轻量级神经网络算法-SqueezeNet
4. 轻量级神经网络算法目录
- 轻量级神经网络算法
4.1 各轻量级神经网络算法总结对比
4.2 SqueezeNet
4.3 DenseNet
4.4 Xception
4.5 MobileNet v1
4.6 IGCV
4.7 NASNet
4.8 CondenseNet
4.9 PNASNet
4.10 SENet
4.11 ShuffleNet v1
4.12 MobileNet v2
4.13 AmoebaNet
4.14 IGCV2
4.15 IGCV3
4.16 ShuffleNet v2
4.17 MnasNet
4.18 MobileNet v3
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章目录
- 4. 轻量级神经网络算法目录
-
- 4.2 SqueezeNet
-
- 4.2.1 问题分析
- 4.2.2 SqueezeNet的三大策略
- 4.2.3 Fire模块
- 4.2.4 SqueezeNet整理结构
- 4.2.5 代码实现SqueezeNet
- 4.2.6 其他实现细节
- 4.2.7 总结
4.2 SqueezeNet
4.2.1 问题分析
最近在卷积神经网络上的研究主要关注提高准确率。在给定相应的准确率之后,通常有多个CNN结构可以达到该准确率要求。在同等准确率的情况下,较小的CNN结构至少有三个优点:
- 在分布式训练期间,较小的CNN需要较少的跨服务器通信
- 在自动驾驶汽车等应用场景下,较小的CNN需要较少的带宽将新模型从云端导入
- 较小的CNN更适合部署在FPGA和其他内存有限的硬件上
为了达到所有这些优点,本文提出了较小的CNN结构,称之为SqueezeNet。SqueezeNet在ImageNet上实现了AlexNet同级别的准确率,但参数减少了50倍。另外使用模型压缩技术,能够将SqueezeNet压缩到小于0.5MB(比AlexNet小近510倍)。
4.2.2 SqueezeNet的三大策略
-
策略1:用1x1卷积代替3x3卷积
1x1卷积核的参数比3x3少9倍,所以网络中部分卷积核改为使用为1x1卷积。 -
策略2:减少输入到3*3卷积核的通道数量
对于一个完全由3×3卷积核组成的卷积层来说,总参数量=输入通道数×卷积核数量×(3×3),所以仅仅替换3×3卷积核为1×1,还不能完全达到减少参数的目的,还需要减少输入到3×3卷积核的通道数。本文提出squeeze layer,来减少输入到3×3卷积核的通道数。 -
策略3:在网络后期再进行下采样,使卷积层具有较大的激活图
这里的激活图(activate maps)指的是输出的特征图。在卷积网络中,每个卷积层产生空间分辨率至少为1×1(经常大于1×1)的输出激活图,激活图的宽和高主要是由1)输入的数据(例如256×256的图片) 2)CNN结构中下采样层方法 决定的。下采样通常是stride>1的卷积层或者池化层,如果在早期layer中有较大的stride,则后面大部分的layers中将是小的激活图,如果在早期layer中stride为1,在网络后期layer中stride>1,则大部分的layer将有一个大的激活图。本文的观点是,大的激活图能够产生更高的分类准确率,所以在网络设计中,stride>1往往设置在后期的layer中。
策略1和策略2在试图保持准确性的同时,明智地减少CNN中的参数数量,策略3是在有限的参数预算上最大化准确率。
4.2.3 Fire模块
为实现这3大策略,提出了Fire模块,Fire模块中主要包含squeeze层和expand层。squeeze卷积如图橙色椭圆内所示,只使用1×1卷积(策略1优化点),然后进入到expand卷积,expand卷积包括1×1(策略1优化点)和3×3卷积,squeeze和expand整体构成Fire模块,该模块有三个超参数s1x1,e1x1,e3x3,其中s1x1是squeeze层卷积核的数量,e1x1是expand层中1×1卷积核的数量,e3x3是expand层中3×3卷积核的数量,另外设置s1x1<(e1x1+e3x3)(策略2优化点),这样就能限制输入到3×3卷积核通道数,实现策略2的想法。

4.2.4 SqueezeNet整理结构
SqueezeNet整体网络结构图如下所示,其中maxpool(stride=2)分别设置在conv1/fire4/fire8/conv10之后,这些相对较晚的pool安排符合策略3的想法。

4.2.5 代码实现SqueezeNet
Fire模块的代码如下:
class Fire(nn.Module):
def __init__(
self,
inplanes: int,
squeeze_planes: int,
expand1x1_planes: int,
expand3x3_planes: int
) -> None:
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
SqueezeNet主要有两个结构,SqueezeNet1_0和SqueezeNet1_1,SqueezeNet1_0即官方版本(图2左侧),SqueezeNet1_1与SqueezeNet1_0相比在没有减少准确率的情况下,节省近2.4倍的参数量和计算量。
SqueezeNet1_0的网络结构如下:
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1))
)
SqueezeNet1_1的网络结构如下:
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1))
)
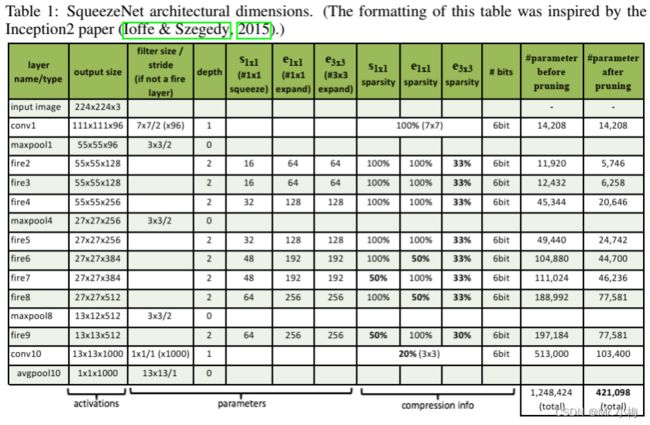
SqueezeNet各层详细参数量及其输入输出如下表所示。
4.2.6 其他实现细节
- 1×1和3×3卷积的输出宽和高不同,所以3×3卷积设置1个为0的padding
- squeeze和expand层中使用ReLU
- 在fire9之后的layer中使用ratio为50%的Dropout
- 参考NiN算法想法,SqueezeNet中不含全连接层
- 训练时,前期学习率设置为0.04,然后线性减少
4.2.7 总结
本文最主要就是三点:
- 用1×1卷积代替部分3×3卷积,输出两种卷积级联的结果
- 减少输入到3×3卷积的特征图的通道数,减少参数量
- 不过早的使用pool,在网络结构后期再使用pool,这样能提高分类准确率