try - catch 语句真的会影响性能吗?
不知道从何时起,传出了这么一句话:Java中使用try catch 会严重影响性能。
然而,事实真的如此么?我们对try catch 应该畏之如猛虎么?
一、JVM 异常处理逻辑
- Java 程序中显式抛出异常由athrow指令支持,除了通过 throw 主动抛出异常外,JVM规范中还规定了许多运行时异常会在检测到异常状况时自动抛出(效果等同athrow), 例如除数为0时就会自动抛出异常,以及大名鼎鼎的 NullPointerException 。
- 还需要注意的是,JVM 中 异常处理的catch语句不再由字节码指令来实现,现在的JVM通过异常表(Exception table 方法体中能找到其内容)来完成 catch 语句;很多人说try catch 影响性能可能就是因为认识还停留于上古时代。[ 很早之前通过 jsr和 ret指令来完成,它们在很早之前的版本里就被舍弃了]。
- 我们编写如下的类,add 方法中计算数值,并捕获异常。
public class TestClass {
private static int len = 779;
public int add(int x){
try {
// 若运行时检测到 x = 0,那么 jvm会自动抛出异常,
// (可以理解成由jvm自己负责 athrow 指令调用)
x = 100/x;
} catch (Exception e) {
x = 100;
}
return x;
}
}
-
使用javap 工具查看上述类的编译后的class文件
# 编译 javac TestClass.java # 使用javap 查看 add 方法被编译后的机器指令 javap -verbose TestClass.class
忽略常量池等其他信息,下边贴出add 方法编译后的 机器指令集:
public int add(int);
descriptor: (I)I
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=2
0: bipush 100 // 加载参数100
2: iload_1 // 将一个int型变量推至栈顶
3: idiv // 相除
4: istore_1 // 除的结果值压入本地变量
5: goto 11 // 跳转到指令:11
8: astore_2 // 将引用类型值压入本地变量
9: bipush 100 // 将单字节常量推送栈顶<这里与数值100有关,可以尝试修改100后的编译结果:iconst、bipush、ldc>
10: istore_1 // 将int类型值压入本地变量
11: iload_1 // int 型变量推栈顶
12: ireturn // 返回
// 注意看 from 和 to 以及 targer,然后对照着去看上述指令
Exception table:
from to target type
0 5 8 Class java/lang/Exception
LineNumberTable:
line 6: 0
line 9: 5
line 7: 8
line 8: 9
line 10: 11
StackMapTable: number_of_entries = 2
frame_type = 72 /* same_locals_1_stack_item */
stack = [ class java/lang/Exception ]
frame_type = 2 /* same */
再来看 Exception table:

from=0, to=5。 指令 0~5 对应的就是 try 语句包含的内容,而targer = 8 正好对应 catch 语句块内部操作。
- 个人理解,from 和 to 相当于划分区间,只要在这个区间内抛出了type 所对应的,“java/lang/Exception” 异常(主动athrow 或者 由jvm运行时检测到异常自动抛出),那么就跳转到target 所代表的第 8 行。
若执行过程中,没有异常,直接从第5条指令跳转到第11条指令后返回,由此可见未发生异常时,所谓的性能损耗几乎不存在;
- 如果硬是要说的话,用了try catch 编译后指令篇幅变长了;goto 语句跳转会耗费性能,当你写个数百行代码的方法的时候,编译出来成百上千条指令,这时候这句goto的带来的影响显得微乎其微。
如图所示为去掉try catch 后的指令篇幅,几乎等同上述指令的前五条。

- 综上所述:“Java中使用try catch 会严重影响性能” 是民间说法,它并不成立。如果不信,接着看下面的测试吧。
二、关于JVM的编译优化
其实写出测试用例并不是很难,这里我们需要重点考虑的是编译器的自动优化,是否会因此得到不同的测试结果?
本节会粗略的介绍一些jvm编译器相关的概念,讲它只为更精确的测试结果,通过它我们可以窥探 try catch 是否会影响JVM的编译优化。
- 前端编译与优化:我们最常见的前端编译器是 javac,它的优化更偏向于代码结构上的优化,它主要是为了提高程序员的编码效率,不怎么关注执行效率优化;例如,数据流和控制流分析、解语法糖等等。
- 后端编译与优化:后端编译包括 “即时编译[JIT]” 和 “提前编译[AOT]”,区别于前端编译器,它们最终作用体现于运行期,致力于优化从字节码生成本地机器码的过程(它们优化的是代码的执行效率)。
1. 分层编译
JVM 自己根据宿主机决定自己的运行模式, “JVM 运行模式”;[客户端模式-Client、服务端模式-Server],它们代表的是两个不同的即时编译器,C1编译器 [Client Compiler] 和 C2编译器 [Server Compiler]。
分层编译分为:“解释模式”、“编译模式”、“混合模式”;
- 解释模式下运行时,编译器不介入工作;
- 编译模式模式下运行,会使用即时编译器优化热点代码,有可选的即时编译器[C1 或 C2];
- 混合模式为:解释模式和编译模式搭配使用。
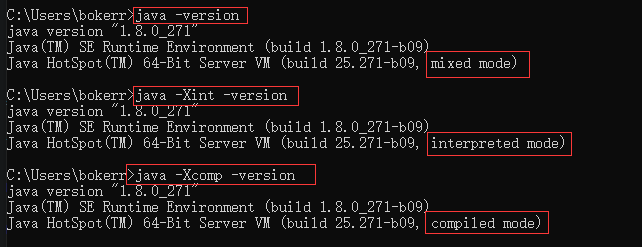
如图,我的环境里JVM 运行于 Server 模式,如果使用即时编译,那么就是使用的:C2 即时编译器。
2. 即时编译器
了解如下的几个概念:
1. 解释模式
它不使用即时编译器进行后端优化
- 强制虚拟机运行于 “解释模式” -Xint
- 禁用后台编译 -XX:-BackgroundCompilation
2. 编译模式
即时编译器会在运行时,对生成的本地机器码进行优化,其中重点关照热点代码。
# 强制虚拟机运行于 "编译模式"
-Xcomp
# 方法调用次数计数器阈值,它是基于计数器热点代码探测依据[Client模式=1500,Server模式=10000]
-XX:CompileThreshold=10
# 关闭方法调用次数热度衰减,使用方法调用计数的绝对值,它搭配上一配置项使用
-XX:-UseCounterDecay
# 除了热点方法,还有热点回边代码[循环],热点回边代码的阈值计算参考如下:
-XX:BackEdgeThreshold = 方法计数器阈值[-XX:CompileThreshold] * OSR比率[-XX:OnStackReplacePercentage]
# OSR比率默认值:Client模式=933,Server模式=140
-XX:OnStackReplacePercentag=100
- 所谓 “即时”,它是在运行过程中发生的,所以它的缺点也也明显:在运行期间需要耗费资源去做性能分析,也不太适合在运行期间去大刀阔斧的去做一些耗费资源的重负载优化操作。
3. 提前编译器:jaotc
- 它是后端编译的另一个主角,它有两个发展路线,基于Graal [新时代的主角] 编译器开发,因为本文用的是 C2 编译器,所以只对它做一个了解;
- 第一条路线:与传统的C、C++编译做的事情类似,在程序运行之前就把程序代码编译成机器码;好处是够快,不占用运行时系统资源,缺点是"启动过程" 会很缓慢;
- 第二条路线:已知即时编译运行时做性能统计分析占用资源,那么,我们可以把其中一些耗费资源的编译工作,放到提前编译阶段来完成啊,最后在运行时即时编译器再去使用,那么可以大大节省即时编译的开销;这个分支可以把它看作是即时编译缓存;
- 遗憾的是它只支持 G1 或者 Parallel 垃圾收集器,且只存在JDK 9 以后的版本,暂不需要去关注它;JDK 9 以后的版本可以使用这个参数打印相关信息:[-XX:PrintAOT]。
三、关于测试的约束
执行用时统计
- System.naoTime() 输出的是过了多少时间[微秒:10的负9次方秒],并不是完全精确的方法执行用时的合计,为了保证结果准确性,测试的运算次数将拉长到百万甚至千万次。
编译器优化的因素
- 上一节花了一定的篇幅介绍编译器优化,这里我要做的是:对比完全不使用任何编译优化,与使用即时编译时,try catch 对的性能影响。
- 通过指令禁用 JVM 的编译优化,让它以最原始的状态运行,然后看有无 try catch 的影响。
- 通过指令使用即时编译,尽量做到把后端优化拉满,看看 try catch 是否会影响到 jvm的编译优化。
关于指令重排序
目前尚未可知 try catch 的使用影响指令重排序;
我们这里的讨论有一个前提,当 try catch 的使用无法避免时,我们应该如何使用 try catch 以应对它可能存在的对指令重排序的影响。
- 指令重排序发生在多线程并发场景,这么做是为了更好的利用CPU资源,在单线程测试时不需要考虑。不论如何指令重排序,都会保证最终执行结果,与单线程下的执行结果相同;
- 虽然我们不去测试它,但是也可以进行一些推断,参考 volatile 关键字禁止指令重排序的做法:插入内存屏障;
- 假定 try catch 存在屏障,导致前后的代码分割;那么最少的try catch代表最少的分割。
- 所以,是不是会有这样的结论呢:我们把方法体内的 多个 try catch 合并为一个 try catch 是不是反而能减少屏障呢?这么做势必造成 try catch 的范围变大。
当然,上述关于指令重排序讨论内容都是基于个人的猜想,犹未可知 try catch 是否影响指令重排序;本文重点讨论的也只是单线程环境下的 try catch 使用影响性能。
四、测试代码
- 循环次数为100W ,循环内10次预算[给编译器优化预留优化的可能,这些指令可能被合并];
- 每个方法都会到达千万次浮点计算。
- 同样每个方法外层再循环跑多次,最后取其中的众数更有说服力。
public class ExecuteTryCatch {
// 100W
private static final int TIMES = 1000000;
private static final float STEP_NUM = 1f;
private static final float START_NUM = Float.MIN_VALUE;
public static void main(String[] args){
int times = 50;
ExecuteTryCatch executeTryCatch = new ExecuteTryCatch();
// 每个方法执行 50 次
while (--times >= 0){
System.out.println("times=".concat(String.valueOf(times)));
executeTryCatch.executeMillionsEveryTryWithFinally();
executeTryCatch.executeMillionsEveryTry();
executeTryCatch.executeMillionsOneTry();
executeTryCatch.executeMillionsNoneTry();
executeTryCatch.executeMillionsTestReOrder();
}
}
/**
* 千万次浮点运算不使用 try catch
* */
public void executeMillionsNoneTry(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("noneTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* 千万次浮点运算最外层使用 try catch
* */
public void executeMillionsOneTry(){
float num = START_NUM;
long start = System.nanoTime();
try {
for (int i = 0; i < TIMES; ++i){
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
} catch (Exception e){
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("oneTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* 千万次浮点运算循环内使用 try catch
* */
public void executeMillionsEveryTry(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {
}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("evertTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* 千万次浮点运算循环内使用 try catch,并使用 finally
* */
public void executeMillionsEveryTryWithFinally(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {
} finally {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("finalTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* 千万次浮点运算,循环内使用多个 try catch
* */
public void executeMillionsTestReOrder(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
} catch (Exception e) { }
try {
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e){}
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
} catch (Exception e) { }
try {
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("orderTry sum:" + num + " million:" + million + " nao: " + nao);
}
}
五、解释模式下执行测试
-
设置如下JVM参数,禁用编译优化
-Xint -XX:-BackgroundCompilation
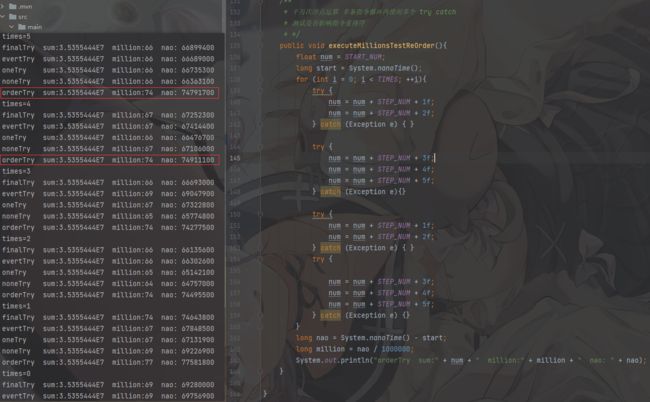
- 结合测试代码发现,即使百万次循环计算,每个循环内都使用了 try catch 也并没用对造成很大的影响。
唯一发现了一个问题,每个循环内多次使用 try catch, 发现性能下降,千万次计算差值为:5~7 毫秒;4个 try 那么执行的指令最少4条goto ,前边阐述过,这里造成这个差异的主要原因是 goto 指令占比过大,放大了问题;当我们在几百行代码里使用少量try catch 时,goto所占比重就会很低,测试结果会更趋于合理。
六、编译模式测试
-
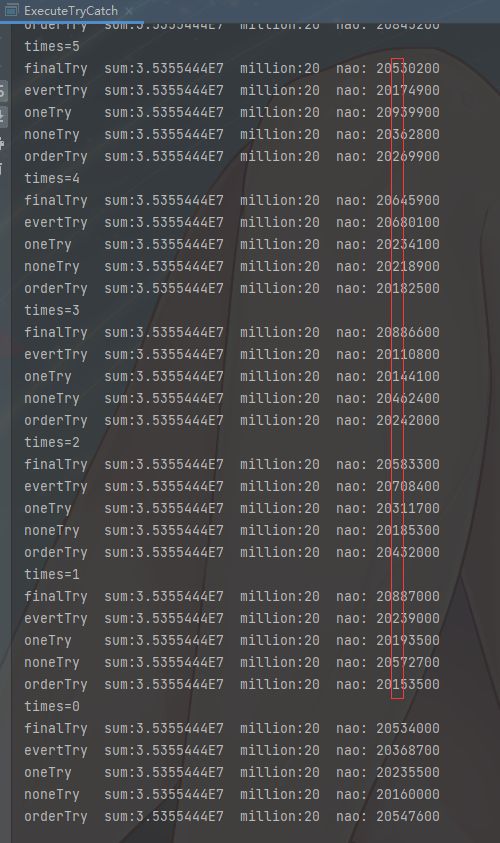
设置如下测试参数,执行10 次即为热点代码
-Xcomp -XX:CompileThreshold=10 -XX:-UseCounterDecay -XX:OnStackReplacePercentage=100 -XX:InterpreterProfilePercentage=33 -
执行结果如下图,难分胜负,波动只在微秒级别,执行速度也快了很多,编译效果拔群啊,甚至连 “解释模式” 运行时多个try catch 导致的,多个goto跳转带来的问题都给顺带优化了;由此也可以得到 try catch 并不会影响即时编译的结论。
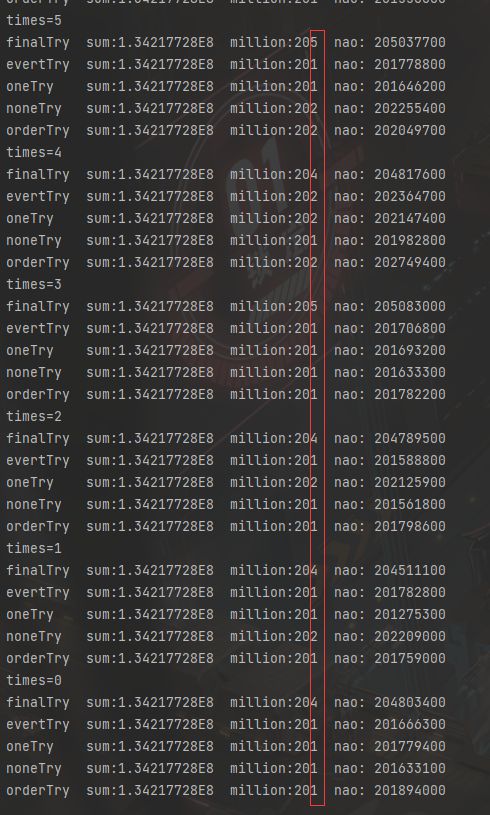
- 我们可以再上升到亿级计算,依旧难分胜负,波动在毫秒级。
七、结论
try catch 不会造成巨大的性能影响,换句话说,我们平时写代码最优先考虑的是程序的健壮性,当然大佬们肯定都知道了怎么合理使用try catch了,但是对萌新来说,你如果不确定,那么你可以使用 try catch;
在未发生异常时,给代码外部包上 try catch,并不会造成影响。
举个栗子吧,我的代码中使用了:URLDecoder.decode,所以必须得捕获异常。
private int getThenAddNoJudge(JSONObject json, String key){
if (Objects.isNull(json))
throw new IllegalArgumentException("参数异常");
int num;
try {
// 不校验 key 是否未空值,直接调用 toString 每次触发空指针异常并被捕获
num = 100 + Integer.parseInt(URLDecoder.decode(json.get(key).toString(), "UTF-8"));
} catch (Exception e){
num = 100;
}
return num;
}
private int getThenAddWithJudge(JSONObject json, String key){
if (Objects.isNull(json))
throw new IllegalArgumentException("参数异常");
int num;
try {
// 校验 key 是否未空值
num = 100 + Integer.parseInt(URLDecoder.decode(Objects.toString(json.get(key), "0"), "UTF-8"));
} catch (Exception e){
num = 100;
}
return num;
}
public static void main(String[] args){
int times = 1000000;// 百万次
long nao1 = System.nanoTime();
ExecuteTryCatch executeTryCatch = new ExecuteTryCatch();
for (int i = 0; i < times; i++){
executeTryCatch.getThenAddWithJudge(new JSONObject(), "anyKey");
}
long end1 = System.nanoTime();
System.out.println("未抛出异常耗时: millions=" + (end1 - nao1) / 1000000 + "毫秒 nao=" + (end1 - nao1) + "微秒");
long nao2 = System.nanoTime();
for (int i = 0; i < times; i++){
executeTryCatch.getThenAddNoJudge(new JSONObject(), "anyKey");
}
long end2 = System.nanoTime();
System.out.println("每次必抛出异常: millions=" + (end2 - nao2) / 1000000 + "毫秒 nao=" + (end2 - nao2) + "微秒");
}
调用方法百万次,执行结果如下:

经过这个例子,我想你知道你该如何 编写你的代码了吧?可怕的不是 try catch 而是 搬砖业务不熟练啊。