mysql
MySQL安装与使用
基本增删改查SQL语句
SQL查询,SQL函数,复杂查询实现(重点)
MySQL用户与权限管理
数据库建模优化
数据库索引建立
数据库查询优化
SQL编程(自定义函数,存储过程,触发器)
JDBC编程,Java+MySQL实现某管理系统
重置表
SELECT * FROM `emp`;
DELETE FROM `emp`;
insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno)
values(7369,'SMITH','CLERK',7902,'1980-12-17',800,null,20),
(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30),
(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30),
(7566,'JONES','MANAGER',7839,'1981-04-02',2975,null,20),
(7654,'MARTIN','SALESMAN',7698,'1981-08-28',1250,1400,30)
,(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,null,30)
,(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,null,10)
,(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,null,20)
,(7839,'KING','PRESIDENT',null,'1981-11-17',5000,null,10)
,(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30)
,(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,null,20)
,(7900,'JAMES','CLERK',7698,'1987-12-03',950,null,30)
,(7902,'FORD','ANALYST',7566,'1981-03-31',3000,null,20)
,(7934,'MILLER','CLERK',7782,'1982-03-31',1300,null,10);
数据库基础
SQL语言包括数据定义(DDL)、数据操纵(DML),数据控制(DCL)和数据查询(DQL)四个部分
数据库特点:
数据结构化, 数据共享度高,冗余度低,易于扩展; 数据独立性高。
索引的特点
1.可以大大加快数据的查询速度
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
自我引用
语句的书写,语句的用法(参数),语句的使用技巧
DB
数据库(database):存储数据的“仓库”。它保存了一系列有组织的数据。
DBMS
数据库管理系统(Database Management System)。数据库是通过DBMS创 建和操作的容器
SQL
结构化查询语言(Structure Query Language):专门用来与数据库通信的语言。
管家DBA
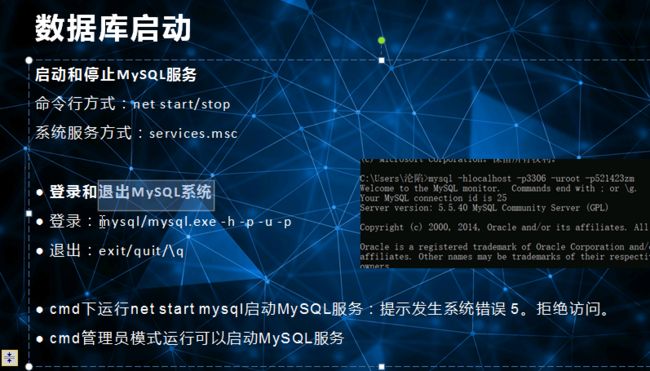
MySQL语法规范
不区分大小写
每句话用;或\g结尾
各子句一般分行写
关键字不能缩写也不能分行
用缩进提高语句的可读性
数据库
创建
创建数据库:create database 数据库名字 [库选项]
create database 数据名库
DEFAULT CHARACTER SET utf8
DEFAULT COLLATE utf8_general_ci;
操作
显示全部:show databases;
匹配部分:show databases like ‘pattern’;
选择数据库:use 数据库名字;
删除
删除数据库 :drop database [name]
表
1.创建
MYSQL的字符集包括字符集(character)和校对规则(collation)两个概念,
字符集:用来定义mysql中存储字符串的方式,
校对规则:用来你定义比较字符串的方式,
服务器级、数据库级、数据表级、字段级。
utf8_bin 将字符串中的每一个字符用二进制数据存储,区分大小写。
utf8_general_ci 不区分大小写,ci是case insensitive的缩写,即一般大小写不敏感。
utf8_general_cs 区分大小写,cs是case sensitive的缩写,即大小写敏感。
1、普通创建表:create table 表名 (字段名 字段类型) [表选项]
ALTER TABLE 表名
CONVERT TO CHARACTER SET utf8
COLLATE utf8_general_ci;
Create table tbl_user (userid varchar(20),username varchar(20),realname varchar(20),age int);
2.复制已有表结构:create table 表名 like 已有表名;
Create table tbl_user1 (userid varchar(20),
username varchar(20),
realnamevarchar(20),
empno int auto_increment //自增,不能为空,值必需唯一
age int)
default charset='utf8'; //默认字符
3.复制已有表结构:create table 表名 like 已有表名;
2.显示
显示所有表:show tables;
显示表结构:desc 表名
显示表创建语句:show create table 表名;
3.修改结构
Insert into 表名[(字段列表)] values(对应字段列表)
Insert into tbl_user(userid,username,realname,age) values('1','admin','jack',10);
#修改
1、修改表名: rename table 旧表名 to 新表名
2、修改字段名: alter table 表名 change 旧字段名 新字段名 字段类型 [列属性] [新位置]
ALTER TABLE emp CHANGE ename empname varchar(30);
3、修改字段类型(属性) alter table 表名 modify 字段名 新类型 [新属性] [新位置]
alter table tbl_emp modify ename varchar(30);
4、修改表选项: alter table 表名 表选项 [=] 新值
#增删
1、新增字段: alter table 表名 add [column] 新字段名 列类型 [列属性] [位置first/after 字段名]
alter table tbl_emp add job varchar(20);
2、删除字段: alter table 表名 drop 字段名
ALTER TABLE tbl_emp DROP COLUMN job;
3.删除表结构: drop table 表名列表;
ALTER TABLE emp DROP COLUMN job;
4.删除数据
Delete from 表名 #删除表中的数据,可以回滚,可以按条件删除部分数据
TRUNCATE TABLE 表名 #删除表中所有的数据,释放表的存储空间,不能回滚。
插入
练习
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
|---|---|---|---|---|
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
| INT | 使用4个字节保存整数数据 |
|---|---|
| CHAR(size) | 定长字符数据。若未指定,默认为1个字符,最大长度255 |
| VARCHAR(size) | 可变长字符数据,根据字符串实际长度保存,必须指定长度 |
| FLOAT(M,D) | 单精度,M=整数位+小数位,D=小数位。 D<=M<=255,0<=D<=30,默认M+D<=6 |
| DOUBLE(M,D) | 双精度。D<=M<=255,0<=D<=30,默认M+D<=15 |
| DATE | 日期型数据,格式’YYYY-MM-DD’ |
| BLOB | 二进制形式的长文本数据,最大可达4G |
| TEXT | 长文本数据,最大可达4G |
1、创建一个名称为mydb1的数据库
2、创建一个使用utf8字符集的mydb2数据库
3、创建一个使用utf8字符集,并带比较规则的mydb3数据库。
4.修改mydb2字符集为gbk;
5.删除数据库mydb3。
6.查看所有数据库。
7.查看数据库mydb1的字符集
SELECT COUNT( *) FROM `emp` ;
不能出现在where中,表中没有数据
SELECT avg(`SAL`)平均工资, MAX(`SAL`)最高工资, MIN(`SAL`)最低工资, SUM(`SAL`) 最高工资 FROM `emp` ;
SELECT * FROM `emp`;
//最大最小值
SELECT MIN(HIREDATE) MAX(HIREDATE) FROM `emp` ;
SELECT avg(sal),DEPTNO FROM `emp` GROUP BY `DEPTNO` ;
找出部门为cleark的平均工资
SELECT avg(sal),DEPTNO,job
FROM `emp` WHERE `JOB` ='CLERK'GROUP BY `DEPTNO`,`JOB` ;
SELECT avg(sal),DEPTNO,job
FROM `emp` WHERE `JOB` ='CLERK'GROUP BY `DEPTNO` ;
SELECT avg(sal),DEPTNO,job
FROM `emp` WHERE `JOB` ='CLERK'GROUP BY `JOB` ; //错误
//部门平均工资大于2000的
SELECT avg(sal),DEPTNO FROM `emp` GROUP BY `DEPTNO` ;
SELECT avg(sal),DEPTNO FROM `emp` GROUP BY `DEPTNO` HAVING avg(sal)>2000;
SELECT COUNT(*) FROM `emp`;
SELECT COUNT( `EMPNO`) FROM `emp`;
//只统计comm不为空的值
SELECT COUNT(comm) FROM `emp`;
4.增删改
增
INSERT INTO table [(column [, column...])] VALUES (value [, value...]);
#字符和日期型数据应包含在单引号中。
#三种方式
1.按列的默认顺序列出各个列的值。
insert into emp values(7782,'小王','架构师',null,'1999-10-22',9999,100,null);
2.在 INSERT 子句中随意列出列名和他们的值。
Insert into emp
(empno,ename,job,hiredate) values(7788,'Scott','开发工程师','2021-12-14');
3.多行插入
Insert into emp
(empno,ename,job,hiredate)
values (7780,'Jerry','开发工程师','2021-12-14'),
(7781,'张某某','测试员','2021-12-11'),
(7782,'李子','测试员','2021-12-11');
、
删
DELETE FROM table [WHERE condition];
1.删除员工号为7781的员工信息
Delete from emp where empno=7781;
2.删除没有工资的员工 当列中的值为空时 可以用is null表示空
Delete from emp where sal is null;
、
改
UPDATE table SET column = value [, column = value, ...][WHERE condition];
1.把表中的所有数据的部门号更新为20
Update emp set deptno=20;
2 把员工编号为7780的工资修改为99999
Update emp set sal=99999 where empno=7780
、
#子性:
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
#一致性:
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
#隔离性:
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
#持久性:
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
数据查询
1.基本查询
SELECT *|{[DISTINCT] column|expression [alias],...}FROM table;
1.所有
2.指定
# ‘AS’,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写
select empno as 员工编号,ename 姓名,job 岗位 from emp
结构
DESCRIBE emp==desc;
SELECT *|{[DISTINCT] column|expression [alias],...} FROM table [WHERE condition(s)];
关系运算
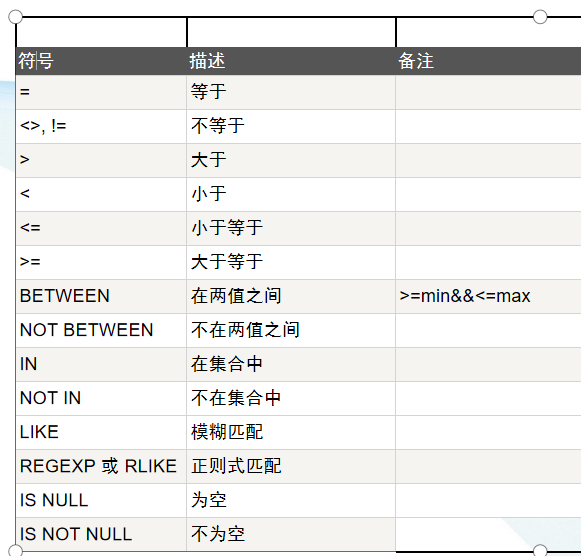
运算

逻辑
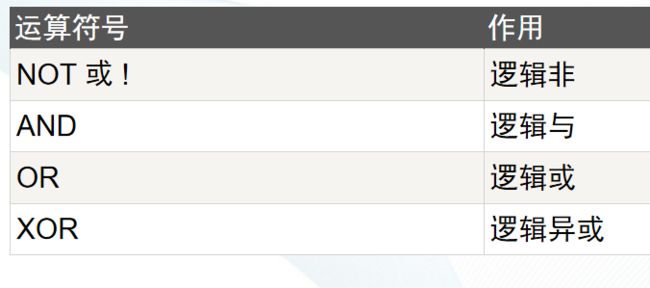
优先级
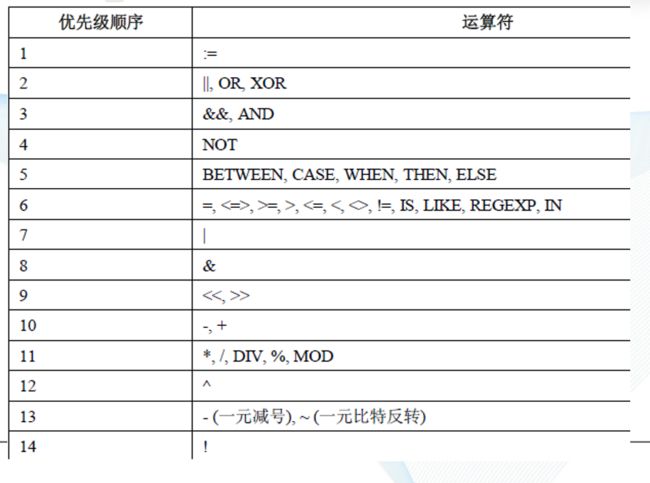
2.排序
select * from emp order by sal [ASC / DESC];
1.可以别名排序
SELECT employee_id, last_name, salary*12 #annsal
FROM employees
ORDER BY #annsal;
2.多个列排序
SELECT ename, deptno, FROM emp
ORDER BY deptno,sal DESC;
ASC(ascend): 升序
DESC(descend): 降序
3 .数据分组
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column];
AVG()
COUNT()
MAX()
MIN()
SUM()
#不能在 WHERE 子句中使用组函数。
#可以在 HAVING 子句中使用组函数。
SELECT max(sal),deptno FROM emp
group by deptno
#having max(sal)>4000;
1.在 GROUP BY子句中包含多个列 #不是特别懂
SELECT avg(sal),deptno,job FROM emp
group by deptno,job order by deptno
2.使用 HAVING 过滤分组:
1. 行已经被分组。
2. 使用了组函数。
3. 满足HAVING 子句中条件的分组将被显示。
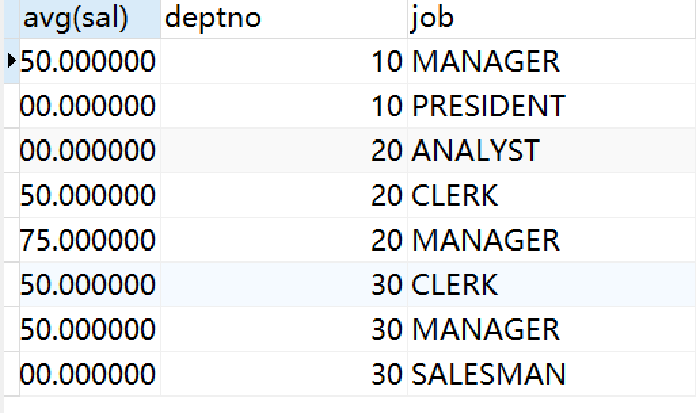
SELECT avg(sal),deptno,job FROM emp
group by deptno,job order by deptno
5.单行函数
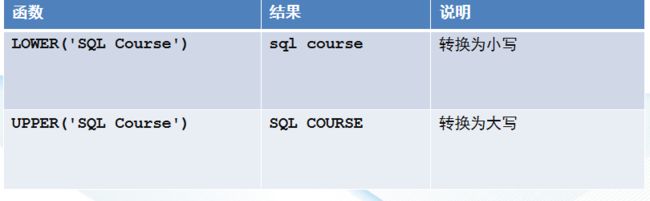
字符控制函数
| LOWER(‘SQL Course’) | sql course | 转换为小写 |
|---|---|---|
| UPPER(‘SQL Course’) | SQL COURSE | 转换为大写 |
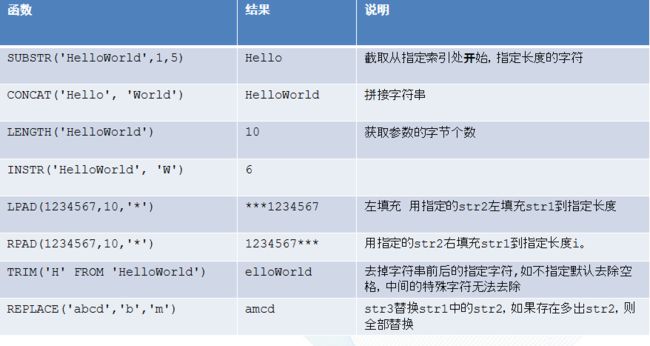
| SUBSTR(‘HelloWorld’,1,5) | Hello | 截取从指定索引处开始,指定长度的字符 |
|---|---|---|
| CONCAT(‘Hello’, ‘World’) | HelloWorld | 拼接字符串 |
| LENGTH(‘HelloWorld’) | 10 | 获取参数的字节个数 |
| INSTR(‘HelloWorld’, ‘W’) | 6 | |
| LPAD(1234567,10,’*’) | ***1234567 | 左填充 用指定的str2左填充str1到指定长度 |
| RPAD(1234567,10,’*’) | 1234567*** | 用指定的str2右填充str1到指定长度i。 |
| TRIM(‘H’ FROM ‘HelloWorld’) | elloWorld | 去掉字符串前后的指定字符,如不指定默认去除空格,中间的特殊字符无法去除 |
| REPLACE(‘abcd’,‘b’,‘m’) | amcd | str3替换str1中的str2,如果存在多出str2,则全部替换 |
#大小写
SELECT lower('HELLO WORLD');
SELECT upper('hello');
SELECT FROM `emp` ;
#
SELECT concat('Hello','world');
SELECT substr('helloword',1,5);
#长度
SELECT * FROM emp WHERE LENGTH (ename);
SELECT * FROM emp WHERE `ENAME` LIKE '_____';
#代替
SELECT instar('123456','3');
#添加列
SELECT TABLE emp` add phone VARCHAR(20);
#重置列属性
ALTER TABLE `emp` modify COLUMN phone VARCHAR (50);
数学函数
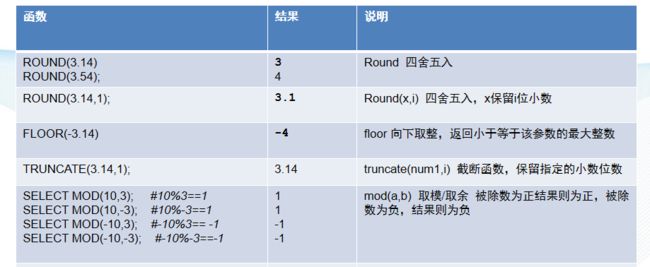
| 函数 | 结果 | 说明 |
|---|---|---|
| ROUND(3.14)ROUND(3.54); | 34 | Round 四舍五入 |
| ROUND(3.14,1); | 3.1 | Round(x,i) 四舍五入,x保留i位小数 |
| FLOOR(-3.14) | -4 | floor 向下取整,返回小于等于该参数的最大整数 |
| TRUNCATE(3.14,1); | 3.1 | truncate(num1,i) 截断函数,保留指定的小数位数 |
| SELECT MOD(10,3); #10%3==1 SELECT MOD(10,-3); #10%-3==1SELECT MOD(-10,3); #-10%3== -1SELECT MOD(-10,-3); #-10%-3==-1 | 11-1-1 | mod(a,b) 取模/取余 被除数为正结果则为正,被除数为负,结果则为负 |
SELECT round(3.1415926,3);//四舍五入保留位数
#整数
SELECT floor(3.14);#4
SELECT floor(-3.14);#-4
SELECT ceil(3.14);
#截取
SELECT TRUNCATE(3.14,1);
#随机
SELECT rand();
SELECT length(rand());
0-10
SELECT TRUNCATE (rand()*10,0);
10-100
SELECT TRUNCATE (rand()*100,0)+10;
日期函数
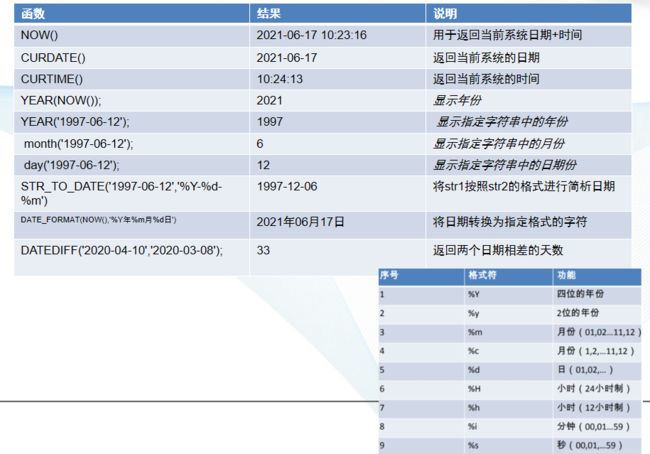
日期函数
| *函数* | *结果* | *说明* |
|---|---|---|
| NOW() | 2021-06-17 10:23:16 | 用于返回当前系统日期+时间 |
| CURDATE() | 2021-06-17 | 返回当前系统的日期 |
| CURTIME() | 10:24:13 | 返回当前系统的时间 |
| YEAR(NOW()); | 2021 | 显示年份 |
| YEAR(‘1997-06-12’); | 1997 | 显示指定字符串中的年份 |
| month(‘1997-06-12’); | 6 | 显示指定字符串中的月份 |
| day(‘1997-06-12’); | 12 | 显示指定字符串中的日期份 |
| STR_TO_DATE(‘1997-06-12’,’%Y-%d-%m’) | 12/06/1997 | 将str1按照str2的格式进行简析日期 |
| DATE_FORMAT(NOW(),’%Y年%m月%d日’) | 2021年06月17日 | 将日期转换为指定格式的字符 |
| DATEDIFF(‘2020-04-10’,‘2020-03-08’); | 33 | 返回两个日期相差的天数 |
| ADDDATE(d,n) | 计算起始日期 d 加上 n 天的日期 | |
| ADDTIME(t,n) | n 是一个时间表达式,时间 t 加上时间表达式 n | |
| DATE_ADD(d,INTERVAL expr type) | 计算起始日期 d 加上一个时间段后的日期 d 参数是合法的日期表达式。expr 参数是您希望添加的时间间隔。Type: | |
| DAYOFMONTH(d) | 计算日期 d 是本月的第几天 | |
| DAYOFWEEK(d) | 日期 d 今天是星期几,1 星期日,2 星期一,以此类推 | |
| DAYOFYEAR(d) | 计算日期 d 是本年的第几天 |
SELECT * FROM `emp` ;
INSERT INTO `emp`( `EMPNO` , `ENAME` , `HIREDATE` )value(9999,'test',now());
SELECT YEAR (now());
#输出年
SELECT `EMPNO` , `ENAME`, `JOB` , `MGR` , year(`HIREDATE`) , `SAL` , `COMM` , `DEPTNO`
FROM `emp`;
#按年查找
SELECT `EMPNO` , `ENAME`, `JOB` , `MGR` ,`HIREDATE` , `SAL` , `COMM` , `DEPTNO`
FROM `emp` WHERE year(HIREDATE)=1981;
#将str1按照str2的格式进行简析日期
SELECT STR_TO_DATE('1999/06/12','%Y/%m/%d');
//SELECT STR_TO_DATE(HIREDATE,'%Y/%m/%d') FROM `emp` ;
SELECT STR_TO_DATE('1990年06月12日','%Y年%m月%d日');
INSERT INTO `emp`( `EMPNO` , `ENAME` , `HIREDATE` )value
(9998,'test',STR_TO_DATE('1990年06月12日','%Y年%m月%d日'));
#时间差
SELECT DATE_FORMAT(now(),'%Y年');
SELECT datediff(now(),'2001/03/15');
SELECT datediff(CURDATE(),'2001/03/15');
SELECT datediff('2101/03/15','2001/03/15');
SELECT `EMPNO` ,datediff(curdate(),`HIREDATE`) , `HIREDATE` FROM `emp`;
获得日期
加2天
SELECT adddate(now(),2);
SELECT date_add(NOW(), interval 2 month) ;
SELECT date_add(NOW(), interval 31 day) ;
SELECT date_add(NOW(), interval -31 day) ;
#下个月1号-1;
##加一个月
SELECT date_add(NOW(), interval 1 month);
##转换格式,保存年月,日为1号
SELECT DATE_FORMAT(date_add(NOW(), interval 1 month),'%Y-%m-01');
##减1天
SELECT date_add(DATE_FORMAT(date_add(NOW(), interval 1 month),'%Y-%m-01'),interval -1 day );
###得到确定的日期基准(格式)再用data_add();
#一年的第多少天
SELECT dayofyear(now());
其他函数
if函数
if(expr1,expr2,expr3) 表达式expr1返回true,显示expr2,否则显示expr3
if(条件,ture,flase);
#md5加密
SELECT md5('jiansheyin1');//38da712bf597d8a92b6d84779789a6e3;
SELECT `EMPNO` , `ENAME`, `JOB` , `MGR` ,`HIREDATE` , `SAL`,IF(comm IS NOT NULL,'有奖金','没有奖金') AS 奖金 , `COMM` , `DEPTNO`
FROM `emp` ;
练习
SELECT round(3.1415926,3);//四舍五入保留位数
//qu
SELECT floor(3.14);
SELECT floor(-3.14);
SELECT ceil(3.14);
SELECT TRUNCATE(3.14,1);
//随机
SELECT rand();
SELECT length(rand());
0-10
SELECT TRUNCATE (rand()*10,0);
10-100
SELECT TRUNCATE (rand()*100,0)+10;
SELECT * FROM `emp` ;
INSERT INTO `emp`( `EMPNO` , `ENAME` , `HIREDATE` )value(9999,'test',now());
SELECT YEAR (now());
输出年
SELECT `EMPNO` , `ENAME`, `JOB` , `MGR` , year(`HIREDATE`) , `SAL` , `COMM` , `DEPTNO`
FROM `emp`;
按年查找
SELECT `EMPNO` , `ENAME`, `JOB` , `MGR` ,`HIREDATE` , `SAL` , `COMM` , `DEPTNO`
FROM `emp` WHERE year(HIREDATE)=1981;
将str1按照str2的格式进行简析日期
SELECT STR_TO_DATE('1999/06/12','%Y/%m/%d');
//SELECT STR_TO_DATE(HIREDATE,'%Y/%m/%d') FROM `emp` ;
SELECT STR_TO_DATE('1990年06月12日','%Y年/%m月/%d日');//
INSERT INTO `emp`( `EMPNO` , `ENAME` , `HIREDATE` )
value (9995,'test',str_to_date('1991年06月12日','%Y年/%m月/%d日'));//
insert into emp(empno, ename, hiredate)
values(9993, 'test', str_to_date('1998年06月12号', '%Y年%m月%d号')) ;
时间差
SELECT DATE_FORMAT(now(),'%Y年');
SELECT datediff(now(),'2001/03/15');
SELECT datediff(CURDATE(),'2001/03/15');
SELECT datediff('2101/03/15','2001/03/15');
SELECT `EMPNO` ,datediff(curdate(),`HIREDATE`) , `HIREDATE` FROM `emp`;
获得日期
2天
SELECT adddate(now(),2);
SELECT date_add(NOW(), interval 2 month) ;
SELECT date_add(NOW(), interval 31 day) ;
SELECT date_add(NOW(), interval -31 day) ;
----下个月1号-1;
加一个月
SELECT date_add(NOW(), interval 1 month);
转换格式
SELECT DATE_FORMAT(date_add(NOW(), interval 1 month),'%Y-%m-01');
SELECT date_add(DATE_FORMAT(date_add(NOW(), interval 1 month),'%Y-%m-01'),interval -1 day );
//得到确定的日期基准(格式)再用data_add();
----一年多少天
SELECT dayofyear(now());
-------md5加密
SELECT md5('jiansheyin1');//38da712bf597d8a92b6d84779789a6e3;
SELECT `EMPNO` , `ENAME`, `JOB` , `MGR` ,`HIREDATE` , `SAL`,IF(comm IS NOT NULL,'有奖金','没有奖金') AS 奖金 , `COMM` , `DEPTNO`
FROM `emp` ;
1.将emp表的入职日期以yyyy/MM/dd的格式显示
SELECT `EMPNO` , `ENAME`, `JOB` , `MGR` ,
date_format(`HIREDATE`,'%Y/%m/%d') ,
`SAL`, `COMM` , `DEPTNO`
FROM `emp` ;
2.获得当前日期+11个月后的日期,并以yyyy-MM-dd hh24:mi:ss格式显示
SELECT DATE_add(now(),interval 11 month);
3.获得上个月最后一天的日期 并以yyyy-MM-dd hh24:mi:ss格式显示
SELECT DATE_FORMAT(now(),'%Y-%m-01');//
SELECT DATE_add( DATE_FORMAT(now(),'%Y-%m-01 %H:%i:%s'),interval -1 day);
4.获得上个月第一天的日期 并以yyyy-MM-dd hh24:mi:ss格式显示
SELECT DATE_add( DATE_FORMAT(now(),'%Y-%m-01 %H:%i:%s'),interval -1 month);
5.假定入职日期为出生日期计算出该员工在2021年还有多久过生日
SELECT DATE_FORMAT(now(),'%m-%d');
SELECT DATE_FORMAT(HIREDATE,'%m-%d') FROM `emp` ;
SELECT datediff( DATE_FORMAT(HIREDATE,'%m-%d'),DATE_FORMAT(now(),'%m-%d')) ,
`HIREDATE` FROM `emp` ;
6.编写sql,假定入职日期为出生日期计算出该员工在2021年还有多久过生日如果生日已过,显示”生日已过”,否则 “还有N天过生日”
SELECT if(datediff(DATE_format( `HIREDATE`,'2021-%m-%d'), now() )<0,'生日以过',
concat('生日还有',datediff(DATE_format( `HIREDATE`,'2021-%m-%d'), now() ),'天')) FROM `emp` ;
7.用update语句将emp表中的所有员工姓名首字母改为大写,其它字母改为小写
SELECT * FROM `emp` ;
UPDATE `emp` SET `ENAME` = lower(ENAME) WHERE Mgr =7902;
UPDATE `emp` SET `ENAME` = concat(upper(substr('smith',1,1)), lower(substr('smith',2,6))) WHERE Mgr =7902;
SELECT substr(`ENAME`,2,LENGTH(`ENAME`) ) FROM `emp` ;
substr(`ENAME`,2,LENGTH(`ENAME`)
——————————LENGTH(`ENAME`)
UPDATE `emp` SET `ENAME` = concat(upper(substr(`ENAME`,1,1)), lower(substr(`ENAME`,2,LENGTH(`ENAME`) ))) ;
——————————substr(`ENAME`,2)
UPDATE `emp` SET `ENAME` = concat(upper(substr(`ENAME`,1,1)), lower(substr(`ENAME`,2))) ;
8.用select语句查询emp表,员工姓名只显示首字母,其它字母用****代替
SELECT RPAD(substr(`ENAME` ,1,1),length(`ENAME`),'*') FROM `emp` ;
9.显示emp表每个员工的奖金,没有奖金的(为null)的显示为0
SELECT if(`COMM` IS NULL,'0', `COMM` ) FROM `emp` ;
10.显示emp表员工名及员工名的长度
SELECT `ENAME` ,length( `ENAME`) FROM `emp` ;
11.用update语句将scott的入职日期增加两个月
SELECT `HIREDATE` FROM `emp` WHERE `ENAME` ='scott';
UPDATE `emp` SET `HIREDATE` = DATE_ADD(`HIREDATE`, INTERVAL -2 month)
WHERE `ENAME` ='scott';
12 显示emp表员工表每个员工的年薪。(工资+奖金)*12
//数值型不要为空
SELECT (sal+if(`COMM` is null,0, COMM) )*12, `SAL` , `COMM` FROM `emp` ;
SELECT * FROM `emp`;
DELETE FROM `emp`;
insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno)
values(7369,'SMITH','CLERK',7902,'1980-12-17',800,null,20),
(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30),
(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30),
(7566,'JONES','MANAGER',7839,'1981-04-02',2975,null,20),
(7654,'MARTIN','SALESMAN',7698,'1981-08-28',1250,1400,30)
,(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,null,30)
,(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,null,10)
,(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,null,20)
,(7839,'KING','PRESIDENT',null,'1981-11-17',5000,null,10)
,(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30)
,(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,null,20)
,(7900,'JAMES','CLERK',7698,'1987-12-03',950,null,30)
,(7902,'FORD','ANALYST',7566,'1981-03-31',3000,null,20)
,(7934,'MILLER','CLERK',7782,'1982-03-31',1300,null,10);
练习
SELECT *
FROM `emp`;
1.求员表中所有员工的平均工资,最高工资,最低工资,工资总和员工人数
SELECT avg(`SAL`) 平均工资, MAX(`SAL`) 最高工资, MIN(`SAL`) 最低工资, SUM(`SAL`) 最高工资, COUNT(*) 员工人数
FROM `emp`;
2.求员表各个部门的平均工资,最高工资,最低工资,工资总和员工人数
SELECT avg(`SAL`) 平均工资, MAX(`SAL`) 最高工资, MIN(`SAL`) 最低工资, SUM(`SAL`) 最高工资, COUNT(*) 员工人数
FROM `emp`
GROUP BY `DEPTNO`;
3.求各岗位的最高工资,显示岗位名称和最高工资
SELECT MAX(`SAL`) 最高工资, JOB
FROM `emp`
GROUP BY `JOB`;
4.求各部门的平均工资,显示平均工资和部门号
SELECT avg(`SAL`) 平均工资, `DEPTNO` 部门号
FROM `emp`
GROUP BY `DEPTNO`;
5.求各部门平均工资,且平均工资低于2000的部门信息
SELECT *, avg(`SAL`) 平均工资
FROM `emp`
GROUP BY `DEPTNO`
HAVING avg(`SAL`) < 2000;
//
//部门平均工资大于2000的
SELECT avg(sal), DEPTNO
FROM `emp`
GROUP BY `DEPTNO`;
SELECT avg(sal), DEPTNO
FROM `emp`
GROUP BY `DEPTNO`
HAVING avg(sal) > 2000;
SELECT COUNT(*)
FROM `emp`;
//部门数
SELECT COUNT(`EMPNO`)
FROM `emp`;
//只统计comm不为空的值
6.求各部门的员工人数,显示人数和部门号
SELECT COUNT(*), DEPTNO
FROM `emp`
GROUP BY `DEPTNO`;
7.求各部门中奖金为null的员工人数,显示人数和部门号
SELECT COUNT(*) - COUNT(comm), `DEPTNO`
FROM `emp`
GROUP BY `DEPTNO`;
8.找出工资大于的1000 的各部门的员工的平均工资,部门号(即工资小于等于等1000的员工不参与分组)
SELECT avg(`SAL`), `DEPTNO`
FROM `emp`
WHERE `SAL` >= 1000
GROUP BY `DEPTNO`;
9.统计有奖金的员工人数 只统计comm列值不为空
SELECT COUNT(`EMPNO`)
FROM `emp`;
10.统计没有奖金的员工人数
SELECT COUNT(*) - COUNT(comm), `DEPTNO`
FROM `emp`;
多表查询
连接
基本连接
使用连接在多个表中查询数据。
#笛卡尔积连接,(where的判断)
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2;
SELECT * FROM `dept` ;
SELECT * FROM `emp` ;
SELECT * FROM `dept`;
SELECT * FROM `salgrade` ;
SELECT * FROM emp,dept WHERE emp.DEPTNO = dept.DEPTNO;
, `grade`
SELECT ename , `SAL` , `COMM` , `JOB` , `emp`.`emp`.`DEPTNO` FROM `emp`
INNER JOIN `dept` ON emp.`DEPTNO` = `dept`.`DEPTNO` ;
INNER JOIN `salgrade` ON sal BETWEEN `losal` AND `hisal`
WHERE `emp`.`DEPTNO` =20;
INSERT INTO `emp`( `EMPNO` , `ENAME` , `JOB` , `HIREDATE` , `SAL`)
VALUE ('9999','test','clark',now(),8888);
SELECT `EMPNO` , `ENAME` , `JOB` , `HIREDATE` , `SAL` FROM `emp`
LEFT JOIN `dept` ON `emp` .`DEPTNO` = `dept`.`DEPTNO` ;
SELECT e.`EMPNO` , e.`ENAME` , e.`JOB` ,e.`MGR` , m.`ENAME` 上级名称 FROM `emp` e
LEFT JOIN `emp` m ON e.`MGR` = m.`EMPNO` ;
表的别名
内连接
SELECT table1.column, table2.column
FROM table_1 [inner] join table_2
ON table1.column1 = table2.column2;
外连接
数据不满足条件,也希望出现在检索结果中,
SELECT table1.column, table2.column
FROM table_1 LEFT|RIGHT join table_2
ON table1.column1 = table2.column2;
练习
1. 显示部门号为20的部门名称、雇员名、入职日期和工资
SELECT dname, loc, `HIREDATE` , `ENAME` `SAL` FROM `emp` INNER JOIN `dept` on `emp`.`DEPTNO` = `dept`.`DEPTNO`
WHERE emp.`DEPTNO` = 20;
2. 显示各个员工的姓名、工资及其工资的级别
//迪卡尔集;
select * from emp e,salgrade s where e.sal>=s.losal and e.sal<=s.hisal;
//迪卡尔集,between;
select e.ename,e.job,e.sal,s.grade,s.losal,s.hisal from emp e,salgrade s
where e.sal between s.losal and s.hisal;
//
SELECT ename, sal,grade FROM `emp` INNER JOIN `salgrade` ON sal BETWEEN `losal` and `hisal` ;
3.显示部门号为20的部门名称、雇员名、入职日期和工资,并按工资升序排序
SELECT dname, `ENAME`, `HIREDATE` , emp.`SAL` FROM `emp` INNER JOIN `dept` on `emp`.`DEPTNO` = `dept`.`DEPTNO`
WHERE `emp`.`DEPTNO` = 20 ORDER BY emp.`SAL` ASC ;
4.显示部门号为20,或雇员名为KING的雇员的部门名称、雇员名、入职日期和工资
SELECT dname, `ENAME`, `HIREDATE` , emp.`SAL` FROM `emp` INNER JOIN `dept` on `emp`.`DEPTNO` = `dept`.`DEPTNO`
WHERE `emp`.`DEPTNO` = 20 or `emp`.`ENAME` ='KING';
5.显示所有员工上级主管的姓名,没有上级主管的则上级主管列值显示为
“无” (左外连接)
SELECT e.`EMPNO` , e.`ENAME` , e.`JOB` ,e.`MGR` ,if(e.`MGR` IS NOT NULL , m.`ENAME` ,'无') 上级名称 FROM `emp` e
LEFT JOIN `emp` m ON e.`MGR` = m.`EMPNO` ;
6.显示所有员工的信息和该员工对应的部门名称,没有部门的员工部门名称以空值填充(左外连接)
SELECT e.`EMPNO` , e.`ENAME` , e.`JOB` ,e.`MGR` , if(`DNAME` IS NULL ,' ', `DNAME` ) FROM `emp` e
LEFT JOIN `dept` d ON e.`DEPTNO` = d.`DEPTNO` ;
7.显示雇员名、雇员编号和部门名称,没有员工的部门名称也需要显示。
SELECT e.`ENAME` ,e.`EMPNO` ,`DNAME` FROM `emp` e
RIGHT JOIN `dept` d ON e.`DEPTNO` = d.`DEPTNO` ;
8.显示所有部门和雇员的详细信息,没有对应部门的员工或没有员工的部门也需要显示。(全外连接)
SELECT e.`ENAME` ,e.`EMPNO` ,`DNAME` FROM `emp` e
RIGHT JOIN `dept` d ON e.`DEPTNO` = d.`DEPTNO` ;
IF-THEN-ELSE
8.子查询
单行子查询
返回多种数据类型和一种类型多个条数
select * from emp where sal>3000;
select * from emp where ename='SCOTT';
/*子查询有可能返回 多行数据,也可能只返回 一行数据,也有一行数据都没有*/
select * from emp where sal>(select sal from emp where ename='SCOTT')
#非法使用子查询
select * from emp where sal>(select sal from emp where deptno=10)
/*找出与10号部门岗位相同的其它部门员工信息*/
select * from emp where deptno!=10 and
job in (select job from emp where deptno=10);
/*其它部门中比10号部门任一工资低的员工信息 10;
##最大值
SELECT * FROM emp WHERE sal<(SELECT max(sal) FROM emp WHERE deptno=10) AND deptno<> 10;
/*返回其它部门比10号部门 所有工资都低的员工信息 sal 10;
SELECT * FROM emp WHERE sal<(SELECT min(sal) FROM emp WHERE deptno=10) AND deptno<> 10;
select * from emp;
/*
找出没有下属性的员工
*/
#有空值的情况
#################################
SELECT *FROM emp WHERE empno NOT IN
(SELECT mgr FROM emp where mgr is not null);
#################################
/*子查询 把某个select查询 结果当做一个结果集(表) 与其它表做关联查询(多表、内连接,外连接)
语法:
select * from 表名A,(查询语句) 别名 B where a.xxx=b.xx
找出各部门的员工的平均工资,及部门名称*/
#嵌套查询
select * from dept,(select avg(sal),deptno from emp group by deptno) temp
where dept.deptno=temp.deptno;
/**/
select * from dept inner join (select avg(sal),deptno from emp group by deptno) temp
on dept.deptno=temp.deptno;
,,
多行子查询
练习
数据表
--1.学生表 Student(SId,Sname,Sage,Ssex)
--SId 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别
--2.课程表 Course(CId,Cname,TId) --CId 课程编号,Cname 课程名称,TId 教师编号
--3.教师表 Teacher(TId,Tname) --TId 教师编号,Tname 教师姓名
--4.成绩表 SC(SId,CId,score) --SId 学生编号,CId 课程编号,score 分数
CREATE table Students(
SId DECIMAL(2,0) PRIMARY key ,
Sname VARCHAR (10),
Sage date,
Ssex varchar(10)
) ;
drop table students;
创建测试数据
SELECT * FROM `emp` ;
学生表 Student
create table Student(SId varchar(10),Sname varchar(10),Sage datetime,Ssex varchar(10));
insert into Student values('01' , '赵雷' , '1990-01-01' , '男');
insert into Student values('02' , '钱电' , '1990-12-21' , '男');
insert into Student values('03' , '孙风' , '1990-05-20' , '男');
insert into Student values('04' , '李云' , '1990-08-06' , '男');
insert into Student values('05' , '周梅' , '1991-12-01' , '女');
insert into Student values('06' , '吴兰' , '1992-03-01' , '女');
insert into Student values('07' , '郑竹' , '1989-07-01' , '女');
insert into Student values('09' , '张三' , '2017-12-20' , '女');
insert into Student values('10' , '李四' , '2017-12-25' , '女');
insert into Student values('11' , '李四' , '2017-12-30' , '女');
insert into Student values('12' , '赵六' , '2017-01-01' , '女');
insert into Student values('13' , '孙七' , '2018-01-01' , '女');
科目表 Course
create table Course(CId varchar(10),Cname nvarchar(10),TId varchar(10))
insert into Course values('01' , '语文' , '02');
insert into Course values('02' , '数学' , '01');
insert into Course values('03' , '英语' , '03');
drop table `teacher` ;
教师表 Teacher
create table Teacher(TId varchar(10),Tname varchar(10))
insert into Teacher values('01' , '张三');
insert into Teacher values('02' , '李四');
insert into Teacher values('03' , '王五');
成绩表 SC
create table SC(SId varchar(10),CId varchar(10),score decimal(18,1))
insert into SC values('01' , '01' , 80);
insert into SC values('01' , '02' , 90);
insert into SC values('01' , '03' , 99);
insert into SC values('02' , '01' , 70);
insert into SC values('02' , '02' , 60);
insert into SC values('02' , '03' , 80);
insert into SC values('03' , '01' , 80);
insert into SC values('03' , '02' , 80);
insert into SC values('03' , '03' , 80);
insert into SC values('04' , '01' , 50);
insert into SC values('04' , '02' , 30);
insert into SC values('04' , '03' , 20);
insert into SC values('05' , '01' , 76);
insert into SC values('05' , '02' , 87);
insert into SC values('06' , '01' , 31);
insert into SC values('06' , '03' , 34);
insert into SC values('07' , '02' , 89);
insert into SC values('07' , '03' , 98);
练习题目
SELECT * FROM sc;
SELECT * FROM student st INNER JOIN sc s WHERE st.SId=s.SId;
#1.查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
#笛卡尔集
SELECT * FROM sc s1 INNER JOIN sc s2 on s1.`SId` = s2.`SId`
WHERE s1.`CId` = '01'and s2.`CId` ='02' and
s1.`score` >s2.`score` ;
#1.1 查询同时存在" 01 "课程和" 02 "课程的情况
SELECT * FROM sc s1 INNER JOIN sc s2 on s1.`SId` = s2.`SId`
WHERE s1.`CId` = '01'and s2.`CId` ='02' ;
1.2 查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
SELECT * FROM
(SELECT s1.`SId` ,s1.`CId` ,s2.`CId` FROM sc s1 INNER JOIN sc s2 on s1.`SId` = s2.`SId`
WHERE s1.`CId` = '01') tmp;
#1.3 查询不存在" 01 "课程但存在" 02 "课程的情况
SELECT * FROM sc s1 INNER JOIN sc s2 on s1.`SId` = s2.`SId`
WHERE s1.`CId` = '02'and s2.`CId` !='01' ;
#2.查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
SELECT * FROM `student` st ,
(SELECT `SId` ,avg( `score`) FROM sc group by `SId` having avg(score)>=60) stGr #学生成绩
st.sid = stGr.sid;
#3.查询在 SC 表存在成绩的学生信息
SELECT * FROM student ,( SELECT sid FROM sc GROUP BY sid) tmp WHERE student.sid=tmp.sid;
#4.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
SELECT * from (SELECT sid,sname FROM student ) s INNER JOIN (SELECT sid,count(*),sum(score) FROM sc GROUP BY sid ) t on s.sid=t.sid ;
#4.1 查有成绩的学生信息
SELECT * FROM student ,( SELECT sid FROM sc GROUP BY sid) tmp WHERE student.sid=tmp.sid;
#5.查询「李」姓老师的数量
SELECT count(*) FROM `teacher` WHERE tname like '李%';
#6.查询学过「张三」老师授课的同学的信息
SELECT * FROM student s INNER JOIN
( SELECT sid FROM sc WHERE cid=
(SELECT cid from course WHERE course.tid=(select tid FROM teacher WHERE tname='张三'))) tmp#返回张三交了哪些学生
on s.sid=tmp.sid;
#7.查询没有学全所有课程的同学的信息
SELECT * FROM student s,(SELECT sid, COUNT( *) FROM sc group by sid HAVING COUNT(*)<=2 ) t WHERE t.sid=s.sid ;
#8.查询至少有一门课与学号为" 01 "的同学所学相同的同学的信息
#这个同学学了那些课
SELECT sid FROM sc GROUP BY sid #有哪些同学选了课
any
(SELECT sid FROM sc WHERE sc.sid='01');
#(SELECT cid FROM student,sc WHERE student.sid='01'and student.sid=sc.sid ) #01学了那些课
#9.查询和" 01 "号的同学学习的课程 完全相同的其他同学的信息
SELECT * FROM `student` WHERE
(SELECT cid FROM sc WHERE `SId` ='02')
(SELECT cid FROM sc WHERE `SId` ='01'))
#10.查询没学过"张三"老师讲授的任一门课程的学生姓名
SELECT sname FROM `student` WHERE sid =any
(
SELECT `SId` FROM sc WHERE `CId` = #老师交了哪些学生
(
SELECT cid FROM `course` WHERE `TId` = #老师的课程编号
(
SELECT tid FROM `teacher` WHERE `Tname` = '张三' #老师的编号
)
)
)
#11.查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
SELECT s.sid,s.sname,t.grade FROM `student` s,
(SELECT avg( `score`) grade, `SId` FROM sc WHERE `score` < 60 GROUP BY `SId` having COUNT( *) >=2) t
WHERE s.`SId` =t.sid;
SELECT c.sid,c.score,c.cid FROM sc c,
(SELECT avg( `score`) grade, `SId` FROM sc WHERE `score` < 60 GROUP BY `SId` having COUNT( *) >=2) t
WHERE c.`SId` =t.sid; #显示分数
#12.检索" 01 "课程分数小于 60,按分数降序排列的学生信息
SELECT * FROM `student` INNER JOIN sc on `student`.`SId` = sc.`SId`
WHERE sc.`score` <=60 and sc.`CId` = '01'
ORDER BY sc.`score` DESC ;
#13.按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
SELECT * FROM `student` st INNER JOIN sc on st.`SId` = sc.`SId` GROUP BY tem.`SId`
SELECT * FROM ( SELECT * FROM `student` st INNER JOIN sc on st.`SId` = sc.`SId`)tmp GROUP BY tmp.`SId`
SELECT * FROM ( SELECT * FROM `student` st INNER JOIN sc on st.`SId` = sc.`SId`)tmp GROUP BY tmp.`SId`
14.查询各科成绩最高分、最低分和平均分: 以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90 要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
15.按各科成绩进行排序,并显示排名, Score 重复时保留名次空缺 15.1 按各科成绩进行排序,并显示排名, Score 重复时合并名次
16.查询学生的总成绩,并进行排名,总分重复时保留名次空缺 16.1 查询学生的总成绩,并进行排名,总分重复时不保留名次空缺
17.统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[60-0] 及所占百分比
#18.查询各科成绩前三名的记录
SELECT SUM( `score`) , `SId` FROM `sc` GROUP BY `SId` ORDER BY SUM( `score`) DESC LIMIT (1,3);
#19.查询每门课程被选修的学生数
SELECT COUNT( *),cid FROM sc GROUP BY `CId` ;
#20.查询出只选修两门课程的学生学号和姓名
SELECT sid , `Sname` FROM `student` WHERE `SId` = any
( SELECT `SId` FROM sc GROUP BY `SId` HAVING COUNT(cid)=2)
#21.查询男生、女生人数
#SELECT COUNT( `Ssex`='男'),COUNT( `Ssex`='女')FROM `student`; 为什么会有返回值
SELECT * FROM
(SELECT COUNT(*) 男 FROM `student` WHERE `Ssex` = '男')
boy ,(SELECT COUNT(*) 女 FROM `student` WHERE `Ssex` = '女' ) gir
#22.查询名字中含有「风」字的学生信息
SELECT * FROM `student` WHERE `Sname` LIKE '%风%'
23.查询同名同性学生名单,并统计同名人数
#24.查询 1990 年出生的学生名单
SELECT * FROM `student` WHERE YEAR (`Sage`)='1990';
#25.查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
SELECT avg( `score`) score FROM `sc` GROUP BY `CId` ORDER BY `score` DESC , `CId` asc ;
26.查询平均成绩大于等于 85 的所有学生的学号、姓名和平均成绩
SELECT s.sid,s.sname,tmp.score FROM `student` s,
(SELECT avg( `score`) `score`,sid FROM `sc`group by `SId` HAVING score>=85) tmp
WHERE tmp.score>90 #s.`SId` = tmp.sid ####################################为什么不能比较score
#27.查询课程名称为「数学」,且分数低于 60 的学生姓名和分数
SELECT s.`Sname`,t.gread FROM `student` s,
(
SELECT sid, `score` gread FROM `sc` WHERE sc.`score` <60 and sc.`CId` =
(SELECT cid FROM `course` WHERE `course`.`Cname` ='数学')
) t###############错误
SELECT s.`Sname`,t.gread FROM `student` s,
(
SELECT sid, `score` gread FROM `sc` WHERE sc.`score` <60 and sc.`CId` =
(SELECT cid FROM `course` WHERE `course`.`Cname` ='数学')
) t WHERE s.`SId` = t.sid;
28.查询所有学生的课程及分数情况(存在学生没成绩,没选课的情况)
29.查询任何一门课程成绩在 70 分以上的姓名、课程名称和分数
30.查询不及格的课程
#31.查询课程编号为 01 且课程成绩在 80 分以上的学生的学号和姓名
SELECT * FROM student INNER JOIN sc on `student`.`SId` = sc.`SId` WHERE sc.`CId` = '01'and sc.`score` >=80;
#32.求每门课程的学生人数
SELECT COUNT( *),cid FROM `sc` GROUP BY `cId` ;
33.成绩不重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
SELECT * FROM
SELECT sid FROM sc WHERE MAX( `score`) #找到成绩最高的学生的编号
SELECT cid FROM `course` WHERE `TId` = #老师的课程编号
(
SELECT tid FROM `teacher` WHERE `Tname` = '张三' #老师的编号
)
34.成绩有重复的情况下,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
35.查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
SELECT sid FROM sc s1 ,sc s2 WHERE s1.`SId`
36.查询每门功成绩最好的前两名
SELECT * FROM `sc` WHERE `CId` ='01', LIMIT (1,2);
#37.统计每门课程的学生选修人数(超过 5 人的课程才统计)。
SELECT COUNT( *) FROM sc group by cid having count( *) >5;
#38.检索至少选修两门课程的学生学号
SELECT `student`.`SId` FROM `student` WHERE `SId` = any
( SELECT sid FROM `sc` GROUP BY `SId` HAVING COUNT( *)>=2)
#39.查询选修了全部课程的学生信息
SELECT * FROM `student` WHERE `SId` = any
( SELECT sid FROM `sc` GROUP BY `SId` HAVING COUNT( *)=3)
#40.查询各学生的年龄,只按年份来算
SELECT YEAR ( `Sage`) FROM `student`;
#41.按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一
SELECT if((dayofyear(now()))<(dayofyear( `Sage`))),
year(now())-year( `Sage`)-1,
year(now())-year( `Sage`) FROM `student`;
#42.查询本周过生日的学生
SELECT * FROM `student` WHERE week(`Sage`)= week(now());
#43.查询下周过生日的学生
SELECT * FROM `student` WHERE week(`Sage`)= DATE_add( week(now()), INTERVAL 1 week);
#44.查询本月过生日的学生
SELECT * FROM `student` WHERE month(`Sage`)= month(now());
#45.查询下月过生日的学生
SELECT * FROM `student` WHERE month(`Sage`)= DATE_add( month(now()), INTERVAL 1 month);
select s.sname,s.sage,t.score FROM `student` s,(select avg(score) score,sid from sc group by sid) t
where t.`SId` =t.sid
9.约束和分页
数据完整性:
约束
1.NOT NULL 非空约束,规定某个字段不能为空
#创建后修改
ALTER TABLE emp MODIFY sex VARCHAR(30) NOT NULL;
#取消修改
ALTER TABLE emp MODIFY sex VARCHAR(30) NULL;
#取消 not null 约束,增加默认值
ALTER TABLE emp MODIFY NAME VARCHAR(15) DEFAULT 'abc' NULL;
2.UNIQUE 唯一约束,规定某个字段在整个表中是唯一的
#修改
ALTER TABLE USER
1.ADD UNIQUE(NAME,PASSWORD);#unique的直接添加
2.ADD CONSTRAINT uk_name_pwd UNIQUE(NAME,PASSWORD);#表后的名
3.MODIFY NAME VARCHAR(20) UNIQUE;#修改列属性
#删除
ALTER TABLE USER
DROP INDEX uk_name_pwd;
3.PRIMARY KEY 主键(非空且唯一)
4.FOREIGN KEY 外键
5.CHECK 检查约束
6.DEFAULT 默认值
分页
SELECT * FROM table LIMIT(PageNo - 1)*PageSize,PageSize;
练习
#books表
CREATE TABLE books (id int primary key AUTO_INCREMENT ,
title varchar(100) NOT NULL ,
author varchar(100) NOT NULL ,
price double(11,2) NOT NULL ,
sales int(11) NOT NULL ,
stock int(11) NOT NULL ,
img_path varchar(100)
#CONSTRAINT uk_username UNIQUE(title) ;
);
INSERT INTO books (title,author,price,sales,stock,img_path )value
('解忧杂货店','东野圭吾',27.20,102,98,'upload/ books/解忧杂货店,jpg'),
('边坡','沈从文',23.00,102,98 ,'upload/ books/边城,jpg'),
('中国哲学史','冯友兰',44.50,101,99,'up1oad/ books/中国哲学史.jpg')
;
show tables;
drop table ClassInfo;
drop table StudenetExam;
drop table StudenetInfo;
drop table teacherinfo;
drop TABLE books;
SELECT *
FROM books;
desc books;
#user表
create table user
(
id int(11) PRIMARY KEY auto_increment,
username varchar(100) not null,
password varchar(100) not null,
email varchar(100),
constraint uk_name UNIQUE (`username`)
);
insert user(username, password, email) value
('admin', 123456, 'admin@atguigu com'),
('admin2', 123456, 'admin2catguigu. com'),
('admin3', 123456, 'admin3catguigu. com'),
('chai', 123, 'chai@atguigu com'),
('caoyang', '123', '[email protected]');
SELECT *
FROM user;
desc user;
#orders
CREATE table orders(
id varchar(10) primary key ,
order_time datetime not null,
total_count int(11) not null,
total_amount double(11,2) not null,
state int(11) not null,
user_id int(11) not null,
foreign key (user_id) REFERENCES user(id)
);
insert table orsers(order_time,total_count,total_amount,state,user_id) VALUE
('152757601948211','2018-05-29 14:40:19',4,114.03,2,1);
SELECT * FROM orders;
desc orders;
drop table orders;
#order_items
CREATE TABLE order_items(
id int(11) primary KEY auto_increment ,
count int(11) not null,
amount double(11,2) not null,
title varchar(100) not null,
author varchar(100) not null,
price double(11,2) not null,
img_path varchar(100) not null,
order_id varchar(100) ,
FOREIGN key (order_id) REFERENCES orders(id)
);
设计一张用户表,
#用户表包含用户编号(主键)\用户名(非空,唯一)\密码(非空)\性别(只能是男或女)\出生日期\手机号(唯一约束)\邮箱 允许为空\
##设计一个登录日志表,记录用户的登录的时间,登录的IP,登录地点,用户编号
reate table tbl_user(
userid int primary key auto_increment,
username varchar(32) not null,
password varchar(64) not null,
sex varchar(4) ,
birthday date ,
phone varchar(15) not null ,
email varchar(25),
CONSTRAINT uk_phone UNIQUE(phone),
CONSTRAINT uk_username UNIQUE(username) /*给username添加唯一约束*/
);
insert into tbl_user_login_log(loginTime,loginIp,loginAddr,userTableUserid)
values(now(),'172.16.0.1','长沙市xxx',5);
/*报错:原因,外键约束会检查userTableUserid列的值是否在tbl_user表的userid列值范围内(1,4)*/
insert into tbl_user_login_log(loginTime,loginIp,loginAddr,userTableUserid)
values(now(),'172.16.0.1','长沙市xxx',1);
insert into tbl_user_login_log(loginTime,loginIp,loginAddr,userTableUserid)
values(now(),'172.16.1.1','长沙市天心区',1);
insert into tbl_user_login_log(loginTime,loginIp,loginAddr,userTableUserid)
values(now(),'172.16.0.1','湖北市xxx',4);
#查询所有用户的登录日志
select * from tbl_user u,tbl_user_login_log l
where u.userid=l.userTableUserid;
delete from tbl_user where userid=1;
create table tbl_user_login_log(
logid int primary key auto_increment,
loginTime datetime not null,
loginIp varchar(14),
loginAddr varchar(100) ,
userTableUserid int ,/*外键约束 参考tbl_user表的userid*/
foreign key (userTableUserid) REFERENCES tbl_user(userid)
);
#插入
insert into tbl_user(username,password,sex,birthday,phone,email)
values('amdin',MD5('123456'),'男','2000-10-12','18007328601',null);
insert into tbl_user(username,password,sex,birthday,phone,email)
values('manager',MD5('666666'),'男','2000-10-12','18007328611',null);
insert into tbl_user(username,password,sex,birthday,phone,email)
values(null,MD5('666666'),'男','2000-10-12','18007328691',null);
10.用户与权限管理
#创建用户
CREATE USER 'username'@'host‘ IDENTIFIED BY 'password';
CREATE USER 'root'@'%‘ IDENTIFIED BY '1';
##说明:
username:你将创建的用户名
host:指定该用户在哪个主机上可以登陆,如果是本地用户可用localhost,如果想让该用户可以从任意远程主机登陆,可以使用通配符%
password:该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器
示例:
ALTER USER ‘用户名’@‘localhost’ IDENTIFIED WITH mysql_native_password BY '新密码';
#授权
GRANT 权限1[,权限2..。] on 数据库名.表名 to 用户名@用户地址 [WITH GRANT OPTION]
WITH GRANT OPTION 这个选项表示该用户可以将自己拥有的权限授权给别人该语句如果发现没有对应用户,则会创建一个新用户
#
select host,user,authentication_string,select_priv,insert_priv,drop_priv from mysql.user;
host: 表示连接类型
% 表示所有远程通过 TCP 连接
Localhost表示本地连接
IP地址如(192.168.0.1) 通过定制IP地址进行远程连接
User: 表示用户名
Select_priv,insert_priv,drop_priv表示用户拥有的权限
#回收授权
REVOKE privilege ON databasename.tablename FROM ‘username’@'用户地址';
如: REVOKE insert ON indexdb.* FROM 'pig'@'%';
把pig对indexdb的insert权限回收掉
#删除
DROP USER ‘用户名@'host';
% 表示所有远程通过 TCP 连接
Localhost表示本地连接
IP地址如(192.168.0.1) 通过定制IP地址进行远程连接

| 权限 | 权限级别 | 权限说明 |
|---|---|---|
| CREATE | 数据库、表或索引 | 创建数据库、表或索引权限 |
| DROP | 数据库或表 | 删除数据库或表权限 |
| GRANT OPTION | 数据库、表或保存的程序 | 赋予权限选项 |
| REFERENCES | 数据库或表 | |
| ALTER | 表 | 更改表,比如添加字段、索引等 |
| DELETE | 表 | 删除数据权限 |
| INDEX | 表 | 索引权限 |
| INSERT | 表 | 插入权限 |
| SELECT | 表 | 查询权限 |
| UPDATE | 表 | 更新权限 |
| CREATE VIEW | 视图 | 创建视图权限 |
| SHOW VIEW | 视图 | 查看视图权限 |
| ALTER ROUTINE | 存储过程 | 更改存储过程权限 |
| CREATE ROUTINE | 存储过程 | 创建存储过程权限 |
| EXECUTE | 存储过程 | 执行存储过程权限 |
| FILE | 服务器主机上的文件访问 | 文件访问权限 |
| CREATE TEMPORARY TABLES | 服务器管理 | 创建临时表权限 |
| LOCK TABLES | 服务器管理 | 锁表权限 |
| CREATE USER | 服务器管理 | 创建用户权限 |
| RELOAD | 服务器管理 | 执行flush-hosts, flush-logs, flush-privileges, flush-status, flush-tables, flush-threads, refresh, reload等命令的权限 |
| PROCESS | 服务器管理 | 查看进程权限 |
| REPLICATION CLIENT | 服务器管理 | 复制权限 |
| REPLICATION SLAVE | 服务器管理 | 复制权限 |
| SHOW DATABASES | 服务器管理 | 查看数据库权限 |
| SHUTDOWN | 服务器管理 | 关闭数据库权限 |
| SUPER | 服务器管理 | 执行kill线程权限 |
练习
11.数据库的设计
第一范式(1NF)的目标:确保每列的原子性。
第二范式(2NF)的目标:确保表中的每列,都和主键相关 。
第三范式(3NF)的目标:确保每列都和主键列直接相关,而不是间接相关 。
12.存储过程与函数
函数,存储过程
事先经过编译并存储在数据库中的一段SQL语句的集合,
存储过程:参数可以使用IN、OUT、INOUT类型,
函数:参数只能是IN类型的。
如果有函数从其他类型的数据库迁移到MySQL,可能需要将函数改造成存储过程。
存储过程和函数允许包含DDL语句,也允许使用事务,还可以调用其他的存储过程和函数
CREATE ROUTINE :创建存储过程或函数,
ALTER ROUTINE:修改或删除存储过程或函数
Drop procedure 存储过程名称;
Drop function 函数名称;
EXECUTE :执行存储过程或函数
查看
show create procedure proc_name;
show create function func_name;
Create procedure sp_name([proc_parameter[,…])
[characteristic…] routine_body
Create function sp_name([func_parameter[,…])
Returns type
[characteristic…] routine_body
Return xxx
调用语法:call sp_name([parameter[,…])
参数说明:
pro_parameter [ IN | OUT | INOUT ] param_name type
func_parameter param_name type
存储过程和函数中不允许执行 LOAD DATA INFILE 语句。
Characteristic特征值:
Language sql 说明下面body是使用sql编写,系统默认
Sql security { definer | invoker } 可以指定子程序该用创建子程序者的许可来执行,还是使用调用者的权限执行。默认是definer
Comment ‘string’ 存储过程或函数的注释信息
{ Contains sql | no sql | reads sql data | modifies sql data} 供子程序使用数据的内在信息,目前只提供给服务器,并没有根据
变量
Declare var_name[,…] type [default value];
变量可以直接赋值,或者通过查询赋值。直接赋值使用set,可以赋常量或者赋表达式。
Set var_name = expr [,var_name = expr] …
Select col_name [,…] INTO var_name [,…] from xxx….; #查询结果必须只有一行
Set @a = xxx; 相当于全局变量
处理过程中遇到问题时相应的处理步骤。
条件定义
Declare condition_name CONDITION FOR condition_value
条件处理(游标中有实例)
Declare handler_type HANDLER FOR condition_value [,…] sp_statement
说明:
Handler_type 目前支持 continue 和 exit ,continue继续执行下面的语句,exit表示终止。
Condition_value 值可以通过declare定义的 condition_name,可以是SQLSTATE 的值或者mysql-error-code的值或SQLWARING、NOT FOUND、SQLEXECEPTION,这3个值是3种定义好的错误类别。
判断循环
#if
CREATE PROCEDURE example_if (IN x INT)
BEGIN
IF x = 1 THEN
SELECT 1;
ELSEIF x = 2 THEN
SELECT 2;
ELSE
SELECT 3;
END IF;
END; -- 调用存储过程CALL example_if(2);
#case
CASE value
WHEN value THEN ...
WHEN value THEN ...
ELSE ...
END CASE
CREATE PROCEDURE example_case(IN x INT)
BEGIN
CASE x
WHEN 1 THEN SELECT 1;
WHEN 2 THEN SELECT 2;
ELSE SELECT 3;
END CASE;
END;
#while
WHILE condition DO
...
END WHILE;
CREATE PROCEDURE example_while(OUT sum INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE s INT DEFAULT 0;
WHILE i <= 100 DO
SET s = s+i;
SET i = i+1;
END WHILE;
SET sum = s;
END;
#loop
-- 创建存储过程
CREATE PROCEDURE example_loop(OUT sum INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE s INT DEFAULT 0;
loop_label:
LOOP
SET s = s+i;
SET i = i+1;
IF i>100 THEN -- 退出LOOP循环
LEAVE loop_label;
END IF;
END LOOP;
SET sum = s;
END;
CALL example_loop(@sum);SELECT @sum;
#repeat until
CREATE PROCEDURE example_repeat(OUT sum INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE s INT DEFAULT 0;
REPEAT
SET s = s+i;
SET i = i+1;
UNTIL i > 100
END REPEAT;
SET sum = s;
END;
游标
-
#1.声明 DECLARE cursor_name CURSOR FOR select_statement#这个语句声明一个游标。 #2. 游标OPEN 语句 OPEN cursor_name 先前声明的游标。 #3. 游标FETCH语句 FETCH cursor_name INTO var_name [, var_name] ... #这个语句用指定的打开游标读取下一行(如果有下一行的话),并且前进游标指针。 4. 游标CLOSE语句 CLOSE cursor_name 这个语句关闭先前打开的游标
练习
drop table tbl_invoice;
###########################################################################数据录入
create table tbl_invoice(
id int primary key auto_increment , #id自增长
studentname varchar(30), #姓名
inoutDate date, #记录日期
inoutDateTime datetime, #出入时间accessible
inoutFlg int , #出入标志 1代表 出 2代表入
result varchar(40) #出入状态分析结果
);
insert into tbl_invoice(studentname,inoutDate,inoutDateTime,inoutFlg) values('如花','2016-06-28','2016-06-28 07:10:20',1);#正常
insert into tbl_invoice(studentname,inoutDate,inoutDateTime,inoutFlg) values('如花','2016-06-28','2016-06-28 22:10:20',2);#正常
insert into tbl_invoice(studentname,inoutDate,inoutDateTime,inoutFlg) values('似玉','2016-06-28','2016-06-28 08:10:20',1);#晚出
insert into tbl_invoice(studentname,inoutDate,inoutDateTime,inoutFlg) values('似玉','2016-06-28','2016-06-28 21:11:20',2);#正常
insert into tbl_invoice(studentname,inoutDate,inoutDateTime,inoutFlg) values('似玉','2016-06-27','2016-06-27 06:10:20',1);#正常
insert into tbl_invoice(studentname,inoutDate,inoutDateTime,inoutFlg) values('李刚','2016-06-27','2016-06-28 05:10:20',2);#超时晚归
###########################################################################
drop procedure updateInvoiceReslut;
delimiter $$
create procedure updateInvoiceReslut()
begin
#定义变量
declare done int default 0;
#以下四个变量用于接收游标提取出来的行数据
declare v_id int(11);
declare v_inoutDate date;
declare v_inoutDateTime datetime;
declare v_inoutFlg int(11);
declare v_time varchar(20);#用于记录inoutDateTime对应的时分秒
declare v_reslut varchar(20);#用于记录出入状态
# 1、游标的定义
declare c_invoice cursor for select id,inoutDate,inoutDateTime,inoutFlg from tbl_invoice;
# 捕获系统抛出的 not found 错误,如果捕获到,将 done 设置为 1 相当于try异常
declare continue handler for not found set done=1;
# 2、打开游标
open c_invoice;
flag:
loop #循环开始
# 3、使用游标
fetch c_invoice into v_id,v_inoutDate,v_inoutDateTime,v_inoutFlg; #提取数据,把数据放到V_开头的变量中
if (done=1) then
leave flag;#当提取数据失败(没有数据)
end if;
set v_time=DATE_format(v_inoutDateTime,'%H:%i:%s');#把v_inoutDateTime转换为 HH:mm:ss 时分秒格式字符串
#判断 v_inoutFlg是1 还是2
if (v_inoutFlg=1) then #判断
#判断 v_time是否小于08:00:00
if (v_time<'08:00:00') then
set v_reslut= '正常';
else
set v_reslut= '晚出';
end if;
elseif (v_inoutFlg=2) then #v_inoutDateTime是8点前还是个8点后
#判断 v_time是否小于08:00:00
#判断inoutDate和inoutDateTime是否为同一天
if (DATE_format(v_inoutDate,'%d')=DATE_format(v_inoutDateTime,'%d')) then
if (v_time<'22:30:00' ) then
set v_reslut= '正常';
elseif (v_time>='22:30:00' and v_time<='23:59:59') then
set v_reslut= '晚归';
else
set v_reslut= '还未处理';
end if;
else
if (v_time>='00:00:00' and v_time<='06:00:00') then
set v_reslut= '延迟晚归';
else
set v_reslut= '未归';
end if;
end if;
end if ;
update tbl_invoice set result= v_reslut where id=v_id;#更新表中的对应 记录
end loop ;
#循环结束
# 4、关闭游标
close c_invoice;
end; $$
SELECT * FROM tbl_invoice;
call updateInvoiceReslut();
##########################################################################################################
数据库资料
工具
powerdesigner
阿里云数据库
数据库密码
数据表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2gIID4jB-1650286529852)(image/image-20211217151912300.png)]
学员信息表
show databases ;
create database HC;
use HC;
create table StudenetInfo(
StuID INT not null primary key ,
StuNumber varchar(20) not null ,
StuName varchar( 20) not null ,
StuAge int check ( StuAge >=15 and StuAge<=35 ),
StuSex varchar(20) not null check ( StuSex='男' or StuSex='女' ),
StuCard varchar( 20) null ,
StuJionTime datetime not null ,
StuAddress varchar( 20) null ,
SClassID int null
) DEFAULT CHARACTER SET utf8
DEFAULT COLLATE utf8_general_ci;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rrdLBj0b-1650286529852)(image/image-20211217151925421.png)]
成绩表
create table StudenetExam(
ExamID int not null unique ,
ExamNumber varchar(20) not null ,
ExamStuID int not null ,
ExamSubject varchar(20) not null ,
ExamResult int null check ( ExamResult>=0 and ExamResult<=100 )
)DEFAULT CHARACTER SET utf8;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dT6WSST1-1650286529853)(image/image-20211217151946916.png)]
班级信息
create table ClassInfo(
ClassID int not null unique ,
CTeacherID int not null ,
ClassGrade varchar(20) not null default 's1' check ( ClassGrade='s1' or ClassGrade='s2' or ClassGrade='s3' )
)DEFAULT CHARACTER SET utf8;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oaOCsb43-1650286529854)(image/image-20211217152014470.png)]
班主任表
create table TeacherInfo(
TeacherID int not null unique ,
TeacherName varchar(20) not null ,
TeacherTel varchar(20) null ,
TeacherEmail varchar(20) not null check ( TeacherEmail like '%@%')
)DEFAULT CHARACTER SET utf8;
show tables ;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2gBF0mk8-1650286529854)(image/image-20211217152027607.png)]
end
;
#循环结束
# 4、关闭游标
close c_invoice;
end; $$
SELECT * FROM tbl_invoice;
call updateInvoiceReslut();
##########################################################################################################
# 数据库资料
## 工具
powerdesigner
# 阿里云数据库
## 数据库密码
dingxian_1
Jiansheyin1
# 数据表
[外链图片转存中...(img-2gIID4jB-1650286529852)]
## 学员信息表
show databases ;
create database HC;
use HC;
create table StudenetInfo(
StuID INT not null primary key ,
StuNumber varchar(20) not null ,
StuName varchar( 20) not null ,
StuAge int check ( StuAge >=15 and StuAge<=35 ),
StuSex varchar(20) not null check ( StuSex=‘男’ or StuSex=‘女’ ),
StuCard varchar( 20) null ,
StuJionTime datetime not null ,
StuAddress varchar( 20) null ,
SClassID int null
) DEFAULT CHARACTER SET utf8
DEFAULT COLLATE utf8_general_ci;
[外链图片转存中...(img-rrdLBj0b-1650286529852)]
## 成绩表
create table StudenetExam(
ExamID int not null unique ,
ExamNumber varchar(20) not null ,
ExamStuID int not null ,
ExamSubject varchar(20) not null ,
ExamResult int null check ( ExamResult>=0 and ExamResult<=100 )
)DEFAULT CHARACTER SET utf8;
[外链图片转存中...(img-dT6WSST1-1650286529853)]
## 班级信息
create table ClassInfo(
ClassID int not null unique ,
CTeacherID int not null ,
ClassGrade varchar(20) not null default ‘s1’ check ( ClassGrade=‘s1’ or ClassGrade=‘s2’ or ClassGrade=‘s3’ )
)DEFAULT CHARACTER SET utf8;
[外链图片转存中...(img-oaOCsb43-1650286529854)]
## 班主任表
create table TeacherInfo(
TeacherID int not null unique ,
TeacherName varchar(20) not null ,
TeacherTel varchar(20) null ,
TeacherEmail varchar(20) not null check ( TeacherEmail like ‘%@%’)
)DEFAULT CHARACTER SET utf8;
show tables ;
[外链图片转存中...(img-2gBF0mk8-1650286529854)]
# end