大数据项目离线数仓(全 )一(数据采集平台)
搭建用户行为数据采集平台、搭建业务数据采集平台、搭建数据仓库系统、制作可视化报表
本篇博客包括搭建用户行为数据采集平台、搭建业务数据采集平台
搭建数据仓库系统在大数据项目离线数仓(全 )二
制作可视化报表在大数据项目离线数仓(全 )三
目录
一、用户行为数据采集平台
1.1软件工具的安装配置
1.1.1工具
1.1.2软件
1.2平台搭建
1.2.1模拟数据生成
1.2.2消息通道
1.2.3测试
二、业务数据采集平台
2.1软件工具的安装配置
2.2平台搭建
2.2.1数据库搭建
2.2.2同步数据到hdfs
2.3测试
2.3.1生成数据
2.3.2执行数据生成jar包
2.3.3同步数据
2.3.4查看
一、用户行为数据采集平台
1.1软件工具的安装配置
1.1.1工具
1)虚拟机:VMware
2)系统:CentOS 7
3)连接工具:MobaXterm_Portable
MobaXterm_Portable的简单使用_一个人的牛牛的博客-CSDN博客_mobaxterm portable和installer区别
4)编码工具:IDEA
1.1.2软件
1)JDK:jdk-8u171-linux-x64
Linux系统CentOS7安装jdk_一个人的牛牛的博客-CSDN博客
2)hadoop:hadoop-3.1.3
hadoop3X HA安装部署_一个人的牛牛的博客-CSDN博客
hadoop配置LZO压缩_一个人的牛牛的博客-CSDN博客
3)zookeeper:zookeeper-3.4.5
zookeeper单机和集群(全分布)的安装过程_一个人的牛牛的博客-CSDN博客
4)kafka:kafka_2.11-2.4.1
kafka单机和集群(全分布)的安装部署过程_一个人的牛牛的博客-CSDN博客_kafka单机安装部署
5)flume:apache-flume-1.9.0-bin
Flume的安装与Flume监控端口数据官方案例_一个人的牛牛的博客-CSDN博客
1.2平台搭建
1.2.1模拟数据生成
模拟行为日志数据的生成-Java文档类资源-CSDN下载
注:jar包来源于尚硅谷,免费下载
1.修改application.properties
可以根据需求生成对应日期的用户行为日志,更改mock.date=
2.修改logback的生成路劲
#/applog/log是路劲
3.path.json
该文件用来配置访问路径,默认就可以了
1.2.2消息通道
1.通道搭建
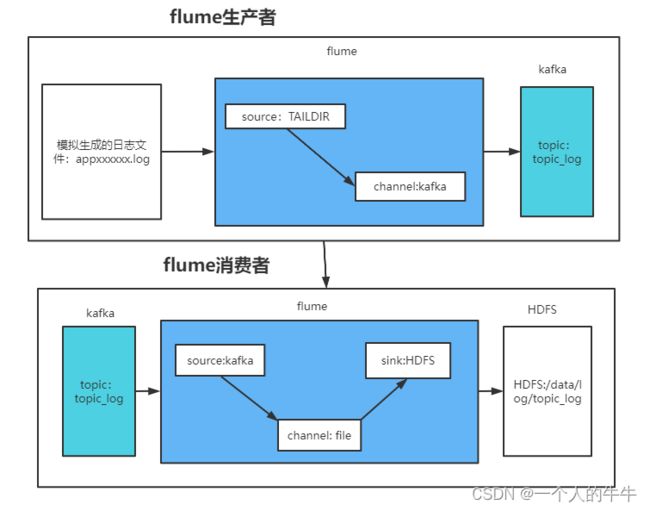
2.flume生产者配置
#主件命名
a1.sources = r1
a1.channels = c1
#配置source
#1固定配置
a1.sources.r1.type = TAILDIR
#2监控的文件夹
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /root/project/offlineDW/applog/applog/log/app.*
#3成功监控的信息
a1.sources.r1.positionFile = /root/project/offlineDW/flume/taildir_position.json
#4拦截器配置
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.zj.flume.interceptor.ETLInterceptor$Builder
#配置channel
#1固定配置
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
#2kafka节点
a1.channels.c1.kafka.bootstrap.servers = hadoop03:9092
#3kafka的topic
a1.channels.c1.kafka.topic = topic_log
#4是否传输header
a1.channels.c1.parseAsFlumeEvent = false
#绑定sink与channel和source与channel的关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c13.flume消费者配置
#组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#source
#固定配置
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
#消费者机器
a1.sources.r1.kafka.bootstrap.servers = hadoop04:9092
#kafka的topic
a1.sources.r1.kafka.topics=topic_log
#flume拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type
a1.sources.r1.interceptors.i1.type = com.zj.flume.interceptor.TimeStampInterceptor$Builder
#channe
#配置channe类型
a1.channels.c1.type = file
#配置checkpoint地址
a1.channels.c1.checkpointDir = /root/project/offlineDW/flume/checkpoint/behavior1
#data地址
a1.channels.c1.dataDirs = /root/project/offlineDW/flume/data/behavior1/
#最大文件大小
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
#控制回滚时间
a1.channels.c1.keep-alive = 6
#sink
#sink类型:hdfs
a1.sinks.k1.type = hdfs
#地址
a1.sinks.k1.hdfs.path =/data/log/topic_log/%Y-%m-%d
#文件开头命名
a1.sinks.k1.hdfs.filePrefix = log-
#计算时间设置(一天)
a1.sinks.k1.hdfs.round = false
#生成新文件策略,10s,128M
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#控制输出文件是原生文件
#压缩格式
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
#拼接
a1.sources.r1.channels = c1
a1.sinks.k1.channels = c11.2.3测试
1.打开flume消费者
bin/flume-ng agent --conf-file conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/training/apache-flume-1.9.0-bin/log2.txt 2>&1 &2.打开flume生产者
bin/flume-ng agent --conf-file conf/file-flume-kafka.conf -n a1 -Dflume.root.logger=INFO,LOGFILE >/training/apache-flume-1.9.0-bin/flume-log.txt 2>&1 &3.生成日志
java -jar xxxx.jar4.查看hdfs数据
http://hadoop02:9870/
有/data/log/topic_log这些内容说明通道打通了。
二、业务数据采集平台
2.1软件工具的安装配置
1)MySQL
Linux安装MySQL5.7(CentOS7)_一个人的牛牛的博客-CSDN博客
2)sqoop
sqoop的安装(sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz)_一个人的牛牛的博客-CSDN博客
#6.测试sqoop连接数据库
bin/sqoop list-databases --connect jdbc:mysql://hadoop01:3306/ --username root --password 123456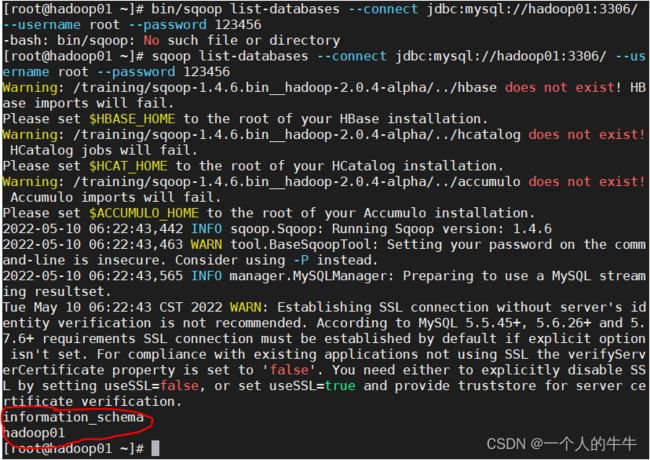
测试连接成功!
3)hive
安装hive配置同步数据到MySQL(apache-hive-3.1.2-bin)_一个人的牛牛的博客-CSDN博客
4)SQLyog
下载SQLyog安装(在Windows上),安装很简单!不做示范了。
链接:https://pan.baidu.com/s/1fQIIRr4hL7f6Jcjwx6ZVMw
提取码:tdnb
2.2平台搭建
2.2.1数据库搭建
MySQL项目--电商平台--数据库搭建_一个人的牛牛的博客-CSDN博客
1.下载模拟数据生成jar包
模拟数据生成写入到mysql-Java文档类资源-CSDN下载
2.把压缩包里的文件上传到Linux的相关目录(我的:/root/project/offlineDW/applog/dblog/)
3.根据需求修改application.properties相关配置
4.运行jar包
java -jar gmall-mock-db.jar5.启动SQLyog,连接到offgmall数据库
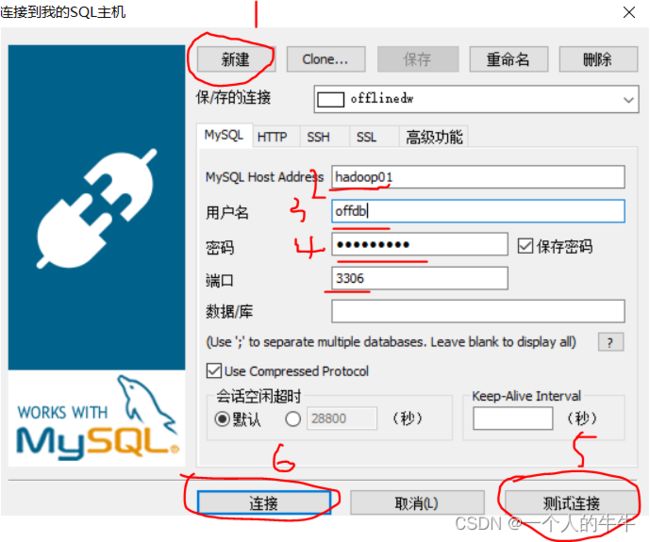
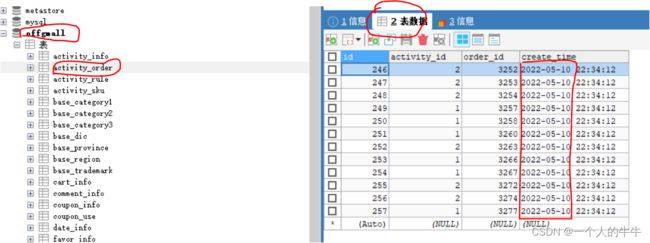
6.查看offgmall数据库下的activity_order表内容,看create_time数据的日期是不是设置的日期
2.2.2同步数据到hdfs
1.同步工具
sqoop
2.同步类型
数据同步策略的类型包括:全量同步、增量同步、新增及变化同步、特殊情况
全量表:存储完整的数据。
增量表:存储新增加的数据。
新增及变化表:存储新增加的数据和变化的数据。
特殊表:只需要存储一次。
3.编写脚本同步数据到hdfs
注:
1)Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
2)APP=offgmall :数据库名称
3)sqoop=/training/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/bin/sqoop :sqoop地址
4)do_date=`date -d '-1 day' +%F` :日期格式
5)hadoop jar /training/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar
com.hadoop.compression.lzo.DistributedLzoIndexer :lzo压缩
6)/data/$APP/db/$1/$do_date :hdfs文件存储位置
7)--username :mysql用户名
8)--password :mysql密码
9)--connect jdbc:mysql://hadoop01:3306/$APP :连接mysql
脚本编写:
vi mysql_to_hdfs.sh
#! /bin/bash
APP=offgmall
sqoop=/training/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/bin/sqoop
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
import_data(){
$sqoop import \
--connect jdbc:mysql://hadoop01:3306/$APP \
--username offdb \
--password Zj_123456 \
--target-dir /data/$APP/db/$1/$do_date \
--delete-target-dir \
--query "$2 and \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by '\t' \
--compress \
--compression-codec lzop \
--null-string '\\N' \
--null-non-string '\\N'
hadoop jar /training/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /data/$APP/db/$1/$do_date
}
import_order_info(){
import_data order_info "select
id,
final_total_amount,
order_status,
user_id,
out_trade_no,
create_time,
operate_time,
province_id,
benefit_reduce_amount,
original_total_amount,
feight_fee
from order_info
where (date_format(create_time,'%Y-%m-%d')='$do_date'
or date_format(operate_time,'%Y-%m-%d')='$do_date')"
}
import_coupon_use(){
import_data coupon_use "select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from coupon_use
where (date_format(get_time,'%Y-%m-%d')='$do_date'
or date_format(using_time,'%Y-%m-%d')='$do_date'
or date_format(used_time,'%Y-%m-%d')='$do_date')"
}
import_order_status_log(){
import_data order_status_log "select
id,
order_id,
order_status,
operate_time
from order_status_log
where date_format(operate_time,'%Y-%m-%d')='$do_date'"
}
import_activity_order(){
import_data activity_order "select
id,
activity_id,
order_id,
create_time
from activity_order
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_user_info(){
import_data "user_info" "select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time
from user_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'
or DATE_FORMAT(operate_time,'%Y-%m-%d')='$do_date')"
}
import_order_detail(){
import_data order_detail "select
od.id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
od.create_time,
source_type,
source_id
from order_detail od
join order_info oi
on od.order_id=oi.id
where DATE_FORMAT(od.create_time,'%Y-%m-%d')='$do_date'"
}
import_payment_info(){
import_data "payment_info" "select
id,
out_trade_no,
order_id,
user_id,
alipay_trade_no,
total_amount,
subject,
payment_type,
payment_time
from payment_info
where DATE_FORMAT(payment_time,'%Y-%m-%d')='$do_date'"
}
import_comment_info(){
import_data comment_info "select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
comment_txt,
create_time
from comment_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_order_refund_info(){
import_data order_refund_info "select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
create_time
from order_refund_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_sku_info(){
import_data sku_info "select
id,
spu_id,
price,
sku_name,
sku_desc,
weight,
tm_id,
category3_id,
create_time
from sku_info where 1=1"
}
import_base_category1(){
import_data "base_category1" "select
id,
name
from base_category1 where 1=1"
}
import_base_category2(){
import_data "base_category2" "select
id,
name,
category1_id
from base_category2 where 1=1"
}
import_base_category3(){
import_data "base_category3" "select
id,
name,
category2_id
from base_category3 where 1=1"
}
import_base_province(){
import_data base_province "select
id,
name,
region_id,
area_code,
iso_code
from base_province
where 1=1"
}
import_base_region(){
import_data base_region "select
id,
region_name
from base_region
where 1=1"
}
import_base_trademark(){
import_data base_trademark "select
tm_id,
tm_name
from base_trademark
where 1=1"
}
import_spu_info(){
import_data spu_info "select
id,
spu_name,
category3_id,
tm_id
from spu_info
where 1=1"
}
import_favor_info(){
import_data favor_info "select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from favor_info
where 1=1"
}
import_cart_info(){
import_data cart_info "select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time,
source_type,
source_id
from cart_info
where 1=1"
}
import_coupon_info(){
import_data coupon_info "select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
spu_id,
tm_id,
category3_id,
limit_num,
operate_time,
expire_time
from coupon_info
where 1=1"
}
import_activity_info(){
import_data activity_info "select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from activity_info
where 1=1"
}
import_activity_rule(){
import_data activity_rule "select
id,
activity_id,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from activity_rule
where 1=1"
}
import_base_dic(){
import_data base_dic "select
dic_code,
dic_name,
parent_code,
create_time,
operate_time
from base_dic
where 1=1"
}
case $1 in
"order_info")
import_order_info
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_detail")
import_order_detail
;;
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"payment_info")
import_payment_info
;;
"base_province")
import_base_province
;;
"base_region")
import_base_region
;;
"base_trademark")
import_base_trademark
;;
"activity_info")
import_activity_info
;;
"activity_order")
import_activity_order
;;
"cart_info")
import_cart_info
;;
"comment_info")
import_comment_info
;;
"coupon_info")
import_coupon_info
;;
"coupon_use")
import_coupon_use
;;
"favor_info")
import_favor_info
;;
"order_refund_info")
import_order_refund_info
;;
"order_status_log")
import_order_status_log
;;
"spu_info")
import_spu_info
;;
"activity_rule")
import_activity_rule
;;
"base_dic")
import_base_dic
;;
"first")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_province
import_base_region
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
esac
脚本的使用:
1)第一次同步数据:mysql_to_hdfs.sh first 2020-05-10 (同步2022-05-10的数据)
2)以后每天同步数据:mysql_to_hdfs.sh all 2022-05-10 (同步2022-05-10的数据)
2.3测试
2.3.1生成数据
(时间:2022-05-10)
vi application.properties
2.3.2执行数据生成jar包
java -jar gmall-mock-db.jar
2.3.3同步数据
1)mysql_to_hdfs.sh all
2)mysql_to_hdfs.sh first 2022-05-10
2.3.4查看
1)启动脚本同步成功后Linux的样式
2)启动脚本同步成功8088样式

3)启动脚本同步成功9870样式 (9870:hadoop3x 50070:hadoop2x)
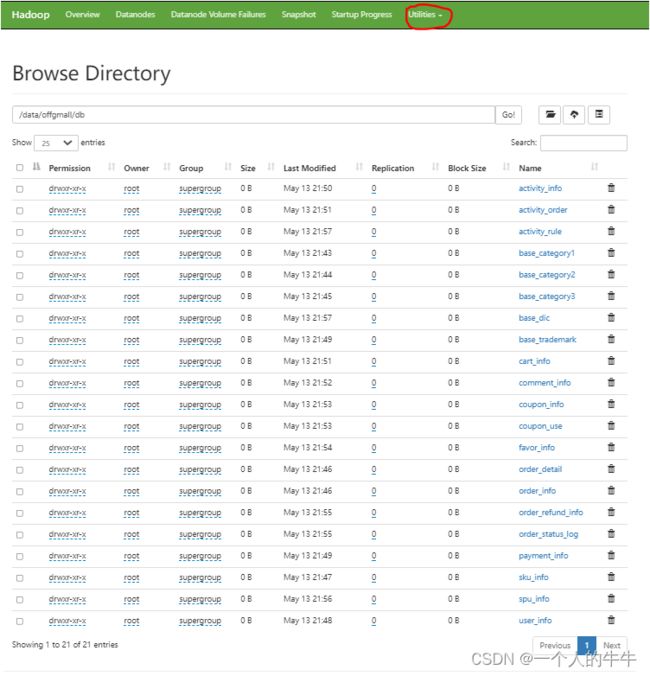
4)同步到hdfs的数据位置
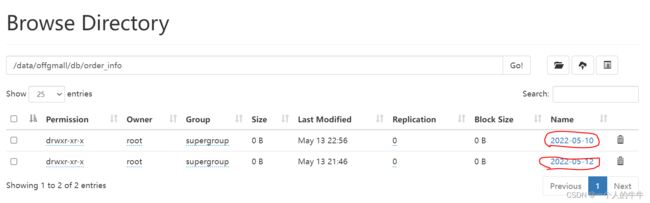
显示出2022-05-10有数据,有数据才有索引。
xxxx.lzo lzo压缩文件
xxxx.index 索引文件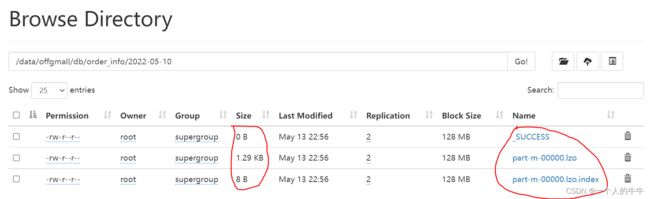
显示出2022-05-12没有数据
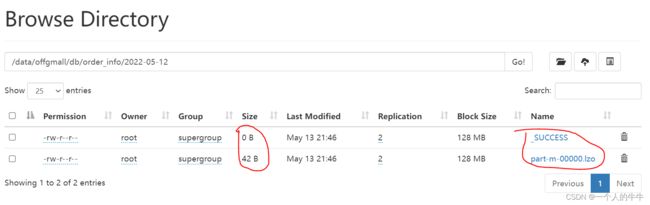
MySQL 到 hdfs同步数据成功!!!
业务数据采集平台搭建完成!!!
本文参考于:
尚硅谷大数据项目
星形和雪花模型_维度建模的三种模型——星型模型、雪花模型、星座模型_浅野千奈美的博客-CSDN博客
若兰幽竹的博客_CSDN博客-Kettle,Spark,Hadoop领域博主