2022年竞赛打榜,神经网络还是干不过树模型??

文 | QvQ
随着深度神经网络的不断发展,DNN在图像、文本和语音等类型的数据上都有了广泛的应用,然而对于同样非常常见的一种数据——表格数据,DNN却似乎并没有取得像它在其他领域那么大的成功。从Kaggle平台上对数据挖掘竞赛Top团队使用的工具统计上也能看出,XGBoost和LightGBM这类提升(Boosting)树模型依旧占据主要地位。
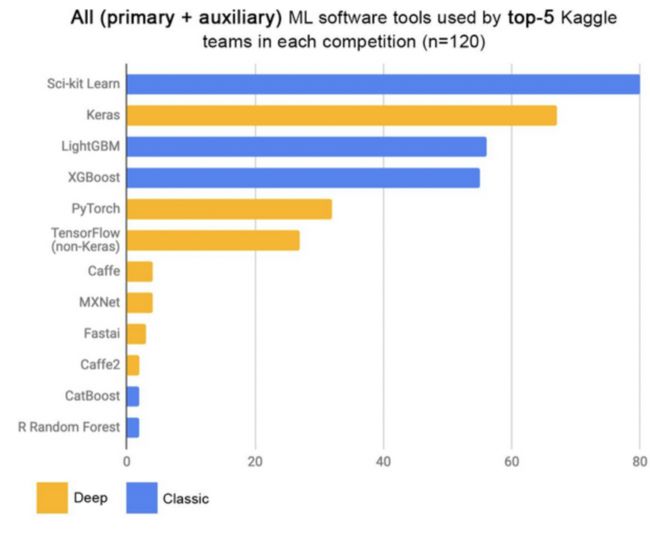
这种来自GBM类模型的压制力在表格数据上尤为明显,即便算上当今专注于处理表格数据的神经网络模型,Xgboost的性能(速度 & 精度)依旧不是这些神经网络可以“碰瓷”的。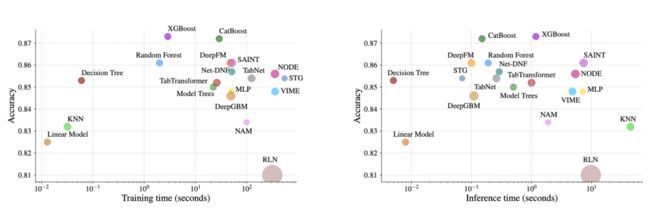
那么,在自然语言领域和图像领域号称超越人的神经网络模型,怎么在表格数据上就变的吭哧瘪肚了呢?今天我们来浅析一下其中可能的原因。
 1.数据有何不同?
1.数据有何不同?
1.1 什么是表格数据?
 表格数据的最大的特点是:异质性(Heterogeneous),即数据的每一列具有不同含义且数据类型不一致,这种异质的表格数据与图像或语言数据(同质数据)相比,其具有密集的数值特征和稀疏的分类特征。
表格数据的最大的特点是:异质性(Heterogeneous),即数据的每一列具有不同含义且数据类型不一致,这种异质的表格数据与图像或语言数据(同质数据)相比,其具有密集的数值特征和稀疏的分类特征。
1.2 NN处理表格数据的挑战
1) 低质量表格数据往往来自于真实世界的统计,而一旦数据来自真实世界,那么事情便复杂起来。可谓是虚假的数据千篇一律,真实的数据五花八门。脏数据、离群点、样本不均衡、数据空间小等一系列现实问题便很容易涌现出来。
inconsistent data
missing values
outliers
expensive
class-imbalanced
small size
2)缺失或拥有复杂的空间相关性当前主流的NN模型往往是在同质数据中使用归纳偏置,最典型的如卷积神经网络。表格数据集中的变量之间往往不存在空间相关性,或者特征之间的相关性相当复杂和不规则。当使用表格数据时,必须从头开始学习它的结构和特征之间的关系。这也是为什么迁移学习难以在表格数据上奏效的原因。
3)强依赖预处理同质数据上的深度学习的一个关键优势是它包含一个隐式表示学习步骤,因此只需要极少的预处理或显式特征构建。然而,当深度神经网络处理表格数据,其性能可能在很大程度上取决于所选择的预处理策略。不当的预处理方式可能导致:
信息缺失,预测性能下降
生成非常稀疏的特征矩阵(如通过使用onehot编码类别特征)导致模型无法收敛
引入先前无序特征的虚假排序信息(如通过使用有序编码方案)
4)特征重要性通常情况下,改变图像的类别需要对许多特征(如像素)进行协调变化,但一个分类(或二进制)特征的最小可能变化可以完全颠覆对表格数据的预测。与深度神经网络相比,决策树算法通过选择单个特征和适当的阈值“忽略”其余数据样本,可以非常好地处理不同的特征重要性。
 2.模型偏置有何不同?
2.模型偏置有何不同?
归纳偏置:在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就称为 归纳偏置(Inductive Bias) 。
因此,归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则(heuristics),然后对模型做一定的约束,从而可以起到“模型选择”的作用,即从假设空间中选择出更符合现实规则的模型。
所以,要理解两个模型在同一数据上的表现差异,就需要理解两个模型归纳偏置的不同。
2.1 实验配置
2.1.1 数据集
新基准参考 45 个表格数据集,选择基准如下 :
异构列,列应该对应不同性质的特征,从而排除图像或信号数据集。
维度低,数据集 d/n 比率低于 1/10。
无效数据集,删除可用信息很少的数据集。
I.I.D.(独立同分布)数据,移除类似流的数据集或时间序列。
真实世界数据,删除人工数据集,但保留一些模拟数据集。
数据集不能太小,删除特征太少(<4)和样本太少(<3000)的数据集。
删除过于简单的数据集。
删除扑克和国际象棋等游戏的数据集,因为这些数据集目标都是确定性的。
2.1.2 数据预处理
论文里尽可能少的使用了人工预处理,只应用以下转换:
高斯化特征:对于神经网络训练,采用Scikit-learn的QuantileTransformer对特征进行高斯化处理。
改变回归目标:在回归任务中,当目标变量的分布是重尾时,对其进行对数变换。
OneHotEncoder:对于本身不处理类别特征的模型,使用ScikitLearn的OneHotEncoder编码分类特征。
2.2 模型
在基于树的模型中,研究者选择了 3 种 SOTA 模型:Scikit Learn 的 RandomForest,GradientBoostingTrees (GBTs) , XGBoost 。
该研究对深度模型进行了以下基准测试:Resnet 、FT Transformer、SAINT 。
FT Transformer:《Revisiting Deep Learning Models for Tabular Data》2021 NIPS。专注于解决表格数据的NN模型。
SAINT:《Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing》 提出一种分离的自注意力神经知识追踪结构,本质还是transformer结构,选它的原因是在一部分表格数据上它有远超transformer的表现。
2.3 归纳偏置
(1)类别特征并不是神经网络的主要弱点图一是在纯数字特征数据集上的表现: 图二是在同时具有数字和分类特征数据集上的表现:
图二是在同时具有数字和分类特征数据集上的表现: 【说明】
【说明】
虚线对应默认超参数的得分,也是第一次随机搜索迭代。
实线上的每个值对应于最佳模型(在验证集上)经过特定次数的随机搜索迭代后的所有数据集上的平均测试分数。
色带对应这15次随机初始化的最低和最高分数。
【显式结论】
调优超参数并不能使神经网络达到SOTA:基于树的模型对于每个随机搜索都具有优越性,即使经过大量的随机搜索迭代,NN模型相比树模型性能差距仍然很大。
类别特征并不是神经网络的主要弱点:类别特征通常被认为是在表格数据上使用神经网络的一个主要问题。我们在数值变量上的结果只揭示了树型模型和神经网络之间的差距比包含分类变量更小。然而,当只学习数字特征时,这种差距仍然存在。
(2)神经网络倾向于比较平滑的解决方案通过不同尺度的高斯核函数将训练集上的output进行平滑,这样可以有效防止模型学习目标函数的不规则pattern。高斯平滑核: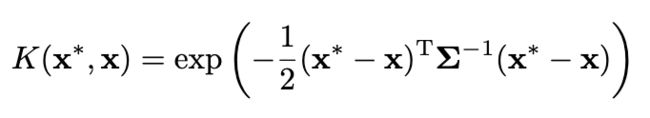 平滑训练集output方式:
平滑训练集output方式: 实验结果:
实验结果:
上图显示了模型性能作为平滑核的长度尺度的函数。结果表明,对目标函数进行平滑处理会显著降低基于树的模型的精度,但对神经网络的精度影响不大。这也说明我们数据集中的目标函数不是平滑的,与基于树的模型相比,神经网络很难拟合这些不规则的函数。
这与Rahaman等人[2]的发现一致,他们发现神经网络偏向拟合低频函数。而基于决策树的模型学习分段常数函数,不会表现出这样的偏见。

上图是电力数据集两个最重要特征的决策边界。在这一部分中,我们可以看到RandomForest能够学习MLP无法学习的x轴上的不规则模式(对应于日期特征)。
(3)非信息特征更能影响类似MLP的NN
表格数据集包含许多非信息(uninformative)特征,对于每个数据集,该研究根据特征的重要性会选择丢弃一定比例的特征(通常按随机森林特征重要性排序)。从下图可以看出,去除一半以上的特征对GBT的分类准确率影响不大。
绿线:保留最重要的特征,依次移除最不重要的特征
红线:依次添加上述被移除的特征
可以发现,当在被移除20%特征时,GBT在测试集上的精度都降低的非常小,直到被移除50%特征时,精度下降才逐渐明显,这表明这些特征大部分是无信息增益的。但是从红线的涨幅来看,这些特征又不是完全无用的。
上图可以看到移除非信息特征减少了 MLP (Resnet) 与其他模型(FT Transformers 和基于树的模型)之间的性能差距 ,而添加非信息特征会扩大差距,这表明MLP 对非信息特征的鲁棒性较差。
(4)MLP更具旋转不变性与其他模型相比,为什么MLP更容易受到无信息特征的影响?其中一个答案是:MLP 是旋转不变的。当对训练集和测试集特征应用旋转时,在训练集上学习 MLP 并在测试集上进行评估,这一过程是不变的。事实上,任何旋转不变的学习过程都具有最坏情况下的样本复杂度,该复杂度至少在不相关特征的数量上呈线性增长。直观地说,为了去除无用特征,旋转不变算法必须首先找到特征的原始方向,然后选择信息最少的特征。 上图 a 显示了当对数据集进行随机旋转时的测试准确率变化,证实只有 Resnets 是旋转不变的。值得注意的是,随机旋转颠倒了性能顺序,这表明旋转不变性是不可取的。事实上,表格数据通常具有单独含义,例如年龄、体重等。
上图 a 显示了当对数据集进行随机旋转时的测试准确率变化,证实只有 Resnets 是旋转不变的。值得注意的是,随机旋转颠倒了性能顺序,这表明旋转不变性是不可取的。事实上,表格数据通常具有单独含义,例如年龄、体重等。
图 b 中显示:删除每个数据集中最不重要的一半特征(在旋转之前),会降低除 Resnets 之外的所有模型的性能,但与没有删除特征使用所有特征时相比,相比较而言,下降的幅度较小。
 模型本质有何不同?
模型本质有何不同?
树模型的本质:分段常数函数 决策树在本质上是一组嵌套的if-else判定规则,从数学上看是分段常数函数,对应于用平行于坐标轴的平面对空间的划分。判定规则是人类处理很多问题时的常用方法,这些规则是我们通过经验总结出来的,而决策树的这些规则是通过训练样本自动学习得到的。而正是这种简单的划分使得模型的决策流形(decision manifolds)可以看成是超平面的分割边界,对于表格数据的效果很好。
决策树在本质上是一组嵌套的if-else判定规则,从数学上看是分段常数函数,对应于用平行于坐标轴的平面对空间的划分。判定规则是人类处理很多问题时的常用方法,这些规则是我们通过经验总结出来的,而决策树的这些规则是通过训练样本自动学习得到的。而正是这种简单的划分使得模型的决策流形(decision manifolds)可以看成是超平面的分割边界,对于表格数据的效果很好。
神经网络的本质:分段线性函数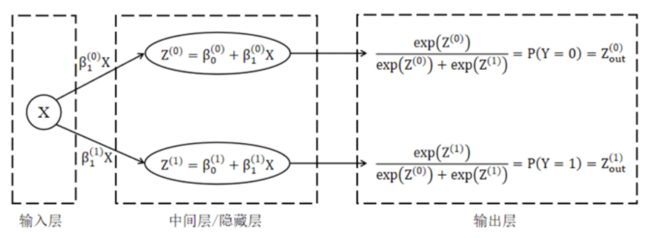 以最简单的神经网络结构表示的单变量逻辑回归模型来说,中间层是ax+b这种线性表达方式进行拟合的表达能力是非常有限的。
以最简单的神经网络结构表示的单变量逻辑回归模型来说,中间层是ax+b这种线性表达方式进行拟合的表达能力是非常有限的。 而不管在中间加多少层线性变换,并不能提高其表达能力,最终模型本质上仍然是一个关于x的线性模型。那么如何引入非线性呢?——激活函数。激活函数的引入使神经网络具备了非线性表达的能力。
而不管在中间加多少层线性变换,并不能提高其表达能力,最终模型本质上仍然是一个关于x的线性模型。那么如何引入非线性呢?——激活函数。激活函数的引入使神经网络具备了非线性表达的能力。 神经网络强大的本质原因:1)激活函数让线性的神经网络具备了“分段”表达的能力。2)任何函数都可以用“分段”线性函数来逼近。成也强大、败也强大,正是因为神经网络这种过强的拟合能力导致在size通常不大的表格数据上很容易过拟合。对于大规模神经网络来说,中间隐层所生成的“高维特征”甚至有时比原始数据还多。
神经网络强大的本质原因:1)激活函数让线性的神经网络具备了“分段”表达的能力。2)任何函数都可以用“分段”线性函数来逼近。成也强大、败也强大,正是因为神经网络这种过强的拟合能力导致在size通常不大的表格数据上很容易过拟合。对于大规模神经网络来说,中间隐层所生成的“高维特征”甚至有时比原始数据还多。
 做个小结
做个小结
树模型特点
天然的鲁棒性,对异常点、缺失值不敏感,不需要归一化等操作。
模型的决策流形(decision manifolds)是可以看成是超平面的分割边界,对于表格数据的效果很好。
基于贪心的自动化特征选择和特征组合能相比其他ML模型,具有更强的非线性表达能力。
树的可解释性很好,分裂可视化以及特征重要性等操作,能改善特征工程。进一步优化特征,提升模型性能。
数据量带来的边际增益不大,容易触及天花板。
NN模型特点
在语义含义统一的稠密数据上,拥有全自动化的特征工程的能力,包括超强的特征挖掘与特征组合能力。
极强的数据记忆能力与外推泛化能力。
对异常值敏感,对于表格数据,强依赖数据预处理。
不可解释,无法像树模型那种直观展示预测流程,无法推演与优化基础特征。
过强的非线性中隐含过拟合和噪音。
闻道有先后,术业有专攻,即便强如神经网络也有自己的软肋。但从上述结果其实也可以发现,神经网络不适合处理表格数据仅仅是因为我们还没有掌握合适的方法,神经网络的强大的建模能力仍毋庸置疑。相信总有一天,神经网络模型将一统江湖,三界唯尊!
卖萌屋作者:乐乐QvQ。
硕士毕业于中国科学院大学,前ACM校队队长,区域赛金牌。竞赛混子,Kaggle两金一银,国内外各大NLP、大数据竞赛Top10。校招拿下国内外数十家大厂offer,超过半数的SSP。目前在百度大搜担任搜索算法工程师。知乎ID:QvQ
作品推荐:
1.13个offer,8家SSP,谈谈我的秋招经验
2.BERT为何无法彻底干掉BM25??
3.训练双塔检索模型,可以不用query-doc样本了?
4.他与她,一个两年前的故事
5.Bing与DuckDuckGo搜索结果惊人一致?Google展现强势差异
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1] Why do tree-based models still outperform deep learning on tabular data? https://arxiv.org/abs/2207.08815
[2] On the Spectral Bias of Neural Networks.https://arxiv.org/abs/1806.08734
[3] Deep Neural Networks and Tabular Data: A Survey. https://arxiv.org/pdf/2110.01889.pdf
[4] Relational inductive biases, deep learning, and graph networks. https://arxiv.org/abs/arXiv:1806.01261
[5] Revisiting Deep Learning Models for Tabular Data. https://arxiv.org/pdf/2106.11959.pdf
[6] 遇事不决,XGBoost,梯度提升比深度学习更容易赢得Kaggle竞赛
[7] 数据挖掘竞赛利器——TabNet模型浅析 https://zhuanlan.zhihu.com/p/152211918
[8] 为什么在实际的kaggle比赛中,GBDT和Random Forest效果非常好?https://www.zhihu.com/question/51818176
