datawhale 8月学习——NLP之Transformers:BERT和GPT
前情回顾
1.attention和transformers
结论速递
由于没有很多的NLP知识背景,跳开NLP框架来学习BERT和GPT的时候,有许多不解和迷惑的地方。在本次学习中,我参考了一些相关的NLP博客文章,试图为自己构建一个NLP的知识体系。对于本次学习,其实核心的需要理解NLP中的预训练+微调模式,以及一类重要的任务——语言建模。
对于BERT模型,教程里面的逻辑并非层层展开的,这边简单小结一下BERT的主要关注点:
- 首先BERT应用是预训练+微调模式,这也是NLP常用的模式;
- BERT模型本质上是一个语言建模模型;
- BERT用了Transformer的Encoder,并且使用了mask来改进Encoder,从而实现语言建模的目的;
- BERT的用途还算广泛,可以用于文本分类,QA任务等,使用方法是下载预训练好的BERT,然后根据任务类型在合适输出位置后加FFNN。
对于GPT模型,教程里将其与对Transformer Decoder的进一步向量化讲解糅合在一起,这边也简单小结一下GPT的关注点:
- GPT模型也是一个语言建模模型
- GPT用了Transformer的Decoder,也因而需要把每一步的输出拿回来当输入
- 对GPT的向量化计算及涉及的权重进行了详细说明
除此之外,这个task还进一步展开解释了Self-Attention的向量化计算过程,结合上一个task的笔记,效果更佳。
本文索引
-
- 前情回顾
- 结论速递
- 1 BERT
-
- 1.1 BERT的诞生
-
- 1.1.1 NLP的发展与BERT的诞生
- 1.1.2 BERT的使用简介
- 1.1.3 BERT的使用案例:句子分类
- 1.2 BERT模型
-
- 1.2.1 概述
- 1.2.2 简单理解BERT模型
- 1.2.3 BERT预训练的本质:语言建模(词嵌入)
-
- 1.2.3.1 词嵌入的回顾
- 1.2.3.2 ELMo:考虑上下文的词嵌入
- 1.2.3.3 OpenAI Transformer:Transformer Decoder获取上文信息
- 1.2.3.4 BERT:Transformer Encoder获取上下文信息
- 1.2.4 BERT的使用
-
- 1.2.4.1 BERT的输入嵌入
- 1.2.4.2 BERT在不同任务上的应用
- 1.2.4.3 将 BERT 用于特征提取
- 1.2.4.4 如何使用BERT
- 2 GPT2和Transformer Decoder的理解
-
- 2.1 什么是GPT2
- 2.2 Transformer Block的进化
-
- 2.2.1 Self-Attention和Masked Self-Attention
- 2.2.2 Transformer-Decoder
- 2.3 简单理解GPT2模型
-
- 2.3.1 宏观上看GPT2的计算过程
- 2.3.2 展开看GPT2的计算过程
-
- 2.3.2.1 输入
- 2.3.2.2 self-attention计算
- 2.3.2.3 输出
- 2.4 向量化理解Self-Attention
-
- 2.4.1 Self-Attention
- 2.4.2 Masked Self-Attention
- 2.5 向量化理解GPT2的计算
-
- 2.5.1 Masked Self-Attention层
- 2.5.2 FFNN层
- 2.5.3 权重矩阵小结
- 2.6 Transformer Decoder的其他应用
- 篇章小测
- 参考阅读
1 BERT
1.1 BERT的诞生
1.1.1 NLP的发展与BERT的诞生
2018年是NLP的ImageNet时刻,就是说多年前类似的发展也加速了机器学习在计算机视觉任务中的应用。在这一年的里程碑式BERT的发布,标志这一个新的时代的开始。
BERT 是一个模型,它打破了模型处理基于语言的任务的能力的多项记录。
这是一个重大的发展,因为它使得任何一个构建构建机器学习模型来处理语言的人,都可以将这个强大的功能作为一个现成的组件来使用,从而节省了从零开始训练语言处理模型所需要的时间、精力、知识和资源。
NLP当前面临的任务是如何最好地表示单词和句子,从而最好地捕捉基本语义和关系。
在这样的背景下,BERT诞生了。BERT诞生于NLP的一些聪明想法上(包括但不限于半监督序列学习、ELMo、ULMFiT、OpenAI transformer和Transformer)。
这些聪明想法为:
- ELMo:考虑上下文的词嵌入技术(后面1.2.3.2节会进行介绍)
- ULM-FiT:NLP 领域的迁移学习
受 ImageNet 预训练在计算机视觉任务上启发,生成式预训练 LM + 任务微调的思路最先在 ULMFiT上得到了尝试。
它所使用的模型是AWD-LSTM,通过LM预训练,目标任务LM微调,还有目标任务分类器微调三步完成。
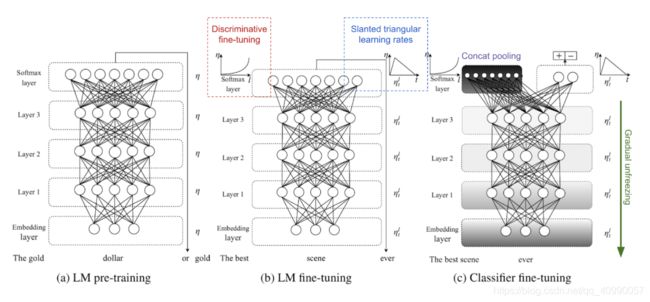
- Transformer:比LSTM更好地处理长期依赖
其Encoder+Decoder结构使得其非常适合机器翻译,但是在文本分类问题上还需要改变。 - OpenAI Transformer:预训练一个 Transformer Decoder 来进行语言建模(后面1.2.3.3节也会详细介绍)
提出BERT的Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing,其代码开源在GitHub上google-research/bert
1.1.2 BERT的使用简介
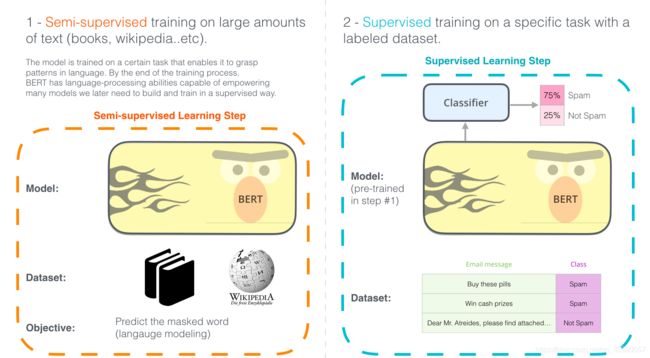
使用BERT分为两大主要的步骤
- 下载预训练好的模型
一般来讲,这个模型是在无标注的数据上训练的 - 针对自己的数据进行模型微调
下面这张图来源于The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning),它比较简单清晰的解释了使用BERT的两大主要步骤。
1.1.3 BERT的使用案例:句子分类
可以通过句子分类任务更直观地理解BERT模型的使用,任务描述如下:
垃圾邮件检测:
通过分析邮件中的信息,判断邮件为“垃圾邮件”或者“非垃圾邮件”。
这个任务属于一个监督学习任务,需要一个带有标签的数据集,即一个邮件内容列表,和对应的一系列标签。
为了比较好地完成这一个任务,我们可能需要一个很大的有标签数据集,但是通过BERT,我们可以减少这个数据集的大小要求。
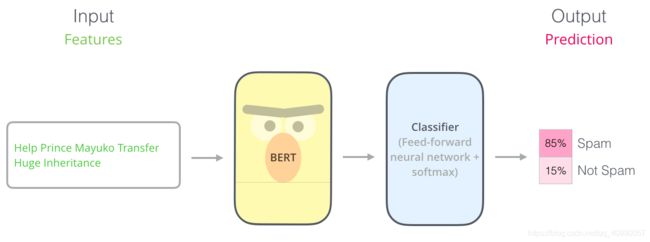
如上图所示,只需要下载一个BERT,然后训练上述的Classifier就可以,几乎不需要改动BERT模型。
这个训练过程称为微调,它起源于Semi-supervised Sequence Learning 和 ULMFiT。
1.2 BERT模型
1.2.1 概述
文章发布时提到了两种大小的BERT,一种是BASE版本,比较小一些(与OpenAI Transformer大小接近),方便和其他模型比较性能;另外一种是LARGE版本,这是一个非常巨大的模型,可以取得最先进的成果。
这两种BERT模型都有大量的Encoder层,BASE和LARGE分别有12层和24层,同时也有更大的前馈神经网络(768, 1024 hidden units)和更多的Attention heads(12, 16)。
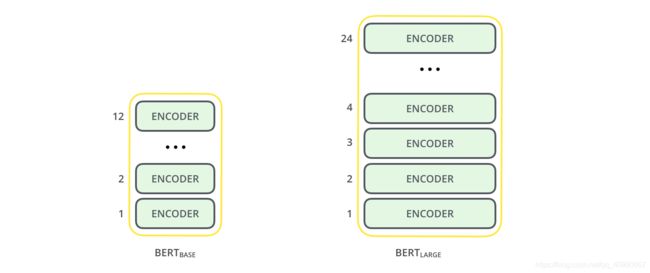

如今已经增加了多个模型,这个在BERT的Github上面可以下载得到,其中中文是唯一的一个非英语模型。
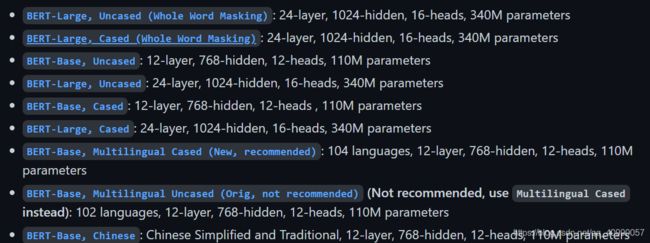
需要注意的是,BERT模型的预训练需要的计算要求非常高,所以其可复现性很差,我们在使用的时候只能够直接用,然后微调。
Reddit对跑一次BERT的价格讨论展示,确实是相当昂贵:
For TPU pods:
4 TPUs * ~$2/h (preemptible) * 24 h/day * 4 days = $768 (base model)
16 TPUs = ~$3k (large model)
For TPU:
16 tpus * $8/hr * 24 h/day * 4 days = 12k
64 tpus * $8/hr * 24 h/day * 4 days = 50k
For GPU:
"BERT-Large is 24-layer, 1024-hidden and was trained for 40 epochs over a 3.3 billion word corpus. So maybe 1 year to train on 8 P100s? "
实在是贵得离谱。
1.2.2 简单理解BERT模型
BERT模型有很多个位置输出,每个位置输出一个大小为hidden_size的向量,如下图所示
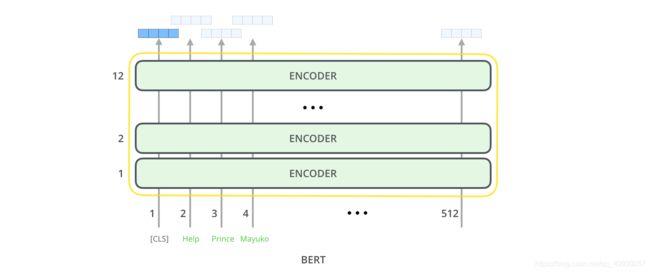
对于前面所述的文本分类的例子,我们关注的是第一个位置输出的向量,也就是[CLS]那个位置。该向量现在可以用作我们选择的分类器的输入。
就像下面这样,叠加一个单层的Classifier
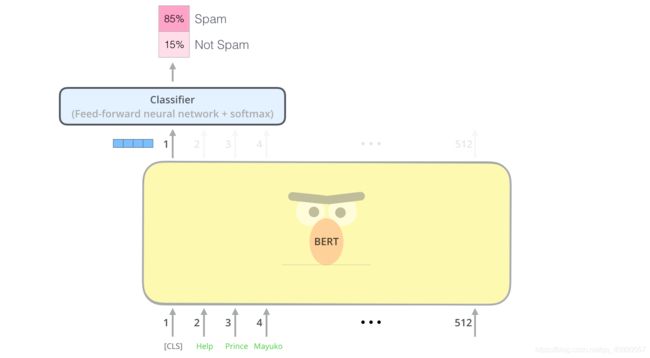
这个感觉有点像计算机视觉问题中VGGNet等网络中完成特征提取的卷积部分,和网络最后完成分类问题的全连接分类部分。
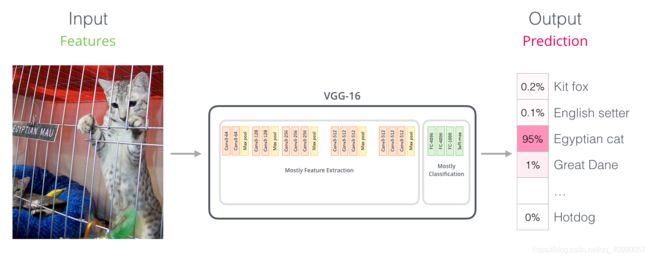
有点像下面这样的类比
| 模型/功能 | 特征提取 | 分类 |
|---|---|---|
| 计算机视觉分类任务 | 卷积层 | 全连接分类层 |
| 文本分类任务 | BERT | 全连接分类层 |
1.2.3 BERT预训练的本质:语言建模(词嵌入)
1.2.3.1 词嵌入的回顾
所谓的词嵌入,是指
单词不能直接输入机器学习模型,而需要某种数值表示形式,以便模型能够在计算中使用。通过 Word2Vec,我们可以使用一个向量(一组数字)来恰当地表示单词,并捕捉单词的语义以及单词和单词之间的关系(例如,判断单词是否相似或者相反,或者像 “Stockholm” 和 “Sweden” 这样的一对词,与 “Cairo” 和 "Egypt"这一对词,是否有同样的关系)以及句法、语法关系(例如,“had” 和 “has” 之间的关系与 “was” 和 “is” 之间的关系相同)。
词嵌入对自然语言处理来说相当重要,为了达到好的效果,最好是在大规模的文本数据上预训练好词嵌入,然后直接拿来使用。
现在已经有很多中词嵌入的方法,最常用的是Word2Vec和GloVe,我们可以下载器预训练好的单词列表,并完成词嵌入。
教程里给了一个直观的词嵌入的例子:
在GloVe中单词stick的词嵌入向量,其长度是200.
1.2.3.2 ELMo:考虑上下文的词嵌入
尽管GloVe已经在很多地方很有用处,但是它并没有考虑到一个单词出现在文章中的不同位置会有什么不同的含义。
语言模型嵌入(Embeddings from Language Model,ELMo)试图通过无监督的方式预训练一个语言模型来获取情景化字词表示,它是一种语境化的词嵌入技术。
ELMo没有对单词使用固定的词嵌入,而是在为每个词分配词嵌入之前,查看整个句子,融合上下文信息。
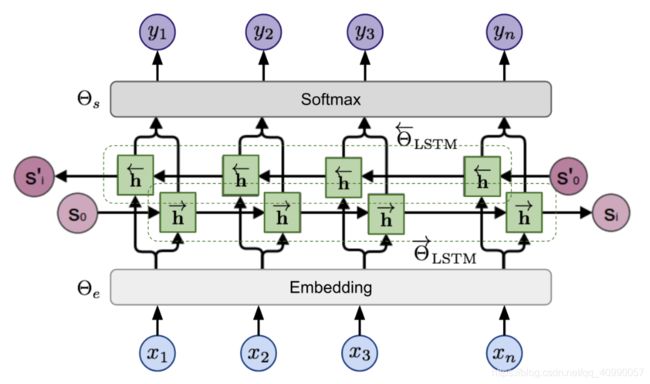
「双向语言模型(bidirectional Language Model,biLM)」 是 ELMo 的基础,当输入为 n n n个标识组成的序列时, ( x 1 , . . . , x n ) (x_1,...,x_n) (x1,...,xn),语言模型会学着根据历史预测下个标识的概率。
下图展示了ELMo 的 biLSTM 基础模型。把很多很多地语料输入到这个模型中,就可以得到上下文词嵌入。
ELMo的秘密通俗地讲,就是通过训练,预测单词序列中的下一个词,从而获得了语言理解能力,这项任务被称为语言建模。
举个例子,以 “Let’s stick to” 作为输入,预测下一个最有可能的单词。分为前向和后向两部分,都会进行预测,每个unit都可以输出当前方向下最大概率出现的下一个单词。
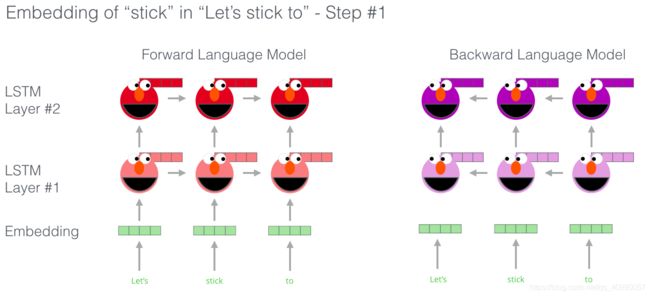
ELMo 通过将隐藏层状态(以及初始化的词嵌入)以某种方式(向量拼接之后加权求和)结合在一起,实现了带有语境化的词嵌入。(为什么每个隐层和初始的词嵌入都要结合起来?)
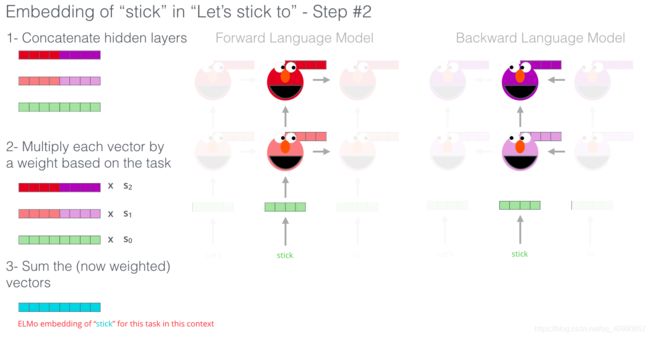
1.2.3.3 OpenAI Transformer:Transformer Decoder获取上文信息
OpenAI Transformer使用Transformer的Decoder 来进行语言建模,选择Decoder是因为它有mask,可以除去下文的影响,适合进行语言建模。
这个模型包括 12 个 Decoder 层。因为在这种设计中没有 Encoder,这些 Decoder 层不会像普通的 Transformer 中的 Decoder 层那样有 Encoder-Decoder Attention 子层。不过,它仍然会有 Self Attention 层(这些层使用了 mask,因此不会看到句子后来的 token)。
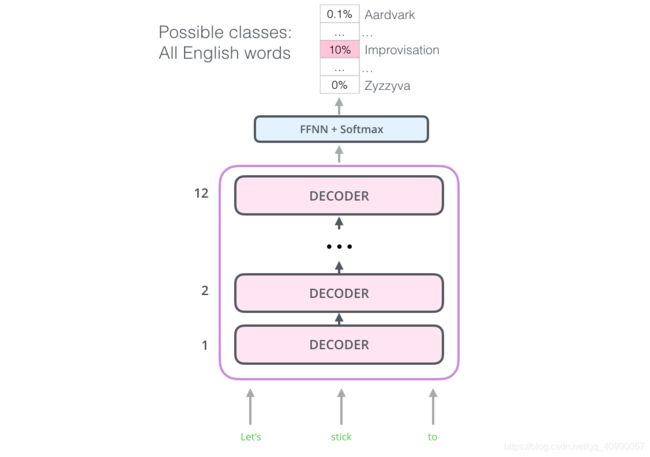
当OpenAI Transformer 经过了预训练,它的网络层经过调整,可以很好地处理文本语言,就可以开始使用它来处理下游任务。
例如句子分类任务(把电子邮件分类为 ”垃圾邮件“ 或者 ”非垃圾邮件“),直接在后面街上一个全连接神经网络。

论文中列举了一些常见的下游任务所需要对应的输入和输出,包括分类任务,推理任务,文本相似性检查,多种选择等。
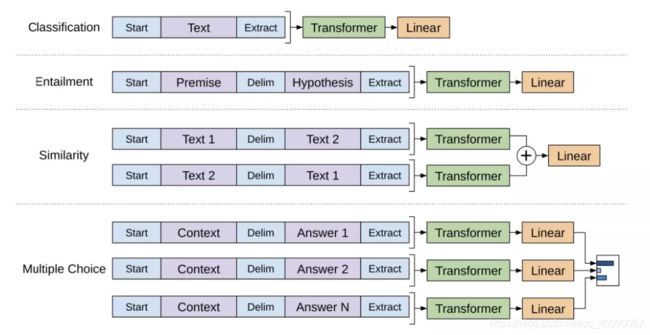
GPT 的一个局限之处在于单向性——模型只会自左向右的预测上下文。
1.2.3.4 BERT:Transformer Encoder获取上下文信息
前面提到,ELMo可以实现双向语言建模,但OpenAI Transformer 只训练了一个前向的语言模型。我们希望可以获得一个双向语言建模的基于Transformer 的模型。
事实上BERT的全称就是Transformer 双向编码器表示(Bidirectional Encoder Representations from Transformers,BERT)
为了能够获取上下文信息,BERT完成了两个任务:
第一个任务,遮罩语言模型(Mask language model,MLM):
BERT尝试使用Transformer的Encoder来实现上下文信息的获取,但是Encoder的self-attention会把更多的注意力集中到自己身上,就学不到有用的上下文信息了。于是,BERT 提出使用 mask,把需要预测的词屏蔽掉。
这个模型也叫MLM,即遮罩语言模型(Mask language model,MLM),它像完形填空一样有趣。
“完形填空(填充缺失测验)是一项练习,测试或评估,由一部分语句构成,其中特定项、字词或符号会被删除(填空文本),与试者的任务是替换缺失语言项……该练习首先由 W.L. Taylor 在 1953 年提出”
- 每个句子随机挡住 15% 的内容。因为如果我们只用特殊占位符 [MASK] 换掉被遮标识,微调的时候特定标识就再也看不到了。所以 BERT 用了几个启发式技巧:
a. 80% 的概率用 [MASK] 替换选定词
b. 10% 的概率用随机词替换
c. 10% 的概率保持不变 - 模型只预测缺失词,但它不知道哪个词被替换了,或者要预测哪个词。输出大小只有输入的 15%
下面这个图可以直观地展示MLM:
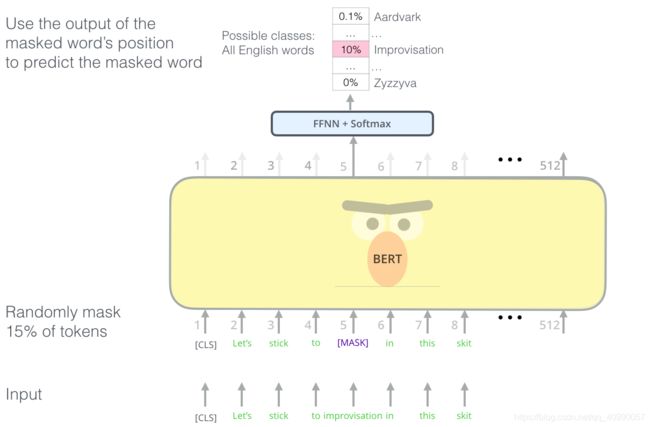
BERT 在语言建模任务中,巧妙地屏蔽了输入中 15% 的单词,并让模型预测这些屏蔽位置的单词。
除了屏蔽输入中 15% 的单词外, BERT 还混合使用了其他的一些技巧,来改进模型的微调方式。例如,有时它会随机地用一个词替换另一个词,然后让模型预测这个位置原来的实际单词。
第二个任务,下一句预测:
由于许多下游任务涉及到对句子间关系的理解(QA,NLI),BERT 额外加了一个辅助任务,训练一个二分类器(binary classifier)判断一句话是不是另一句的下文:
- 对语句对(A,B)采样:
a. 50% 的情况 B 是 A 的下文
b. 50% 的情况不是 - 模型对两句话进行处理并输出一个二值标签,指明 B 是否就是 A 后的下一句话
上述两个辅助任务的训练数据可以轻易从任意单语语料中获取,所以训练规模不受限制。训练损失是累计平均遮罩 LM 概率,和累计平均下文预测概率。

BERT 预训练的第 2 个任务是两个句子的分类任务。在上图中,tokenization 这一步被简化了,因为 BERT 实际上使用了 WordPieces 作为 token,而不是使用单词本身。在 WordPiece 中,有些词会被拆分成更小的部分。
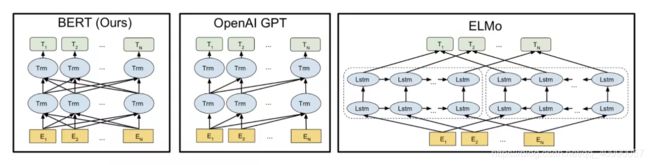
下面这个图片展示了上面提到的三个语言建模模型的不同,还挺直观的。
1.2.4 BERT的使用
1.2.4.1 BERT的输入嵌入
为了在任务中使用BERT模型,需要了解BERT模型的不同位置输出的含义,这个其实涉及到了BERT的输入嵌入
BERT的输入嵌入是三部分的和:
- 「字段标识嵌入(WordPiece tokenization embeddings)」
字段模型原本是针对日语或德语的分词问题提出的。相较于使用自然分隔的英文单词,它们可以进一步分成更小的子词单元便于处理罕见词或未知词。(分词优化也是一个常见的问题) - 「片段嵌入(segment embedding)」
如果输入有两句话,分别有句子 A 和句子 B 的嵌入向量,并用特殊标识 [SEP] 隔开;如果输入只有一句话就只用句子 A 的嵌入向量。 - 「位置嵌入(position embeddings)」
位置 embedding 需要学习而非硬编码。
如下图所示:
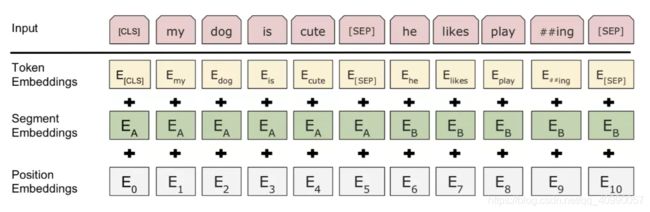
需要注意的是,注意第一个标识必须是 [CLS],它是之后下游任务预测中会用到的占位符。
1.2.4.2 BERT在不同任务上的应用
其实也就是微调,论文中给了下图:
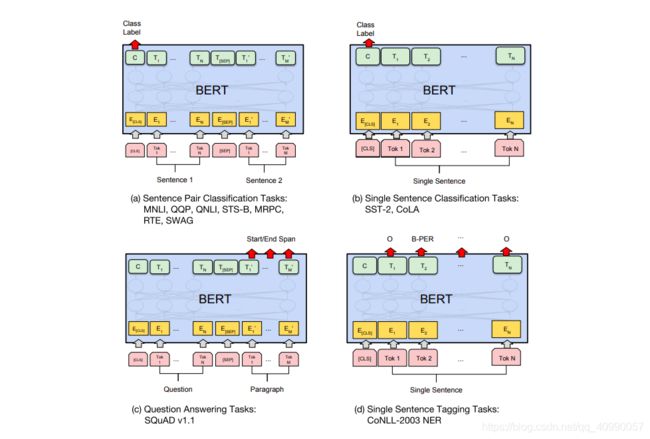
对于分类任务,取首个标识 [CLS] 的最终隐态 h L [ C L S ] h_L^{[CLS]} hL[CLS],然后再加上一个权重矩阵(可以通过全连接神经网络训练得到),再 s o f t m a x softmax softmax就可以,也就是 s o f t m a x ( h L [ C L S ] W c l s ) softmax(h_L^{[CLS]}W_{cls}) softmax(hL[CLS]Wcls)。
而QA任务,要针对问题预测给定段落的文本跨度。BERT 对每个标识要预测两个概率分布,分别对应描述作为文本范围的开端和末尾的几率。微调时新训练的只有两个小矩阵 W s W_s Ws和 W e W_e We ,而 s o f t m a x ( h L ( i ) W s ) softmax(h_L^{(i)}W_{s}) softmax(hL(i)Ws)和 s o f t m a x ( h L ( i ) W e ) softmax(h_L^{(i)}W_{e}) softmax(hL(i)We)对应两个概率分布。
总体来讲微调下游任务时加上的内容很少——一两个权重矩阵,负责将 Transformer的 隐态转换成可解释形式。
1.2.4.3 将 BERT 用于特征提取
使用 BERT 并不是只有微调这一种方法。就像 ELMo 一样,你可以使用预训练的 BERT 来创建语境化的词嵌入。然后你可以把这些词嵌入用到你现有的模型中。论文里也提到,这种方法在命名实体识别任务中的效果,接近于微调 BERT 模型的效果。
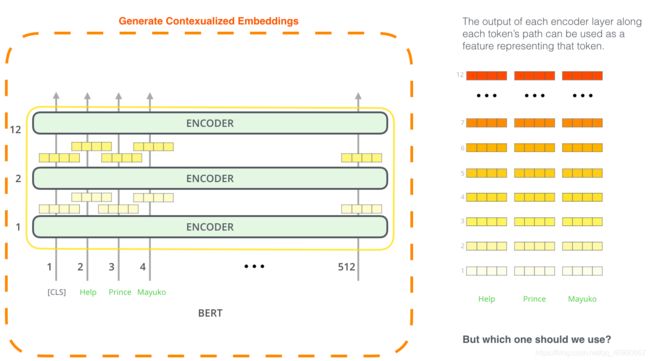
1.2.4.4 如何使用BERT
尝试 BERT 的最佳方式是通过托管在 Google Colab 上的 BERT FineTuning with Cloud TPUs。如果你之前从来没有使用过 Cloud TPU,那这也是一个很好的尝试开端,因为 BERT 代码可以运行在 TPU、CPU 和 GPU。
2 GPT2和Transformer Decoder的理解
2.1 什么是GPT2
事实上,我们在前面的1.2.3.3节已经接触到了GPT,OpenAI Transformer,也叫生成式预训练 Transformer(Generative Pre-training Transformer,GPT)。
GPT2是OpenAI开发的GPT 2.0,它的核心思想就是认为可以用无监督的预训练模型去做有监督任务。GPT2模型的结构还是和GPT一样,由Transformer的Decoder构成。和前文所述一致,它是通过从大量语料上训练一个机器学习模型,来进行语言建模。
GPT-2发布了四个大小版本,层数都很多,如下图
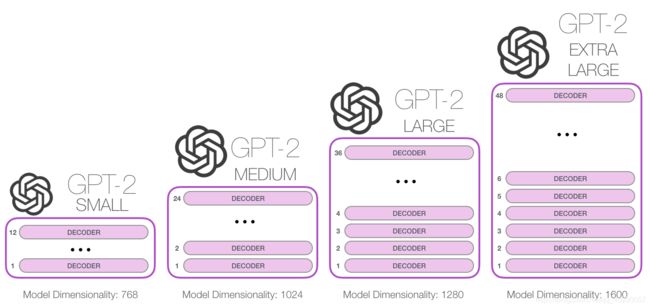
与使用Encoder的BERT模型不同,采用了Decoder的GPT2在每次生成一个结果后,都会把结果添加到输入序列当中,这个新的序列就会变成模型下一步的输入,这是一种叫“自回归(auto-regression)”的思想。这种做法可以使得 RNN 非常有效。
这个其实很好理解,因为decoder就是这么运作的。
GPT2,和后来的一些模型如 TransformerXL 和 XLNet,本质上都是自回归的模型。但 BERT 不是自回归模型。这是一种权衡。去掉了自回归后,BERT 能够整合左右两边的上下文,从而获得更好的结果。XLNet 重新使用了 自回归,同时也找到一种方法能够结合两边的上下文。
2.2 Transformer Block的进化
2.2.1 Self-Attention和Masked Self-Attention
经过上一个任务attention和transformers的学习,我们现在已经很熟悉Transformer是由Encoder和Decoder构成的。
Encoder长这样,Self-Attention是重要的部分。
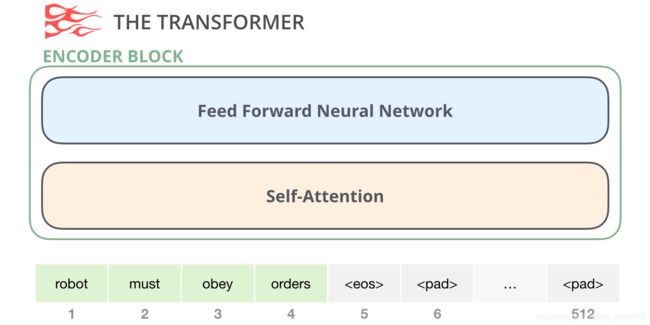
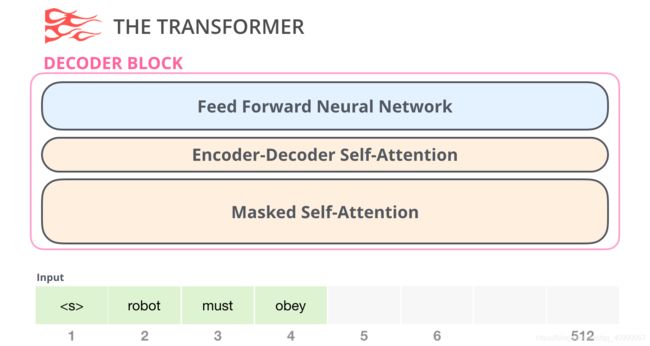
而Decoder长这样,它比Encoder多了一个Encoder-Decoder Self-Attention层,从而使它可以关注到来自于Encoder的信息。
同时Decoder的Self-Attention有Mask,也叫Masked Self-Attention,用于屏蔽未来的token,具体来说,它不像 BERT 那样将单词改为mask,而是通过改变 Self-Attention 的计算,阻止来自被计算位置右边的 token。
下图可以比较直观地看出来Self-Attention和Masked Self-Attention的区别。
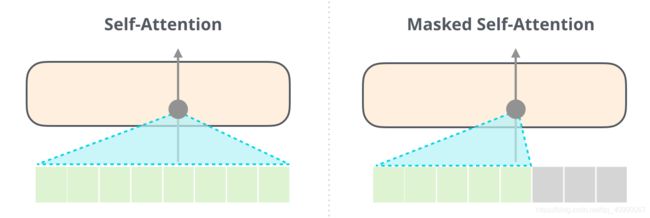
其中Self-Attention是BERT用的,而Masked Self-Attention是GPT2用的。
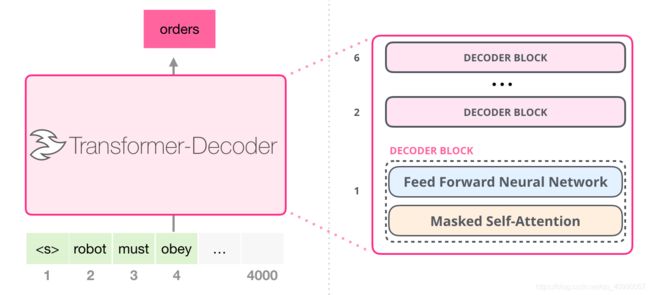
2.2.2 Transformer-Decoder
由Generating Wikipedia by Summarizing Long Sequences 提出的仅decoder模型Transformer-Decoder是GPT的雏形。
2.3 简单理解GPT2模型
2.3.1 宏观上看GPT2的计算过程
GPT-2 能够处理 1024 个 token。每个 token 沿着自己的路径经过所有的 Decoder 模块。
运行一个训练好的 GPT-2 模型的最简单的方法是让它自己生成文本(这在技术上称为 生成无条件样本)。或者,我们可以给它一个提示,让它谈论某个主题(即生成交互式条件样本)。在漫无目的情况下,我们可以简单地给它输入初始 token,并让它开始生成单词(训练好的模型使用 <|endoftext|>作为初始的 token。我们称之为
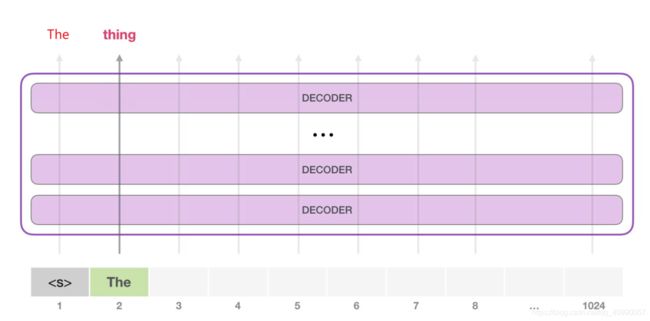
模型只有一个输入的 token,因此只有一条活跃路径。token 在所有层中依次被处理,然后沿着该路径生成一个向量。这个向量可以根据模型的词汇表计算出一个分数(模型知道所有的 单词,在 GPT-2 中是 5000 个词)。
在这个例子中,我们选择了概率最高的 the。但我们可以把事情搞混——你知道如果一直在键盘 app 中选择建议的单词,它有时候会陷入重复的循环中,唯一的出路就是点击第二个或者第三个建议的单词。同样的事情也会发生在这里,GPT-2 有一个 t o p − k top-k top−k 参数,我们可以使用这个参数,让模型考虑第一个词( t o p − k = 1 top-k =1 top−k=1)之外的其他词。
请注意,第二条路径是此计算中唯一活动的路径。GPT-2 的每一层都保留了它自己对第一个 token 的解释,而且会在处理第二个 token 时使用它(我们会在接下来关于 Self Attention 的章节中对此进行更详细的介绍)。GPT-2 不会根据第二个 token 重新计算第一个 token。
其实就是,给一个输入,经过GPT2,出来一个输出;下一个时刻,再把这个输出作为输入放入GPT2,然后计算下一个输出。
2.3.2 展开看GPT2的计算过程
2.3.2.1 输入
首先是输入编码,如下图,每一行都是一个词的embedding。这是一个数字列表wte,可以表示一个词并捕获一些含义。这个列表的大小在不同的 GPT-2 模型中是不同的。最小的模型使用的 embedding 大小是 768。
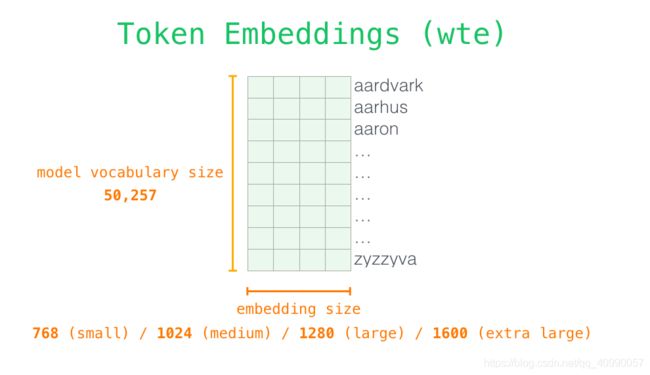
在这个列表的最开始,我们需要一个
但是,在把
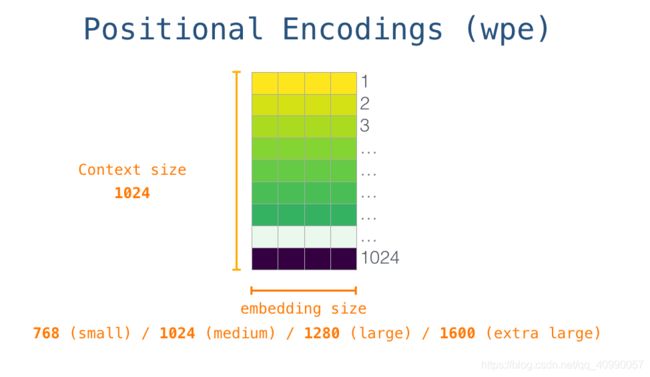
wpe和wte都需要放入模型,则需要先把两个矩阵相加,再输入模型。

这一点还挺重要的,这意味着后一个时刻的输入并不是直接是前一个时刻的输出。(但是怎么换算的暂时没有想明白)
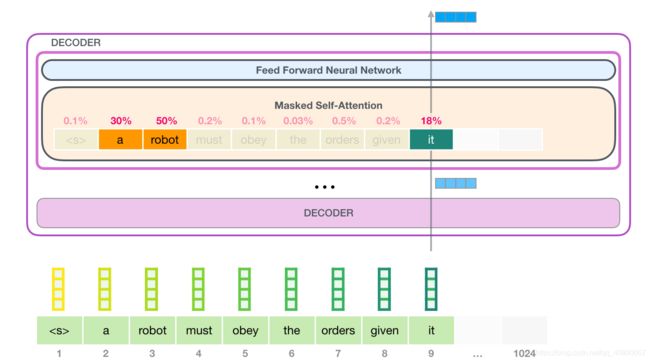
2.3.2.2 self-attention计算
键值对self-attention回顾
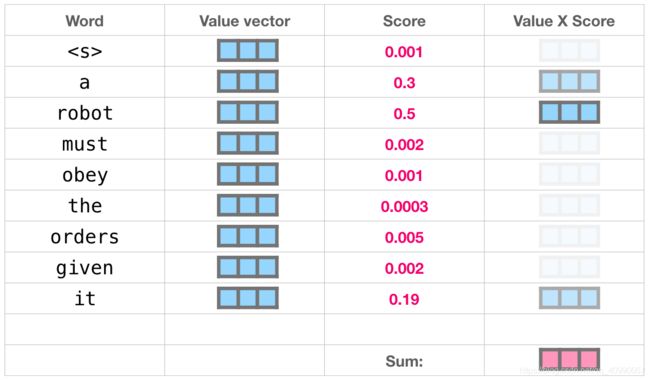
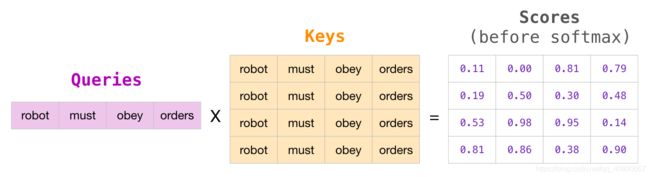
每个时刻,拿着Q,找K对应的V,有点像在文件柜里头找文件,下面这张图展示了Q与K匹配的情况。
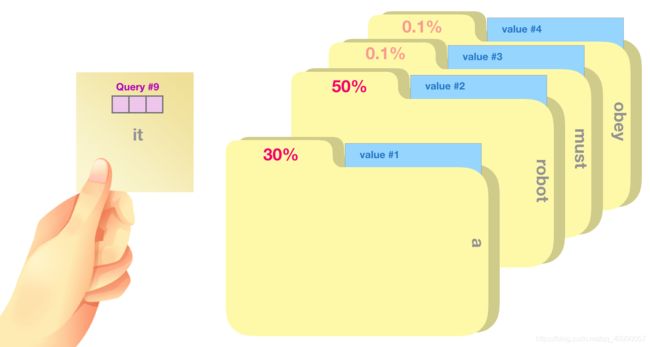
将每一个值乘以分数并求和,就可以得到自注意力结果
2.3.2.3 输出
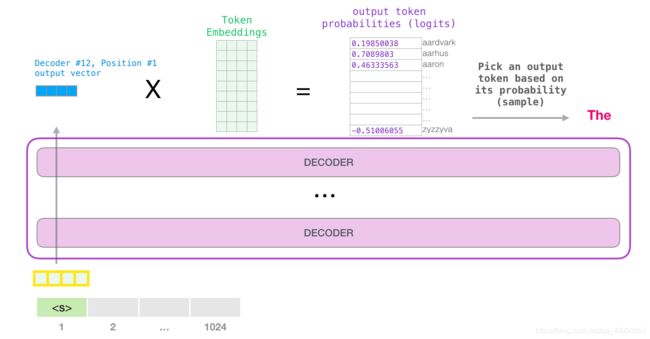
当模型顶部产生输出向量时,可以将该向量乘以embedding的矩阵。

embedding矩阵的每一行都对应于模型词汇表的一个词,这个相乘的结果,就对应于表里每个词(token)的分数。(token通常是词的一部分,其实用token更合适)
比如说,像下面这个

然后就可以找到最大的一个 token( t o p k = 1 top_k=1 topk=1),当然同时也可以多得到几个,这样可能效果会更好。
一般来说会 t o p k top_k topk 设置为 40,让模型考虑得分最高的 40 个词。
2.4 向量化理解Self-Attention
2.4.1 Self-Attention
在以下例子中,让我们看看一个玩具 Transformer,它一次只能处理 4 个 token。
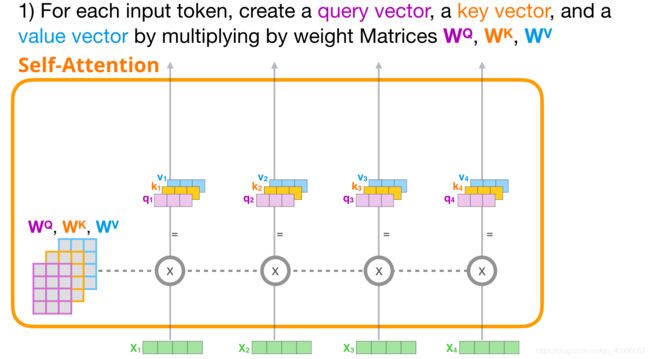
Self-Attention 主要通过 3 个步骤来实现:
- 为每个token创建 Query、Key、Value 向量(通过乘以 W Q W_Q WQ, W K W_K WK, W V W_V WV来实现) 。
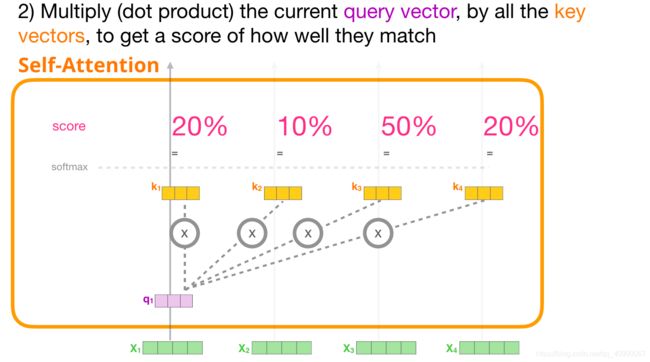
- 对于每个输入的 token,使用它的 Query 向量为所有其他的 Key 向量进行打分。
- 将 Value 向量乘以它们对应的分数后求和。
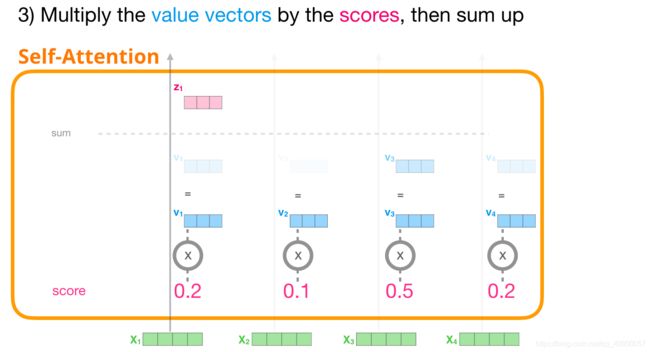
2.4.2 Masked Self-Attention
Masked Self-Attention其实也只是,把后面的token挡住(设为0),模型无法看到未来的值。
这个masking通常通过一个矩阵来实现,叫做attention mask。

在刚刚的Self-Attention计算中,我们是把Q和K相乘来计算分数的。加入Attention Mask后就会变成这样

再softmax的话就变成实际分数

2.5 向量化理解GPT2的计算
2.5.1 Masked Self-Attention层
在这边有一个计算技巧,从第二个位置开始(忽略
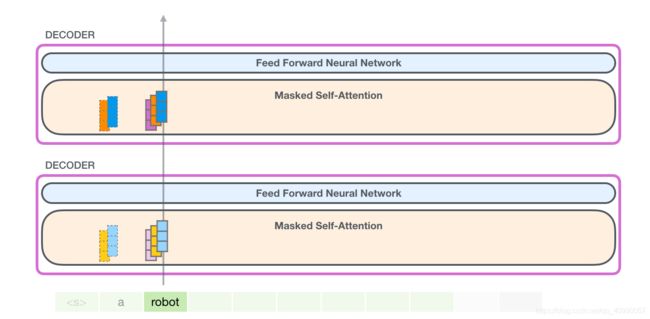
也依然是需要通过三步来完成计算的,我们一一拆解(以当前处理句中it为例)
- 创建Query、Key和Value矩阵
it的embedding+位置编码,再乘以 W Q W_Q WQ, W K W_K WK, W V W_V WV
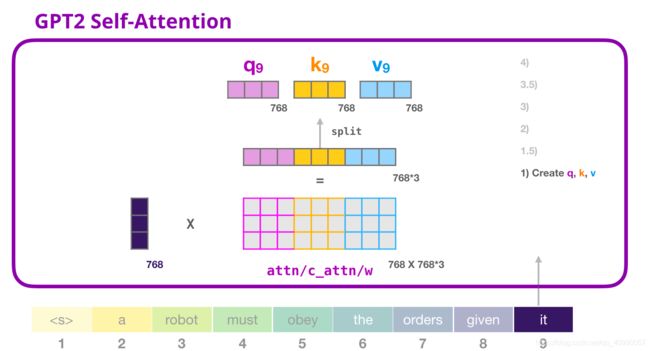
然后分裂成注意力头(head),需要注意的是,Self-attention 在 Q、K、V 向量的不同部分进行了多次计算。拆分 attention heads 只是把一个长向量变为矩阵。小的 GPT-2 有 12 个 attention heads,因此这将是变换后的矩阵的第一个维度。 - 对每一个注意力头,进行评分Score
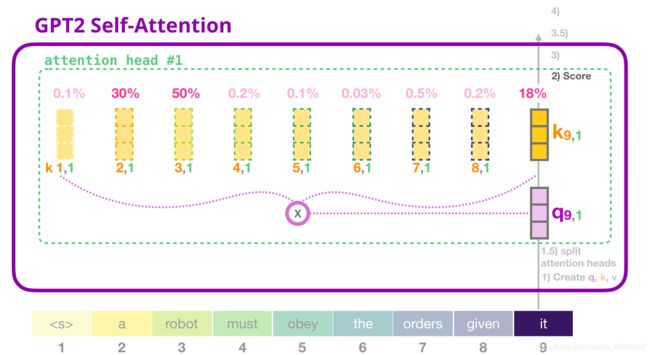
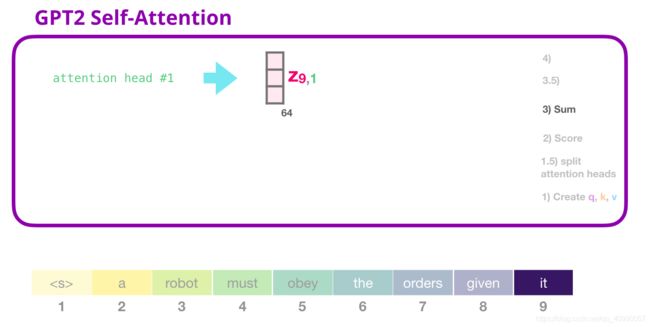
- 求和
对每一个注意力头,都可以完成得到一个注意力结果
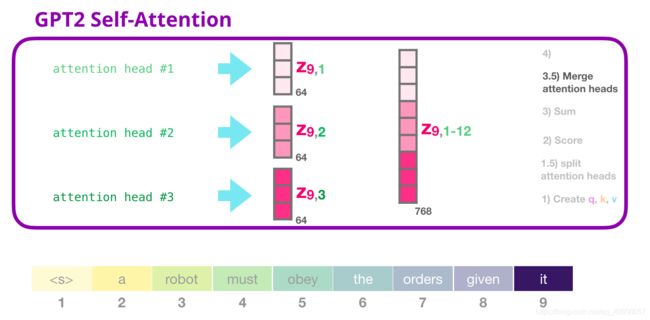
都多个注意力头进行合并
- 进行投影,使得注意力头的结果投影到Self-Attention层的输出向量中
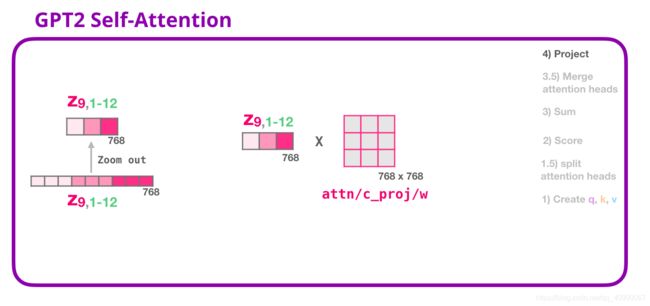
然后就可以输出了
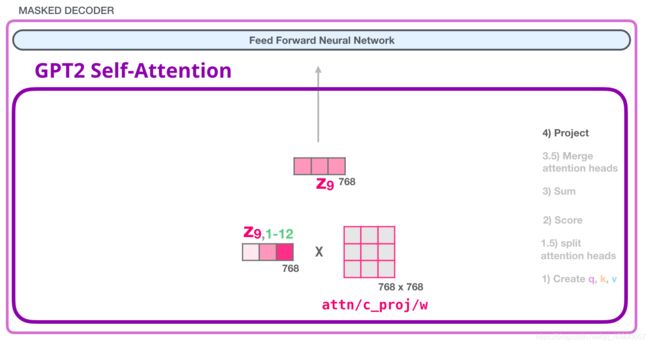
2.5.2 FFNN层
Self-Attention层输出的向量会输入到FFNN(全连接神经网络层),这一层的计算主要分为两步:
- 乘以权重矩阵(其实就是FFNN训练好的weight)需要注意的是,其实FFNN是可以有bias向量的,这里没有展示
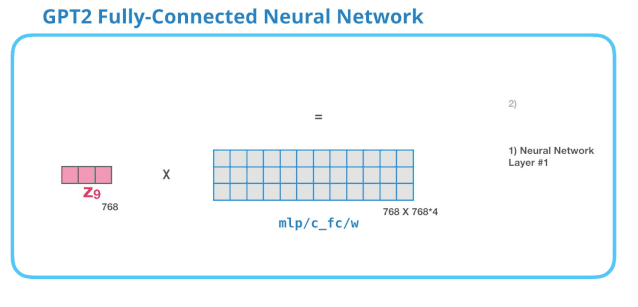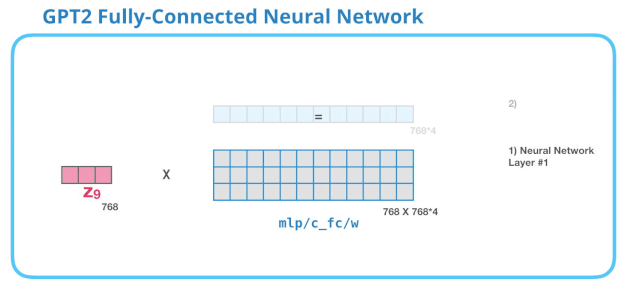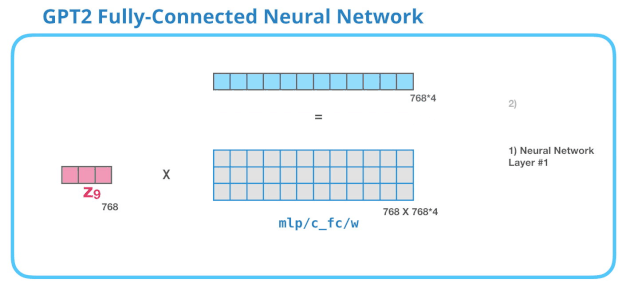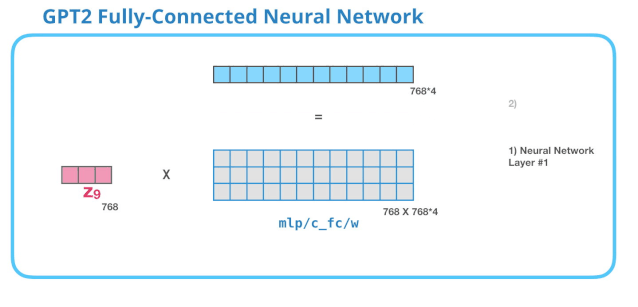
- 再把向量映射回模型的维度(输入的token维度),这个结果就是Transformer对token的输出
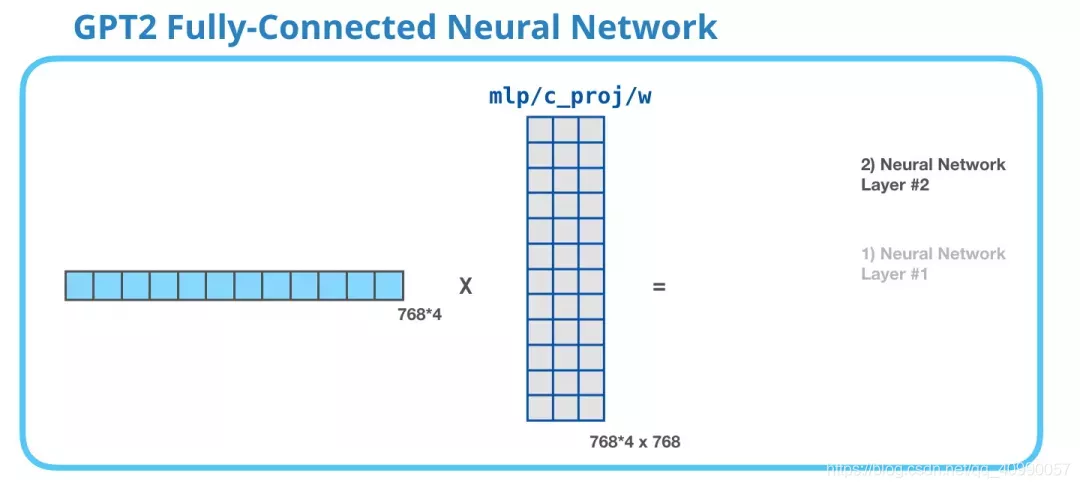
2.5.3 权重矩阵小结
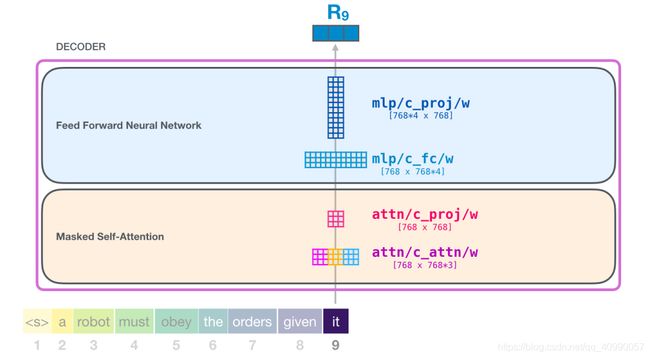
在整个GPT2一个decoder模块的计算中,所涉及到的权重矩阵包括:
- W Q W_Q WQ, W K W_K WK, W V W_V WV
- 注意力头投影到输出向量的矩阵
- 全连接神经网络的权重矩阵
- 全连接神经网络把向量映射到输出维度的矩阵
以GPT2 BASE为例,一个decoder模块所涉及的权重矩阵和其维度如下图所示:
GPT2模型中的每一个decoder模块都有自己的权重矩阵,除此之外,整个模型共用的矩阵有:
- token embedding矩阵
- 位置编码矩阵
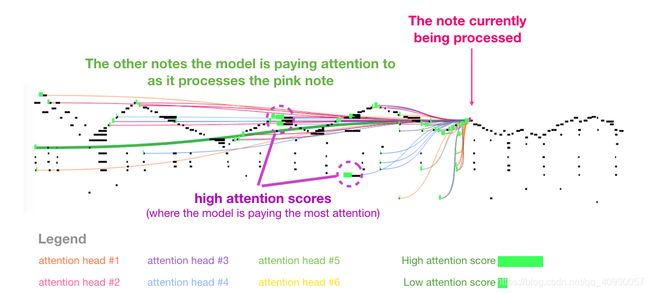
2.6 Transformer Decoder的其他应用
包括:
- 机器翻译:不需encoder,但是Decoder的输出不会作为输入?
- 生成摘要:阅读Wikipedia文章,然后生成摘要,Wikipedia的实际开头部分作为训练数据的标签
- 音乐生成:类似于语言建模,把音符、速度、力度表示为向量(这个图挺酷的,贴一下)
篇章小测
- 问题4: BERT预训练时mask的比例,可以mask更大的比例吗?
BERT预训练时,会mask掉15%的单词,这15%的原始单词作为标签,来训练模型。
如果再多可能会影响到学习准确率?(问题10: BERT训练的时候mask单词的比例可以特别大(大于80%)吗?待补充) - 问题5: BERT如何进行tokenize操作?有什么好处?
tokenize就是分词,BERT中的tokenize用的是基于WordPiece的算法,是子词粒度的方法。(tokenize知识尚缺,待补充) - 问题6: GPT如何进行tokenize操作?和BERT的区别是什么?
(同上) - 问题7: BERT模型特别大,单张GPU训练仅仅只能放入1个batch的时候,怎么训练?
事实上我们一般不会自己训练BERT,由于缺乏实际经验…改TPU可能是最简单粗暴的方法。但是有时候没有TPU,就(待补充) - 问题9: Transformer中的残差网络结构作用是什么?
解决深度学习中的退化问题,也就是防止层数增加导致梯度消失。 - 问题11: BERT预训练是如何做mask的?
每个句子随机挡住 15% 的内容,每个词(在随机选中的15%中)都有10%的概率被随便替换,有80%的概率被 [MASK] 替换。因为如果我们只用特殊占位符 [MASK] 换掉被遮标识,微调的时候特定标识就再也看不到了。 - 问题11: word2vec到BERT改进了什么?
早期的word2vec无法实现上下文信息的融入,ELMo考虑使用LSTM,融入了上下文模型进行语言建模,由于使用的是循环神经网络,所以有长期依赖的问题;后面诞生的Open AI GPT使用了Transformer的Decoder,它解决了长期依赖的问题,但是只能单向获取上文信息;BERT则采用了Transformer的Encoder,使得它可以实现双向语言建模。
参考阅读
- Datawhale教程
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
- NLP语言模型发展史
- 一文读懂BERT
- The Illustrated GPT-2 (Visualizing Transformer Language Models)
- 一文读懂BERT(原理篇)
- 一文读懂BERT(实践篇)