轻量级神经网络算法系列文章-ShuffleNet v1
4. 轻量级神经网络算法目录
- 轻量级神经网络算法
4.1 各轻量级神经网络算法总结对比
4.2 SqueezeNet
4.3 DenseNet
4.4 Xception
4.5 MobileNet v1
4.6 IGCV
4.7 NASNet
4.8 CondenseNet
4.9 PNASNet
4.10 SENet
4.11 ShuffleNet v1
4.12 MobileNet v2
4.13 AmoebaNet
4.14 IGCV2
4.15 IGCV3
4.16 ShuffleNet v2
4.17 MnasNet
4.18 MobileNet v3
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章目录
- 4. 轻量级神经网络算法目录
-
- 4.11 ShuffleNet v1
-
- 4.11.1 简介
- 4.11.2 主要模块介绍
-
- 4.11.2.1 pointwise conv(PW,1×1卷积)
- 4.11.2.2 group conv(组卷积)
- 4.11.2.3 深度可分离卷积(depthwise separable convolution)
- 4.11.3 Channel Shuffle
- 4.11.4 ShuffleNet Unit
- 4.11.5 网络结构
- 4.11.6 总结
4.11 ShuffleNet v1
本文介绍了一种计算效率极高的CNN结构,称之为ShuffleNet,专门为计算能力有限的移动设备(例如10-150 MFLOPs)设计。ShuffleNet主要使用两种运算pointwise group convolution和channel shuffle,在保持精度的同时大大降低计算成本。
4.11.1 简介
目前(2017.12之前)最优的算法结构例如Xception、ResNext等因为大量使用1×1卷积,虽然会使模型变小,但导致计算效率降低。本文提出的pointwise group convolution可以降低1×1卷积的计算复杂度。当然group卷积也有一定缺点(后面讲),为了解决组卷积带来的副作用,提出了channel shuffle(随机通道)来帮助信息在各通道之间流动。
与目前热门的VGG和ResNet相比,在限定的计算复杂度之内,ShuffleNet允许有更多的特征映射通道,这有助于编码更多的信息,并且这对非常小的网络的性能特别关键。
4.11.2 主要模块介绍
4.11.2.1 pointwise conv(PW,1×1卷积)
1×1卷积的代码实现:
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, groups=1)
首先计算一下1×1卷积为什么也会耗资源,使计算效率低下,后续与后面组卷积参数量和计算量对比。
如上面代码所示的1×1卷积,
假设input_channels=c1=32,output_channels=c2=32,记输入特征图的宽高为W H=224 224,则参数量=c2×(c1×1×1)=c1×c2=1024,计算量MAdds=2×c1×H×W×1×1×c2≈103M
1×1卷积的作用:
- 降维
降维的最主要作用就是减少参数,如下图是ResNet的一个残差block设计,本来一个3×3卷积总共的参数量是256×3×3×256+256=590080,加入1×1卷积后,变成1×1 conv -> 3×3conv,参数量变成(256×1×1×64+64)+(64×3×3×64+64)=16448+36928=53376,590080/53376≈11,整整节省了11倍。
- 升维
残差连接中,往往需要输入输出通道保持一致,如上图所示,方便进行Add操作,所以需要升维操作,把通道数变成和输入时一致,所以就会用到升维。 - 信息融合
同样是看上看上图的残差块,无论是降维还是升维,可以理解成通道之间的信息进行了融合,转换成了新的表达方式。 - 非线性
1×1卷积能够保持输入输出特征的宽高不变,在1×1卷积之后加入非线性函数(例如ReLU),就起到了非线性转换的功能
4.11.2.2 group conv(组卷积)
以输入特征1×32×224×224为例。
- 普通卷积
首先看一下普通卷积的运算过程:
普通卷积的代码如下:
nn.Conv2d(32,32,kernel_size=3,stride=1,padding=1,groups=1,bias=False)
普通卷积示意图如下所示:

普通卷积的参数量=32×(32×3×3)=9216,计算量MAdds=2×(32×3×3)×(224×224)×32≈925M
图中可以看到,每个卷积核的大小为32×3×3,每个卷积核都要和输入特征进行卷积操作,输出特征1×224×224,32个卷积核的输出合在一起即输出结果32×224×224
- 组卷积1:分32组,输出32维
接下来讲一个最常用的组卷积,组数和输入通道数一样的,实现代码如下:
nn.Conv2d(32,32,kernel_size=3,stride=1,padding=1,groups=32,bias=False)
组卷积示意图如下:

组卷积的参数量=32×(1×3×3)=288,计算量MAdds=2×(1×3×3)×(224×224)×32≈29M
可以看出与普通卷积相比,参数量骤降32倍。
假设卷积核尺寸是1×1,则组卷积的参数量和计算量分别是:
组卷积的参数量=32×(1×1×1)=32,计算量MAdds=2×(1×1×1)×(224×224)×32≈3M
与4.11.2.1中的普通1×1卷积相比的参数量1024和计算量103M相比骤降好多倍。!!!可以看出1×1卷积中加入组卷积能节省多少参数量和计算量了。
图中可以看到,每个卷积核的大小为1×3×3,输入特征分成了32组,每组特征1×224×224,每个卷积核只需要和32组特征中的一个进行卷积操作,输出特征1×224×224,32个卷积核的输出合在一起即输出结果32×224×224
- 组卷积2:分16组,输出16维
接下来讲另一个组卷积,组数是输入通道数的一半,
实现代码如下:
nn.Conv2d(32,16,kernel_size=3,stride=1,padding=1,groups=16,bias=False)
组卷积示意图如下:

组卷积的参数量=16×(2×3×3)=288,计算量MAdds=2×(2×3×3)×(224×224)×16≈29M
从图中可以看到,每个卷积核的大小为2×3×3,输入特征分成了16组,每组特征2×224×224,每个卷积核只需要和16组特征中的一个进行卷积操作,输出特征1×224×224,16个卷积核的输出合在一起即输出结果16×224×224
- 组卷积3:分8组,输出32维
接下来讲另一个组卷积,组数是输入通道数的1/4,
实现代码如下:
nn.Conv2d(32,32,kernel_size=3,stride=1,padding=1,groups=8,bias=False)
组卷积的示意图如下:

组卷积的参数量=32×(4×3×3)=1152,计算量MAdds=2×(4×3×3)×(224×224)×32≈116M
从图中可以看到,每个卷积核的大小为4×3×3,输入特征分成了8组,每组特征4×224×224,每个卷积核只需要和8组特征中的一个进行卷积操作,输出特征1×224×224,32个卷积核的输出合在一起即输出结果32×224×224
4.11.2.3 深度可分离卷积(depthwise separable convolution)
详见MobileNet v1中介绍。
4.11.3 Channel Shuffle
现在的卷积神经网络基本都是由多个相同结构的blocks组成,Xception、ResNeXt、MobileNet中提出深度可分离卷积和 group 卷积来在精度和计算成本之间取得权衡。但是本文研究发现,这些网络并没有充分使用1×1卷积(在MobileNet中称之为逐点卷积PW),因为1×1卷积需要相当大的复杂性。例如,在ResNeXt中,只有3×3层使用了组卷积,因此,对于ResNeXt中的每个残差单元,逐点卷积占据93.4%的MAdds。在小型网络中,如此耗计算成本的逐点卷积会导致使用有限的通道数来满足复杂度的约束,这可能会严重影响精度。
为了解决这个问题,最直接的方法就是在1×1卷积中加入组卷积(group conv),这样显著降低了计算成本。但是如果多组卷积叠加在一起,则存在一个副作用:某个通道的输出仅来自一小部分输入通道。如下图(a)所示,有两个组卷积GConv1和GConv2,堆叠的情况,粉色部分通道一直只处理粉色部分的信息,蓝色和绿色部分同样。显然,某一组的输出仅与该组内的输入相关。这样导致通道组之间的信息流无法流通,并削弱了信息的表示。
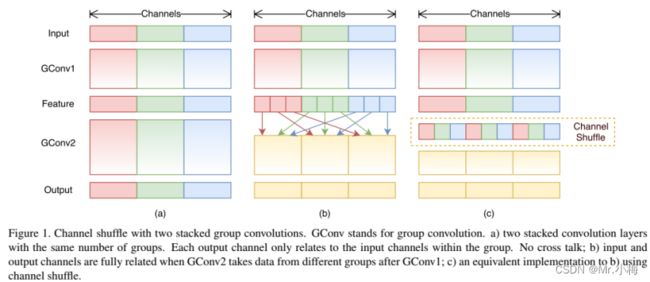
假设一个具有g组的卷积层,其输出具有g×n个信道;先将输出通道维度重塑为(g;n),转置,然后将其展平,作为下一层的输入。channel shuffle具体实现代码如下:此外,channel shuffle是可微的,这意味着它可以嵌入到网络结构中进行端到端训练。
channel shuffle的代码实现如下:
def channel_shuffle(self, x):
batchsize, num_channels, height, width = x.data.size()
assert num_channels % self.group == 0
group_channels = num_channels // self.group
x = x.reshape(batchsize, group_channels, self.group, height, width)
x = x.permute(0, 2, 1, 3, 4)
x = x.reshape(batchsize, num_channels, height, width)
return x
channel shuffle操作使得可以构建具有多个组卷积层的更强大的结构,下一节讲解使用channel shuffle和group conv组成的ShuffleNet单元。
4.11.4 ShuffleNet Unit
首先参考ResNet的bottleneck(如图(a)所示)开始设计,修改普通的3×3卷积为深度卷积,然后用逐点群卷积代替第一个1×1层,后面接一个channel shuffle,就构建成了一个ShuffleNet Unit,如图中(b)所示。第二个逐点群卷积的目的是恢复通道维数以匹配shortcut路径。为了简单起见,不在第二个逐点层之后应用额外的channel shuffle操作,因为它产生的结果变化不大。另外参考Xception,在DW卷积之后不适用ReLU。对于使用stride>1的情况,只需做两个修改:(1)在shortcut路径上添加3×3平均池化 (2)将逐元素相加ADD替换为通道级联Concat,这使得可以在不增加额外计算成本的情况下轻松地扩大通道维数。

相比ResNet和ResNeXt,shuffleNet在相同的设置下,结构复杂度更低。例如,给定输入大小c×h×w、通道数m和组卷积组数g,ResNet单元需要hw(2cm+9m2)FLOPs,ResNeXt需要hw(2cm+9m2/g)的FLOPs,ShuffleNet Unit需要仅仅hw(2cm/g+9m)的FLOPs。换句话说,给定计算预算,ShuffleNet可以使用更多的特征映射。这对于小型网络至关重要,因为小型网络通常没有足够的通道来处理信息。
另外需要注意的是,在ShuffleNet中,深度卷积仅在瓶颈特征映射上使用,尽管深度卷积通常具有非常低的计算复杂度,但实验发现难以在低功率的移动设备上有效地实现,这可能是由于与其他密集操作相比,深度卷积的计算/存储器访问比较差造成的。在ShuffleNet单元中,仅在瓶颈上使用深度卷积,以尽可能避免不必要的开销。
4.11.5 网络结构
基于ShuffleNetUnit,如表1中展示了整个shuffleet结构,所提出的网络主要由为三个阶段的ShuffleNetUnit单元的堆栈组成(stage2/3/4),
每个stage第一层stride=2,每个stage中的其他超参数保持不变,下一stage中的输出通道数加倍。与ResNet类似,每个ShuffleNet Unit中bottleneck中的通道数设置为输出通道数的1/4。这块有优化空间,进一步的超参数调谐可能会产生更好的结果,但是为了提供更简单的设计,不做太多修改。

在ShuffleNet Unit中,组卷积组数g控制逐点卷积的连接稀疏性,表1测试了不同的组数,调整了输出通道,以确保总体计算成本大致不变(大约140M FLOPs)。显然,对于给定的复杂度约束,较大的组数导致更多的输出信道(因此更多的卷积滤波器),这有助于编码更多信息,但由于有限的对应输入信道,也可能导致单个卷积滤波器的性能下降。
为了将网络定制为期望的复杂性,我们可以简单地在通道数量上应用比例因子s。例如,我们将表1中的网络表示为
“ShuffleNet 1×”,则“shuffleet s×”意味着将ShuffleNet 1×中的过滤器数量缩放s倍,因此总体复杂度将大约是shufflet1×的s^2倍。
4.11.6 总结
- 大量的1×1卷积也是很消耗资源的,所以修改1×1卷积为1×1 group卷积(即pointwise group convolution)
- 1×1 gruop卷积有会导致一些缺点,每个group卷积之内只关注本组信息,为弥补这些缺点,提出channel shuffle,使各个group之间信息可以交互