轻量级神经网络算法-MobileNet v1
4. 轻量级神经网络算法目录
- 轻量级神经网络算法
4.1 各轻量级神经网络算法总结对比
4.2 SqueezeNet
4.3 DenseNet
4.4 Xception
4.5 MobileNet v1
4.6 IGCV
4.7 NASNet
4.8 CondenseNet
4.9 PNASNet
4.10 SENet
4.11 ShuffleNet v1
4.12 MobileNet v2
4.13 AmoebaNet
4.14 IGCV2
4.15 IGCV3
4.16 ShuffleNet v2
4.17 MnasNet
4.18 MobileNet v3
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章目录
- 4. 轻量级神经网络算法目录
-
- 4.5 MobileNet v1
-
- 4.5.1 问题分析
- 4.5.2 MobileNet v1关键点
- 4.5.3 深度可分离卷积
- 4.5.4 MobileNet网络结构设计
- 4.5.5 Width Multiplier(宽度倍增器):更薄型号的模型
- 4.5.6 Resolution Multiplier(分辨率倍增器):减少分辨率表达
- 4.5.7 总结
论文:《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
4.5 MobileNet v1
本文为移动和嵌入式视觉应用提供了一种称为MobileNets的高效率模型。MobileNets基于一种流线型架构,使用深度可分离卷积构建的轻量级深度神经网络。本文引入了两个简单的全局超参数,可以有效地在延迟和准确性之间进行权衡。使用者可以根据需求调整超参数来选择合适的模型。
4.5.1 问题分析
卷积神经网络已经无处不在,总的趋势是制造更深更复杂的网络,以达到更高的精度。但是,在模型大小和速度方面,这些只为提高准确率而做的改进并不一定能使网络更有效。例如,在机器人、自动驾驶汽车和增强现实等现实应用中,识别任务需要在计算资源有限的平台上及时执行。
4.5.2 MobileNet v1关键点
为解决以上问题,本文提出了一种高效的网络结构,简化模型参数,另设置两个超参数,能够根据自身需求,自定义网络大小,使得这些模型可以很容易地匹配移动和嵌入式视觉应用的设计要求。
- 使用深度可分离卷积(depthwise separable filters)构建模型
- 使用两个超参数宽度系数和分辨率系数(width multiplier and resolution multiplier)来自定义调整模型结构,方便选择合适的模型结构
4.5.3 深度可分离卷积
如下图所示,展示了一个标准卷积如何分解为一个深度卷积(depthwise conv)和一个1×1逐点卷积(pointwise conv)。
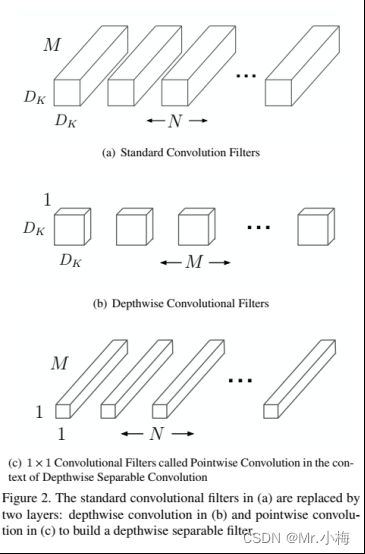
图中(a)标准的卷积操作是将shape为Df×Df×M的特征图F映射为shape为Df×Df×N特征图G,Df是输入特征图的宽和高,M是输入特征图的通道数,N是输出特征图的通道数。
一个标准的卷积参数量=Dk×Dk×M×N,Dk是卷积核的尺寸,
标准卷积的计算量=Dk×Dk×M×N×Df×Df
标准卷积运算具有卷积核过滤特征和组合特征以产生新表示的效果,可以把标准卷积拆分为两个步骤(滤波和组合)来大幅降低计算成本,这就是深度可分离卷积。
深度可分离卷积有两层构成,深度卷积(depthwise conv)和逐点卷积(pointwise conv)。深度卷积对每个输入通道(输入深度)应用同一个单个滤波器(卷积核),逐点卷积是一种简单的1×1卷积,用于线性组合深度卷积层的输出。这两种卷积之后接BN和ReLU。
深度卷积的计算量=Dk×Dk×M×Df×Df
逐点卷积的计算量=M×N×Df×Df
深度可分离卷积对比标准卷积:
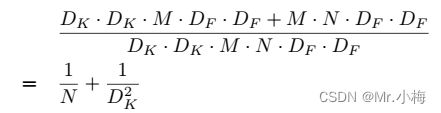
MobileNet使用3×3的深度可分离卷积,与标准卷积相比节省8-9倍计算量。
深度可分离卷积的代码实现:
nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
在进行 deepthwise(DW) 卷积时只使用了一种维度为inp的3x3卷积核进行特征提取(没有进行特征组合);
在进行 pointwise(PW) 卷积时只使用了维度为oup的1×1 的卷积核进行特征组合。
使用深度可分离卷积对比全卷积神经网络,在准确率只减少1%的情况下,在Mult-Adds和参数上节省了很多。

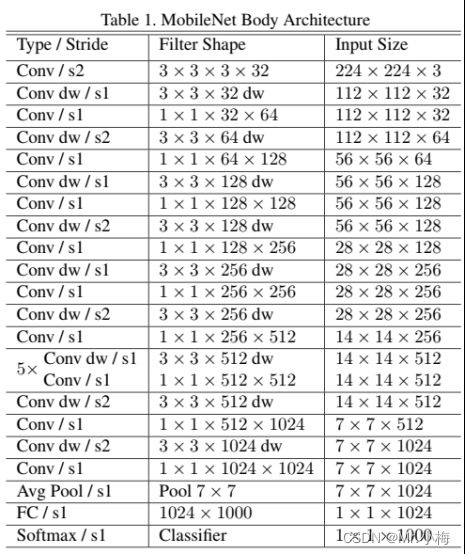
4.5.4 MobileNet网络结构设计
模型结构如下表所示,每一层之后都接BN和ReLU,除了最后一层接入softmax层进行分类。
4.5.5 Width Multiplier(宽度倍增器):更薄型号的模型
尽管基本MobileNet架构已经很小,延迟也很低,但很多时候,特定用例或应用程序可能要求模型更小更快。为了构造这些较小且计算成本较低的模型,引入了一个非常简单的参数α称为宽度系数。宽度系数α的作用是在每一层均匀地薄化网络。例如对于给定layer和参数α,则该layer的输入通道数变由M变为αM,输出通道数由N变为αN。
加入宽度系数后的深度可分离卷积的计算量为=Dk×Dk×αM×Df×Df+M×αN×Df×Df
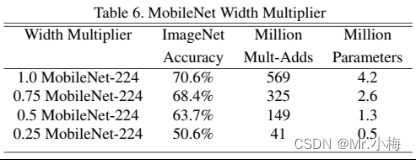
下表显示了使用宽度系数α缩小MobileNet架构的精度、计算和尺寸权衡。精度平稳下降,直到在α=0:25时架构变得太小。
4.5.6 Resolution Multiplier(分辨率倍增器):减少分辨率表达
降低神经网络计算成本的第二个超参数是分辨率系数ρ,应用到输入图片中,之后每个层由相同的乘数减少。
加入分辨率系数后的深度可分离卷积的计算量为=Dk×Dk×M×ρDf×ρDf+M×N×ρDf×ρDf
加入宽度系数和分辨率系数后的深度可分离卷积的计算量为=Dk×Dk×αM×ρDf×ρDf+M×αN×ρDf×ρDf
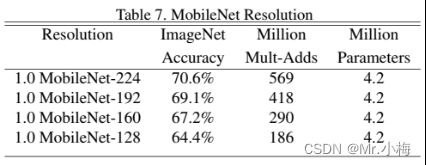
ρ∈(0,1],一般设置为224/192/160/128。ρ=1即标准模型,分辨率系数具有将计算成本降低ρ**2倍的效果。表3显示了当架构收缩方法顺序应用于层时,层的计算和参数数量。第一行显示了全卷积层的Mult-Adds和参数量,输入特征图大小为14×14×512,核K大小为3×3×512×512

表7显示了通过训练输入分辨率降低的网络,不同分辨率系数的精度、计算和大小权衡。精度在分辨率范围内平稳下降。
4.5.7 总结
- 提出了使用深度可分离卷积代替常规卷积,大幅降低参数量和计算量
- 设置超参数α(宽度系数),用于调节每层特征图的输入输出通道数,来降低模型参数量和计算量
- 设置超参数ρ(分辨率系数),用于调节输入到网络的图片分辨率,降低模型计算量