特征加入到原始输入特征中,形成最终的特征,从而有效地检测出复杂的微小人脸。(Zhu、Zheng、Luu和Savvides,2017)通过首先将较低级别特征下采样到较高级别特征的大小,然后将其与L2归一化连接,将较低级别特征与较高级别特征相结合。(Roo,Li,Zhu和Zhang,2019)使用双线性上采样策略将低层特征与相邻特征相结合。(Yoo,Dan和Yun,2019)设计了一种通过重复通过网络的特征地图生成方案。
4.3.2.技术2:加入小人脸的上下文信息
人脸检测(Bai、Zhang、Ding和Ghanem.,2018)表明,添加上下文信息可以显著提高小人脸的性能。但是,过多的上下文信息也会由于过度拟合而影响小面的性能。有些方法通过扩大脸部周围的感受区来增加上下文信息。(Najibi、Samangouei、Chellappa和Davis,2017)采用了较大的滤波器尺寸,例如卷积网络中的5x5和7x7滤波器,而不是3x3滤波器。(Wang,Yuan和Network,2017)采用特征融合方法,将较低级别的特征与较高级别的特征结合在一起,形成一个聚合连接模块。在这个模块中,较低的特征映射首先通过一个类似于inception的网络来增加语义信息,然后将较低的特征映射与较高的特征映射连接起来。(Samangouei等人,2018年)在每个边界框周围添加了上下文信息。在(Tang等人,2018年)中,整合了来自身体和肩部的额外上下文信息,并使用半监督方法为其他身体部位生成标签。(Tian等人,2018)使用分段分支添加额外的上下文和语义信息,无需额外的注释,并且分段分支共享相同的检测感受域,这使得分段分支成为更具辨别力特征的额外来源。(Li、Tang、Han、Liu和He,2019)使用(Huang等人,2017)的密集块结构来整合提取的上下文特征。(Zhu等人,2017)整合身体信息以减少误报。身体特征是通过额外的RoI池操作获得的来扩大感受野.在分类和边界盒回归中使用了组合的面部和身体特征.
4.3.3.技术3:纠正小人脸的前景和背景类不平衡。
对于小人脸检测,检测器网络通常在图像上放置大量小锚,这通常会产生大量负锚和极少数正锚,导致较高的误报率。处理类不平衡有两种主要方法。a) 过滤锚。(Zhang等人,2017年)使用了一个最大输出背景标签,该标签预测了背景标签的几个分数,并选择了最大值作为最终分数。(Chi等人,2019年)在较低的层上使用两步分类法来过滤小脸的假阳性,这有助于平衡正面和负面示例,以改进分类结果。b) 取样。(Zhang et al.,2017)采用硬负挖掘,使正负比最大为3:1。(纳吉比、辛格和戴维斯,2019a)也使用硬底片采矿。如果与地面真实值边界框的重叠大于0.5,则锚定标记为正。(Li等人,2019)提出了一种平衡的数据锚抽样策略,以同等概率选择大尺寸和小尺寸锚。(Tang等人,2018)提出了一种棱锥盒,该棱锥盒在阳性和阴性样本上均采用最大输入输出技术,以降低小对象的假阳性率。(Wang,Li,Ji,&Wang,2017)应用在线硬示例挖掘(OHEM),根据损失对示例进行排序,并选择损失最高的前示例作为硬示例。此外,在训练过程中,他们对每个小批次的正面硬示例和负面硬示例采用1:1的比例。
4.3.4.4技术4:增加小脸的训练示例
重要的是确保小对象有足够的锚来匹配,否则小对象无法很好地训练,并且训练模型的召回率将很低。有三种主要技术可以增加小脸孔的训练示例。a) 匹配策略。(Zhu、Tao、Luu和Savvides 2018)发现,小脸和小锚的平均IoU远低于大脸。为了设计与小规模物体匹配的锚,提出了一种新的匹配分数来考虑人脸尺度和锚定步长,使得小脸部尺度也能获得高IOU得分。此外,在训练过程中,人脸被随机移动以匹配更多的锚。(Chi等人,2019年)确定了锚定比率和感受野之间的不匹配,并提出了初期风格的特征图,以增加特征图比例的多样性,减少面部和锚定之间的不匹配.
b) 增加锚。(Zhang等人,2017年)添加了额外的卷积层,以便为小对象生成更多的锚.它还降低了下部锚关联层上的步幅大小,以增加可能与更多小比例对象匹配的锚数量。此外,提出了一种两阶段锚点匹配策略,以确保每个小对象都有足够的锚点进行匹配。(Zhu等人,2018)通过减少步幅和面部与锚定中心之间的距离,以及增加额外的移位锚定,增加了锚定的数量。此外,对于最高IoU分数仍低于匹配阈值的硬面孔,选择分数最高的前几个锚定作为正面示例。(Luo等人,2019年)增加了锚的范围,以便更多小尺寸锚可以与小面匹配。
c) 多尺度训练。(Wang、Chen、Huang、Yao和Liu,2017)将输入图像调整为不同大小,以生成不同大小的对象,小对象可以调整为更大的对象,以匹配更多的锚定框。(Najibi等人,2017年)设计了一个具有三个不同卷积分支的多尺度网络,用于检测不同尺度的人脸:分别是小型、中型和大型人脸。利用conv4和conv5的元素和特征检测小人脸。从conv5中直接检测中等人脸。conv5后,从max pooling检测到大面。(Hu&Ramanan,2017)使用了一个图像pyra mid,其中输入图像的比例为原始分辨率的0.5、1和2。然后应用两种类型的特征映射来捕获不同比例的人脸。
4.4. 航空影像中的目标检测技术
对于航空图像中的目标检测,主要有四种方法:(i)基于模板匹配的方法,(ii)基于知识的方法,(iii)基于OBIA的方法,(iv)基于机器学习的方法(Cheng&Han,2016)。近年来,基于深度学习的方法取得了最好的效果。通常,在大型图像数据集(如ImageNet和COCO数据集)上预训练的CNN会在航空图像上进行微调。此外,针对航空图像中目标的独特属性,如多尺度、多角度等,提出了新的深度神经网络,以获得更好的性能。例如,(Dong,Liu和Xu,2018)提出了旋转不变模型,以在遥感图像上实现良好的性能。此外,提出了弱监督学习方法(Peng等人,2018),以无监督的方式学习高层特征,以捕获遥感图像中物体的结构信息。
4.4.1.1技术1:处理航空影像对象的方向
航空影像中的对象可以具有任意方向或旋转。设计了基于深度神经网络的检测器来解决这个问题。旋转不变CNN(RICNN)(Cheng,Zhou,&Han,2016)在基本CNN架构中创建了一个新的旋转不变层。引入旋转不变量和Fisher判别CNN(RIFD)(chen,2018)提出了一种基于CNN多尺度特征的旋转不变正则化和fisher判别正则化方法。旋转不变正则化器将旋转前后训练样本的CNN特征表示映射为相似,而fisher判别正则化器将CNN特征约束为类内示例相似,但不同类中的示例不同。最近,在单级目标检测器中提出了锚旋转方法,以实现旋转不变性(Yang等人,2018)。为了提高航空图像的检测性能,提出了一种特征细化技术,通过特征插值将包围盒的位置信息编码到相应的特征点上,以改进特征重构和对齐。R-Net在(Yang等人,2018年)中提出了一个生成可旋转区域提案的网络。
4.4.2.技术2:结合航空影像目标的上下文信息。
通过组合特征图和扩展的卷积,探测网络中包含了更多小目标的上下文信息。来自多个卷积层的特征映射可以连接起来形成一个新的特征映射。扩展卷积可以添加到CNN模型中,以提高小尺度目标检测的性能。
4.4.3.技术3:校正航空图像对象的前景和背景类不平衡
基于Faster RCNN提出了IoU自适应可变形R-CNN(Yan等人,2019),以解决对象检测器中分类器训练中的类不平衡问题。通过分析IoU在网络模型的不同部分所扮演的不同角色,提出了一种IoU引导的检测框架,以减少训练过程中小目标信息的丢失。此外,还设计了一种基于IoU的加权损失来学习正ROI的IoU信息,以提高检测精度。最后,提出了类纵横比约束非最大抑制(CARC-NMS)方法来提高检测精度。
4.4.4.技术4:增加航空图像对象的训练示例
已提出多尺度网络模型,用于检测航空图像中各种大小的对象,例如(Wu、Hong、Ghamisi、Li和Tao,2018)中的多尺度和旋转不敏感卷积通道特征(MsRi CCF)。MsRi CCF通过集成稳健的低层特征生成、分类器生成和离群点去除以及幂律检测,提出了用于地理空间目标检测的MsRi CCF.
4.5. 小目标检测的实例分割方法
与前几节中介绍的流行的基于边界盒的对象检测器不同,深度CNN(例如分割)也被应用于对象检测。分割方法的主要缺点是逐像素标记,这非常耗时,并且需要大量计算和内存。对于小对象检测,对象的每个像素都很重要,使用像素信息可以产生良好的结果。FCN(Long,Shelhamer和Darrell,2015)是最早使用CNN进行语义切分的方法之一。FCN采用CNN,没有完全连接的层,这允许输入图像具有任意大小。它使用池层来减少计算时间并增加接收字段的大小。基于FCN,U-Net(Ronneberger、Fischer和Brox,2015)提出了一种编码器-解码器体系结构,以解决确定适当数量的池层的问题。它有一个U形结构,以平衡良好的定位精度和有效的上下文信息之间的权衡。在编码器中,它使用池层来逐渐减小层大小,而在解码器阶段,它使用卷积来逐渐增大层大小。此外,U-Net使用从编码器到解码器的快捷连接来帮助解码器恢复细粒度信息。在接收场和定位精度之间进行权衡,接收场越大,定位精度越低。然而,当接收场太小时,定位精度也可能由于缺乏上下文信息而降低。功能金字塔网络(FPN)结合了FCN和更快的R-CNN。在更快的R-CNN生成的两个预测之上:(i)边界框定位和(ii)边界框识别,FPNs添加了第三个输出,(iii)用于分割的实例掩码预测。FPNs还使用了一些新技术,如新的ROI对齐层、多任务培训和更好的主干网络,以进一步改进。对于小目标检测,也提出了一些基于分割方法的其他技术。为了在信息中包含更多的上下文,提出了带有反褶积胶囊的胶囊网络,以扩展网络架构中的原始层(LaLonde&Bagci,2018)。分段可以使用自下而上和自上而下的网络体系结构来组合不同层的特征(Ronneberger等人,2015年),或者使用金字塔池层在多个尺度上分段对象,如DeepLab(Chen等人,2018年)。为了增加小对象的训练示例,可以通过联合使用无监督和超级监督学习,结合不同模型的特征,形成多尺度表示来学习更稳健的嵌入(Lin,Milan,et al.,2017)。中的概念掩码(王林,沈,张和科恩,2018)使用半监督学习方法训练具有图像级la bels的深层神经网络。然后,对结果进行细化和扩展,以预测注意图。最后,训练了一个注意力驱动的班级分割网络.
5.用于小目标检测的深度学习方法的性能评估
在本节中,介绍了在广泛使用的公共基准数据集上具有代表性的最新对象检测方法的性能。重点是小目标检测。
5.1. 数据集
我们使用了来自三个不同领域的数据集:通用目标检测、人脸检测和航空图像中的目标检测。通用目标检测数据集中的图像大多是在日常生活和室内环境下采集的。对象通常为刚性形状。检测的困难通常来自照明和背景杂波。相比之下,人脸有一个共同的结构,包含几个固定部分的区域,如眼睛、鼻子、嘴巴等,并且这些部分之间的关系是已知的。就航空图像而言,它们是在多种不同的条件下收集的,例如安装在飞机、直升机或无人驾驶飞机(UAS)下面的摄像头,这导致了物体的直下视图,与一般物体检测或人脸检测数据集中的图像有很大的不同。我们在图2中展示了三个数据集的示例。

- 通用对象检测数据集。实验中使用了来自Microsoft公共对象上下文(COCO)数据集(Lin et al.,2014)和SUN数据集(Xiao、Hays、Ehinger、Oliva和Torralba,2010)的图像组合。COCO由80个类别的82 K训练和40 K验证图像组成。COCO是对象检测中广泛使用的数据集,也是一个相对困难的数据集,因为与其他数据集相比,对象的大小相对较小。在我们的实验中,我们从COCO中选择了十个小物体类别,其中最大的物理尺寸小于30厘米。所选对象类别包括鼠标、电话、开关、插座、时钟、卫生纸、化妆盒、水龙头、盘子和罐子。然后,我们使用COCO和SUN数据集中的地面真值边界框来过滤大对象,以创建包含具有小边界框的小对象的数据集。表2显示了我们实验中使用的这个小对象数据集的统计信息。它包含4952个图像中的8393个对象实例.鼠标类别的对象实例数最多,1739张图中2173个实例.纸巾盒类别具有最少的实例:100个图像中有103个实例。数据集中的对象实例很小。所有对象实例的相对面积中值为0.08%到0.58%。作为比较,PASCAL VOC数据集中对象相对面积的中位数为1.38%至46.40%。这个数据集在两个方面具有挑战性。首先,由于尺寸较小,用于区分小对象和背景杂波的外观线索要少得多。第二,图像中小对象的边界框假设数量远大于VOC中大对象的边界框假设数量.
2)人脸检测数据集。我们在实验中使用了更宽的人脸数据集(Yang、Luo、Loy和Tang,2016)。该数据集包含32203个图像,其中包含393703个带注释的面,其中158989个在序列集中,39496个在验证集中,其余在测试集中。验证和测试集分为“容易”、“中等”和“困难”子集。这是最具挑战性的公共人脸数据集之一,主要是由于人脸尺度和遮挡的多样性。我们在更广泛数据集的训练集上训练所有模型,并在验证集和测试集上评估其性能。此外,创建了小对象的子集,其中包含小于50x50像素的对象。3) 航空图像数据集。我们的实验使用了航空图像中目标检测的大规模数据集(DOTA;Xia等人,2018)。它是最大的航空图像注记对象数据集之一,包含2806幅高分辨率航空图像和188282个不同比例和形状的对象实例。它有15个对象类别,包括船舶、飞机、储罐、棒球钻石、网球场、篮球场、地面田径场、港口、桥梁、大型车辆、小型车辆、直升机、环岛和足球场。DOTA数据集包含具有挑战性和复杂的场景。在我们的实验中,我们使用平均精度(mAP)作为我们的测量指标。mAP的定义是在PASCAL VOC挑战赛中首次提出的(Everingham、Van Gool、Williams、Winn和Zisserman,2010)。准确度是正确预测的百分比,召回率是所有可能的积极因素中真正积极因素的百分比。给出了一个准确率召回公式,ap定义如下:

其中p(r)是召回值r的预测值。
5.2. 实验结果
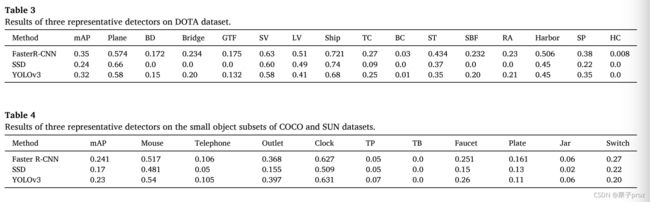
我们用来生成本文结果的软件可以在GitHub上找到(Liu,2020)。表3显示了DOTA数据集上3种最先进的对象检测器(更快的R-CNN、SSD和YOLOv3)的结果。更快的R-CNN是一种两级目标探测器,其性能优于其他两种一级目标探测器。更快的R-CNN在mAP上达到35%,分别比YOLOv3和SSD高3%和11%。在单级目标探测器中,YOLOv3的性能比SSD好得多。一个原因是YOLOv3中的低层和高层特征融合以及多尺度训练技术对于小目标检测是有效的。表4显示了在COCO和SUN数据集的小对象子集上更快的R-CNN、SSD和YOLOv3的结果。他们的总地图很低。同样,更快的R-CNN表现最好,mAP为24.1%。YOLOv3比速度更快的R-CNN稍差,而SSD则更糟糕。表5显示了在宽面数据集上更快的R-CNN、SSD和YOLOv3以及SSH的结果。SSH是专门为人脸检测而设计的。总体而言,更快的R-CNN表现最好,mAP为33.6%,其次是YOLOv3,mAP为31.5%。尽管SSH是为人脸检测而设计的,但它在小人脸上的表现并不好,比更快的R-CNN和YOLOv3差。SSH实现了30.8%的mAP。SSD表现不佳,mAP为24.6%。在预测结果时,这些方法的执行时间以每秒帧数(FPS)来衡量。所有实验都在戴尔Alienware计算机上运行,该计算机配备GTX 980 M GPU和运行Ubuntu的8GB内存。对于大小为512×512像素的较宽人脸数据集的图像,较快的R-CNN的运行时间为4fps,这是最慢的,因为它采用了两级对象检测结构。SSH和SSD的运行时间相似,分别为14和18fps。约洛夫3跑得最快,每秒40帧.

6未来研究方向
与基于锚的方法不同,最近提出了几种无锚算法,并取得了最新的成果。这些方法摆脱了手工设计的锚,可以表示任何比例和比率的边界框。(Duan等人,2019)将边界框表示为一对中心点和角点。(Tychsen-Smith&Peterson,2017)将目标检测任务表述为稀疏边界框概率分布。它首先估计了四个角落的位置分布。每个角点的特征由最近邻采样和边界框宽度和高度构成。在其深层神经网络中,反褶积层用于恢复在汇集层中丢失的信息。(Law&Deng,2018)将目标检测问题定义为检测和分组具有额外嵌入信息的角点对。网络作为主干网络,预测了左上角和右下角的热图。利用嵌入向量对属于同一对象的角点进行进一步分组,预测角点之间的相似性。此外,还提出了角点池层,用于将角点的先验位置知识结合到特征提取过程中。(Wang,Chen,et al.,2017)使用中心点和四个角(左上角、右上角、左下角和右下角)表示边界框。它将特征地图划分为网格单元,并对每个单元预测单元中中心点和角点的概率、x偏移和y偏移以及点链接的概率。点链接包含两部分:特殊索引(点链接到单元的概率)和点索引(角点和中心点之间的链接概率)。与其他估计边界框点的方法不同,(Zhou、Zhuo和Krahenbuhl,P,2019)使用完全基于外观的算法估计对象上的四个极值点。它预测了五个特征图:一个用于中心点,四个用于角点。极值点是通过maxpooling生成的。根据对四个角的任意组合的预测,计算中心,并在中心的热图上进行验证。具有已验证中心点的角点中心表示检测到的对象。(Duan等人,2019年)改进了信息网络(Law&Deng,2018年)。提出了用三个点(两个角点和一个中心点)表示边界盒、中心池和级联角池来提取强特征.
以上论文由文献翻译工具整理,有很多翻译不准确的地方.